李宏毅深度学习(1)——CNN的3个property
CNN其实就是把一些neuron拿走。为什么?3个property。
property 1
a neuron does not have to see the whole image to discover the pattern. 比如一张鸟的图片,第一layer是去侦测有没有鸟嘴存在(beak detector)。
property 2
鸟嘴的位置不影响,不用两组parameters来train这个特征。
property 3
subsampling the pixels does not change the object. we can subsample the image to make the pic smaller.
so, less parameters.

the structure:
(convolution + max pooling) x many times + flatten + fully connected feedforward NN
property 1 2 是convolution来处理
property 3 是max pooling来处理

怎么解决property 1?
每个3x3的filter就是相当于网络的parameters
每个filter作用就是detect了一个小pattern
下面这个filter和6x6做了内积之后,stride=1,变成4x4(叫做一个feature map), 就是去侦测有没有斜着的111
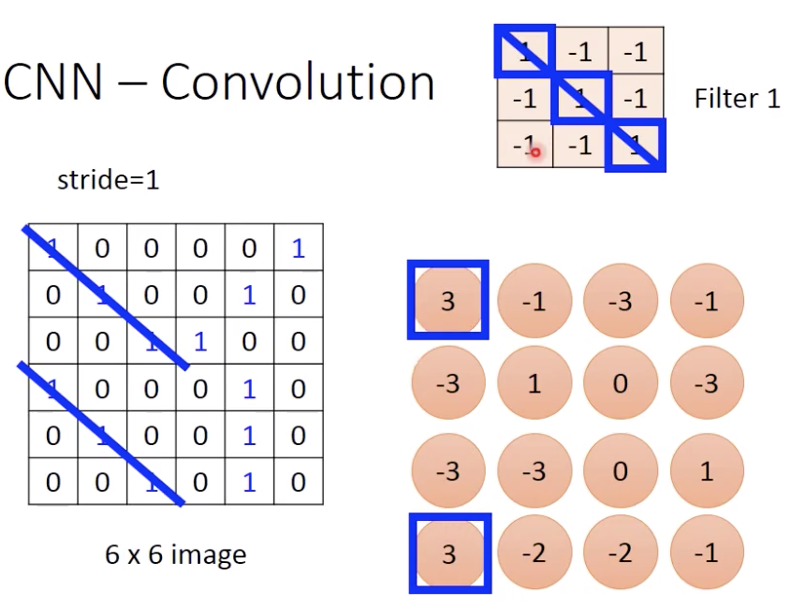
你有几个filter,就会得到几个feature map。(那我就有问题了,image的旋转怎么办)
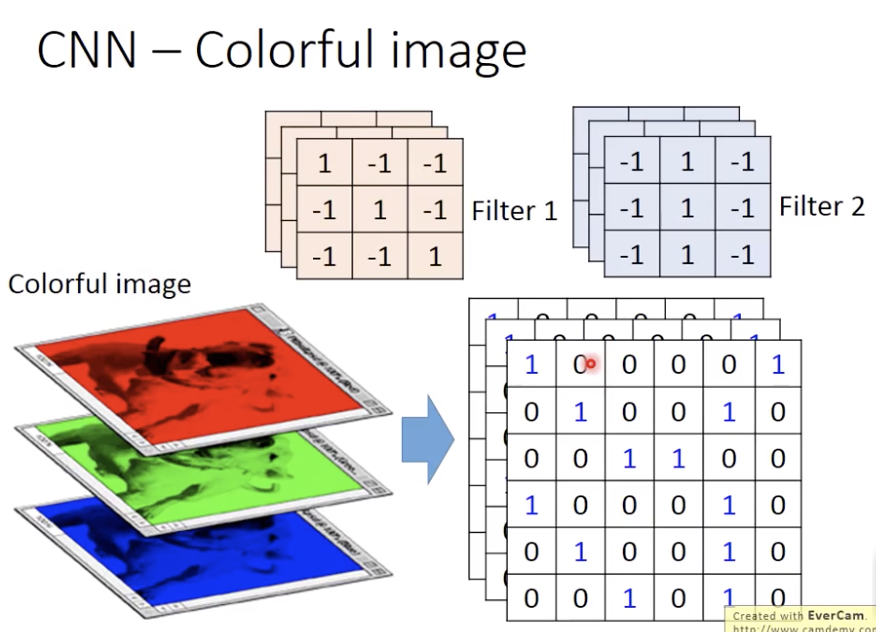
刚才说的是黑白的image,那彩色的image怎么办
RGB三层,
filter也是一个三层的
那现在filter和image做内积怎么和network的neuron联系起来呢?
比如6x6的image和3x3的filter。把pixel拉直了之后,就是这个神经元只和下标1 2 3 ,7 8 9,13 14 15的pixel有连接 (not fully connected )
less parameters!
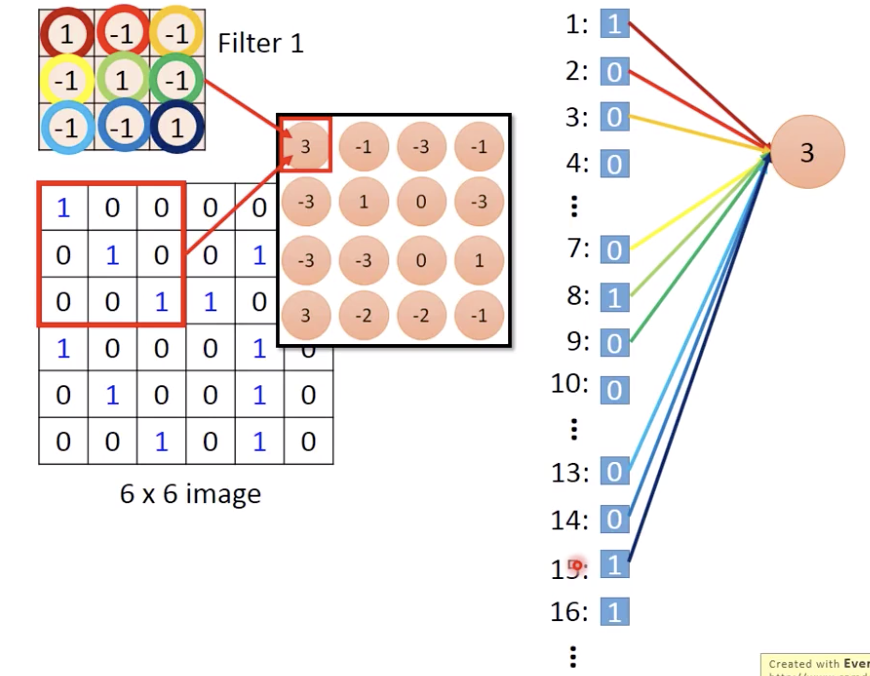
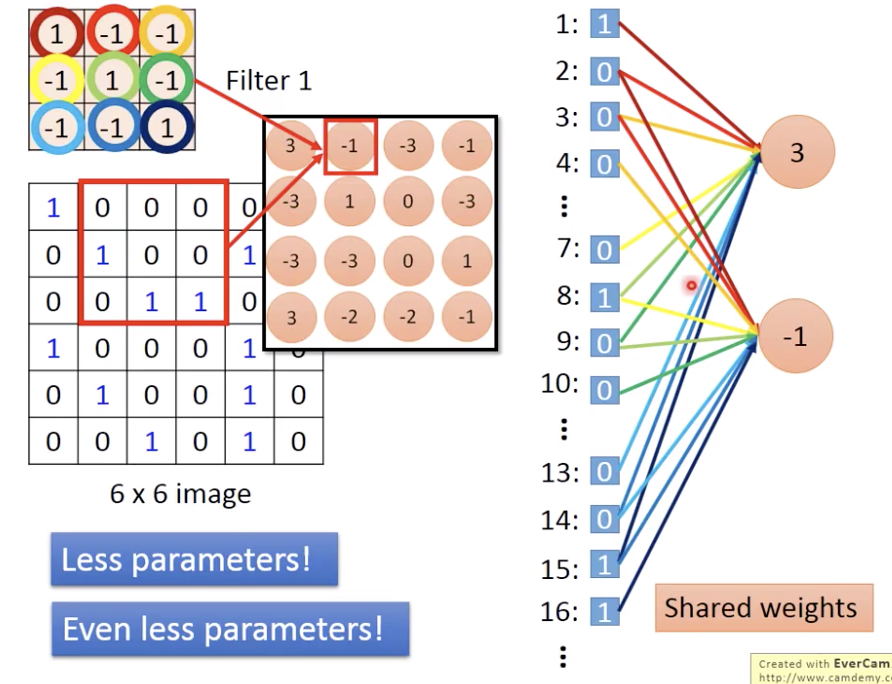
那怎么解决滑步stride?
用规则,比如上一个neuron连接到input 2 的位置就和 接着的neuron连接input 3的位置有一样的weight
(even less parameters)
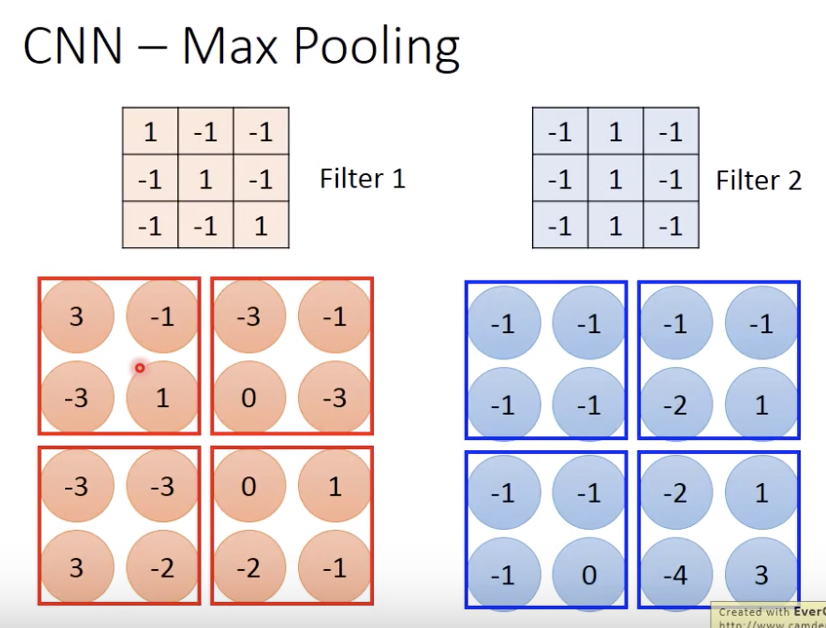
max pooling就是,4个一组取最大值/平均值
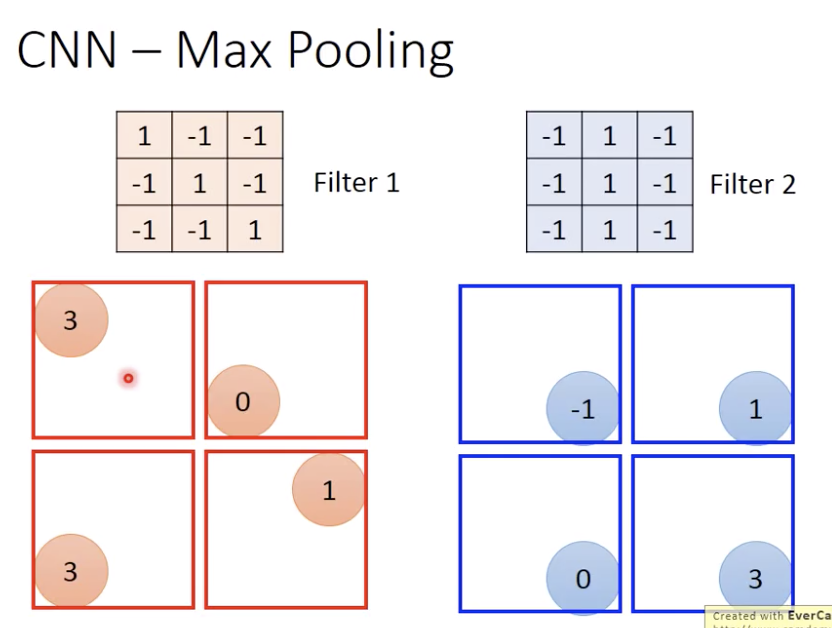
现在6x6变成了4x4,又变成了2x2但是有多个channel, 这样
最后一个immage的深度就是filter的个数。the number of channel is the number of filters
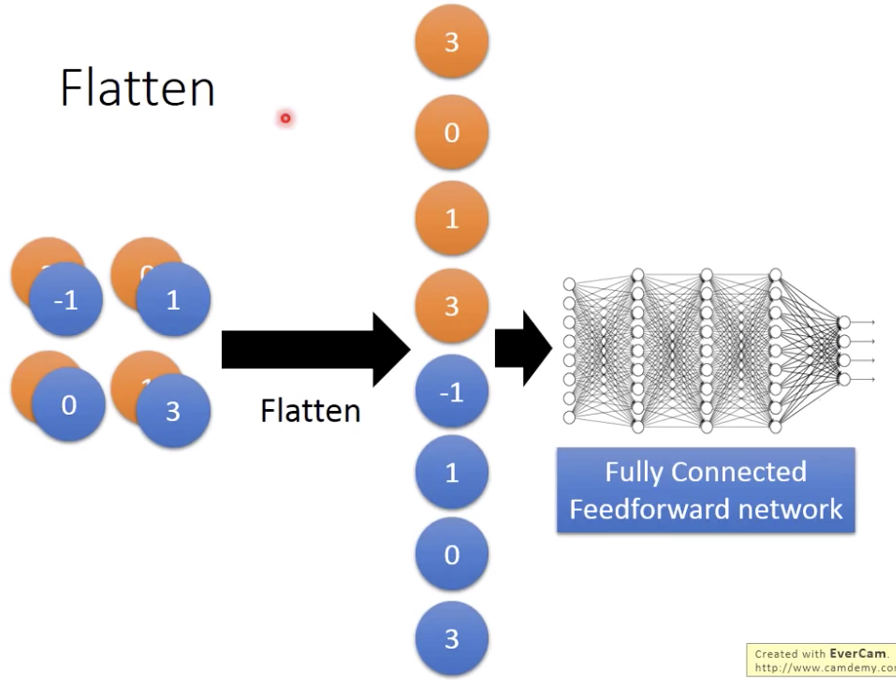
flatten没什么好讲的
keras里面参数的含义
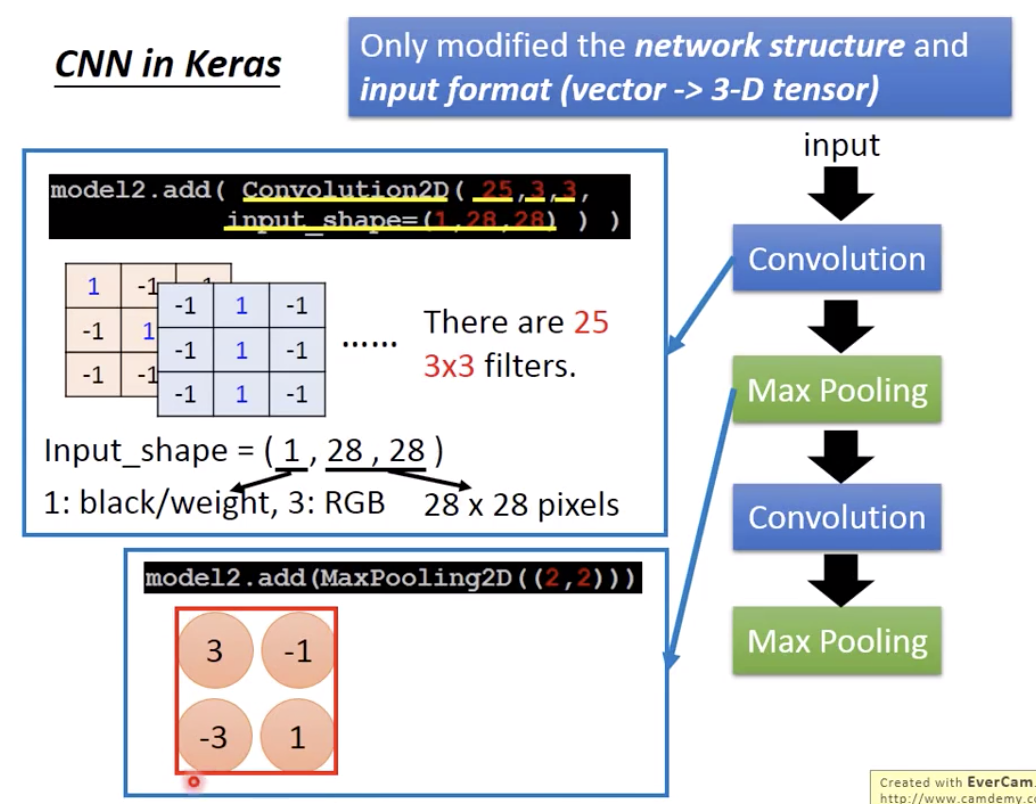
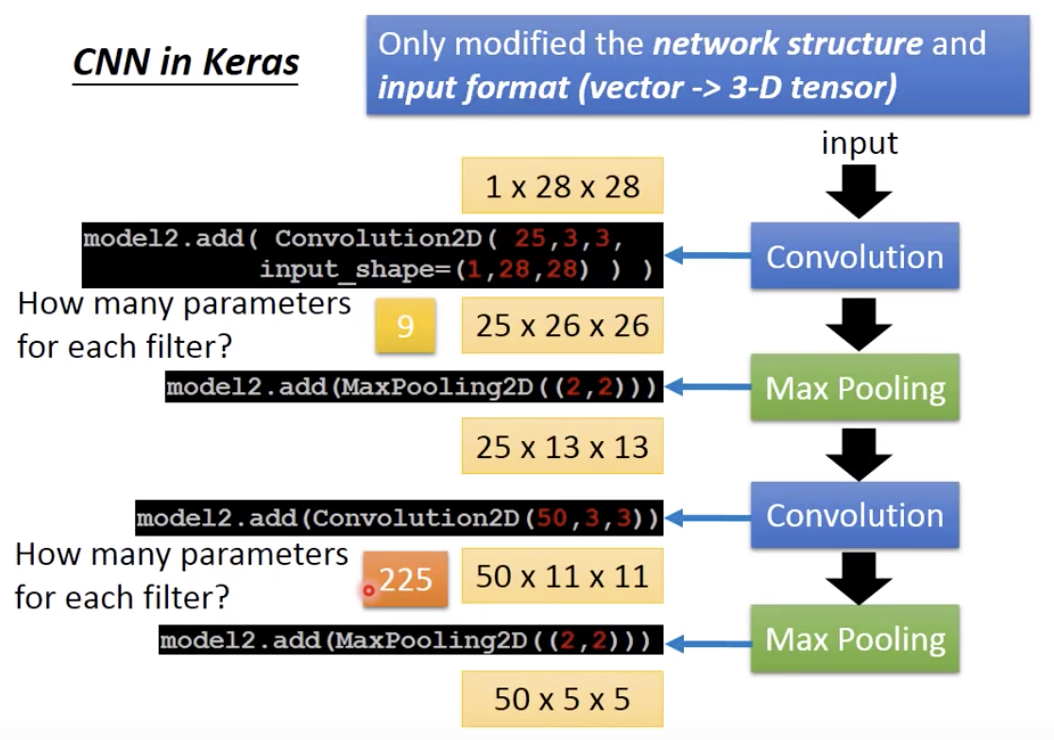
25个filter,stride=1,所以第一次convolution之后得到的是25个channel,28-2=26.
2nd layer的filter用50个,还是3x3大小,所以第二次convolution之后得到的是50个channel,13-2=11.
每个filter参数是3x3=9,2nd layer的filter参数还要算上深度25,所以是25x9=225.
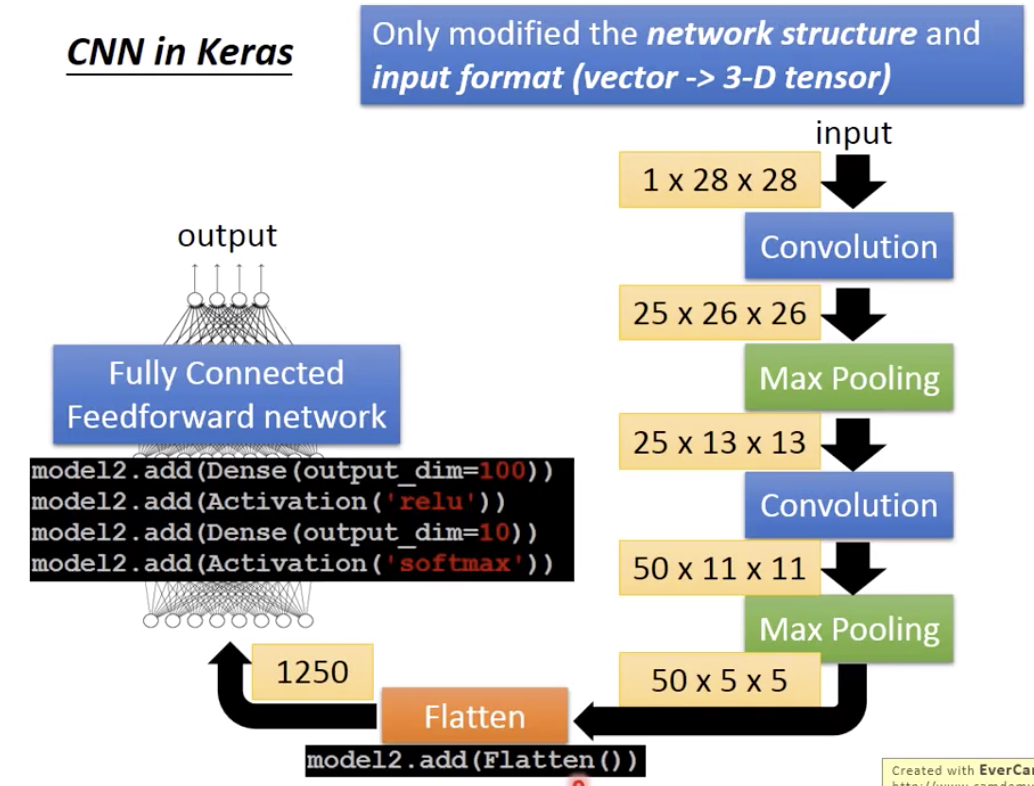
最后50x5x5拉直,就是1250,丢到fully connected network里面
what does cnn learn?
第一层filter作甚很好理解,因为input这时候是一个3x3的pixel。其实你不能想象的是他第二层的filter是在作甚,因为这时候3x3的filter看到的东西比最初画面的9个pixel更大,因为是第一层convo+MaxPooling之后的结果。那么怎么分析一个filter做的啥?
我们定义一个degree of activation。就是filter的结果11x11这个output 全部加和。有多么被activation。然后,用gradient descent,最大化a^k的input x是什么样子的。(这是和训练filter参数的过程反过来的,固定filter,训练input)
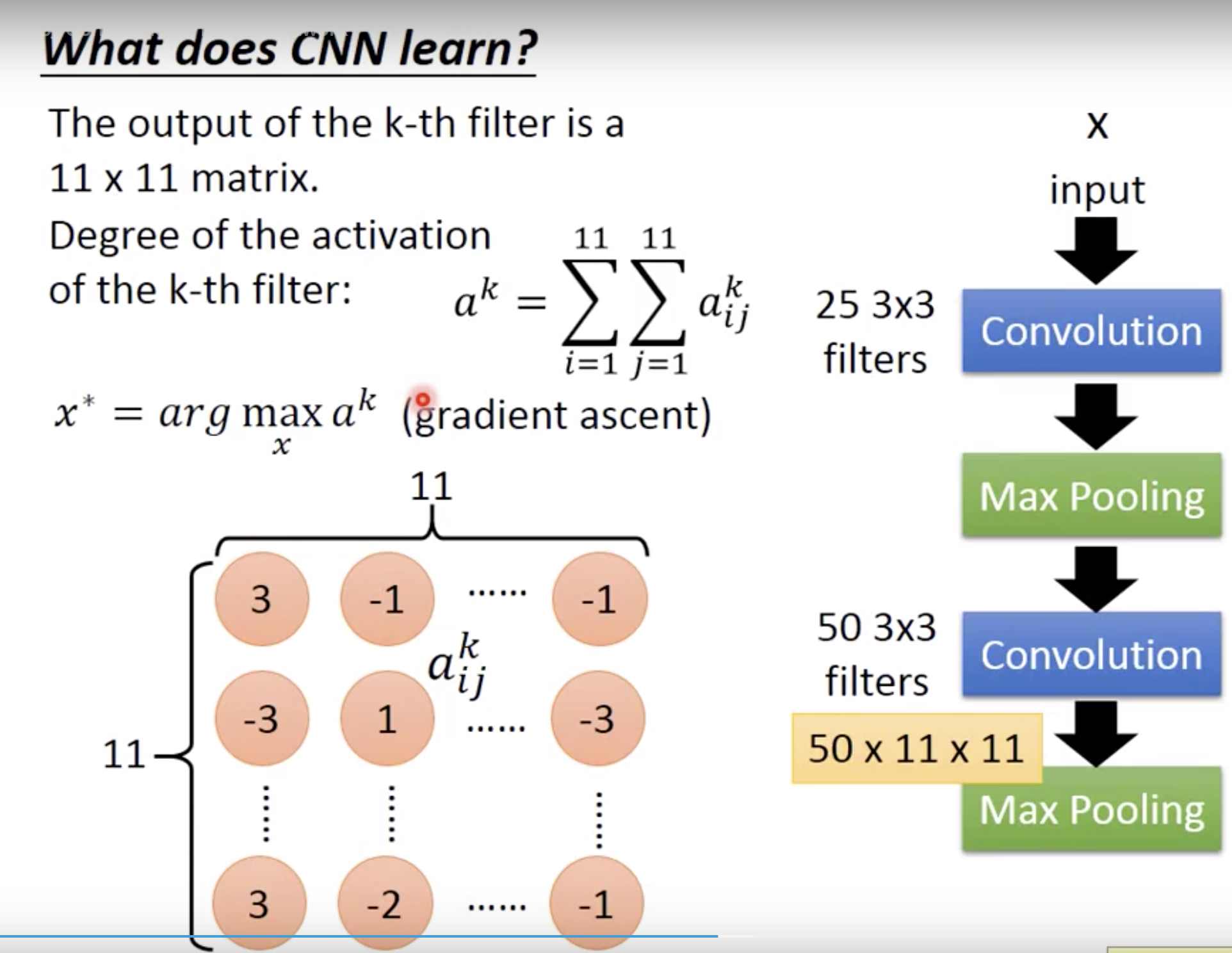

看这个filter detect的是什么样的pattern。你就会发现这个第二层的filter去detect的就是各个方向斜条纹密密麻麻重复的纹路pattern。
那么最后fully connected里面每个neron的工作是什么。同样的方法。

一个应用 alphago

不需要max pooling。因为不会把围棋的任何一行去掉,去检测pattern。
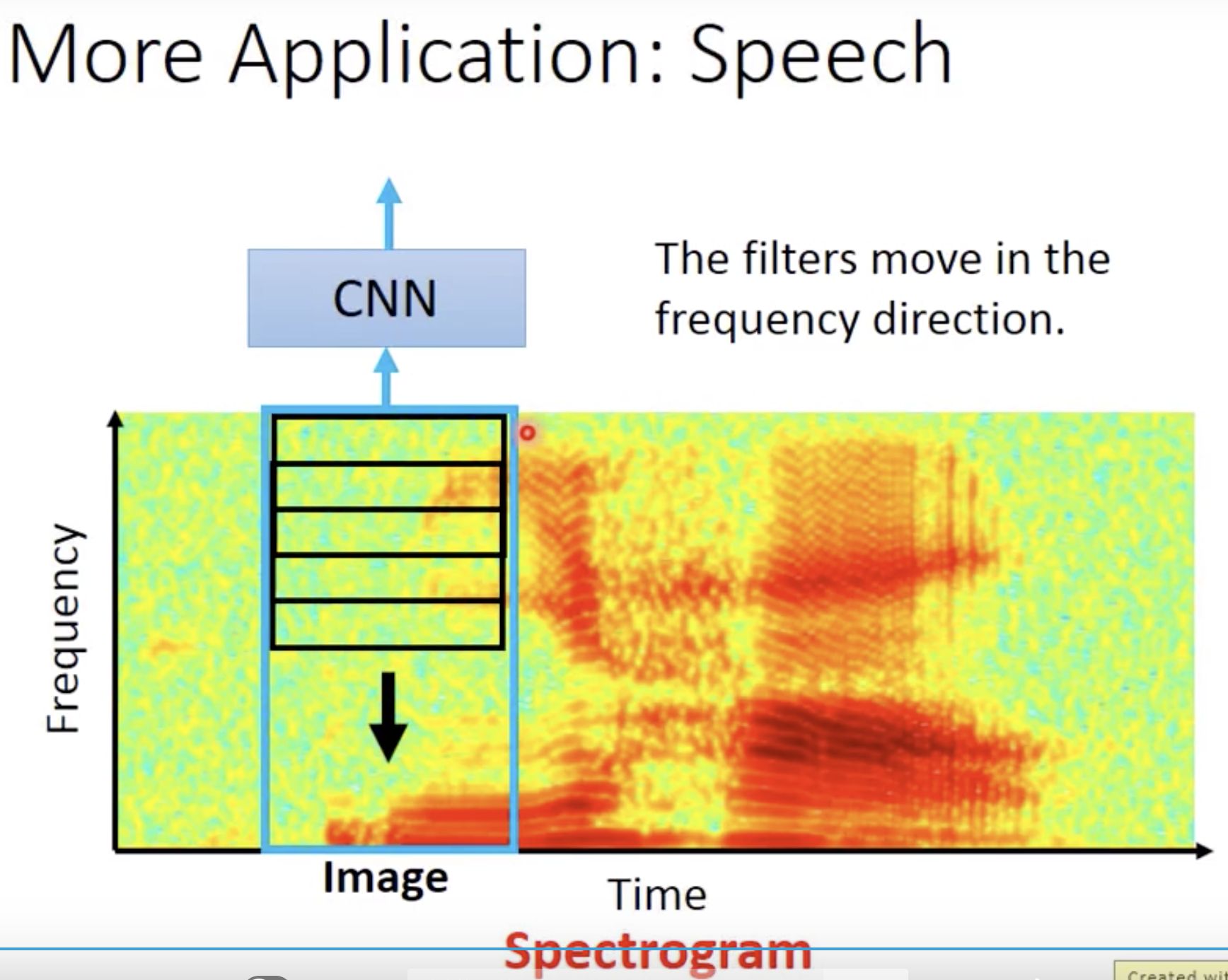
声音就是去看声音频谱,filter不会在time方向移动,因为一般cnn后面会接上lstm,已经把时间考虑进去了。只在频率方向移动,因为男生女生说你好的pattern一样 但是频率不一样
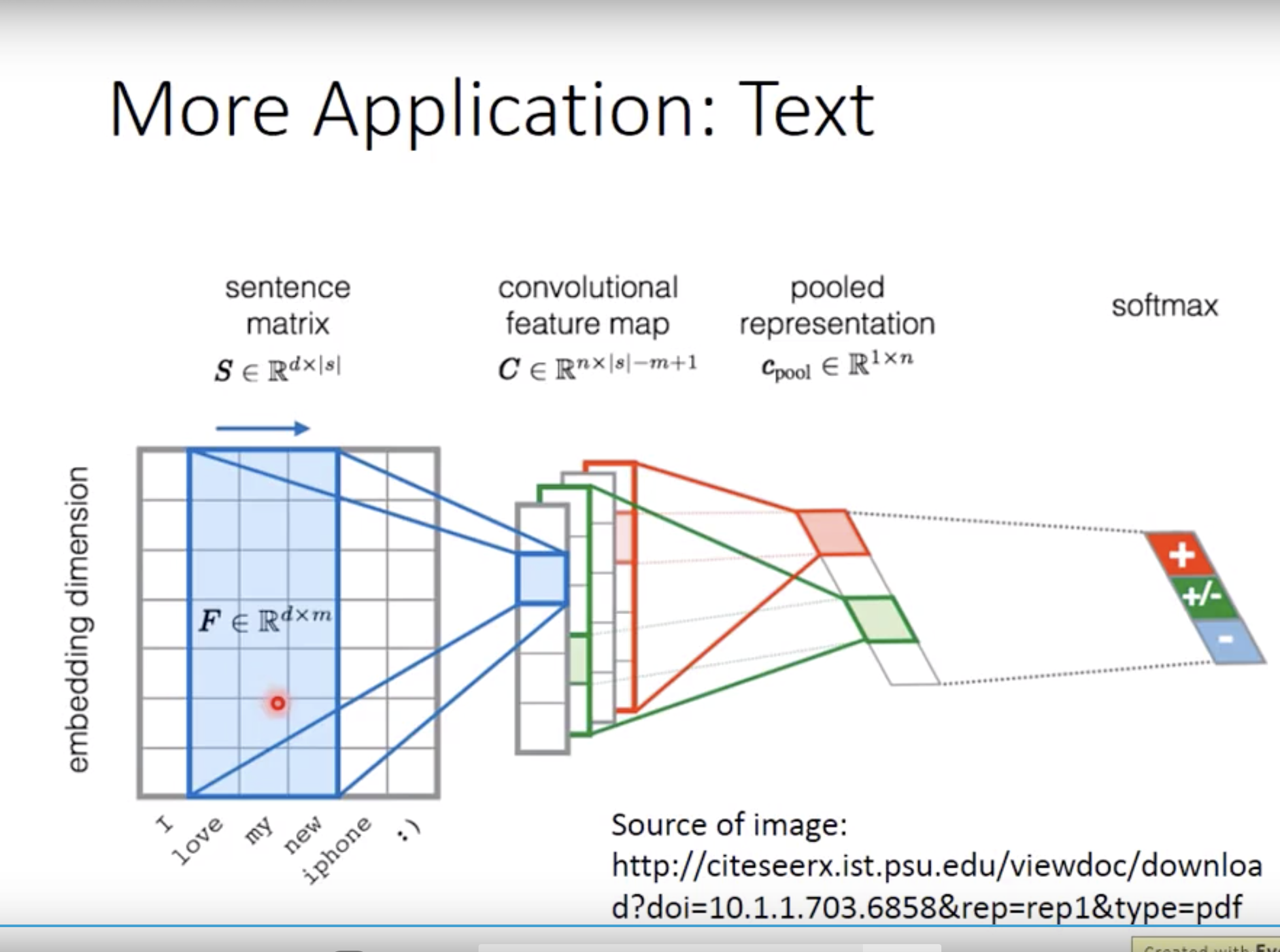
text的application就是沿着橘子的方向去移动filter,filter和embedding一样高的