
集合(二)
备注:若有不正之处,请多谅解并欢迎批评指正。转载请标明链接:https://www.cnblogs.com/pmbb/p/11427724.html
集合(二)对集合(一)做一些简单的补充和复习
集合的作用
在编程中,需要管理很多对象集.比如某班全部同学,某个公司所有人员资料等.
要管理这些资料,java必须提供某种数据结构支持.
由于时间,空间,安全的考虑,有各种不同的实现.比如ArrayList,vector.hashmap,linklist,treemap,hashset等多种实现.
为了屏蔽实现差异,java提供了一个Collection(集合)接口,规定必须实现一些公用的方法.
比如 add.remove,size等等这样,不管底层如何实现,我都知道他们至少拥有上面方法.
一句话java集合就是提供一组通用接口的,管理大量数据的数据结构实现.
集合框架体系介绍
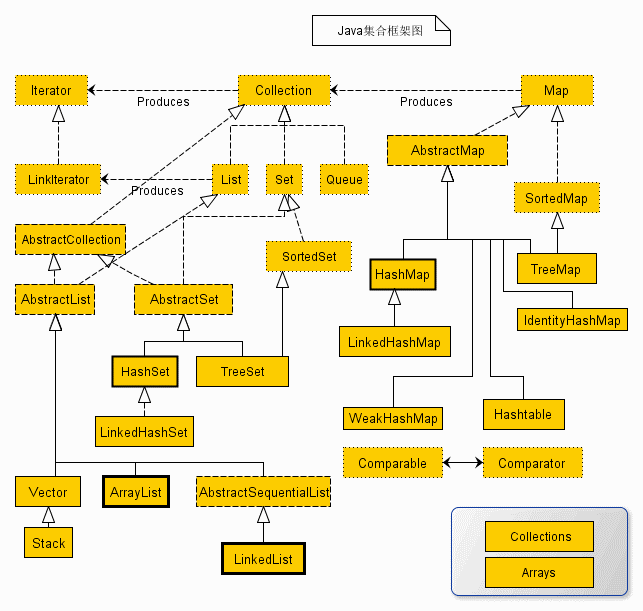
总结:
List , Set, Map都是接口,前两个继承至Collection接口,Map为独立接口
Set下有HashSet,LinkedHashSet,TreeSet
List下有ArrayList,Vector,LinkedList
Map下有Hashtable,LinkedHashMap,HashMap,TreeMap
Collection接口下还有个Queue接口,有PriorityQueue类
Collection接口
Collection是最基本的集合接口,一个Collection代表一组Object,即Collection的元素(Elements)。一些Collection允许相同的元素而另一些不行。一些能排序而另一些不行。Java SDK不提供直接继承自Collection的类,Java SDK提供的类都是继承自Collection的“子接口”如List和Set。
— List 有序,可重复
ArrayList
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程不安全,效率高
Vector
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程安全,效率低
LinkedList
优点: 底层数据结构是链表,查询慢,增删快。
缺点: 线程不安全,效率高
—Set 无序,唯一
HashSet
底层数据结构是哈希表。(无序,唯一)
如何来保证元素唯一性?
1.依赖两个方法:hashCode()和equals()
LinkedHashSet
底层数据结构是链表和哈希表。(FIFO插入有序,唯一)
1.由链表保证元素有序
2.由哈希表保证元素唯一
TreeSet
底层数据结构是红黑树。(唯一,有序)
1. 如何保证元素排序的呢?
自然排序
比较器排序
2.如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
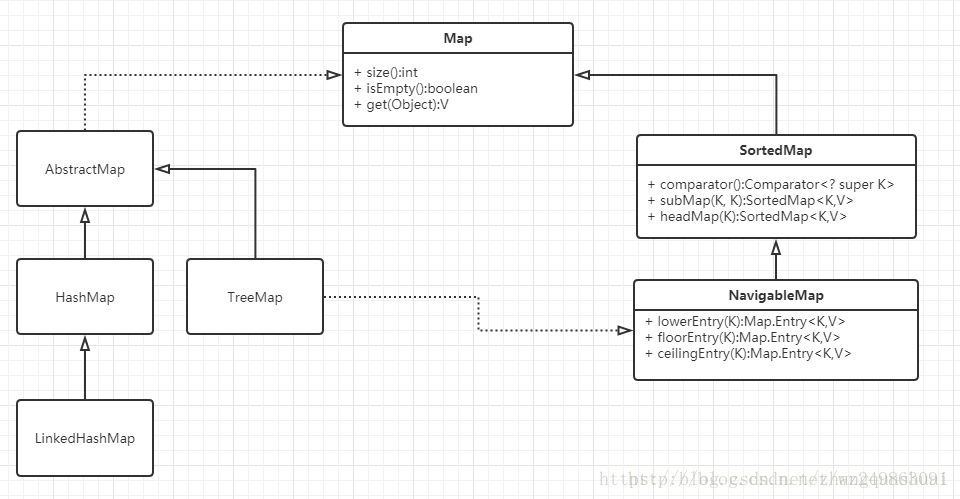
Map接口有三个比较重要的实现类,分别是HashMap、TreeMap和HashTable。
TreeMap是有序的,HashMap和HashTable是无序的。
Hashtable的方法是同步的,HashMap的方法不是同步的。这是两者最主要的区别。
这就意味着:
Hashtable是线程安全的,HashMap不是线程安全的。
HashMap效率较高,Hashtable效率较低。
如果对同步性或与遗留代码的兼容性没有任何要求,建议使用HashMap。 查看Hashtable的源代码就可以发现,除构造函数外,Hashtable的所有 public 方法声明中都有 synchronized关键字,而HashMap的源码中则没有。
Hashtable不允许null值,HashMap允许null值(key和value都允许)
父类不同:Hashtable的父类是Dictionary,HashMap的父类是AbstractMap
ArrayList和LinkedList各自的工作原理分析原理分析
👉先来点鸡汤
前几年易中天可谓非常的火,接受过很多采访。他的情况比较特殊,在武汉读高中时期,恰逢“知识青年上山下乡”活动,就到新疆去了。
在新疆生产建设兵团工作、生活了10年,而后在乌鲁木齐钢铁公司子弟中学任教。77年全国恢复高考后他没有去考大学,78年国家恢复研究生招生后他去考了,然后被武汉大学中文系录取。
当时主持人问他,为什么跳过本科直接考研究生呢?他的回答是:考场上的事谁能说的准呐,如果我和我的学生一起去参加高考,万一他考上了我没考上,这多丢人呢(还怎么好意思当人家的老师)。但是考研如果考不上,那在学生面前是不丢人的。
大名鼎鼎的教授当初都害怕考不上,看来考上考不上乃兵家常事。
面试也是一样的,我们应该正确对待。知道的就回答,不知道的就请教,似是而非的就探讨,开开心心的度过一个小时的交谈就行了。至于结果那要看缘分了,而且这是一个双向选择。
👉记一次面试
有位应聘者来面试,我和他坐到了小会议室里。他,很年轻,刚入行,应该还培训过,是不是计算机专业我已经记不清了。
但这不重要,照例还是从List问起。一是List可以说是最简单的,二是简单的问题更能考察一个人的思维表达能力。
我:做Java开发的,List肯定用过,你都用过哪些List的实现类呢?
他:一般都用ArrayList。
我:除了ArrayList,你还知道哪些List,没用过也行。
他:(有点紧张)不知道。
其实他的水平大概我也清楚了,完全可以再问两个问题草草把他打发走。但只要时间允许的情况下,我是不会这样做的。
一方面是不让面试者觉得自己因水平较差不受重视。
二是这部分人大都是转行培训刚入坑不久的新人,不想让他们的自信心受到打击。
三是面试的过程其实对面试官也是一种锻炼,也可以借机refresh自己的记忆。
最后说句良心话,面试者为了这个面试花在路上的时间估计都要一个小时,如果用5分钟就让人家走,感觉有点说不过去。
我:还有一个LinkedList,不知道你有没有见过。
他:知道,平时没用过,所以没什么印象。
我:一个叫ArrayList,一个叫LinkedList,根据名字你说下它们底层是怎么实现的?
他:应该一个是用数组实现的,一个是链表实现的。
我:那你能不能说一下数组和链表的主要区别是什么?
大概过了好几秒,他没有回答,也不说不知道。我觉得可能是我问的方式略微笼统,我就又具体了一些。
我:数组和链表是数据结构里的概念,这你应该知道。我的意思是从数据结构的角度,数组有什么特点,链表有什么特点,或者说它们在内存里大致是怎么分布的?
他:数据结构的东西不太会。
我觉得我的问题已经很清晰了,但凡是正常的开发者,多多少少都应该能说出点,可是,他没有。
看得出他有点紧张,所以我每次都是微笑着、用很柔和的声音和他说话,就害怕太强势了给他造成影响。
虽然这么简单的问题,他都不会,我还是很耐心地给他讲解,就当是锻炼自己了。
我:定义一个数组,只需指定一个长度即可。然后就可以通过变量名+索引(或者说下标)的形式访问数组元素了,下标不能超过数组长度,否则就会发生索引越界异常。
比如数组a,长度是10,那么第一个元素就是a[0],最后一个就是a[9]。想访问哪个元素只要指定下标就可以了。像这种可以随意访问任何元素的,有个专用名词叫做随机访问。
那我们来看下它在内存中是如何分布的,才支持随机访问。其实数组在内存中是一段连续的空间,你可以把它想象成一个梯子,一个格子紧挨着一个格子。
数组名,也就是这个a,指向了这个空间的起始处地址,也就是数组的第一个元素的地址,所以其实和a[0]指向的是同一个地方。但a和a[0]的含义不一样,a表示内存地址,a[0]表示这个地址上存的元素。
这里的下标0其实指的是相对于起始处地址的偏移量。0表示没有偏移,所以就是起始处地址的那个元素,也即第一个元素。
a[1]表示相对于起始处地址偏移量为1的那个元素,实际可以认为底层执行的是*(a + 1)。a+1表示从起始地址开始向后偏移1个之后的地址,那么*(星号)的意思就是取出那个地址上存储的元素。因为向后偏移了1个,其实就是第二个,所以a[1]叫取出数组的第二个元素。
因数组在内存中是一段连续的空间,所以不管访问哪个元素都是这两步,加上偏移量,然后取数据。这就是它支持随机访问的原因。说白了就是所有元素按顺序挨在了一起。
也可以看出来,不管数组的长度是多长,访问元素的方式都是这两步,都在常量的时间内完成。所以按索引访问数组元素的时间复杂度就是O(1)。
ArrayList只不过是对数组的包装,因为数组在内存中分配时必须指定长度,且一旦分配好后便无法再增加长度,即不可能在原数组后面再接上一段的。
ArrayList之所以可以一直往里添加,是因为它内部做了处理。当底层数组填满后,它会再分配一个更大的新的数组,把原数组里的元素拷贝过来,然后把原数组抛弃掉。使用新的数组作为底层数组来继续存储。
他:你讲的非常好,我完全听懂了,比我当时那个培训班的老师讲的好多了。
我:LinkedList也实现了List接口,也可以按索引访问元素,表面上用起来感觉差不多,但是其底层却有天壤之别。
与数组一下子分配好指定长度的空间备用不同,链表不会预先分配空间。而是在每次添加一个元素时临时专门为它自己分配一个空间。
因为内存空间的分配是由操作系统完成的,可以说每次分配的位置都是随机的,并没有确定的规律。所以说链表的每个元素都在完全不同的内存地址上,那我们该如何找到它们呢?
唯一的做法就是把每个元素的内存地址都要保存起来。怎么保存呢?那就让上一个元素除了存储具体的数据之外,也存储一份下一个元素在内存中的地址。
整个就像前后按顺序依次相连的一条链,我们只要保存第一个元素的内存地址,就可以顺藤摸瓜找到所有的元素。
这其实就像一个挖宝藏游戏,假设共10步,告诉你第一步去哪里挖。然后挖出一个字条,上面写着第二步去哪里挖。依次这样挖下去。第九步挖出字条后才知道宝藏的位置,然后第十步就把它挖出来了。
可见为了得到宝藏必须这样一步一步挖下去。中间的任何一步都不能跳过,因为第十步宝藏的位置在第九步里放着呢,第九步的位置在第八步里放着呢,依次倒着下来就到了第一步的位置,而第一步的位置已经告诉你了。
所以数组更像是康庄大道、四平八稳。链表更像是曲径通幽、人迹罕至。一个像探险,步步为营。一个像回家,轻车熟路。
可见按索引访问链表元素时,必须从头一个个遍历,而且链表越长,位置越靠后,所需花费的时间就越长。所以按索引访问链表元素的时间复杂度就是O(n),n为链表的长度。
也说明了链表不支持随机访问。所以ArrayList就实现了RandomAccess(随机访问)接口,而LInkedList就没有。
他:你讲的真好。
👉后记
后来这个应聘者给我司前台打电话,说他自己水平太差,无法到我司来。但是叮嘱前台一定要转达对我的感谢。
说面试时他内心非常紧张,但面试官总是面带微笑很温和地跟他说话。遇到不懂的地方,总是非常有耐心地给他讲解,旁征博引,举一反三。最后他都听懂了,而且也不紧张了。
我感觉这是我收到的对我最高的评价,不是吗?
Vector和Stack(简单介绍)
Java Collection系列下面有List,Set,Queue等,而Vector属于List下面的一个实现。
Vector:
线程安全,默认容量为10,容量增长量默认为0,每次进行扩容是旧的容量乘以2。支持null的添加。基于数组实现。
Stack:
Stack继承Vector的栈结构。
Vector简介
Vector 是矢量队列,它是JDK1.0版本添加的类。继承于AbstractList,实现了List, RandomAccess, Cloneable这些接口。
Vector 继承了AbstractList,实现了List;所以,它是一个队列,支持相关的添加、删除、修改、遍历等功能。
Vector 实现了RandmoAccess接口,即提供了随机访问功能。RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在Vector中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。
Vector 实现了Cloneable接口,即实现clone()函数。它能被克隆。
和ArrayList不同,Vector中的操作是线程安全的;
历史:
其实ArrayListhe和Vector在用法上完全相同.但由于Vector是一个古老的集合.(从jdk1.0就有了),那时候java还没有提供系统的集合框架,所以在Vector里提供了一些方法名很长的方法.例如:addElement(Object obj),实际上这个方法和add(Object obj)没什么区别.
从jdk1.2以后,Java提供了系统的集合框架,就将Vector改为实现List接口,作为List的实现之一,从而导致Vector里有一些重复的方法.
Vector里有一些功能重复的方法,这些方法中方法名更短的是属于后来新增的方法.更长的是原先vector的方法.而后来ArrayList是作为List的主要实现类.看过的Java思想编程中也提到了Vector有很多缺点.尽量少用Vector实现类.
第2部分 Stack
public class Stack<E>extends Vector<E>
由于Vector是通过数组实现的,这就意味着,Stack也是通过数组实现的,而非链表。
Stack类表示后进先出(LIFO)的对象堆栈。它通过五个操作对类Vector进行了扩展 ,允许将向量视为堆栈。它提供了通常的push和pop操作,以及取堆栈顶点的peek方法、测试堆栈是否为空的empty方法、在堆栈中查找项并确定到堆栈顶距离的search方法。
首次创建堆栈时,它不包含项。
Deque 接口及其实现提供了 LIFO 堆栈操作的更完整和更一致的 set,应该优先使用此 set,而非此类。例如:
Deque<Integer> stack = new ArrayDeque<Integer>();
从以下版本开始: JDK1.0
第三部分 结论
这两个都是jdk1.0的过时API,应该避免使用.因此不再对其源码进行解析学习.
jdk1.5新增了很多多线程情况下使用的集合类.位于java.util.concurrent.
如果你说,Vector是同步的,你要在多线程使用.那你应该使用java.util.concurrent.CopyOnWriteArrayList等而不是Vector.
如果你要使用Stack做类似的业务.那么非线程的你可以选择linkedList,多线程情况你可以选择java.util.concurrent.ConcurrentLinkedDeque 或者java.util.concurrent.ConcurrentLinkedQueue
多线程情况下,应尽量使用java.util.concurrent包下的类.
使用多种方式遍历集合
以ArrayList做例子
1 import java.util.*; 2 3 public class Test{ 4 public static void main(String[] args) { 5 List<String> list=new ArrayList<String>(); 6 list.add("Hello"); 7 list.add("World"); 8 list.add("HAHAHAHA"); 9 //第一种遍历方法使用 For-Each 遍历 List 10 for (String str : list) { //也可以改写 for(int i=0;i<list.size();i++) 这种形式 11 System.out.println(str); 12 } 13 14 //第二种遍历,把链表变为数组相关的内容进行遍历 15 String[] strArray=new String[list.size()]; 16 list.toArray(strArray); 17 for(int i=0;i<strArray.length;i++) //这里也可以改写为 for(String str:strArray) 这种形式 18 { 19 System.out.println(strArray[i]); 20 } 21 22 //第三种遍历 使用迭代器进行相关遍历 23 24 Iterator<String> ite=list.iterator(); 25 while(ite.hasNext())//判断下一个元素之后有值 26 { 27 System.out.println(ite.next()); 28 } 29 } 30 }
遍历map例子
1 import java.util.*; 2 3 public class Test{ 4 public static void main(String[] args) { 5 Map<String, String> map = new HashMap<String, String>(); 6 map.put("1", "value1"); 7 map.put("2", "value2"); 8 map.put("3", "value3"); 9 10 //第一种:普遍使用,二次取值 11 System.out.println("通过Map.keySet遍历key和value:"); 12 for (String key : map.keySet()) { 13 System.out.println("key= "+ key + " and value= " + map.get(key)); 14 } 15 16 //第二种 17 System.out.println("通过Map.entrySet使用iterator遍历key和value:"); 18 Iterator<Map.Entry<String, String>> it = map.entrySet().iterator(); 19 while (it.hasNext()) { 20 Map.Entry<String, String> entry = it.next(); 21 System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue()); 22 } 23 24 //第三种:推荐,尤其是容量大时 25 System.out.println("通过Map.entrySet遍历key和value"); 26 for (Map.Entry<String, String> entry : map.entrySet()) { 27 System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue()); 28 } 29 30 //第四种 31 System.out.println("通过Map.values()遍历所有的value,但不能遍历key"); 32 for (String v : map.values()) { 33 System.out.println("value= " + v); 34 } 35 } 36 }
迭代器的使用和工作原理
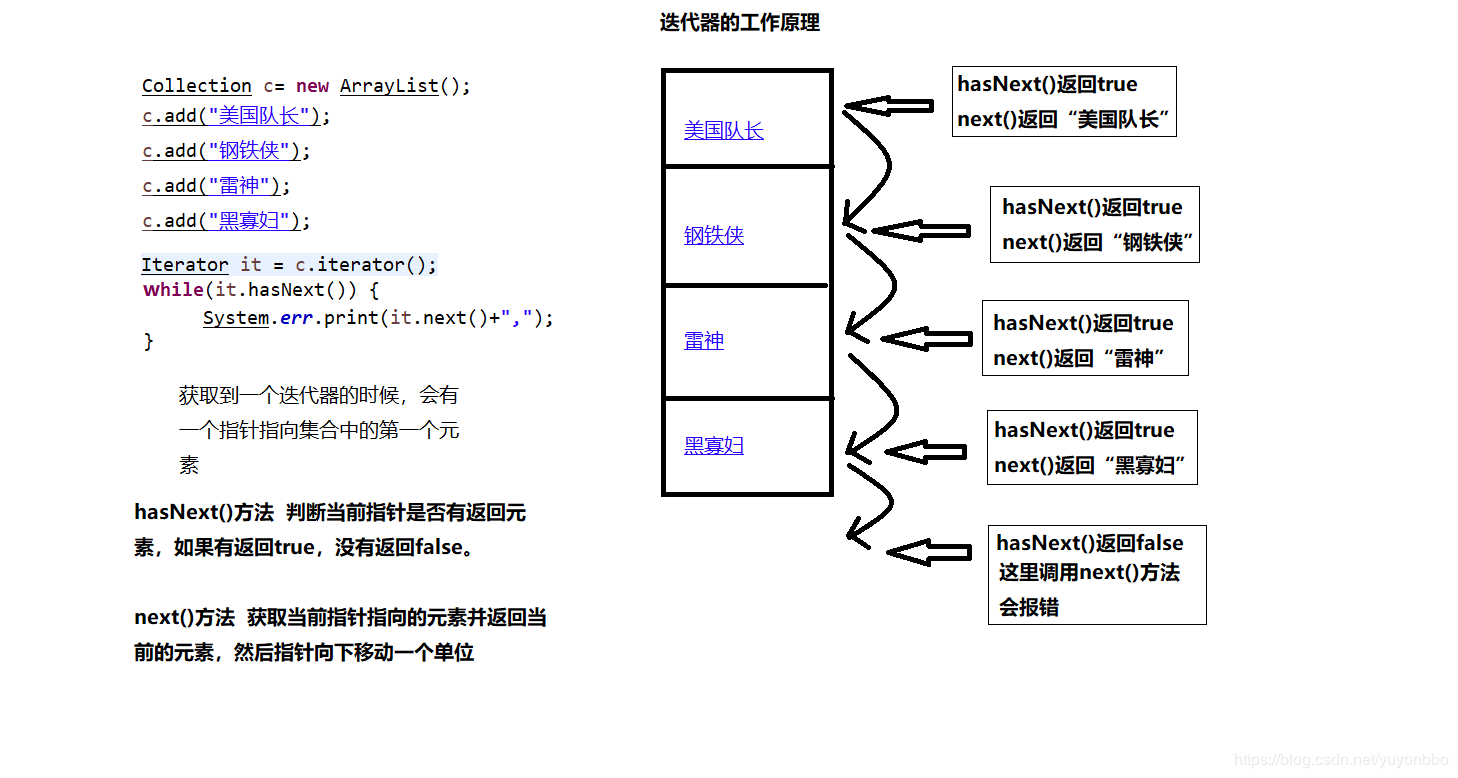
1 //创建一个单列集合 2 //LinkedList链表集合 3 //List接口 4 //创建一个指向自己接口的引用对象,创建了LinkedList类的对象后把它上溯到了list接口,现在它是list的对象,多态的实现。 5 List list=new LinkedList(); 6 7 list.add("1"); 8 list.add("2"); 9 list.add("3"); 10 11 //获取当前集合的迭代器 12 Iterator it =list.iterator(); 13 14 //第一种 While循环 15 16 //判断迭代器下一个位置上有木有元素 17 18 while(it.hasNext()){ 19 20 //返回当前迭代的元素 21 22 System.out.println(it.next()); 23 24 } 25 26 //第二种for循环 27 28 //判断迭代器下一个位置上有木有元素 29 30 for(;it.hasNext();){ 31 32 //返回当前迭代的元素 33 34 System.out.println(it.next()); 35 36 }
如果用迭代器 的话,建议用While循环写,如果用for循环写,对内存的优化不够。
it.remove();//删除当前迭代器指向的元素。最后打印长度为0。 重点:进行remove之前 必须调用it.next();方法,因为这个方法是删除当前迭代器指向的元素
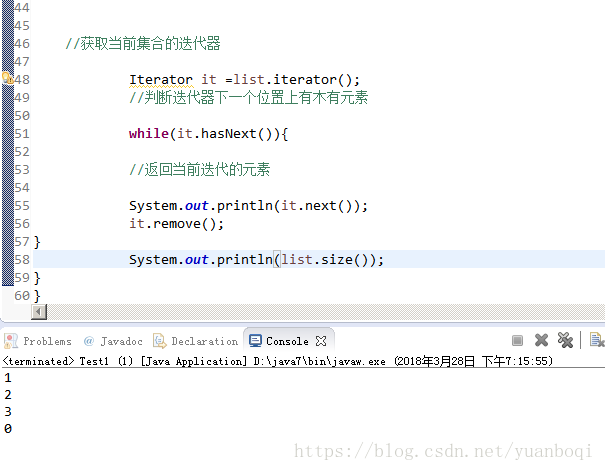
//在迭代器迭代的过程中不允许对迭代器对象进行任何操作,否则会引发安全隐患
1 package com.test; 2 3 import java.util.ArrayList; 4 import java.util.List; 5 import java.util.ListIterator; 6 7 // 迭代器在变量元素的时候要注意事项: 8 // 在迭代器迭代元素的过程中,不允许使用集合对象改变集合中的元素的个数(也就是添加或者删除),可以进行修改 9 // 如果需要添加或者删除只能使用迭代器的方法进行操作 10 11 // 如果使用集合对象在迭代的过程中改变集合的元素个数,会出现异常 java.util.ConcurrentModificationException 12 13 // 迭代器迭代的过程:就是迭代器从创建开始,到最后一次使用的过程中。 14 15 public class Iter { 16 17 public static void main(String[] args) { 18 19 List list=new ArrayList(); 20 21 list.add("刘备"); 22 list.add("曹操"); 23 list.add("孙权"); 24 25 // ListIterator为List接口中特有的迭代器ListIterator,该迭代器继承Iterator 26 27 ListIterator it=list.listIterator(); 28 while(it.hasNext()) { 29 System.out.print(it.next()+","); 30 it.add("aaa"); //在迭代过程中,迭代器调用了添加方法,会将迭代器的指针向下移动一个单位。为了防止死循环 31 //list.add("bbb"); //在迭代过程中,不能用集合对象对集合进行修改,会直接抛出异常( java.util.ConcurrentModificationException) 32 } // 刘备,曹操,孙权, 33 System.out.println(); 34 35 System.out.println(list); //[刘备, aaa, 曹操, aaa, 孙权, aaa] 36 37 ListIterator it2=list.listIterator(); 38 it2.next(); //最后一次使用 39 list.add("aaa"); //这种写法可以 40 System.out.println(list); //[刘备, aaa, aaa, 曹操, aaa, 孙权, aaa] 41 42 ListIterator it3=list.listIterator(); 43 list.add("aaa"); //这种写法不可以,因为在迭代过程中使用了集合对象改变了集合元素的个数 44 it3.next(); //最后一次使用 45 System.out.println(list); //[刘备, aaa, aaa, 曹操, aaa, 孙权, aaa] 46 47 48 } 49 50 }
HashSet和LinkedHashSet各自的工作原理分析
上来先了解一下HashSet这东西是个什么来头
1 public class HashSet<E> 2 extends AbstractSet<E> 3 implements Set<E>, Cloneable, java.io.Serializable{...}
继承自AbstractSet抽象类,实现了Set接口。该集合内无重复元素且遍历是无序的。基本操作就是add跟remove那些方法,基本不变。
成员变量跟构造方法
1 static final long serialVersionUID = -5024744406713321676L; 2 3 private transient HashMap<E,Object> map; 4 5 // Dummy value to associate with an Object in the backing Map 6 private static final Object PRESENT = new Object();
1 public HashSet() { 2 map = new HashMap<>(); 3 } 4 public HashSet(int initialCapacity) { 5 map = new HashMap<>(initialCapacity); 6 } 7 public HashSet(int initialCapacity, float loadFactor) { 8 map = new HashMap<>(initialCapacity, loadFactor); 9 } 10 public HashSet(Collection<? extends E> c) { 11 map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16)); 12 addAll(c); 13 } 14 HashSet(int initialCapacity, float loadFactor, boolean dummy) { 15 map = new LinkedHashMap<>(initialCapacity, loadFactor); 16 }
HashSet的底层由一个HashMap来实现,默认大小为0,而参数为集合的时候,默认大小会在集合数量与0.75的倍数加1,同16之间取最大值;且其增删查改都是基于内部维护的HashMap来做对应的操作。因为其底层基于HashMap,可以确定HashSet的遍历也是无序的。但是这样子我们就由疑问了,HashMap允许空键(当然只允许存在一个),也允许不同键内多个空值,但是HashSet只允许非重复元素呀。如果是这样的话,衍生了4个问题:那如果说HashSet的底层是HashMap的话,究竟我们add方法执行的时候,存的元素是在key-value的哪一个?怎样存?怎样避免重复值保存?还有那HashSet允许空值么?我们带着这个问题来看add方法
怎么实现的无重复元素
我们点开add方法一脸的思密达,于是我们再看了看remove。
1 public boolean add(E e) { 2 return map.put(e, PRESENT)==null; 3 } 4 public boolean remove(Object o) { 5 return map.remove(o)==PRESENT; 6 }
此时我颤抖的嘴角强行微笑,因为,他真的是用map来操作,足见第一二个问题的答案,HashSet调用add方法其实就是将元素作为key,将HashSet内部维护的一个标示对象存入map中,但是这里的比较是否等于null是几个意思?就这样来实现去重判断?
这里我们需要回顾一下HashMap的put方法,因为HashSet本身就是对HashMap的又一层封装,如果不懂的需要回头去看一下我在《java HashMap 底层实现和源码分析》里面分享的内容。这里贴出HashMap的put方法。
1 public V put(K key, V value) { 2 if (table == EMPTY_TABLE) { 3 inflateTable(threshold); 4 } 5 if (key == null) 6 return putForNullKey(value); 7 int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key); 8 int i = indexFor(hash, table.length); 9 for (HashMapEntry<K,V> e = table[i]; e != null; e = e.next) { 10 Object k; 11 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { 12 V oldValue = e.value; 13 e.value = value; 14 e.recordAccess(this); 15 return oldValue; 16 } 17 } 18 19 modCount++; 20 addEntry(hash, key, value, i); 21 return null; 22 } 23 24 private V putForNullKey(V value) { 25 for (HashMapEntry<K,V> e = table[0]; e != null; e = e.next) { 26 if (e.key == null) { 27 V oldValue = e.value; 28 e.value = value; 29 e.recordAccess(this); 30 return oldValue; 31 } 32 } 33 modCount++; 34 addEntry(0, null, value, 0); 35 return null; 36 } 37 38 void addEntry(int hash, K key, V value, int bucketIndex) { 39 if ((size >= threshold) && (null != table[bucketIndex])) { 40 resize(2 * table.length); 41 hash = (null != key) ? sun.misc.Hashing.singleWordWangJenkinsHash(key) : 0; 42 bucketIndex = indexFor(hash, table.length); 43 } 44 45 createEntry(hash, key, value, bucketIndex); 46 } 47 48 void createEntry(int hash, K key, V value, int bucketIndex) { 49 HashMapEntry<K,V> e = table[bucketIndex]; 50 table[bucketIndex] = new HashMapEntry<>(hash, key, value, e); 51 size++; 52 }
到这里,我们可以看到,HashMap在做put操作的时候,其实是已经做对应结果返回了。
如果是未存在的key,那么就创建Entry单向链表保存value值(只是在HashSet的环境下我们只关注key就可以,value的值是什么无意义),创建完成返回null;如果是已经存在的key,那么就修改该key对应的hash值在哈希table中的下标Entry,最后返回旧值。
第三个问题的答案便是:HashSet只需要根据HashMap返回的结果,就可以知道现在add所传的对象是否已经存在,并将结果返回。所以,即使HashSet调用add方法返回了false,其实内部交由HashMap去执行时候也是执行过一次put操作了,只是插入的值没有变而已
最后一个问题我想大家也都猜到了,HashSet允许用add插入null值。
感觉HashSet寥寥数言,这里顺便介绍下LinkedHashSet吧
LinkedHashSet
不错,唯一成员就是序列化的id
1 private static final long serialVersionUID = -2851667679971038690L;
剩下的就是构造函数
1 public LinkedHashSet(int initialCapacity, float loadFactor) { 2 super(initialCapacity, loadFactor, true); 3 } 4 public LinkedHashSet(int initialCapacity) { 5 super(initialCapacity, .75f, true); 6 } 7 public LinkedHashSet() { 8 super(16, .75f, true); 9 } 10 public LinkedHashSet(Collection<? extends E> c) { 11 super(Math.max(2*c.size(), 11), .75f, true); 12 addAll(c); 13 }
可以确定的是,对内部维护的HashMap的加载因子是使用默认的0.75,且默认的Entry数组大小根据不同的情况确定,无参则是16,有参则是在集合数量的2倍,同11之间取最大值
更多源码分析:https://blog.csdn.net/learningcoding/article/details/79983248 (这个源码有注释)
Collections工具类的使用
排序操作
Collections提供以下方法对List进行排序操作
void reverse(List list):反转
void shuffle(List list),随机排序
void sort(List list),按自然排序的升序排序
void sort(List list, Comparator c);定制排序,由Comparator控制排序逻辑
void swap(List list, int i , int j),交换两个索引位置的元素
void rotate(List list, int distance),旋转。当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将 list的前distance个元素整体移到后面。
下面简单演示Collections操作List
1 package collection; 2 3 import java.util.ArrayList; 4 import java.util.Collections; 5 import java.util.Comparator; 6 7 public class CollectionsTest { 8 public static void main(String[] args) { 9 ArrayList nums = new ArrayList(); 10 nums.add(8); 11 nums.add(-3); 12 nums.add(2); 13 nums.add(9); 14 nums.add(-2); 15 System.out.println(nums); 16 Collections.reverse(nums); 17 System.out.println(nums); 18 Collections.sort(nums); 19 System.out.println(nums); 20 Collections.shuffle(nums); 21 System.out.println(nums); 22 //下面只是为了演示定制排序的用法,将int类型转成string进行比较 23 Collections.sort(nums, new Comparator() { 24 25 @Override 26 public int compare(Object o1, Object o2) { 27 // TODO Auto-generated method stub 28 String s1 = String.valueOf(o1); 29 String s2 = String.valueOf(o2); 30 return s1.compareTo(s2); 31 } 32 33 }); 34 System.out.println(nums); 35 } 36 }
执行结果,
1 [8, -3, 2, 9, -2] 2 [-2, 9, 2, -3, 8] 3 [-3, -2, 2, 8, 9] 4 [9, -2, 8, 2, -3] 5 [-2, -3, 2, 8, 9]
查找,替换操作
int binarySearch(List list, Object key), 对List进行二分查找,返回索引,注意List必须是有序的
int max(Collection coll),根据元素的自然顺序,返回最大的元素。 类比int min(Collection coll)
int max(Collection coll, Comparator c),根据定制排序,返回最大元素,排序规则由Comparatator类控制。类比int min(Collection coll, Comparator c)
void fill(List list, Object obj),用元素obj填充list中所有元素
int frequency(Collection c, Object o),统计元素出现次数
int indexOfSubList(List list, List target), 统计targe在list中第一次出现的索引,找不到则返回-1,类比int lastIndexOfSubList(List source, list target).
boolean replaceAll(List list, Object oldVal, Object newVal), 用新元素替换旧元素。
下面示范简单用法,
1 package collection.collections; 2 3 import java.util.ArrayList; 4 import java.util.Collections; 5 6 public class CollectionsTest { 7 public static void main(String[] args) { 8 ArrayList num = new ArrayList(); 9 num.add(3); 10 num.add(-1); 11 num.add(-5); 12 num.add(10); 13 System.out.println(num); 14 System.out.println(Collections.max(num)); 15 System.out.println(Collections.min(num)); 16 Collections.replaceAll(num, -1, -7); 17 System.out.println(Collections.frequency(num, 3)); 18 Collections.sort(num); 19 System.out.println(Collections.binarySearch(num, -5)); 20 } 21 }
执行结果,
1 [3, -1, -5, 10] 2 10 3 -5 4 1 5 1
同步控制
Collections中几乎对每个集合都定义了同步控制方法,例如 SynchronizedList(), SynchronizedSet()等方法,来将集合包装成线程安全的集合。下面是Collections将普通集合包装成线程安全集合的用法,
1 package collection.collections; 2 3 import java.util.ArrayList; 4 import java.util.Collection; 5 import java.util.Collections; 6 import java.util.HashMap; 7 import java.util.HashSet; 8 import java.util.List; 9 import java.util.Map; 10 import java.util.Set; 11 12 public class SynchronizedTest { 13 public static void main(String[] args) { 14 Collection c = Collections.synchronizedCollection(new ArrayList()); 15 List list = Collections.synchronizedList(new ArrayList()); 16 Set s = Collections.synchronizedSet(new HashSet()); 17 Map m = Collections.synchronizedMap(new HashMap()); 18 } 19 }
设置不可变(只读)集合
Collections提供了三类方法返回一个不可变集合,
emptyXXX(),返回一个空的只读集合(这不知用意何在?)
singleXXX(),返回一个只包含指定对象,只有一个元素,只读的集合。
unmodifiablleXXX(),返回指定集合对象的只读视图。
用法如下,
1 package collection.collections; 2 3 import java.util.Collection; 4 import java.util.Collections; 5 import java.util.HashMap; 6 import java.util.List; 7 import java.util.Map; 8 import java.util.Set; 9 10 public class UnmodifiableCollection { 11 public static void main(String[] args) { 12 List lt = Collections.emptyList(); 13 Set st = Collections.singleton("avs"); 14 15 Map mp = new HashMap(); 16 mp.put("a",100); 17 mp.put("b", 200); 18 mp.put("c",150); 19 Map readOnlyMap = Collections.unmodifiableMap(mp); 20 21 //下面会报错 22 lt.add(100); 23 st.add("sdf"); 24 mp.put("d", 300); 25 } 26 }
执行结果,
1 Exception in thread "main" java.lang.UnsupportedOperationException 2 at java.util.AbstractList.add(Unknown Source) 3 at java.util.AbstractList.add(Unknown Source) 4 at collection.collections.UnmodifiableCollection.main(UnmodifiableCollection.java:22)
参考网址:
集合:https://blog.csdn.net/zhangqunshuai/article/details/80660974
arraylist与linkedList各自的工作原理:https://blog.csdn.net/Summer_Lyf/article/details/88048505
Vector和Stack:https://blog.csdn.net/For_Forever/article/details/82936534
https://www.cnblogs.com/devin-ou/p/7989451.html
遍历:https://www.runoob.com/java/java-collections.html
迭代器:https://blog.csdn.net/yuanboqi/article/details/79732122
https://blog.csdn.net/yuyonbbo/article/details/89601943
HashSet和LinkedHashSet各自的工作原理分析:https://blog.csdn.net/Arthurs_L/article/details/81516750
Collections工具类的使用:https://www.cnblogs.com/fysola/p/6021134.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号