mongoDB-使用总结($group 、$unwind、$cond等)
1.按年分库表联合查询
db.collection_2023_3.aggregate(
{$set:{_id:'2023_3'}},
{$unionWith:{coll:'collection_2023_4',pipeline:[ { $set: { _id: "2023_4" } } ]}}
)
2.多字段分组
{
$group: {
_id: {
data_time: '$data_time',
isoWeek: '$isoWeek'
},
sum_pnum: {
$sum: '$pnum'
}
}
}
多字段分组时要给字段起别名,当第二次分组时再用到第一次分组的字段时,用’$_id.字段别名’
如:
db.collection_2023.aggregate(
{$set:{_id:'2023'}},
{$unionWith:{coll:'collection_2022',pipeline:[ { $set: { _id: "2022" } } ]}},
{$match:{sid:'S00002',p_type:{$in:[1,2,3]},data_time:{$gte:'2023-01-01',$lte:'2023-10-13'}}},
{$project:{data_time:'$data_time',year:{$substr:['$data_time',0,4]},pnum:1,tNum:1,stayTime:1}},
{$group:{_id:{data_time:'$data_time',year:'$year'},sum_pnum:{$sum:'$pnum'},sum_tNum:{$sum:'$tNum'},avg_stayTime:{$avg:'$stayTime'}}},
{$group:{_id:'$_id.year',sum_pnum:{$sum:'$sum_pnum'},sum_tNum:{$sum:'$sum_tNum'},avg_stayTime:{$avg:'$avg_stayTime'}}},
{$project:{data_time:1,sum_pnum:1,avg_stayTime:{$round:[{$divide:['$avg_stay_time',60]},2]},
jdlv:{$round:[{$divide:['$sum_pnum',{$add:['$sum_pnum','$sum_tNum']}]},4]}
}},
{$sort:{_id:1}}
)
3.多次分组,即一个查询中写多个$group
不同身份(p_type)的pnum要按日求和,按周时要每日平均
db.collection_2023.aggregate(
{$set:{_id:'2023'}},
{$unionWith:{coll:'collection_2022',pipeline:[ { $set: { _id: "2022" } } ]}},
{$match:{sid:'S001',p_type:{$in:[2,3,4]},data_time:{$gte:'2023-01-01',$lte:'2023-10-13'}}},
{$project:{data_time:'$data_time',isoWeek:{$isoWeek:{date:{"$dateFromString":{"dateString":"$data_time"}},"timezone":"Asia/Shanghai"}},pnum:1,cnum:1}},
{$group:{_id:{data_time:'$data_time',isoWeek:'$isoWeek'},sum_pnum:{$sum:'$pnum'}}},
{$group:{_id:'$_id.isoWeek',sum_pnum:{$sum:'$sum_pnum'},avg_pnum:{$avg:'$sum_pnum'}}},
{$project:{_id:1,sum_pnum:1,avg_pnum:{$round:['$avg_pnum',0]}}},
{$sort:{_id:1}}
)
注,一个查询中可以出现多次match和project,match和project可出现在group之前,也可以出现在group之后
4.数组展开 $unwind
使用数组的值,$数组名.字段名
db.collection_2023.aggregate(
{$set:{_id:'2023'}},
{$unionWith:{coll:'collection_2022',pipeline:[ { $set: { _id: "2022" } } ]}},
{$match:{pid:'S001',data_time:{$gte:'2022-12-02',$lte:'2023-10-08'}}},
{$unwind:'$stay_time_datas'},
{$group:{_id:'$stay_time_datas.stay_time_label',sum_cnum:{$sum:'$stay_time_datas.cnum'}}},
{$project:{_id:1,sum_cnum:'$sum_cnum'}},
{$sort:{_id:1}}
)
5.使用对象的值

使用对象的属性,$对象名.属性名
db.collection_2023.aggregate(
{$match:{pid:'S001',data_time:{$gte:'2023-01-01',$lte:'2023-03-13'}}},
{$group:{_id:'$data_time',one:{$sum:'$peer.one'},two:{$sum:'$peer.two'},three:{$sum:'$peer.three'},four_or_more:{$sum:'$peer.four_or_more'}}},
{$sort:{_id:1}}
)
多字段排序,如{$sort:{pid:1,month:1}}
6.group分组之后可取$max $min $sum $avg $first第一个 $last最后一个
$max 最大值
$min 最小值
$sum 求和
$avg 求均值
$first第一个
$last最后一个
如:取最大值
{$group:{_id:'',MaxModifytime:{$max:'$modify_time'}}}
如:$first第一个
db.collection.aggregate(
{$match:{cid:'320100',ptime:{$gte:'2023-05-01 00:00:00',$lte:'2023-07-13 23:59:59'}}},
{$sort:{ptime:-1}},
{$group:{_id:{date1:{$substr:['$ptime',0,10]}},value:{$first:"$value"}}},
{$project:{_id:'$_id.date1',pubtime:1,value:1}},
{$sort:{_id:1}}
)
注,sort也可以出现多次,可出现在任何位置
7.逻辑运算符 $not $and $or $nor
$not非
$and与
$or或
$nor 多个条件中一个也不符合
--$not
db.user.find({age:{$ne:18}})
db.user.find({age:{$not:{$eq:18}}})
--$or
'$or':[
{sre:{$in:['2']}},
{tgt:{$in:['2']}}
]
--'$nor
'$nor':[
{sre:{$in:['18','19','20','21']}},
{tgt:{$in:['18','19','20','21']}}
]
{$match:{dt:{$gte:'2023-08-05',$lte:'2023-09-28'},sid:'S00001',
'$or':[
{sre:{$in:['2']}},
{tgt:{$in:['2']}}
],
'$nor':[
{sre:{$in:['18','19','20','21']}},
{tgt:{$in:['18','19','20','21']}}
],
sex:{$in:[0,1]},
}}
$and 同理
8.$cond聚合分析的条件操作
有两种语法
{ $cond: { if: <boolean-expression>, then: <true-case>, else: <false-case> } }
或:
{ $cond: { if: <boolean-expression>, then: <true-case>, else: <false-case> } }
如果<boolean-expression>条件为true,则执行<true-case>,否则执行<false-case>
{ "_id" : 1, "item" : "abc1", qty: 300 }
{ "_id" : 2, "item" : "abc2", qty: 200 }
{ "_id" : 3, "item" : "xyz1", qty: 250 }
db.inventory.aggregate(
[
{
$project:
{
item: 1,
discount:
{
$cond: { if: { $gte: [ "$qty", 250 ] }, then: 30, else: 20 }
}
}
}
]
)
>>结果:
{ "_id" : 1, "item" : "abc1", "discount" : 30 }
{ "_id" : 2, "item" : "abc2", "discount" : 20 }
{ "_id" : 3, "item" : "xyz1", "discount" : 30 }
9.数学运算符 加减乘除、取余 $add $subtract $multiply $divide $mod
$add 加 { $add: [ <expression1>, <expression2>, ... ] }
$subtract 减 { $subtract: [ <expression1>, <expression2> ] }
$multiply乘 { $multiply: [ <expression1>, <expression2>, ... ] }
$divide 除 { $divide: [ <expression1>, <expression2> ] }
$mod 取余 { $mod: [ <expression1>, <expression2> ] }
jdlv:{$round:[{$divide:['$pnum',{$add:['$pnum','$tNum']}]},4]}
jkl:{$round:[{$divide:['$sum_pnum',{$multiply:[56,5]}]},2]}
10.$strLenCP
$strLenCP 是aggregate的一个管道符返回UTF-8编码下的字符数,每个字符均计数为1
{ $strLenCP: <string expression> }
{ $strLenCP: "Hello World!" } 12
{ $strLenCP: "" } 0
{ $strLenCP: "寿司" } 2
11.$size 计算数组长度
db.collection.find( { field: { $size: 2 } } );
12.更改字段值
更改数组中字段的值:
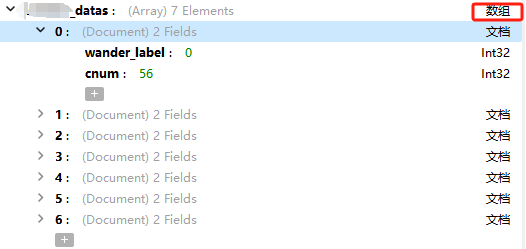
将该数组的中wander_label 为6的cnum值更改成33
db.collection.update( {rid:'P00001',type:{$in:[0]},data_time:{$gte:'2023-10-07'},'w_datas.wander_label':6}, {$set:{'w_datas.$.cnum':33}} )
更改对象的值:

将peer对象中one字段的值更改成121
db.collection.update( {rid:'P00001',type:{$in:[0]},data_time:{$gte:'2023-10-07'}}, {$set:{'peer.one':121}} )
13.正则表达式 $regex
查询rid以P00001开头的记录 db.collection.aggregate( {$match:{rid:{$regex:/^P00001/}}} ) 查询rid以S00401结尾的所有记录(相当于like '%S00401') db.collection.aggregate( {$match:{rid:{$regex:/S00401$/}}} )
{$regex:/^P00001/} 以P00001开头
{$regex:/^P00001/i} 以P00001开头,或以p0001开头,i表示忽略大小写
{$regex:/S00401$/} 相当于like '%S00401'
{$regex:/S00401$/i} 相当于like '%S00401',或like '%s00401',i表示忽略大小写
14.分组后求字段个数(先使用$addToSet将字段存入set集合,再对set求长度$size)
db.collection_2024_3.aggregate {$unwind:'$s_f_d'}, {$project:{sre:'$s_f_d.sre',site_id:'$s_f_d.id',tgt:'$s_f_d.tgt',p_id:'$p_id',dt:'$dt'}}, {$match:{dt:{$gte:'2024-03-14',$lte:'2024-04-05'}, tgt:{$in:['unkn','101','102','103','104','105']}, site_id:{$in:['unkn','101','102','103','104','105']}, sre:'101' }}, {$group:{_id:{sre:'$sre',site_id:'$site_id',tgt:'$tgt'},p_set:{$addToSet:'$p_id'}}}, {$project:{_id:0,sre:'$_id.sre',site_id:'$_id.site_id',tgt:'$_id.tgt',personNum:{$size:'$p_set'}}} )
需求是要按照sre,site_id,tgt分组,然后统计p_id的个数
MongoDB中没有直接personNum:{$sum:'$p_id'}或者personNum:{$count:'$p_id'},所以不能直接拿到字段次数,
若如果使用分组统计行数 {$group:{_id:{sre:'$sre',site_id:'$site_id',tgt:'$tgt'},personNum:{$sum:1}}},
personNum:{$sum:1}是统计出现的行数,可能会有重复的情况,故不能直接统计行数,采用以下思路:
分组后使用p_set:{$addToSet:'$p_id'},将出现的p_id存入set集合,该集合无序不重复,做到了去重的目的,再使用personNum:{$size:'$p_set'},
求set的长度,从而获得分组后的字段个数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号