关于MongoDB数据库-增删改查
一、数据库简介
非关系性数据库:
文档document:相当于关系数据库中的一行记录。
集合collection:多个文档组成一个集合,相当于关系数据库中的一张表。
数据库database:多个集合组织构成数据库
为了帮助理解,mongoDB与关系型数据库的对比,如下图:

可使用客户端工具NoSQL Manager for MongoDB访问MongoDB数据库。
1、日期格式
Date()
显示当前的时间
new Date()
构建一个格林尼治时间 可以看到正好和Date()相差8小时,我们是+8时区,也就是时差相差8,所以+8小时就是系统当前时间
ISODate()
也是格林尼治时间
> Date()
Wed Jul 22 2020 18:38:50 GMT+0800
> new Date()
ISODate("2020-07-22T10:42:58.868Z")
> ISODate()
ISODate("2020-07-22T10:46:26.137Z")
db.report_traffic_site_hour.insert({relationid:'aaa',datatime:Date(),innum:300})
{
"_id" : ObjectId("5f18186f392a971272ac9328"),
"relationid" : "aaa",
"datatime" : "Wed Jul 22 2020 18:43:59 GMT+0800",
"innum" : 300.0
}
db.report_traffic_site_hour.insert({relationid:'aaa',datatime:new Date(),innum:200})
{
"_id" : ObjectId("5f181832392a971272ac9327"),
"relationid" : "aaa",
"datatime" : ISODate("2020-07-22T10:42:58.868Z"),
"innum" : 200.0
}
db.report_traffic_site_hour.insert({relationid:'aaa',datatime:ISODate(),innum:100})
{
"_id" : ObjectId("5f181902392a971272ac9329"),
"relationid" : "QBGC",
"datatime" : ISODate("2020-07-22T10:46:26.137Z"),
"innum" : 100.0
}
2、主键 _id
_id 是集合中文档的主键;
_id自动编入索引;
默认情况下,_id 字段的类型为 ObjectID。如果需要,用户还可以将 _id 覆盖为 ObjectID 以外的其他内容。
ObjectID 长度为 12 字节,由几个 2-4 字节的链组成。每个链代表并指定文档身份的具体内容。以下的值构成了完整的 12 字节组合:
一个 4 字节的值,表示自 Unix 纪元以来的秒数
一个 3 字节的机器标识符
一个 2 字节的进程 ID
一个 3 字节的计数器,以随机值开始

通常,你不必担心要如何生成 ObjectID。如果文档尚未分配 _id 值,MongoDB 将自动生成一个 _id 值;
_id 字段基本上是不可变的。在创建文档之后,根据定义,它已被分配了一个无法更改的 _id。话虽如此,在插入新文档时是可以覆盖 _id 的。
二、NoSQL Manager for MongoDB工具页面简介
注:可参考https://www.pianshen.com/article/532179412/ NoSQL Manager for MongoDB 使用简单教程
以查询为例进行介绍:
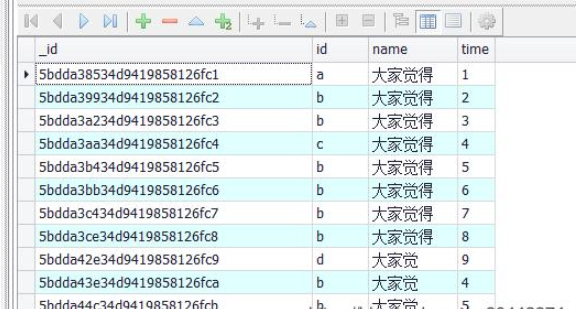
模拟数据如下
1、shell面板命令查询:
首先选中数据表,打开shell面板。
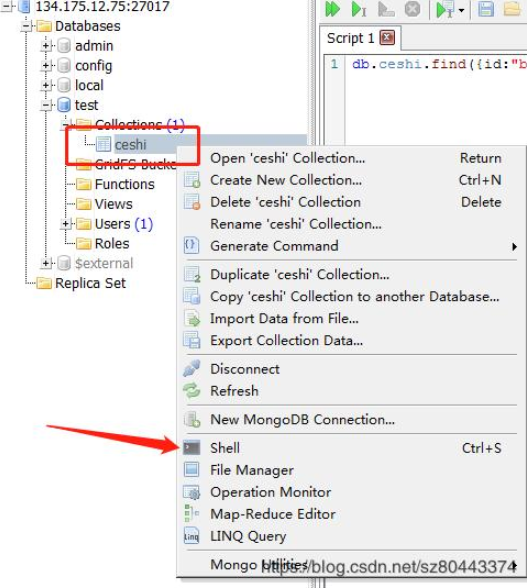
在shell面板中输入:
db.ceshi.find({id:"b",time:{$gte:"3"}},{_id:0}).limit(100).skip(0).sort({time:1})
查询结果如下:
#上面方法为查询id="b",time大于等于3,_id字段设置不显示(0不显示,1显示),限制100条,跳过前面的0条(skip),按time排序(1升序,0倒叙)
# 字段不用加引号
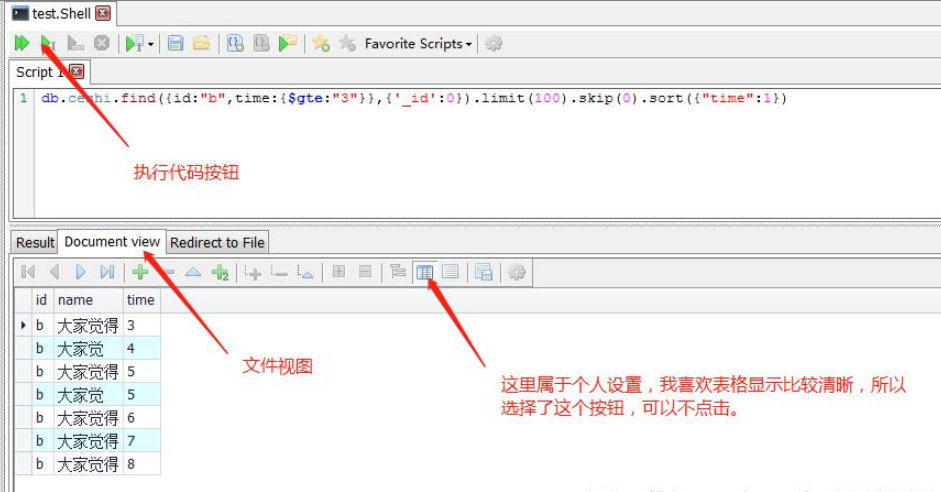
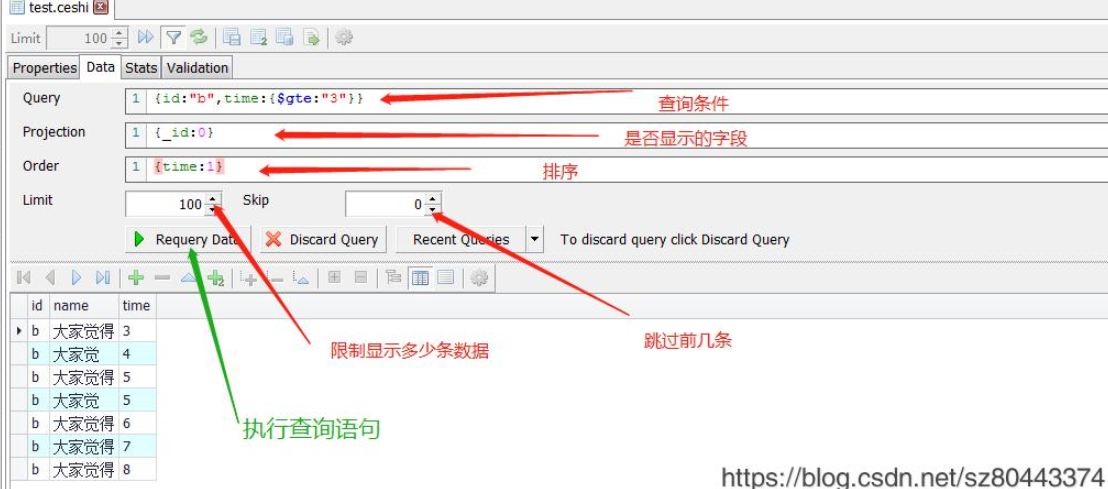
2、通过GUI来查询
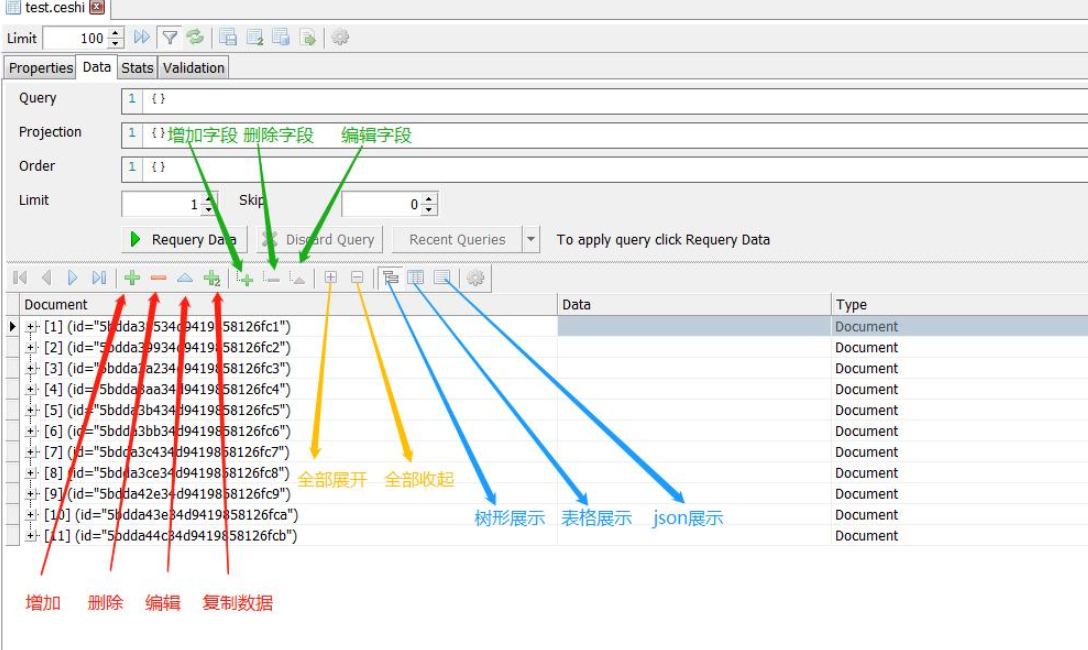
三、常用操作
增、删、改、查
注:可参考
https://www.cnblogs.com/jmcui/p/8858111.html
https://www.cnblogs.com/ywjfx/p/10129007.html
1、增加
语法: db.collectionName.insert(document)。
①不指定id,数据库会随机分配一个id
db.report_traffic_site_hour.insert({relationid:'aaa',datatime:ISODate('2020-07-14T09:00:00Z'),innum:8000});
②指定id
db.report_traffic_site_hour.insert({_id:'aaa#2020-07-14 18:00',relationid:'QBGC',datatime:ISODate('2020-07-14T10:00:00Z'),innum:2000})
③添加一个document
db.user.insert({_id:6,name:'zhaos',age:23,sex:'f'});
④添加多个document
db.user.insert({_id:7,name:'zhaos',age:23,sex:'f'},{_id:8,name:zpl,age:23,sex:'f'});
2、删除
语法: db.collection.remove(查询表达式, 选项)。
选项是指需要删除的文档数,{0/1},默认是0,删除全部文档。
例1:
db.report_traffic_site_hour.remove({relationid:'aaa',datatime:ISODate('2020-07-14T09:00:00Z')});
例2:
#只删除一个gender:'m'的s文档,num是指删除的文档数
db.user.remove({gender:'m',1})
3、修改
语法:
Update()方法
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
})
参数说明:
Query:查询条件
Update:更新语句
Upsert:可选,默认值是false。如果根据查询条件没找到对应的文档,如果设置为true,相当于执行insert,如果设置为false,不做任何的操作。
Multi:可选,默认false,只更新找到的第一条记录,如果为true,把查出来的多条记录全部更新
writeConcern:可选,跑出异常的级别
$inc 自增
$mul 乘
$rename 重命名
$setOnInsert
$set 用来指定一个键的值,如果不存在则创建它
$unset 用来指定一个键的值,如果不存在不创建创建它
$min 最小
$max 最大
$currentDate 当前时间
例1:
db.report_traffic_site_hour.update({relationid:'aaa',datatime:ISODate('2018-07-14T10:00:00Z')},{$set:{innum:5000}})
结果:WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
例2:
db.report_traffic_site_hour.update({relationid:'aaa',datatime:ISODate('2018-07-14T10:00:00Z')},{$inc:{innum:1000}})
结果:WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
4、查询
语法: db.collection.find(查询表达式,查询的列)
例1:
#查询所有文档
db.report_traffic_site_hour.find()
db.report_traffic_site_hour.find({relationid:'aaa'})
例2:
#查询QBGC,_id不显示,relationid,datatime,innum三列显示,0表示显示不显示该列,1表示显示该列
db.report_traffic_site_hour.find({relationid:'aaa'},{_id:0,relationid:1,datatime:1,innum:1})
$ne 不等于 db.user.find({age:{$ne:30}})
$gt 大于 db.user.find({age:{$gt:30}})
$gte 大于等于 db.user.find({age:{$gte:30}})
$lt 小于 db.user.find({age:{$lt:30}})
$lte 小于等于 db.user.find({age:{$lt:30}})
$in 在 db.user.find({age:{$in:[28,29,30]}})
$nin 不在 db.user.find({age:{$nin:[28,29,30]}})
$mod 语法: {field:{$mod:[ divisor(除数), remainder(余数)]}}
db.report_traffic_site_hour.find({innum:{$mod:[10,5]}})
$exists 语法:{field:{$exists:1}}
db.user.find({age:{$exists:1}}) 查询有age列的文档
$where 条件
查询innum 大于1000小于5000的文档
db.report_traffic_site_hour.find({$where:'this.innum>1000' && 'this.innum<5000'})
db.report_traffic_site_hour.find({relationid:'aaa',$where:'this.innum>1000' && 'this.innum<5000'}) 且
db.report_traffic_site_hour.find({relationid:'aaa',$where:'this.innum<1000' || 'this.innum>5000'}) 或
加法:$add 如:{$add:['$innum','$outnum']}
减法:$subtract
乘法:$multiply
除法:$divide
5、聚合函数
使用聚合框架可以对集合中的文档进行变换和组合。基本上,可以用多个构件创建一个管道(pipeline),用于对一连串的文档进行处理。这些构件包括筛选(filtering)、投射(projecting)、分组(grouping)、排序(sorting)、限制(limiting)和跳过(skipping)。
例:
db.driverLocation.aggregate(
{$match:{areaCode:'350203'}},
{$project:{driverUuid:1,uploadTime:1,positionType:1}}, {$group:{_id:{driverUuid:'$driverUuid',positionType:'$positionType'},uploadTime:{$first:{$year:'$uploadTime'}},count:{'$sum':1}}},
{$sort:{count:-1}},
{$limit:100},
{$skip:50}
)
① 筛选(filtering)—> $match
一般放在第一个,可快速将不需要的文档过滤掉,$match可以使用所有常规的查询操作符("$gt"、"$lt"、"$in"等)
② 投射(projecting)—> $project
可以通过指定 {"fieldname" : 1} 选择需要投射的字段,或者通过指定 { "fieldname":0 } 排除不需要的字段;
还可对字段起别名:db.users.aggregate({"$project" : {"userId":"$_id", "_id":0}})
③ 分组(grouping)—> $group
选定了需要进行分组的字段,就可以将选定的字段传递给"$group"函数的"_id"字段{$group:{_id:null,sum:{$sum:"$innum"}}}
如上,_id:null是没有分组字段,直接求innum字段的sum和,"$innum"是引用该字段,注意要加单引号或双引号
④ 限制(limiting)—> $limit
{$limit:100}返回结果集的前100个文档
⑤ 跳过(skipping)—> $skip
{$skip:50}跳过结果集的前50个文档
注意:$limit和$skip的顺序,如下
{$limit:100},{$skip:50} 返回结果集的前100个,然后在此基础上再跳过这100个的前50个,最后返回的是50个文档
{$skip:50},{$limit:100} 先跳过结果集的前50个,然后在此基础上再限制100个,最后返回的是100个文档
拆分(unwind)—> $unwind
可以将数组中的每一个值拆分为单独的文档。
例如文档:{ "_id" : 1, "item" : "ABC1", sizes: [ "S", "M", "L"] }
聚合运算:db.inventory.aggregate( [ { $unwind : "$sizes" } ] )
结果:
{ "_id" : 1, "item" : "ABC1", "sizes" : "S" }
{ "_id" : 1, "item" : "ABC1", "sizes" : "M" }
{ "_id" : 1, "item" : "ABC1", "sizes" : "L" }
1、分组操作符:
{$sum : value} 对于分组中的每一个文档,将value与计算结果相加。
{$avg : value} 返回每个分组的平均值
{$max : expr} 返回分组内的最大值。
{$min : expr} 返回分组内的最小值。
{$first : expr} 返回分组的第一个值,忽略后面所有值。只有排序之后,明确知道数据顺序时这个操作才有意义。
{$last : expr} 与"$first"相反,返回分组的最后一个值。
字符串表达式:
适用于单个文档的运算
{$substr : [expr, startOffset, numToReturn]} 其中第一个参数expr必须是个字符串,这个操作会截取这个字符串的子串(从第startOffset字节开始的numToReturn字节,注意,是字节,不是字符。在多字节编码中尤其要注意这一点)expr必须是字符串。
{$concat : [expr1, expr2, ..., exprN]]} 将给定的表达式(或者字符串)连接在一起作为返回结果。
{$toLower : expr} 参数expr必须是个字符串值,这个操作返回expr的小写形式。
{$toUpper : expr} 参数expr必须是个字符串值,这个操作返回expr的大写形式。
2、逻辑操作符 $or, $and, $nor, $not
$or 或
语法:{$or: [ {<expression1>}, {<expression2>}, ... , {<expressionN>} ] }
db.report_traffic_site_hour.find({$or:[{relationid:'bbb'},{relationid:'ccc'},{relationid:'aaa'}]})
类似:db.report_traffic_site_hour.find({relationid:{$in:['bbb','ccc','aaa']}})
注意$or和 $in 的区别,$or后面是两个或两个以上表达式,$in后面是数组;
$and 且
语法:{$and: [ {<expression1>}, {<expression2>}, ... , {<expressionN>} ] }
db.report_traffic_site_hour.find({$or:[{relationid:'bbb'},{innum:
5000}]})
db.inventory.find({$and:[{ price:{$ne:1.99}},{price: {$exists: true}}]})
$nor 都不是
语法:{$nor: [ {<expression1>}, {<expression2>}, ... , {<expressionN>} ] }
db.report_traffic_site_hour.find({$nor:[{relationid:'bbb'},{relationid:'ccc'},{relationid:'aaa'}]})
$not 非
语法: { field: { $not: {<operator-expression>} } }
db.inventory.find({price:{$not:{$gt:1.99}}})
3、日期表达式
$ifNull 如果为空
{$ifNull : [expr, replacementExpr]} 如果expr是null,返回replacementExpr,否则返回expr
日期表达式
适用于单个文档的运算
{$year: "$date" } 返回日期的年份部分
{$month: "$date" } 返回日期的月份部分
{$dayOfMonth: "$date" } 返回日期的天部分
{$hour: "$date" } 返回日期的小时部分
{$minute: "$date" } 返回日期的分钟部分
{$second: "$date" } 返回日期的秒部分
{$millisecond: "$date" } 返回日期的毫秒部分
{$dayOfYear: "$date" } 一年中的第几天
{$dayOfWeek: "$date" } 一周中的第几天,between 1 (Sunday) and 7 (Saturday).
{$week: "$date" } 以0到53之间的数字返回一年中日期的周数。周从星期日开始,第一周从一年中的第一个星期天开始。一年中第一个星期日之前的日子是在第0周。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号