django 实现读写分离
- 主要目的:单个数据库进行读写操作频繁,降低速度,增加服务器读写数据库压力,为了解决这一问题,对数据库进行读写分离,将大大提升项目的性能。其基本原理是:
- 让主数据库处理事务性的增删改查,而从数据库处理查询操作,当主数据库因一些事务性操作导致数据变更后,同步更新到其他读库。写库一个,读库可以有多个。采用日志同步的方式实现主从同步。
-
在Django的配置文件settings.py中,DATABASES中添加代码如下:
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'HOST': '127.0.0.1', # 主服务器的运行ip 'PORT': 3306, # 主服务器的运行port 'USER': 'django', # 主服务器的用户名 'PASSWORD': 'django', # 主服务器的密码 'NAME': 'djangobase' # 数据表名 }, 'slave': { 'ENGINE': 'django.db.backends.mysql', 'HOST': '127.0.0.1', 'PORT': 8306, 'USER': 'django_slave', 'PASSWORD': 'django_slave', 'NAME': 'djangobase_slave' } } -
在models.py创建完表后,进行数据库迁移
python manage.py makemigrations # 在migrations文件夹下生成记录 python manage.py migrate --database default # 默认可以不写参数 python manage.py migrate --database slave # 在从库再迁移一次,就可以在上面建立相同的表 -
创建数据库操作的路由分类
- 使用sqllite
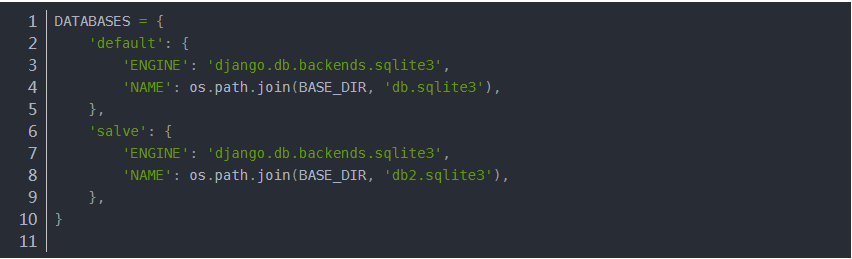
- 使用mysql
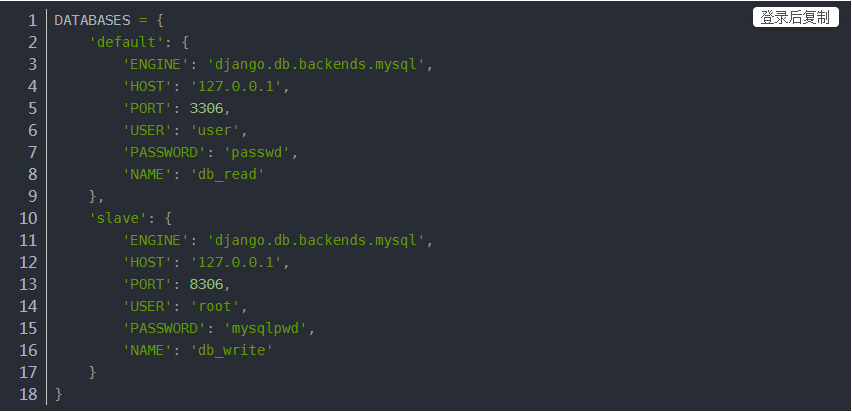
- 在项目的utils中创建db_router.py文件,并在该文件中定义一个db类,用来进行读写分离
#读写分离
class MasterSlaveDBRouter(object):
def db_for_read(self, model, **hints):
"""读数据库"""
return "slave"
def db_for_write(self, model, **hints):
"""写数据库"""
return "default" #默认的库 读
def allow_relation(self, obj1, obj2, **hints):
"""是否运行关联操作"""
return True
#一主多从 多个数据库读 一个数据库写
class Router:
def db_for_write(self, model, **kwargs):
return 'db1'
def db_for_read(self, model, **kwargs):
return random.choices['db2', 'db3', 'db4']
#分库分表
class Router:
def db_for_write(self, model, **kwargs):
app_name = model._meta.app_label
if app_name == 'app01':
return 'db1'
elif app_name == 'app02':
return 'db2'
def db_for_read(self, model, **kwargs):
app_name = model._meta.app_label
if app_name == 'app01':
return 'db1'
elif app_name == 'app02':
return 'db2'
-
配置读写分离路由
- 在配置文件中增加
#配置读写分离 DATABASE_ROUTERS = ['项目名.utils.db_router.MasterSlaveDBRouter("自定义的类名称")'] -
还可以使用手动的方式进行读写分离
- 进行orm操作的时候使用using操作对应数据库
def write(request): models.User.objects.using('default').create(name='张三', pwd='123', phone=1234) return HttpResponse('写成功') def read(request): obj = models.User.objects.filter(id=1).using('db2').first() return HttpResponse('读成功')


 浙公网安备 33010602011771号
浙公网安备 33010602011771号