自然场景下的人脸识别(一)——人脸检测

人脸检测技术有许多的应用场景,最常见的就是拍摄照片时检测到人脸并且做美颜。
本人本科毕业设计题目与人脸识别相关,人脸识别的第一部就是进行人脸检测,检测出人脸后再进行后续的人脸比对识别。这里总结一下我这段时间所学的知识,后面继续做人脸识别相关。
综述
人脸识别这个问题在很久之前就已经提出了。
在人脸识别领域很著名的算法是2004年 Viola and Jones 提出的,使用 Haar-like 特征和 AdaBoost算法来训练分类器,通过分类的级联来获得一个较强的人脸识别模型。这个模型能够很好的检测出正面的人脸。然而在自然场景下拍摄的照片,由于光照、面部姿态角、遮挡的原因,这个算法在漏检率十分的高。Viola and Jones 也提出了一些方法来解决面部姿态角不同所产生的人脸漏检的问题,但是模型的复杂性都是相对比较高的。
另外一个进行人脸检测的方法是使用DPM模型。DPM模型是在HOG特征基础上进行改进的,DPM使用了多个分辨率不同的HOG特征。利用了子模型和主模型空间的先验知识,在人脸面部姿态角变化、遮挡问题上有很强的鲁棒性。
但是上述的两种方法及其改良版本,训练过程比较复杂,在某些场景下漏检率比较高,所以和毕业设计老师交流的时候,老师建议使用深度学习的方法来尝试人脸检测。所以我的毕业设计也就走向了使用神经网络来实现的道路上了。这篇总结也是围绕我所看的论文所写的。
基于神经网络的人脸检测
深度学习人脸检测最早的代表论文是2015年CVPR上的 "A Convolutional Neural Network Cascade for Face Detection",保留了传统人脸检测方法中Cascade的方法。另一篇是 "Multi-view Face Detection Using Deep Convolutional Neural Networks" 亮点是使用了全卷积网络,得到图像的heatmap。
2016年kpzhang发表的"Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks"综合使用了上面两种方法。由于kpzhang在github上开源了他的测试代码和模型,所以目前我所使用的人脸检测方法也是这种方法。
其实有很多工作是将Object Detection 的方法例如RCNN,FastRCNN、YOLO应用到人脸检测上的。其实上面提到的方法也参考了很多Object Detection的做法。由于毕业设计是做人脸识别相关的,所以我所看的论文就都是面对人脸检测这个小一点的问题上的。
论文阅读及相关的笔记
下面是我在学习人脸检测时所看的3篇关于人脸检测相关的论文的笔记
1. A Convolutional Neural Network Cascade for Face Detection
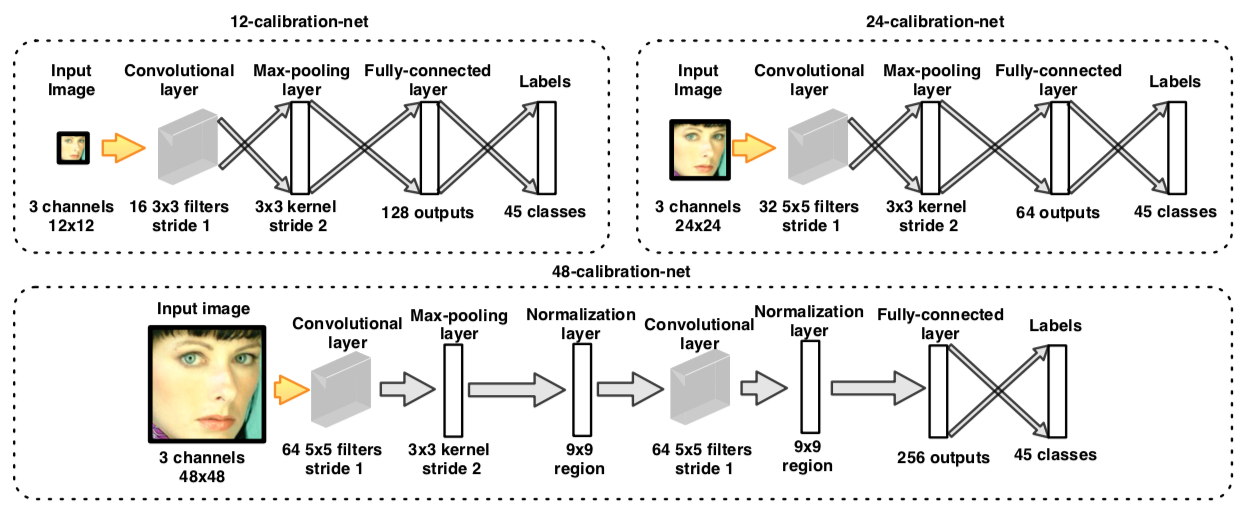
这篇论文是将卷积神经网络运用在人脸检测任务上比较有代表性的文章。这篇论文提出的方法保留了 Detector Cascade 的结构,使用了6个CNN网路进行级联,其中3个CNN网络用来做是否存在人脸的二分类,另外3个用来作为人脸边界框框的校准(calibration)
- 用于人脸检测的二分类网络:
12-net,24-net,48-net - 用于候选框校准的网络:
12-calibration-net,24-calibration-net,48-calibration-net

三个候选框校正的网络实现的是多分类网络而不是回归网络
通过对3个维度的预定义缩放集合构成N个校准模式,校准模式可以写成\(\{[s_n,x_n,y_n]\}_{n=1}^{N}\)。给定一个检测窗口\((x,y,w,h)\)(\((x,y)\)表示检测窗口的左上角,\((w,h)\)表示大小),校准模式将会以下面的形式来校准提供的检测窗口:
实际使用中\(s_n, x_n, y_n\)的取值范围:
所以 \(N=45\)。因为这45个校准模式之间并不是两两正交的,所以文中没有直接使用最高得分的校准模式对候选框进行校准,而是采取加权平均的方式进行的(其中\(t\)为阈值):
2. Multi-View Face Detection Using Deep Convolutional Neural Networks
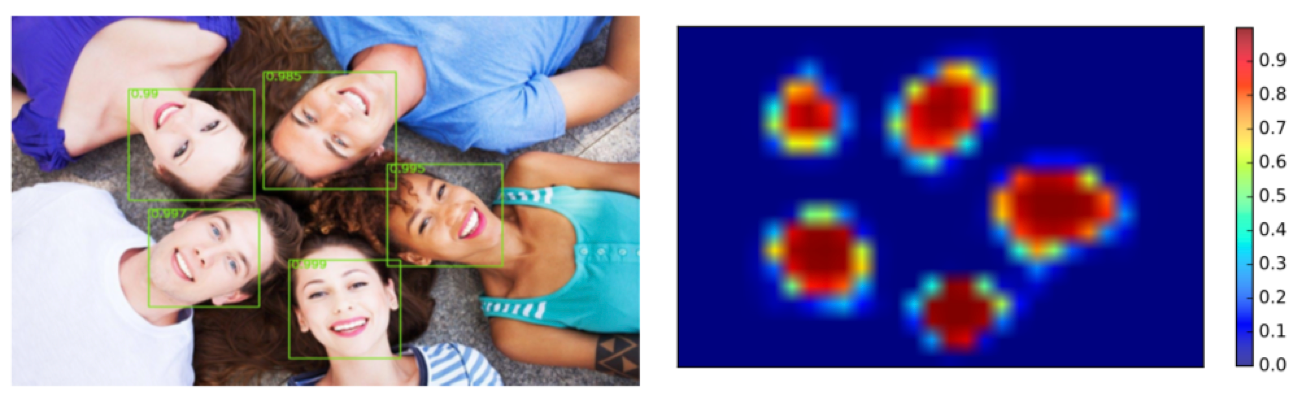
这篇网络与前面一篇相比,亮点在于,作者使用的全卷积网络代替了滑窗。图片经过全卷积网络生成了一个人脸检测的heatmap,代表了检测器在图片上的不同响应。根据响应评分获得人脸候选框。
论文中使用的是AlexNet网络,使用AlexNet在LFW数据集上进行微调得到。他们对AlexNet的全连接层测参数进行修正,使其变为卷积层,由于AlexNet具有比较好的分类能力,所以论文中没有使用像级联架构来检测人脸。网络最终的输出为图片的heatmap
3. Joint Face Detection and Alignment using Multi-task Cascaded Convolution Networks
multi-task 在2016年的时候突然火了起来,这篇论文就采用了multi-task的卷积神经网络,结合了上面两篇论文的一些做法,主要思想有一下5点:
- 采用cascaded multi-task 结构,3级级联结构,每一级单独训练
- 将face detection、 alignment 和 landmark 作为multi-task 在一个网络中同时优化,三者的相关性能够促进准确率的提高。
- 使用全卷积网络代替滑窗生成图片heatmap, 前期过滤大部分的背景窗口
- 采用Online Hard Example Mining提高准确率
- 使用Image Pyramid以检测不同尺度的人脸。
下图是作者论文中关于使用到的神经网络的结构图
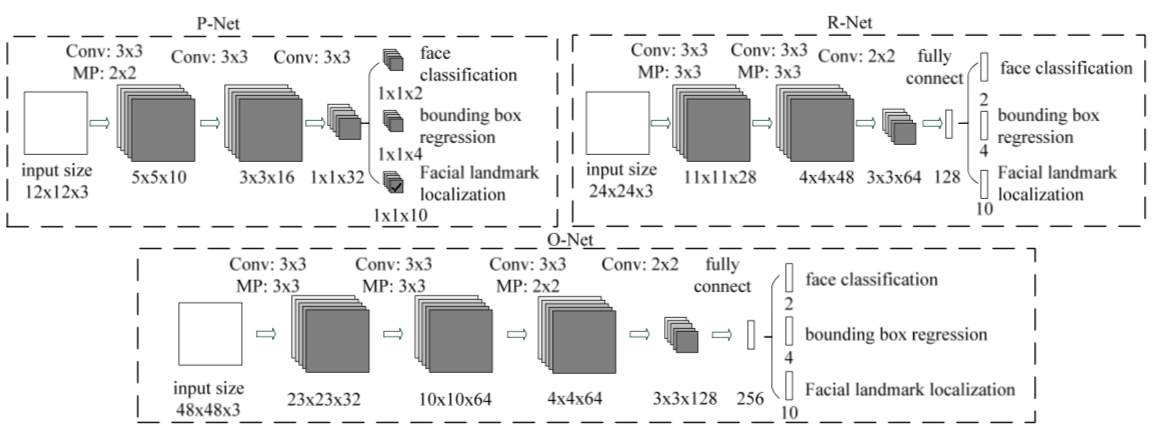
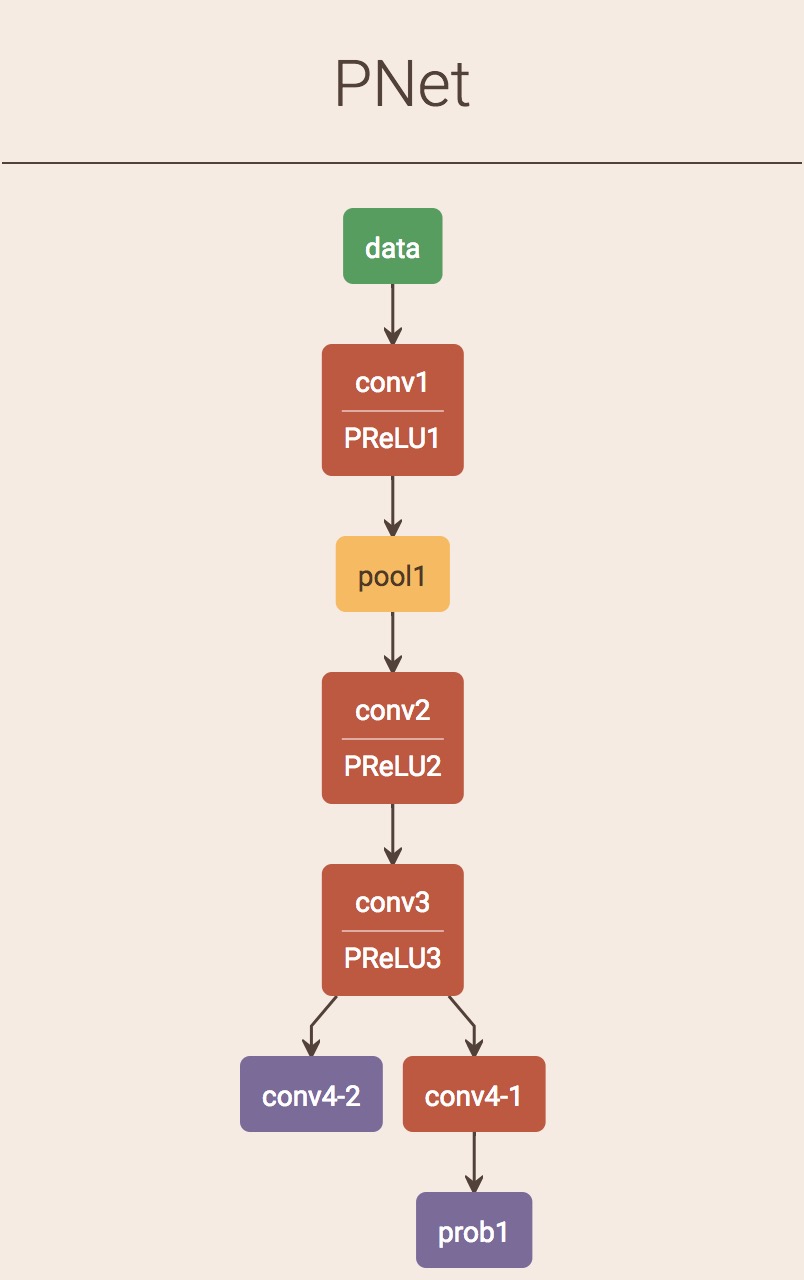
文中使用的三个网络结构也是从浅到深。前期使用浅层的卷积神经网络过滤掉大量的背景选框,因为此时是为了快速过滤无关紧要的背景,所以卷积网络的能力可以不是特别强。 配合multi-task,前期可以快速提取候选框。第一个阶段所采用的网络作者称为Pnet
接下来就是两个结构相仿的卷积神经网络Rnet和Onet。网络能力逐步增强。输入候选图像的大小也从小到大,分别为24px和48px
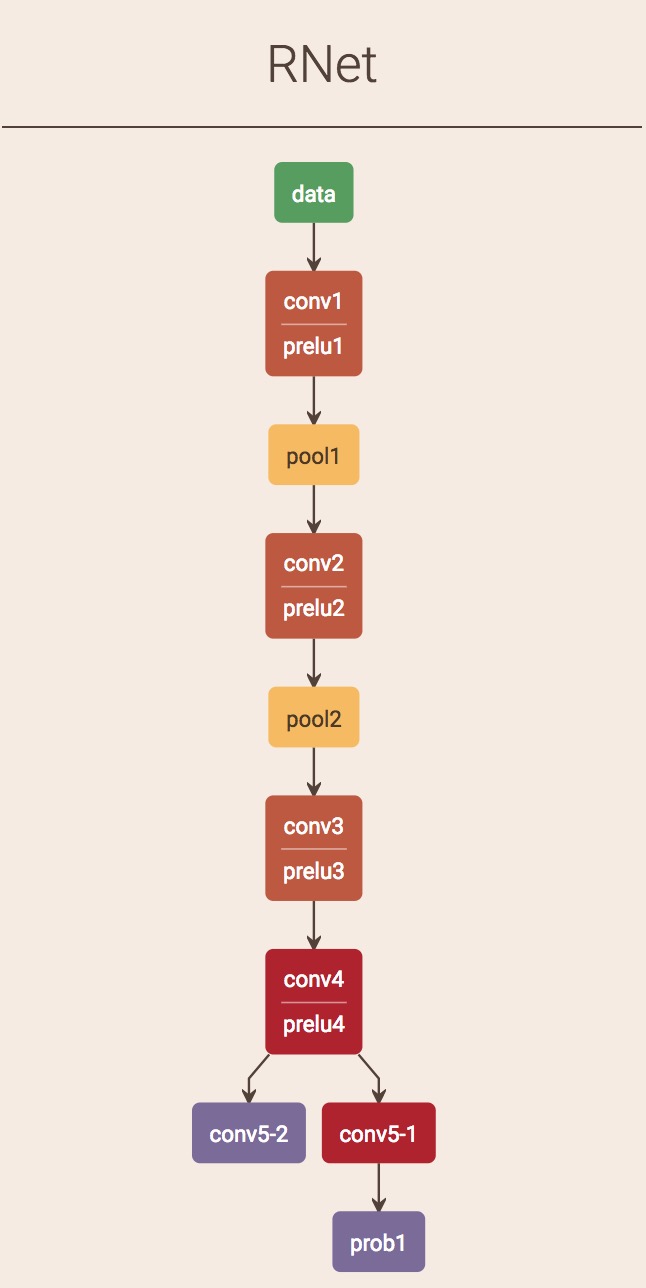
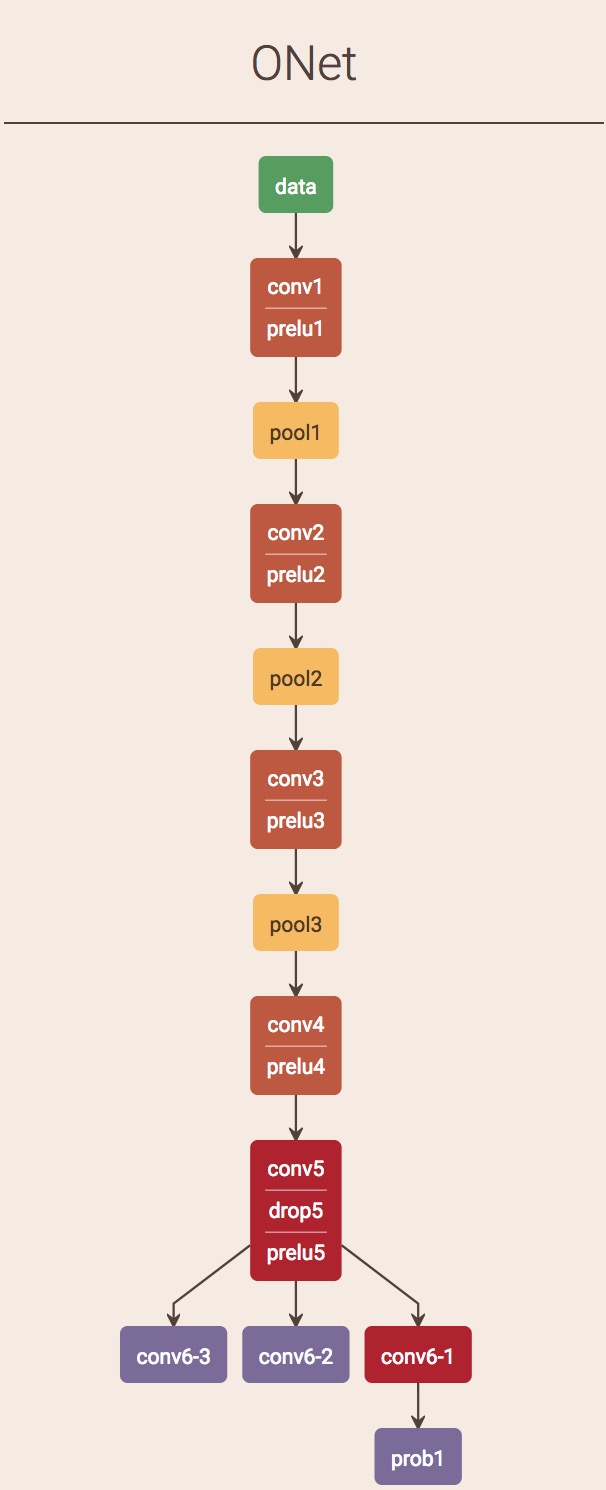
上面的网络是kpzhang93开源出来的网络模型进行绘制出来的,眼尖的读者会发现,Pnet和Rnet和论文中不一样,少了一个输出,这是因为作者采用的WiderFace数据集,该数据集没有landmard(人脸关键点)信息,因此Pnet和后续的Onet只做了classification和bounding box regression。
multi-task 损失函数的定义
损失函数的定义由多个任务的误差进行加权求和得到
在线困难样本挖掘(Online Hard Sample Mining)
在训练的时候使用OHSM来提高模型的准确率,每个mini-batch中计算出70%的困难样本,只是计算这些困难样本的损失来计算梯度。因为容易的样本对提高模型能力相对比较小。
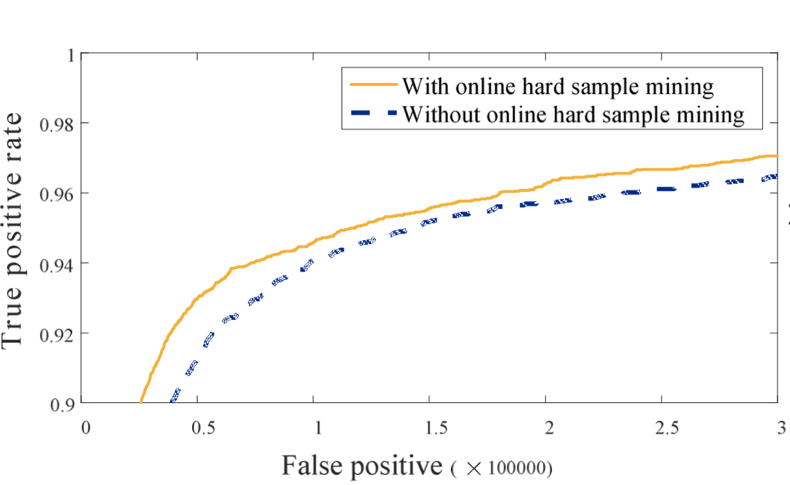
最终结果


Summary
这篇文章是本人本科毕业设计所学内容的总结。如果各位读者有什么看法和建议欢迎在评论区提出来。行文有什么纰漏的话,也请大家不吝指正。谢谢
过段时间我也会继续把人脸识别关于人脸对比的学习内容总结出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号