HASH算法介绍
HASH算法介绍
在Oracle中使用频率最高的算法就是hash算法接下来以共享池中的SQL语句查找为例,描述hash算法
1.HASH key,hash函数与hash值
最简单的hash就是求余给它一个值可以生成另一个值。
hash算法的核心就是设计一个hash函数,每次传给它一个给定值(源值,也称为hash的key),可以得到另外一个相应的值(hash值)。hash函数就是将源值(hash key)转化为hash值的过程,而且此过程是可重复的。
例如,以“除以31取余为例”,除以31取余可以称为hash函数,假设传给这个hash函数一个值50,得到的结果为19,那么这个值19就是hash值。而这个被传给它的50则是hash key。
除法或者求余会占用非常高的CPU资源并且无法应用于字符串,所以大部分hash函数都是位运算的。位运算是一个速度很快的操作,相比较除法和求余。位运算只会占用很少的CPU资源。但hash函数仍然是强CPU消耗型操作,因此在hash算法使用比较密集的时候,CPU的占用率一定会居高不下。在Oracle中比如逻辑读。每一次逻辑读都要计算hash值,然后根据这个hash值来找到Cache Buffer Chain链表,因此逻辑读是一种很消耗CPU的操作。
通过HASH算法将各种各样的SQL语句转化成一个数值,目的就是快速搜索。
2.链表与HASH
2.1 使用遍历算法查询链表
在Oracle中,hash算法的作用主要是快速搜索。而搜索目标就是内存,通过hash在内存中快速定位。内存中的数据组织成链表,其组织形式如下。
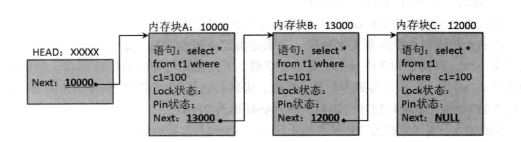
解释一下上图的含义,通常在一个链表中会存在一个表头,表头会记录下一内存块的信息。上图中内存块A的地址是10000,在A中保存了语句select * from t1 where c1=100的相关信息,同时内存块A也将内存块B的地址记录下来。以此类推内存块B也记录了一个语句的信息和C的地址。C是这个链表的最后一个所以记录的除了语句外没有下一内存块的地址为null。需要注意的是这些内存块不是相连的而是记录地址的关系。
具体执行流程
现在想查看“select * from t1 where c1=101;”这条SQL的相关信息,从链表头部开始步骤如下
- 取出头中记录的下一内存块的地址 10000。
- 访问10000处的内存块,查看里面的语句和想要查询的目标语句是否一致,不是的话去这个内存块所记录的下一目标块查看。
- 取出10000处内存块中下一内存块的地址:13000。
- 访问13000处的内存块,发现里面的语句和要查询的目标语句一致,发现这就是要找的目标。
- 访问13000处内存块相关信息。
以上的执行方式就是数据结构中最初级的方法——遍历算法。在链表中搜索某个内存块,像这种从头到尾比较每一个内存块就是链表的遍历算法,当然如果链表很长那么查询的时间也会变得很长,所以在查询长链表的时候遍历算法的效率很低。也因此产生了更高效的hash算法。
2.2 使用hash算法查询
遍历算法对内存块的存放没有要求,但是hash算法要求内存块必须都是相连的,并且内存块的顺序也有要求。具体如下:
还是上例中的3条SQL,3块内存对应的3条SQL的hash值和hash值除以3的余数如下:
| 内存块 | 语句内容 | hash值 | 除以3的余数 |
|---|---|---|---|
| 内存块A | select * from t1 where c1 = 100 | 468183 | 0 |
| 内存块B | select * from t1 where c1 = 101 | 472279 | 1 |
| 内存块C | select * from t1 where c1 = 100 | 911081 | 2 |
在内存中排序相应如下:
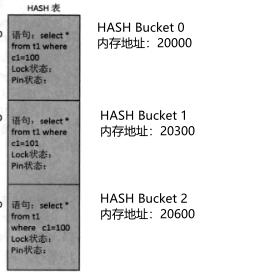
内存分配方式:假设每个内存块为300字节,那么这三个内存块共需要内存分配900字节。并且根据表中计算出来的余数,内存块的应该以A、B、C的顺序排放在内存中如上图所示。A的内存地址为20000,B的内存地址为20300,C的内存地址为20600。这样做的好处是每个内存块不需要再记录下一内存块的地址了,因为内存块的大小是一样并且有一定的顺序,在本内存块的内存地址上加300就可以了。
使用hash算法来查询链表直接将要查找的内容作为HASHkey并计算hash值然后再求余。这里每块内存被Oracle命名为HASH Bucket,这三个HASH Bucket组合成为HASH表。而HASH Bucket的编号来自于余数。
具体执行流程
现在查看“select * from t1 where c1=101;”这条SQL的相关信息
- 将“select * from t1 where c1=101;”作为HASH Key计算其hash值,得到472279,除以3余数为1,因此目标应该在1号HASH Bucket中。
- 计算1号HASH Bucket的位置公式为HASH表地址+HASH Bucket编号×HASH Bucket大小,也就是20000+1×300=20300。
- 得到地址后访问1号HASH Bucket中的相关信息。
2.3 两种查询的区别
在链表中如果要查询的目标在第n个节点,就必须从头开始搜索,搜索n个节点如果这个n很大那么查询的效率就会很低。
在HASH表中,只需要对搜索目标进行hash运算根据上面的公式得到HASH Bucket的编号即可。
其次链表需要使用循环逐个搜索,HASH表没有循环。链表算法的复杂度是O(n),而HASH算法的复杂度是O(1)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号