html模板结合itextpdf生成pdf文档--demo
这段时间,接到一个需求,是将doc文档生成pdf文档。因为doc文档还挺复杂的,按照网上的示例使用java代码一个一个生成,那就太复杂了,所以就想到使用html模板来生成pdf文档。文章结束附代码链接(下载pdf,pdf添加水印文字图片,poi导出excel,freemarker导出excel)。
步骤:
1.wps打开doc文档,文件另存为html格式
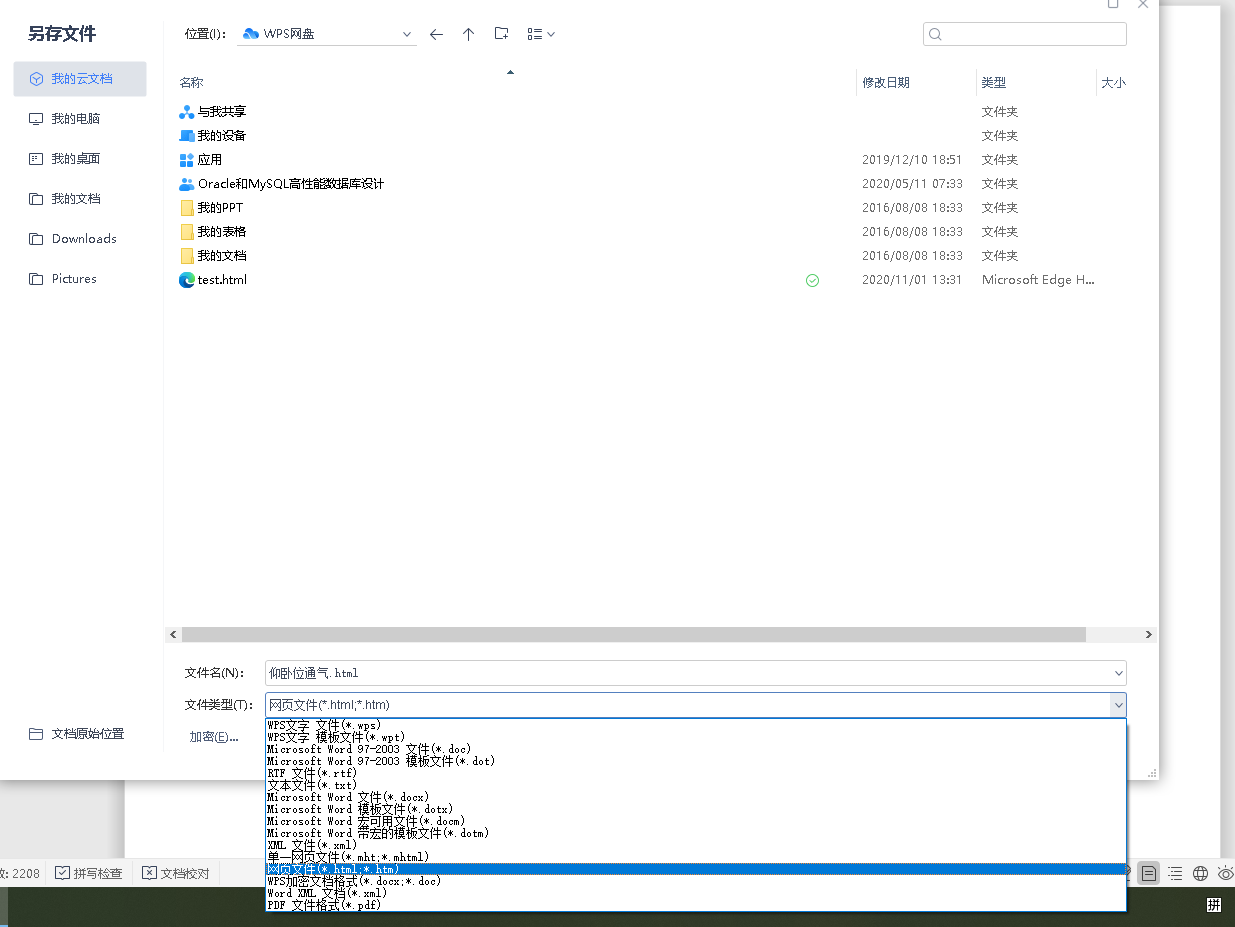
2.将生成的html复制进项目,如果有图片,则把同名文件中的图片复制进项目
3.把html中的图片路径替换成正确的路径
4.检查html中的标签是否都正确结束。
5.下载调试,如果有表格等,可能会导致有些边框出不来,所以需要调试table的td标签的border属性。
代码链接:
https://download.csdn.net/download/zj520_/13103967
图片是我使用demo代码测试导出的文件:
生成的水印文字,支持多页生成:

可能遇到的坑:
一、报错信息: The document has no pages.
原因1:在生成PDF时,需要生成PDF的内容,标签有误,在使用itextpdf下载pdf的时候,一定要保证标签有开始,有结束才行。
比如生成的html文件中的meta标签,img标签;
解决:
<meta http-equiv=Content-Type content="text/html; charset=UTF-8"/>
<meta name=ProgId content=Word.Document/>
<meta name=Generator content="Microsoft Word 14"/>
<meta name=Originator content="Microsoft Word 14"/>
<img src=""/>
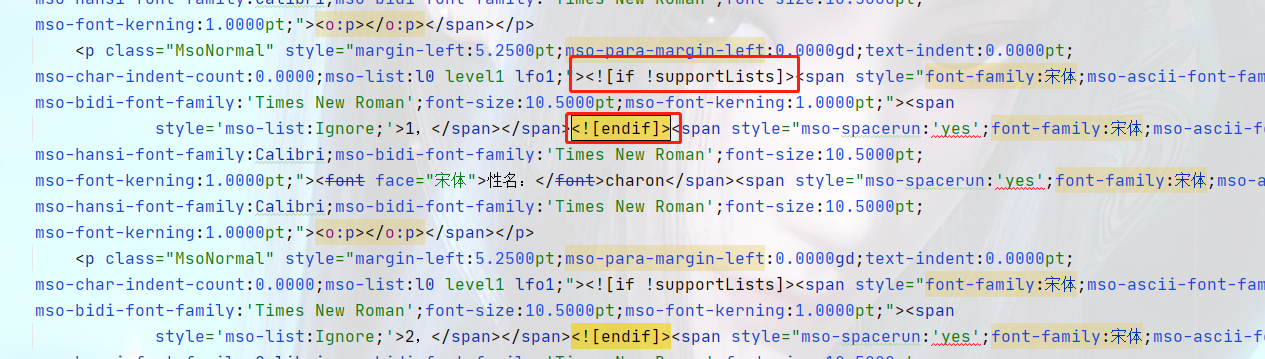
原因2:使用新版的wps生成的html文档中含有itextPdf不识别的内容,我这次就因为这个搞了我几天。后面发现就是在html中有下图中的内容。
解决:将这些内容删掉即可
二、java.nio.charset.MalformedInputException: Input length = 1
原因:是因为html的字符编码的问题,将文件的编码转为utf-8即可。
解决:将生成的html文件中的标签中的
<meta http-equiv=Content-Type content="text/html; charset=gb2312" />
改为:
<meta http-equiv=Content-Type content="text/html; charset=UTF-8" />
三、在使用ftl生成excel的时候,wps生成的xml文件,里面有很多内容不能格式化,可能会导致导出的文件有问题,打不开,所以就只格式化Worksheet标签内的内容就行了。
四、生成的xls结尾的文档,使用office打开会提示:"文件格式和扩展名不匹配",但是点击是,仍然能打开,网上有解决方案,如果有大佬有更好的方案,麻烦留言告知。
使用freemarker导出doc文档同理,如果有图片或者表格合并的问题,请点击链接:
https://www.cnblogs.com/pluto-charon/p/10934174.html
-------------------------------------20210107添加--------------------------------------
在项目上线后发现,使用freemarker导出的excel文件,在其他的系统(手机端)导入不进去。但是新建一个excel文件,把内容复制进去,又可以导进去。这肯定是wps生成的excel模板有问题吧,于是我又试了用office/poi生成模板,还是导不进去。然后就使用了下面的这种方式。使用可以导入的文档,用poi将文件读取出来,然后再一行一行的设置值(工作量很大),这种方式就可以导入了。至于什么原因,暂时没有时间研究。。。。。
package com.example.charon;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.springframework.util.ClassUtils;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.nio.file.Files;
import java.nio.file.OpenOption;
import java.nio.file.Path;
import java.nio.file.Paths;
/**
* @className: GenerateExcel
* @description: 读取模板的方式生成excel
* @author: charon
* @create: 2021-01-07 08:18
*/
public class GenerateExcel {
public static void main(String[] args) throws URISyntaxException, IOException {
URI uri = ClassUtils.getDefaultClassLoader().getResource("file/pdf/excel").toURI();
File file = new File(uri.getPath() + "/generate-excel.xls");
// 如果是xls则使用HSSFWorkbook,如果是xlsx则使用 XSSFWorkbook
HSSFWorkbook hssfWorkbook = new HSSFWorkbook(new FileInputStream(file));
// 获取sheet页
Sheet sheet = hssfWorkbook.getSheet("身份信息");
// 插入数据,如果是固定行数的模板,则需要获取最大行,然后遍历忘对应的单元格中插入数据
for (int i = 0; i < 10; i++) {
// 因为我的表头占了两行
Row row = sheet.createRow(i+2);
// 如果是固定模板,则直接getRow,getCell就行了。因为我这边是
row.createCell(0).setCellValue("测试姓名"+i);
row.createCell(1).setCellValue("测试性别"+i);
row.createCell(2).setCellValue("测试年龄"+i);
row.createCell(3).setCellValue("测试原籍"+i);
row.createCell(4).setCellValue("测试现籍"+i);
}
ByteArrayOutputStream baos = new ByteArrayOutputStream();
hssfWorkbook.write(baos);
byte[] outBytes = baos.toByteArray();
hssfWorkbook.close();
Path outPath = Paths.get("d://Test-generate-excel.xls");
Files.write(outPath,outBytes,new OpenOption[0]);
}
}
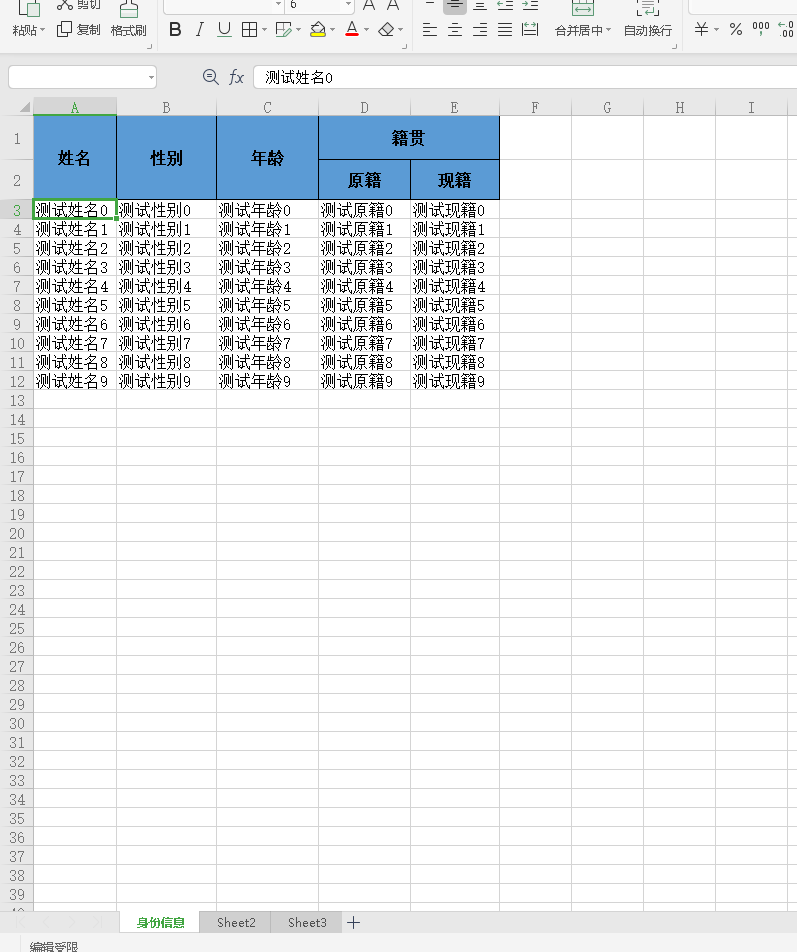
导出效果图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号