基于Ubuntu 20安装k8s
本文基于互联网多篇blog实战,对自己实际部署安装过程中遇到的问题记录写下。
整个安装部署使用非 root 身份
配置要求:
1. linux 系统
2. 至少2G内存
3. 至少2个CPU
4. 所有机器之间网络互通
5. 机器hostname、mac地址、product_uuid 唯一
6. 6443端口可使用
7. swap 交换分区关闭
一 前置步骤:
1. 统一所有节点的 /etc/hosts 文件中关于k8s集群的主机映射,以及相应机器的hostname
2. 关闭所有机器的swap分区
sudo swapoff -a #修改/etc/fstab,注释掉swap行 sudo vi /etc/fstab
3. 统一机器时区
sudo timedatectl set-timezone Asia/Shanghai #系统日志服务立即生效 sudo systemctl restart rsyslog
4. 统一安装docker服务 (2022.05.03 版本Docker version 20.10.7, build 20.10.7-0ubuntu5~20.04.2)
#这里直接使用自带源来安装,其版本符合要求 sudo apt-get install docker.io
5. 统一安装kubeadm和kubelet工具
sudo apt-get install -y curl curl -s https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add - # 此处使用 kubernetes-xenial 而不是 Ubuntu 20.04 的focal echo "deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list sudo apt-get update sudo apt-get install -y kubelet=1.23.9-00 kubeadm=1.23.10-00 kubectl=1.23.9-00
注意:这里指定了kubelet/kubeadm/kubectl的版本为1.23.9,之所以指定版本,是因为1.24版本之后,k8s弃用了docker,改用cri,这就导致最新版本的kubeadm初始化集群时,docker images命令看不到相关镜像,也就没有办法通过docker来管理镜像,在kubeadm拉取镜像失败时,不能手动通过docker来提前拉取。
二 初始化master节点
使用下面命令来初始化master
sudo kubeadm init --image-repository=gcr.akscn.io/google_containers --pod-network-cidr=172.16.0.0/16
2022.9.11更新
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.Unfortunately, an error has occurred:
timed out waiting for the conditionThis error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- 'systemctl status kubelet'
- 'journalctl -xeu kubelet'Additionally, a control plane component may have crashed or exited when started by the container runtime.
To troubleshoot, list all containers using your preferred container runtimes CLI.
Here is one example how you may list all running Kubernetes containers by using crictl:
- 'crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock ps -a | grep kube | grep -v pause'
Once you have found the failing container, you can inspect its logs with:
- 'crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock logs CONTAINERID'
couldn't initialize a Kubernetes cluster使用最新版本kubeadm (通过“kubeadm version”命令发现kubeadm的版本是1.25版本) 初始化集群时,无法成功,报以上错误。
根据报错信息逐步排查:
1. 首先检查了kubelet服务是running状态
2. 然后用 journalctl -xeu kubelet 查看日志,发现大量"Error getting node" err="node报错,网络检索后,找到“kubeadm init fails with node not found · Issue #2370 · kubernetes/kubeadm · GitHub” 中的参考回答发现没有帮助
3. 过滤掉大量"Error getting node" err="node的报错后,发现有failed to pull image \"k8s.gcr.io/pause:3.6\"的报错,而 kubeadm init初始化时,log中提示拉取的镜像版本是pulling: registry.aliyuncs.com/google_containers/pause:3.8
4. 通过kubeadm config images list确认已拉取的镜像的确是3.8版本,而不是3.6版本,所以init初始化时找不到3.6版本后去尝试拉取,而已知k8s.gcr.io这个域名是被墙了
5. 既然仓库被墙,那么尝试走代理,网络检索后得知可以用sudo http_proxy=a.b.c.d:1080 kubeadm init这种形式来使得kubeadm走代理,但实测不生效
综上,已经知道问题原因是镜像版本不对,导致无法成功初始化,并且无法走代理。
6. 镜像被墙,无法拉取,也无法走代理,根据曾经学习过的姿势,可以手动拉取镜像后再重命名为k8s.gcr.io/pause:3.6。但新的问题出现了,使用docker images命令,无法查看kubeadm init初始化期间拉取的镜像,网络查询后发现k8s 1.25版本后,弃用了docker,改为cri。所以无法通过docker提前拉取镜像后改名来曲线救国。
7. 查询k8s cri资料后,发现最后支持docker的k8s集群版本是1.23,故采用降级kubelet/kubeadm/kubectl版本的版本来进行k8s集群的初始化
最终,通过使用1.23版本的kubeadm成功初始化集群
最后,根据网上一篇文章所说,kubeadm这个工具是与k8s同步进行更新的,且为了实现最佳实践,会从网络下载最新最佳实践配置,这意味着kubeadm初始化集群相关的教程可能会随着时间推移而失效,可能会出现形形色色的报错,就如同上面的错误一样。这点非常不友好,博客教程会随时变得不可参考。
↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑更新分割线↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑
返回报错:
“[ERROR ImagePull]: failed to pull image gcr.akscn.io/google_containers/kube-apiserver:v1.23.6: output: Error response from daemon: Get https://gcr.akscn.io/v2/: http: server gave HTTP response to HTTPS client
, error: exit status 1
[ERROR ImagePull]: failed to pull image gcr.akscn.io/google_containers/kube-controller-manager:v1.23.6: output: Error response from daemon: Get https://gcr.akscn.io/v2/: read tcp 192.168.0.200:44566->40.73.69.67:443: read: connection reset by peer
, error: exit status 1
[ERROR ImagePull]: failed to pull image gcr.akscn.io/google_containers/kube-scheduler:v1.23.6: output: Error response from daemon: Get https://gcr.akscn.io/v2/: http: server gave HTTP response to HTTPS client
, error: exit status 1
[ERROR ImagePull]: failed to pull image gcr.akscn.io/google_containers/kube-proxy:v1.23.6: output: Error response from daemon: Get https://gcr.akscn.io/v2/: http: server gave HTTP response to HTTPS client
, error: exit status 1
[ERROR ImagePull]: failed to pull image gcr.akscn.io/google_containers/pause:3.6: output: Error response from daemon: Get https://gcr.akscn.io/v2/: http: server gave HTTP response to HTTPS client
, error: exit status 1
[ERROR ImagePull]: failed to pull image gcr.akscn.io/google_containers/etcd:3.5.1-0: output: Error response from daemon: Get https://gcr.akscn.io/v2/: x509: certificate has expired or is not yet valid
, error: exit status 1
[ERROR ImagePull]: failed to pull image gcr.akscn.io/google_containers/coredns:v1.8.6: output: Error response from daemon: Get https://gcr.akscn.io/v2/: http: server gave HTTP response to HTTPS client
, error: exit status 1”
多次Google搜索没找到解决方法,最后仔细看其他成功的blog发现是因为初始化的命令行参数使用了“--image-repository=gcr.akscn.io/google_containers”导致的,更换为“sudo kubeadm init --image-repository registry.cn-hangzhou.aliyuncs.com/google_containers --pod-network-cidr=172.16.0.0/16” 后成功继续执行,但紧接着又报错:
“[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused”
网络搜索后得知是因为kubelet服务没有启动,用 sudo systemctl start kubelet 尝试启动,但是启动没有成功,查看报错日志发现
“kubelet[61248]: E0503 16:54:09.970816 61248 server.go:302] "Failed to run kubelet" err="failed to run Kubelet: misconfiguration: kubelet cgroup driver: \"systemd\" is different from docker cgroup driver: \"cgroupfs\""”
根据错误提示,应该是docker driver导致,通过创建/etc/docker/daemon.json文件,写入如下配置:
{ "exec-opts": [ "native.cgroupdriver=systemd" ] }
并重启相关服务后,kubelet服务成功运行,如下:
sudo systemctl daemon-reload sudo systemctl restart docker sudo systemctl start kubelet

kubelet服务成功后,继续进行kubeadm的初始化,此时报错:
“error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR Port-6443]: Port 6443 is in use
[ERROR Port-10259]: Port 10259 is in use
[ERROR Port-10257]: Port 10257 is in use
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR Port-2379]: Port 2379 is in use
[ERROR Port-2380]: Port 2380 is in use
[ERROR DirAvailable--var-lib-etcd]: /var/lib/etcd is not empty”
从错误中发现端口被占用了,如下
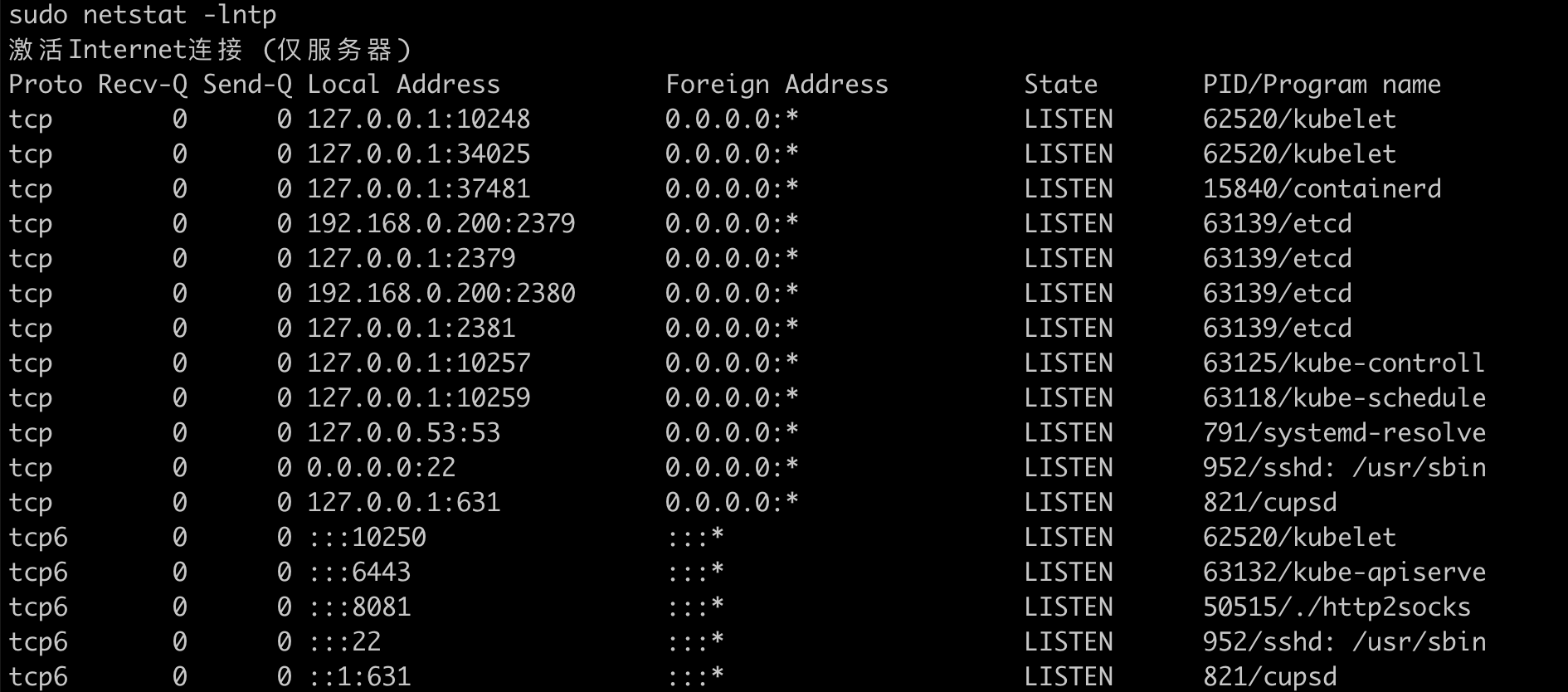
从结果看,很明显是kubeadm init之前的操作部分成功了,重新执行命令会因为之前已经成功的步骤冲突而报错,在kubeadm --help中,发现有个可用的子命令可以用来重置,如下:
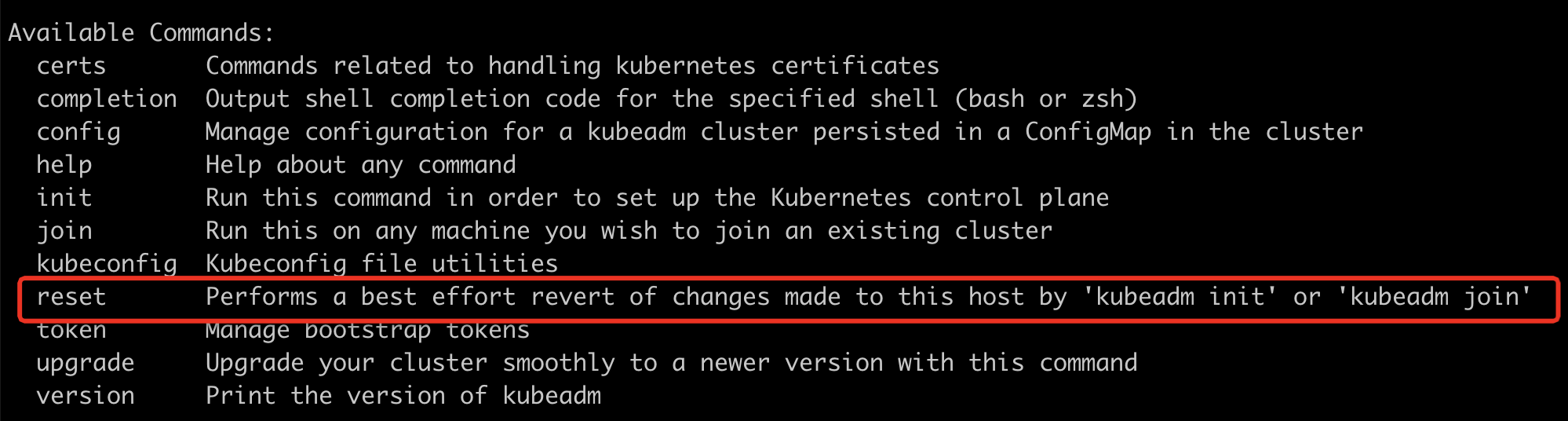
重置成功后再次初始化。到此,如无异常,k8s的master将初始化成功,并获得以下提示
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.0.221:6443 --token w41cvr.5jzuvpr5y70bawnw \
--discovery-token-ca-cert-hash sha256:e0f34d8d73b6820ef804a2d5c3b081b0bc1ea29ed19392e405a4aedba916cb07
master节点初始化成功后,为了操作集群,还需要根据init初始化成功最后输出的log来做三步配置。
第一步配置一个kube config,如下
非root方式使用
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
如果想用root用户来操作,则配置一个环境变量
export KUBECONFIG=/etc/kubernetes/admin.conf
第二步配置一个 pod network,这里网络上能找到多个插件,如 Calico、flannel、canal等,这里使用calico插件
# 下载calico网络配置文件 wget https://docs.projectcalico.org/v3.21/manifests/calico.yaml # 找到 calico.yaml文件中内容为 name: CALICO_IPV4POOL_CIDR 的配置 # 启用该配置,并且设置 value: "172.16.0.0/16"(匹配kubeadm init命令中的"--pod-network-cidr=172.16.0.0/16"参数) # 使用该配置 kubectl apply -f calico.yaml
三 初始化 node 节点
完成上面配置kube config和pod network两步操作之后,就剩下最后一步:初始化worker node节点并加入集群。步骤如下:
登录到需要加入的第一台worker节点上执行前面的join命令,如下:
kubeadm join 192.168.0.221:6443 --token w41cvr.5jzuvpr5y70bawnw --discovery-token-ca-cert-hash sha256:e0f34d8d73b6820ef804a2d5c3b081b0bc1ea29ed19392e405a4aedba916cb07
执行命令,报了master曾经出现的错误
“[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused.”
一样的,查看日志发现是kubelet服务没启动,一样创建/etc/docker/daemon.json文件并写入下面配置后重启服务,
{
"exec-opts": [
"native.cgroupdriver=systemd"
]
}
sudo systemctl daemon-reload sudo systemctl restart docker sudo systemctl start kubelet
然后再次执行join命令,报错:
“error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists
[ERROR FileAvailable--etc-kubernetes-bootstrap-kubelet.conf]: /etc/kubernetes/bootstrap-kubelet.conf already exists
[ERROR Port-10250]: Port 10250 is in use
[ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists”
同之前master上执行kubeadm init类似,也是kubeadm join部分步骤成功导致的,同样使用命令 sudo kubeadm reset 重置后重新join就成功了。
到此,k8s集群的安装就成功了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号