关于《汇编语言(王爽)》程序6.3使用16个dw 0的问题
在学习王爽老师《汇编语言》的第6.2节时,在程序6.3代码中,给出了如下的代码:
1 assume cs:code 2 code segment 3 dw 0123h, 0456h, 0789h, 0abch, 0123h, 0456h, 0789h, 0abch 4 dw 0,0,0,0, 0,0,0,0, 0,0,0,0, 0,0,0,0 5 6 start: mov ax,cs 7 mov ss,ax 8 mov sp,30h 9 10 mov bx,0h 11 mov cx,8 12 s: push cs:[bx] 13 add bx,2 14 loop s 15 16 mov bx,0 17 mov cx,8 18 s0: pop cs:[bx] 19 add bx,2 20 loop s0 21 22 mov ax,4c00h 23 int 21h 24 code ends 25 end start
可以看到第4行中定义了16个dw 0,也就是16个字型数据(32个字节型),随后将该32个字节内存空间当做栈来使用。初始栈顶为30h,结构图如下:
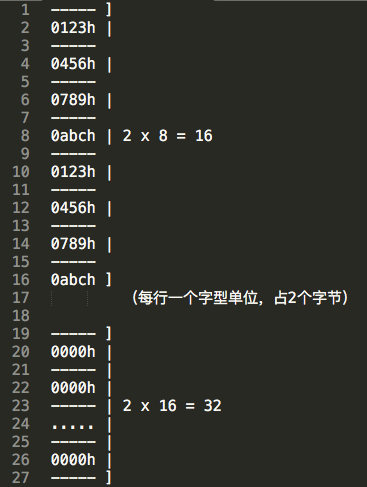
从上图可以看到,总共花费了48个字节,48转换成16进制值为30H,而内存地址从0开始计数,因此这2个dw的内存起止地址为0~2F,上面的代码将第二个dw段视作栈空间,初始栈为空,因此指向栈下面的内存空间,结构如下:

所以代码的第8行将栈偏移地址寄存器SP设置为30h。
这里有一个问题,第一个dw段只定义了8个字型数据(16个字节),为了逆序反转它,应该只需要8个字型大小的栈空间,但实际却定义了16个字型数据(32个字节),多出来8个字型数据,似乎是多余的。更改代码,将第二个dw段中定义的16个字型数据更改为8个,这样栈偏移地址寄存器SP就应该设置为20h,然后调试程序看看,如下:
首先回忆书本第4章4.9节程序执行过程的跟踪中的说明,一个程序的加载一定是先找到一段足够空间的内存,该内存空间的地址段为SA,偏移地址为0,因此寄存器CS=SA,寄存器IP=0h。而该内存前面256个字节用来和程序通信,因此实际的指令段地址为CS=CS+10h。
上机查看加载到内存的代码指令,可以看到IP寄存器的值的确为20h,因为前面32个字节是数据空间,第33个字节才是真正指令,因此IP指向20h(这是程序源码中start标志告诉编译器的)。另外,也可以看到第一个压栈的循环在0B34:002D~0B34:0033处。
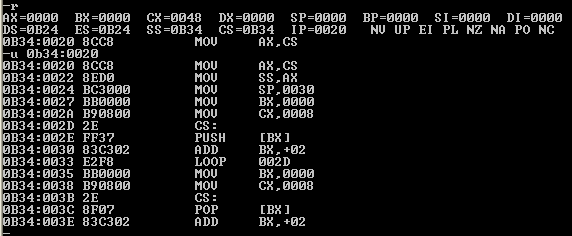
在执行循环压栈数据之前,先查看代码指令前20个字节的空间的值,也就是2个dw段中定义的数据。然后一次性执行完第一个循环,使用g命令,令其执行到0B34:0035处开始等待,然后再查看一次前20字节的数据空间,如下:
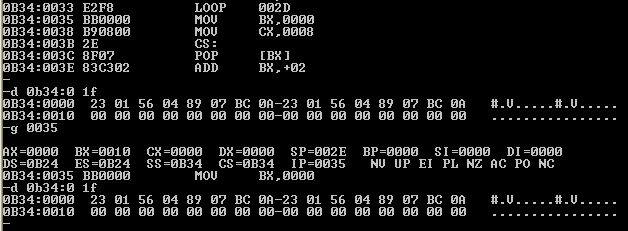
从上图可以发现一个比较奇怪的地方,那就是栈空间的数据并没有改变,第一个dw段的数据没有压栈。这不应该,为什么没有正常工作?再次查看代码指令,突然发现代码指令被改写了,如下图:

由于指令被改写,那自然上面的程序就没发正常工作了。那为什么指令的内容会被改变呢?回想书本第3章最后一个问题,也就是实验2中最后一个提问,为什么栈里的数据改变了?

最前面的程序使用16个dw字型数据做栈空间时,能够正常工作,而使用8个字型数据时,则出现了问题,这原因是不是和上面图中的提问的答案一样?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号