paper
class LinearSelfAttention(nn.Module):
"""
This layer applies a self-attention with linear complexity, as described in `https://arxiv.org/abs/2206.02680`
This layer can be used for self- as well as cross-attention.
Args:
embed_dim (int): :math:`C` from an expected input of size :math:`(N, C, H, W)`
attn_drop (float): Dropout value for context scores. Default: 0.0
bias (bool): Use bias in learnable layers. Default: True
Shape:
- Input: :math:`(N, C, P, N)` where :math:`N` is the batch size, :math:`C` is the input channels,
:math:`P` is the number of pixels in the patch, and :math:`N` is the number of patches
- Output: same as the input
.. note::
For MobileViTv2, we unfold the feature map [B, C, H, W] into [B, C, P, N] where P is the number of pixels
in a patch and N is the number of patches. Because channel is the first dimension in this unfolded tensor,
we use point-wise convolution (instead of a linear layer). This avoids a transpose operation (which may be
expensive on resource-constrained devices) that may be required to convert the unfolded tensor from
channel-first to channel-last format in case of a linear layer.
"""
def __init__(
self,
embed_dim: int,
attn_drop: float = 0.0,
proj_drop: float = 0.0,
bias: bool = True,
) -> None:
super().__init__()
self.embed_dim = embed_dim
self.qkv_proj = nn.Conv2d(
in_channels=embed_dim,
out_channels=1 + (2 * embed_dim),
bias=bias,
kernel_size=1,
)
self.attn_drop = nn.Dropout(attn_drop)
self.out_proj = nn.Conv2d(
in_channels=embed_dim,
out_channels=embed_dim,
bias=bias,
kernel_size=1,
)
self.out_drop = nn.Dropout(proj_drop)
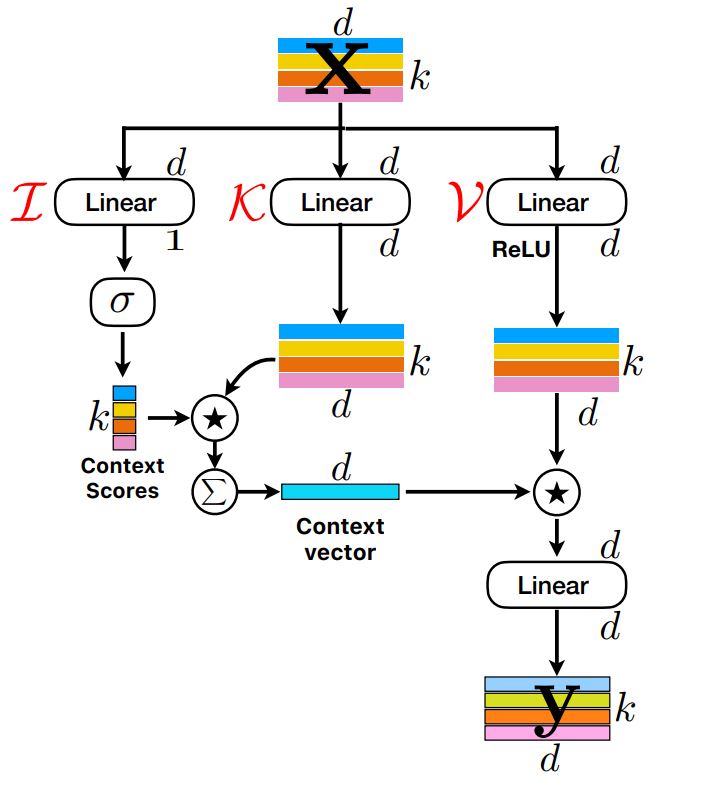
def _forward_self_attn(self, x: torch.Tensor) -> torch.Tensor:
# [B, C, P, N] --> [B, h + 2d, P, N]
qkv = self.qkv_proj(x)
# Project x into query, key and value
# Query --> [B, 1, P, N]
# value, key --> [B, d, P, N]
query, key, value = qkv.split([1, self.embed_dim, self.embed_dim], dim=1)
# apply softmax along N dimension query 是一个 Batch大小 1通道 每个patch内若干个值 多个patch 的结构 这个softmax会让每个patch内的值和为1
context_scores = F.softmax(query, dim=-1)
context_scores = self.attn_drop(context_scores)
# Compute context vector
# [B, d, P, N] x [B, 1, P, N] -> [B, d, P, N] --> [B, d, P, 1] 这里会触发广播机制 然后每个通道里的所有patch都压缩到一个patch上 可以将这个patch看做这一层的代表
context_vector = (key * context_scores).sum(dim=-1, keepdim=True)
# combine context vector with values
# [B, d, P, N] * [B, d, P, 1] --> [B, d, P, N] 将每个通道里的所有patch和这通道的代表patch相乘,就能将每个patch和全局的patch关联起来
out = F.relu(value) * context_vector.expand_as(value)
out = self.out_proj(out)
out = self.out_drop(out)
return out
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号