paper
def my_self(x: torch.Tensor):
'''
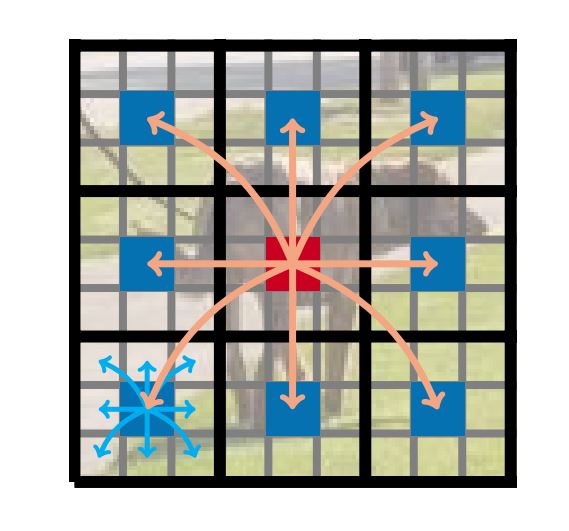
通过这段代码 可以把每张图片图片中相对位置相同的若干个tokens放到最后两个维度
'''
# [B, C, H, W] -> [B, C, n_h, p_h, n_w, p_w]
# n_h是高度方向上可以分多少个patch p_h patch的高度 n_w 宽度方向上可以分多少个patch p_w patch的宽度
x = x.reshape(batch_size, in_channels, num_patch_h, patch_h, num_patch_w, patch_w)
# [B, C, n_h, p_h, n_w, p_w] -> [B, C, n_h, n_w, p_h, p_w]
x = x.transpose(3, 4)
# [B, C, n_h, n_w, p_h, p_w] -> [B, C, N, P] where P = p_h * p_w and N = n_h * n_w
# num_patches 有多少个patch patch_area 每个patch的大小 patch的大小决定了要分多少组 假如说一个patch内有四个token,那么面积就是4,所有patch中的第一个token之间互相计算自注意力,所有patch中的第二个token之间互相计算自注意力,第三第四同理
x = x.reshape(batch_size, in_channels, num_patches, patch_area)
# [B, C, N, P] -> [B, P, N, C]
# 一共有多少张图片,每张图片中的token分几个组,每个组内有多少token,每个token的维度有多少 至此,需要互相之间需要计算自注意力的token都已经固定在了最后两个维度上
x = x.transpose(1, 3)
# [B, P, N, C] -> [BP, N, C]
# 一张图片有P组,B张图片就是BP组
x = x.reshape(batch_size * patch_area, num_patches, -1)
return x
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号