SCConv:SRU CRU
import torch
import torch.nn.functional as F
import torch.nn as nn
class GroupBatchnorm2d(nn.Module):
def __init__(self, c_num: int,
group_num: int = 16,
eps: float = 1e-10
):
super(GroupBatchnorm2d, self).__init__()
assert c_num >= group_num
self.group_num = group_num
self.weight = nn.Parameter(torch.randn(c_num, 1, 1))
self.bias = nn.Parameter(torch.zeros(c_num, 1, 1))
self.eps = eps
def forward(self, x):
N, C, H, W = x.size()
x = x.view(N, self.group_num, -1)
mean = x.mean(dim=2, keepdim=True)
std = x.std(dim=2, keepdim=True)
x = (x - mean) / (std + self.eps)
x = x.view(N, C, H, W)
return x * self.weight + self.bias
class SRU(nn.Module):
def __init__(self,
oup_channels: int,
group_num: int = 16,
gate_treshold: float = 0.5,
torch_gn: bool = False
):
super().__init__()
self.gn = nn.GroupNorm(num_channels=oup_channels, num_groups=group_num) if torch_gn else GroupBatchnorm2d(
c_num=oup_channels, group_num=group_num)
self.gate_treshold = gate_treshold
self.sigomid = nn.Sigmoid()
def forward(self, x):
gn_x = self.gn(x) # 一个样本的分成若干个group 每个group内部 做归一化
w_gamma = self.gn.weight / torch.sum(self.gn.weight) # 每层的权重除所有层的权重和
w_gamma = w_gamma.view(1, -1, 1, 1) # 修改形状
reweigts = self.sigomid(gn_x * w_gamma) # 将归一化的输入和每层的权重相乘 得到新的权重
# Gate
info_mask = reweigts >= self.gate_treshold # 超过阈值
noninfo_mask = reweigts < self.gate_treshold # 没超过阈值
x_1 = info_mask * gn_x # 超过阈值的信息
x_2 = noninfo_mask * gn_x # 没超过阈值的信息
x = self.reconstruct(x_1, x_2) # 重构两部分信息
return x
def reconstruct(self, x_1, x_2):
x_11, x_12 = torch.split(x_1, x_1.size(1) // 2, dim=1)
x_21, x_22 = torch.split(x_2, x_2.size(1) // 2, dim=1)
return torch.cat([x_11 + x_22, x_12 + x_21], dim=1)
"""
对输入张量 x 进行分组归一化,得到 gn_x。
计算归一化层的权重 w_gamma,并将其形状调整为 (1, -1, 1, 1)。
使用 sigmoid 激活函数对 gn_x 和 w_gamma 的乘积进行激活,得到 reweigts。
根据 reweigts 和 gate_treshold 生成两个掩码:info_mask 和 noninfo_mask。
使用掩码将 gn_x 分成两部分:x_1 和 x_2。
调用 reconstruct 方法对 x_1 和 x_2 进行重建,并返回结果。"""
class CRU(nn.Module):
'''
alpha: 0<alpha<1
'''
def __init__(self,
op_channel: int,
alpha: float = 1 / 2,
squeeze_radio: int = 2,
group_size: int = 2,
group_kernel_size: int = 3,
):
super().__init__()
self.up_channel = up_channel = int(alpha * op_channel)
self.low_channel = low_channel = op_channel - up_channel
self.squeeze1 = nn.Conv2d(up_channel, up_channel // squeeze_radio, kernel_size=1, bias=False)
self.squeeze2 = nn.Conv2d(low_channel, low_channel // squeeze_radio, kernel_size=1, bias=False)
# up
self.GWC = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=group_kernel_size, stride=1,
padding=group_kernel_size // 2, groups=group_size)
self.PWC1 = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=1, bias=False)
# low
self.PWC2 = nn.Conv2d(low_channel // squeeze_radio, op_channel - low_channel // squeeze_radio, kernel_size=1,
bias=False)
self.advavg = nn.AdaptiveAvgPool2d(1)
def forward(self, x):
# Split
up, low = torch.split(x, [self.up_channel, self.low_channel], dim=1) # 特征按dim分两份 up_channel low_channel
up, low = self.squeeze1(up), self.squeeze2(low) # up_channel low_channel 的dim 进一步压缩
# Transform
Y1 = self.GWC(up) + self.PWC1(up) # Y1 dim=32 直接还原为初始维度也就是输入的x的dim
Y2 = torch.cat([self.PWC2(low), low], dim=1) # 也还原为初始dim
# Fuse
out = torch.cat([Y1, Y2], dim=1) # 拼接完成 得到两倍的x的dim
out = F.softmax(self.advavg(out), dim=1) * out # 还是在算每个通道的权重
out1, out2 = torch.split(out, out.size(1) // 2, dim=1) # 将两倍的通道的特征图分成两份
return out1 + out2 # 相加 还原成初始dim
class ScConv(nn.Module):
def __init__(self,
op_channel: int,
group_num: int = 4,
gate_treshold: float = 0.5,
alpha: float = 1 / 2,
squeeze_radio: int = 2,
group_size: int = 2,
group_kernel_size: int = 3,
):
super().__init__()
self.SRU = SRU(op_channel,
group_num=group_num,
gate_treshold=gate_treshold)
self.CRU = CRU(op_channel,
alpha=alpha,
squeeze_radio=squeeze_radio,
group_size=group_size,
group_kernel_size=group_kernel_size)
def forward(self, x):
x = self.SRU(x)
x = self.CRU(x)
return x
if __name__ == '__main__':
x = torch.randn(3, 32, 64, 64).cuda() # 输入 B C H W
model = ScConv(32).cuda()
print(model(x).shape)
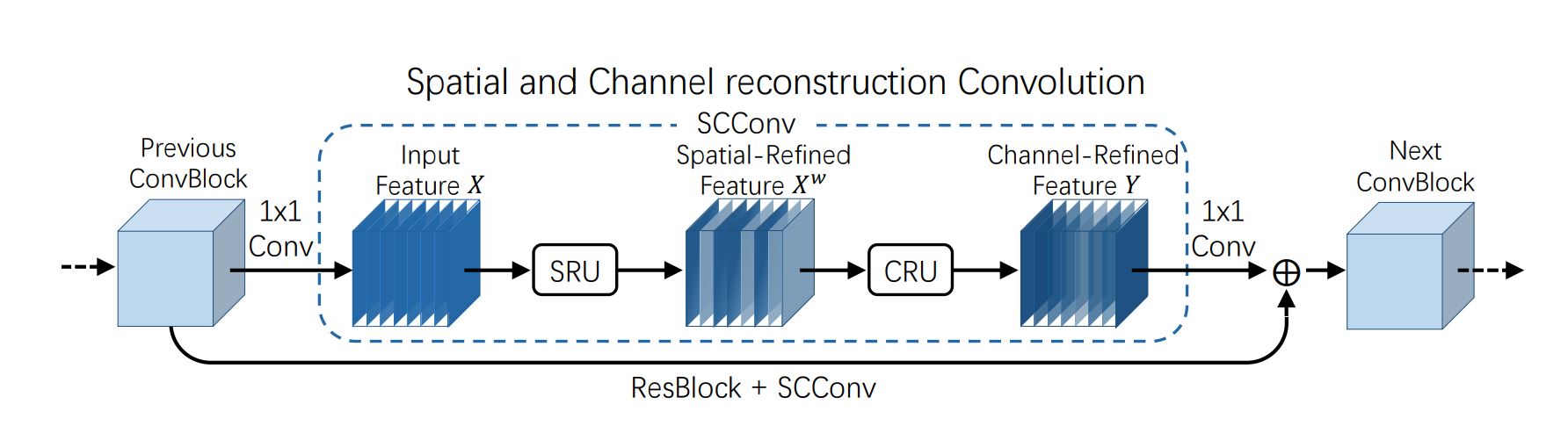
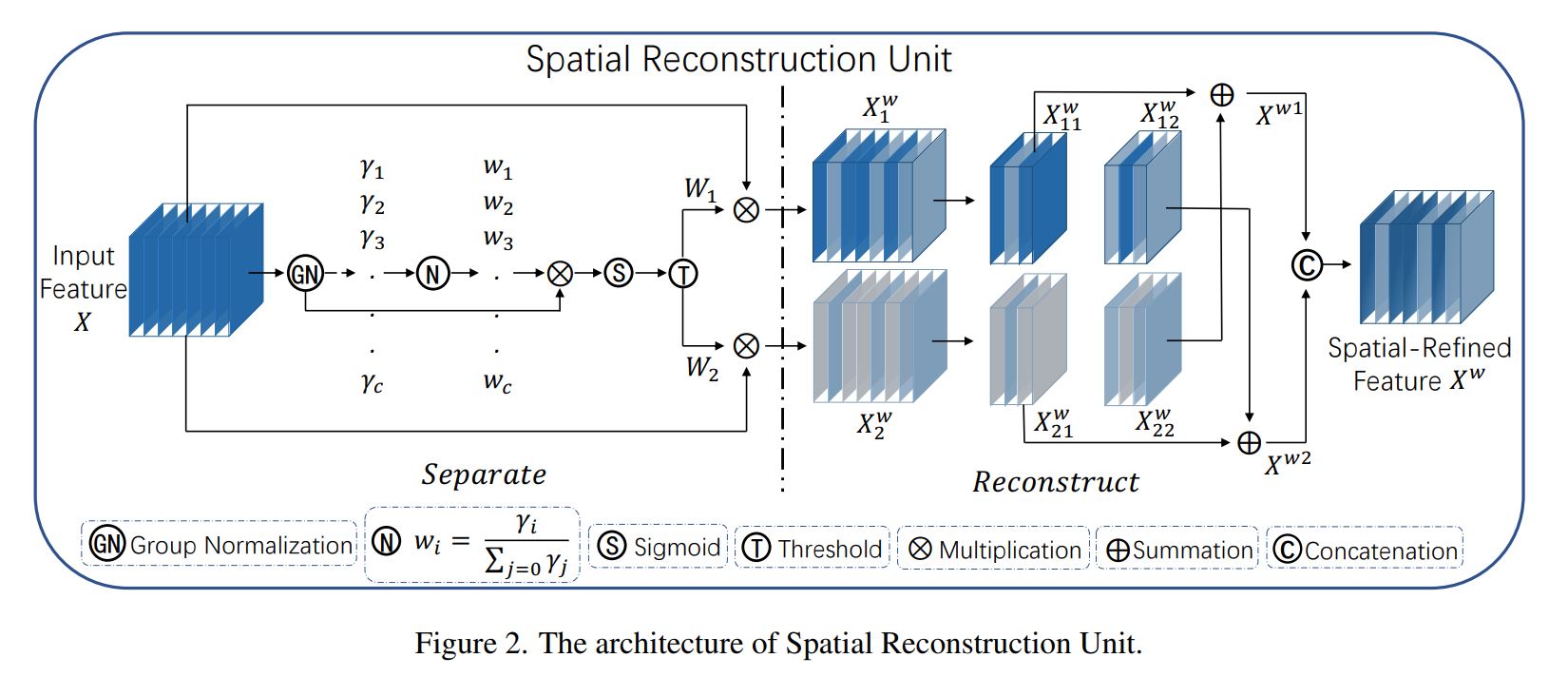
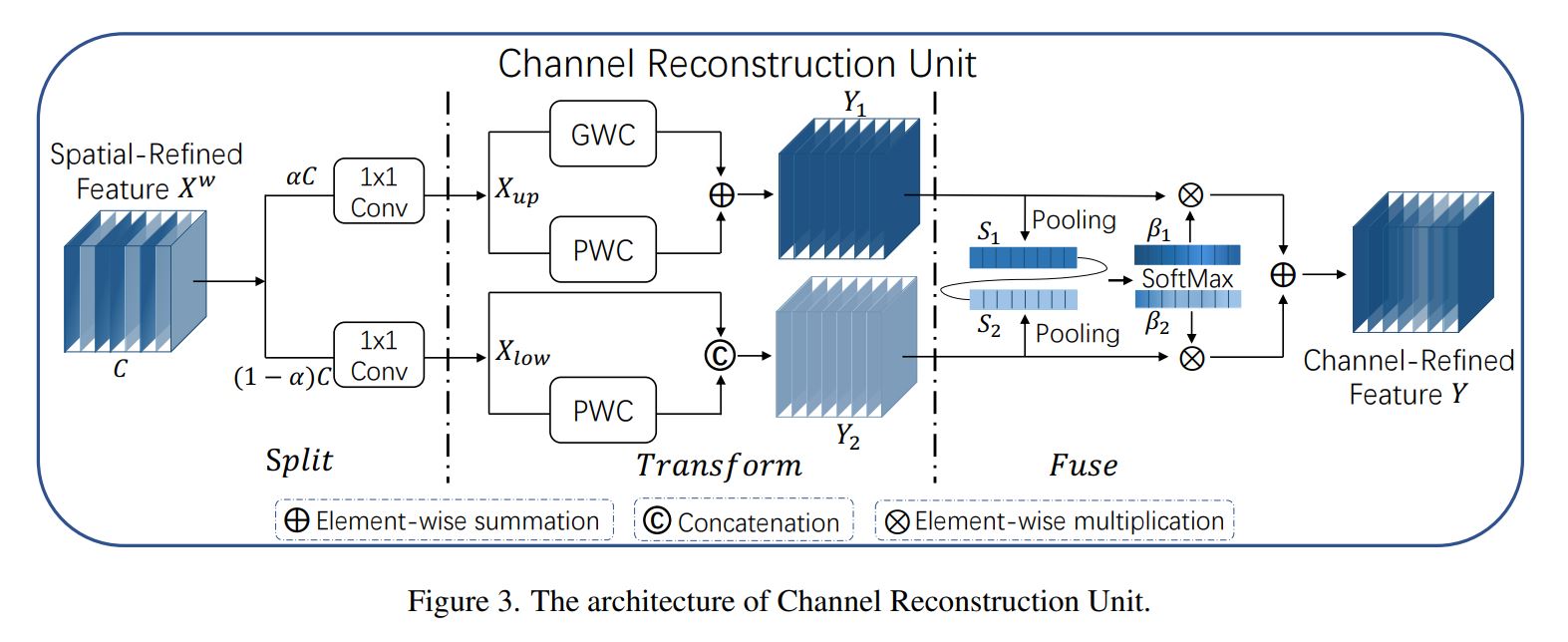

 浙公网安备 33010602011771号
浙公网安备 33010602011771号