MOGANET-CA模块
paper
(1) 前向路径
fc1 和 dwconv:
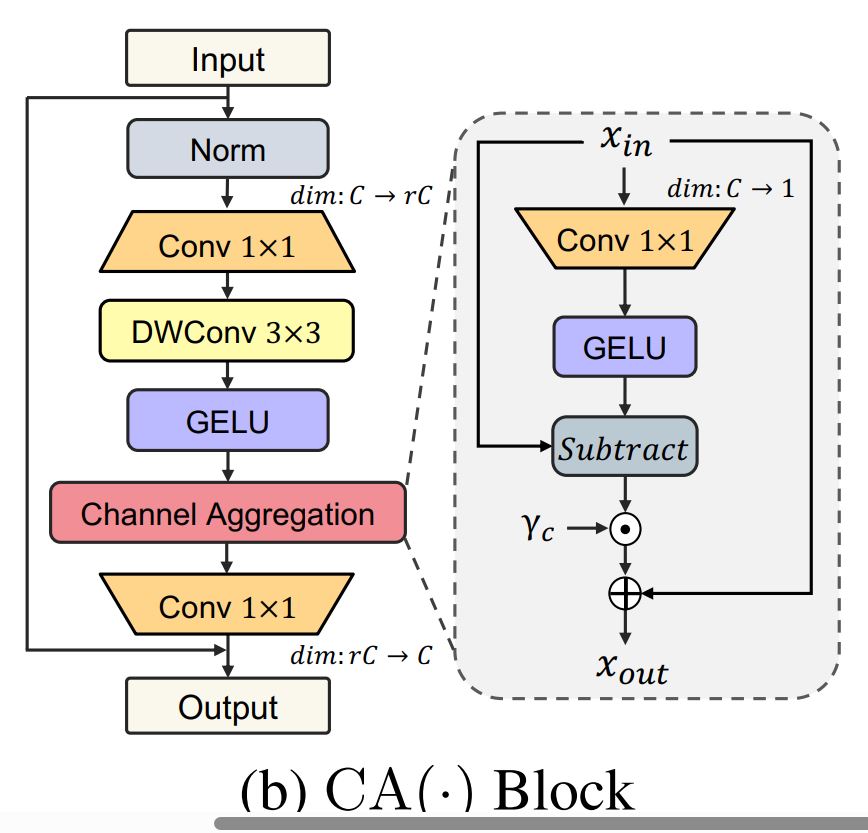
第一部分是一个标准的 ConvFFN 模块,先用逐点卷积(fc1)将输入特征维度扩展为 4 倍的 feedforward_channels,然后通过深度卷积(dwconv)增强局部特征提取能力。
act 和 drop:
在激活函数后使用 dropout,增强泛化能力。
(2) 特征分解
特征分解 (feat_decompose) 是模块的核心亮点:
全局特征生成:
使用一个逐点卷积(decompose)生成单通道全局特征图 (t),通过 GELU 激活增强非线性建模能力。
特征去偏与差异信息提取:
原始特征减去全局特征 (x - t),提取局部差异信息。
可学习缩放:
使用 ElementScale 调节特定特征的重要性,为每个通道分配动态权重。
特征重整合:
将调整后的特征加回原始特征 (x + t),保留了全局特征,同时增强了局部信息。
这一设计增强了模型在局部细节和全局特征间的权衡能力。
(3) 第二阶段投影
fc2:
最后一层逐点卷积将通道数投影回原始维度,完成特征变换。
import torch
import torch.nn as nn
def build_act_layer(act_type):
#Build activation layer
if act_type is None:
return nn.Identity()
assert act_type in ['GELU', 'ReLU', 'SiLU']
if act_type == 'SiLU':
return nn.SiLU()
elif act_type == 'ReLU':
return nn.ReLU()
else:
return nn.GELU()
class ElementScale(nn.Module):
#A learnable element-wise scaler.
def __init__(self, embed_dims, init_value=0., requires_grad=True):
super(ElementScale, self).__init__()
self.scale = nn.Parameter(
init_value * torch.ones((1, embed_dims, 1, 1)),
requires_grad=requires_grad
)
def forward(self, x):
return x * self.scale
class ChannelAggregationFFN(nn.Module):
"""An implementation of FFN with Channel Aggregation.
Args:
embed_dims (int): The feature dimension. Same as
`MultiheadAttention`.
feedforward_channels (int): The hidden dimension of FFNs.
kernel_size (int): The depth-wise conv kernel size as the
depth-wise convolution. Defaults to 3.
act_type (str): The type of activation. Defaults to 'GELU'.
ffn_drop (float, optional): Probability of an element to be
zeroed in FFN. Default 0.0.
"""
def __init__(self,
embed_dims,
kernel_size=3,
act_type='GELU',
ffn_drop=0.):
super(ChannelAggregationFFN, self).__init__()
self.embed_dims = embed_dims
self.feedforward_channels = int(embed_dims * 4)
self.fc1 = nn.Conv2d(
in_channels=embed_dims,
out_channels=self.feedforward_channels,
kernel_size=1)
self.dwconv = nn.Conv2d(
in_channels=self.feedforward_channels,
out_channels=self.feedforward_channels,
kernel_size=kernel_size,
stride=1,
padding=kernel_size // 2,
bias=True,
groups=self.feedforward_channels)
self.act = build_act_layer(act_type)
self.fc2 = nn.Conv2d(
in_channels=self.feedforward_channels,
out_channels=embed_dims,
kernel_size=1)
self.drop = nn.Dropout(ffn_drop)
self.decompose = nn.Conv2d(
in_channels=self.feedforward_channels, # C -> 1
out_channels=1, kernel_size=1,
)
self.sigma = ElementScale(
self.feedforward_channels, init_value=1e-5, requires_grad=True)
self.decompose_act = build_act_layer(act_type)
def feat_decompose(self, x):
# x_d: [B, C, H, W] -> [B, 1, H, W]
t=self.decompose(x) # 将多通道用一个通道来表示
t=self.decompose_act(t) # 对单通道应用GELU激活函数 增加非线性 帮助模型学习更加复杂的模式
t=x - t #原始特征图减去t 去除或削弱了x与temp相似的特征 如果t是全局或主要特征 那么x-t可以理解成局部或差异信息
t=self.sigma(t) # 包含一个可学习的参数 用来调整每个通道的权重
x = x + t # 将原特征图和缩放之后的特定信息相加
return x
def forward(self, x):
# proj 1
x = self.fc1(x)
x = self.dwconv(x)
x = self.act(x)
x = self.drop(x)
# proj 2
x = self.feat_decompose(x)
x = self.fc2(x)
x = self.drop(x)
return x
if __name__ == '__main__':
input = torch.randn(1, 64, 32, 32).cuda()# 输入 B C H W
block = ChannelAggregationFFN(embed_dims=64).cuda()
output = block(input)
print(input.size())
print(output.size())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号