论文
代码
import torch
import torch.nn as nn
from functools import partial
from torch.nn.init import trunc_normal_
import math
from timm.models.helpers import named_apply
def act_layer(act, inplace=False, neg_slope=0.2, n_prelu=1):
# activation layer
act = act.lower()
if act == 'relu':
layer = nn.ReLU(inplace)
elif act == 'relu6':
layer = nn.ReLU6(inplace)
elif act == 'leakyrelu':
layer = nn.LeakyReLU(neg_slope, inplace)
elif act == 'prelu':
layer = nn.PReLU(num_parameters=n_prelu, init=neg_slope)
elif act == 'gelu':
layer = nn.GELU()
elif act == 'hswish':
layer = nn.Hardswish(inplace)
else:
raise NotImplementedError('activation layer [%s] is not found' % act)
return layer
def _init_weights(module, name, scheme=''):
if isinstance(module, nn.Conv2d) or isinstance(module, nn.Conv3d):
if scheme == 'normal':
nn.init.normal_(module.weight, std=.02)
if module.bias is not None:
nn.init.zeros_(module.bias)
elif scheme == 'trunc_normal':
trunc_normal_(module.weight, std=.02)
if module.bias is not None:
nn.init.zeros_(module.bias)
elif scheme == 'xavier_normal':
nn.init.xavier_normal_(module.weight)
if module.bias is not None:
nn.init.zeros_(module.bias)
elif scheme == 'kaiming_normal':
nn.init.kaiming_normal_(module.weight, mode='fan_out', nonlinearity='relu')
if module.bias is not None:
nn.init.zeros_(module.bias)
else:
# efficientnet like
fan_out = module.kernel_size[0] * module.kernel_size[1] * module.out_channels
fan_out //= module.groups
nn.init.normal_(module.weight, 0, math.sqrt(2.0 / fan_out))
if module.bias is not None:
nn.init.zeros_(module.bias)
elif isinstance(module, nn.BatchNorm2d) or isinstance(module, nn.BatchNorm3d):
nn.init.constant_(module.weight, 1)
nn.init.constant_(module.bias, 0)
elif isinstance(module, nn.LayerNorm):
nn.init.constant_(module.weight, 1)
nn.init.constant_(module.bias, 0)
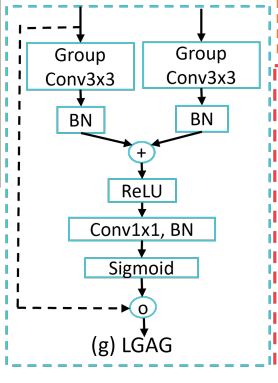
# Large-kernel grouped attention gate (LGAG)
class LGAG(nn.Module):
'''
结合特征图与注意力系数,激活高相关性特征,高层特征的门控信号来控制网络不通阶段间的信息流动
在LAGA机制中,能够有效地融合来自skip链接的信息,以更少的计算在更大的局部上下文中捕获显著的特征。
用在需要将两个shape相同的tensor融合的地方。
'''
def __init__(self, F_g, F_l, F_int, kernel_size=3, groups=1, activation='relu'):
super(LGAG, self).__init__()
if kernel_size == 1:
groups = 1
self.W_g = nn.Sequential(
nn.Conv2d(F_g, F_int, kernel_size=kernel_size, stride=1, padding=kernel_size // 2, groups=groups,
bias=True),
nn.BatchNorm2d(F_int)
)
self.W_x = nn.Sequential(
nn.Conv2d(F_l, F_int, kernel_size=kernel_size, stride=1, padding=kernel_size // 2, groups=groups,
bias=True),
nn.BatchNorm2d(F_int)
)
self.psi = nn.Sequential(
nn.Conv2d(F_int, 1, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
self.activation = act_layer(activation, inplace=True)
self.init_weights('normal')
def init_weights(self, scheme=''):
named_apply(partial(_init_weights, scheme=scheme), self)
def forward(self, g, x):
g1 = self.W_g(g)
x1 = self.W_x(x)
psi = self.activation(g1 + x1)
psi = self.psi(psi)
return x * psi
if __name__ == '__main__':
in_dim=128
width=4
hidden_dim=in_dim//width
block = LGAG(in_dim,in_dim,hidden_dim).cuda()
g = torch.randn(3,128,64,64).cuda() #输入 B C H W
x = torch.randn(3,128,64,64).cuda() #输入 B C H W
output = block(g,x)
print(input.size())
print(output.size())