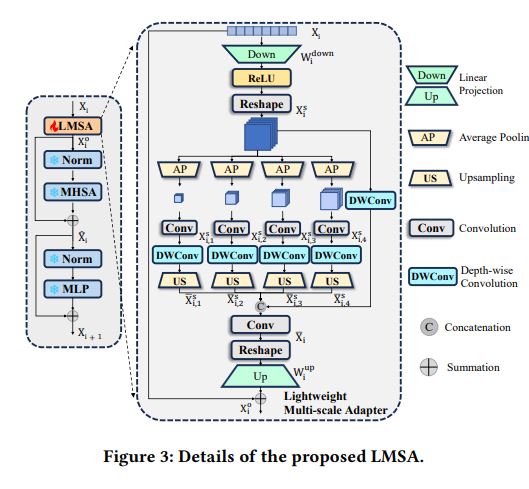
Multi-Scale and Detail-Enhanced Segment Anything-1-LMSA-轻量级多尺度适配器
用自适应的全局平均池化获得不同尺寸的大小(设置的值就是每层经过池化之后的大小) 再用上采样 让不同尺寸的特征图来到原始大小上 然后将它们和原特征图在深度方面叠加
代码
论文
import torch.nn as nn
import torch
import torch.nn.functional as F
class ModifyPPM(nn.Module):
def __init__(self, in_dim, reduction_dim, bins):
super(ModifyPPM, self).__init__()
self.features = []
for bin in bins:
self.features.append(nn.Sequential(
nn.AdaptiveAvgPool2d(bin),
nn.Conv2d(in_dim, reduction_dim, kernel_size=1),
nn.GELU(),
nn.Conv2d(reduction_dim, reduction_dim, kernel_size=3, bias=False, groups=reduction_dim),
nn.GELU()
))
self.features = nn.ModuleList(self.features)
self.local_conv = nn.Sequential(
nn.Conv2d(in_dim, in_dim, kernel_size=3, padding=1, bias=False, groups=in_dim),
nn.GELU(),
)
def forward(self, x):
x_size = x.size() # shape: 1 64 16 16
out = [self.local_conv(x)] # shape: 1 64 16 16
for f in self.features:
y=f(x) # 获得不同尺寸的特征 通过自适应全局平均池化来实现 传入一个大小 这个大小就是最后输出特征图的大小
y=F.interpolate(y, x_size[2:], mode='bilinear', align_corners=True) #将特征图的宽高再通过插值的方法变成和输入的宽高一样
out.append(y) # 记录这个尺寸对应的特征
return torch.cat(out, 1) #将所有尺寸的特征在深度方向进行融合 返回的结果中包含原本的输入和输入在四个尺寸上的特征,而四个尺寸的特征图的深度都是原来的四分之一,四个加在一起刚好和原来的深度相同,也就是说返回的特征图的深度是两倍的输入深度
class LMSA(nn.Module):
def __init__(self, in_dim, hidden_dim, patch_num):
super().__init__()
self.down_project = nn.Linear(in_dim,hidden_dim)
self.act = nn.GELU()
self.mppm = ModifyPPM(hidden_dim, hidden_dim //4, [3,6,9,12])
self.patch_num = patch_num
self.up_project = nn.Linear(hidden_dim, in_dim)
self.down_conv = nn.Sequential(nn.Conv2d(hidden_dim*2, hidden_dim, 1),
nn.GELU())
def forward(self, x):
down_x = self.down_project(x) # dim 128 ->64
down_x = self.act(down_x)
down_x = down_x.permute(0, 3, 1, 2).contiguous() # B C H W
down_x = self.mppm(down_x).contiguous()
# 感觉下面有点啰嗦了 返回的是2*hidden_dim 直接用1*1的卷积修改通道数和输入相加就行
down_x = self.down_conv(down_x) # 因为返回的特征图的深度被翻倍了 这里再降下来
down_x = down_x.permute(0, 2, 3, 1).contiguous() # 将通道数移动到最后一个维度
up_x = self.up_project(down_x) # 升维 使其和输入的x相同 为了后一步的元素相加
return x + up_x
if __name__ == '__main__':
in_dim=128
hidden_dim=64
patch_num=16
block = LMSA(in_dim,hidden_dim,patch_num).cuda()
input = torch.randn(1, patch_num, patch_num, in_dim).cuda() #输入 B C H W
output = block(input)
print(input.size())
print(output.size())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号