国产PLC软件PikePLC——编译器介绍
针对PikePLC的编译器,此处只作简单的介绍,毕竟要想详细介绍编译器需要很长的篇幅。
在PikePLC中内置了四款编译器,分别是:
- 将梯形图编写的POU转换为ST语言的编译器;
- 将用FBD编写的POU转换为ST语言的编译器;
- 将ST语言转换为C头文件和源文件的编译器;
- 开源的GNU编译器,将C文件编译为最终在目标环境中运行的二进制文件。
针对Ladder和FBD转换为ST语言的编辑器,实现起来比较简单,基本上就是根据Ladder和FBD的模型,分析出逻辑关系,然后将其转换为对应的ST语句即可。
而真正有技术难度的是ST编译器。PikePLC所使用的StructuredText(ST)编译器基于Eclipse开源基金会的xtext(
https://www.eclipse.org/Xtext/)项目开发。至于xtext项目的介绍以及使用,读者可以前往其官网进行查看,这里就不再准备介绍它。
基于xtext最重要的就是实现描述ST语言词法和语法规则的.xtext文件。然后是基于规则文件进行一些语法分析以及语法检查的功能扩展。其实xtext已经为开发者做了很多工作,所以实现起来也会事半功倍。
PikePLC基于xtext实现的词法和语法模型,包含了IEC61131-3 v2.0中描述的PLC软件模型,按照范围从大到小以及组织层级关系,分为:
- 配置-CONFIGURATION
- 资源-RESOURCE
- 任务-TASK
- POU-PROGRAM、FB、FC统称为POU
- 当然还有用户自定义数据类型、全局变量以及变量地址配置等
然后就是基于xtext构建的模型,对ST代码进行语法分析,如:类型匹配分析、调用关系分析、循环依赖分析、变量使用分析等等。
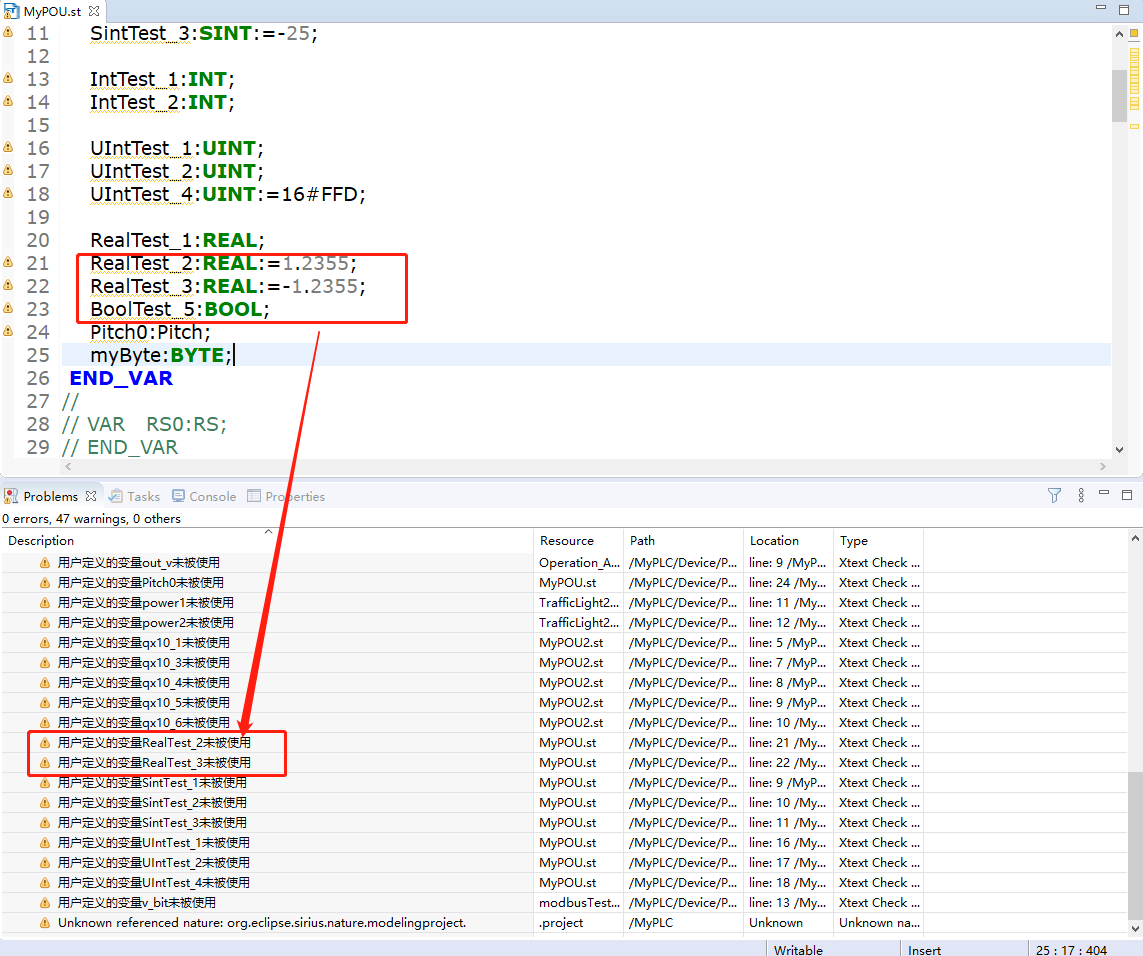
下图:检测在POU中被定义但未被使用的变量
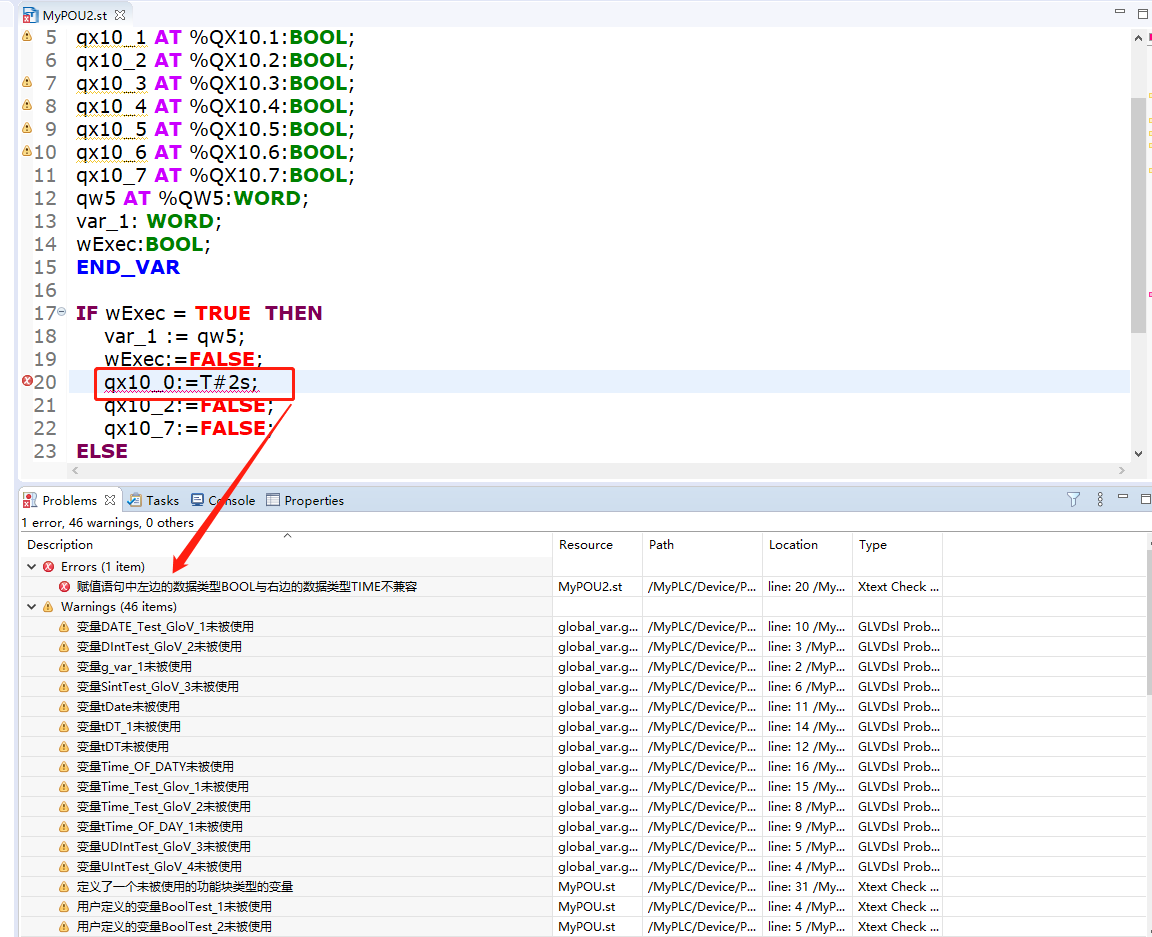
下图:数据类型匹配分析
然后是基于xtext构建的语法模型,生成对应的C头文件和源文件
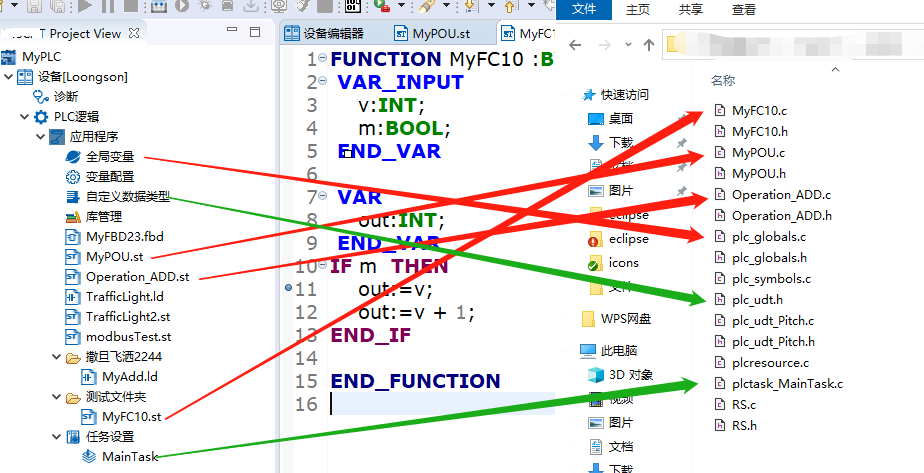
下图:ST文件与C文件对应关系
最后调用GCC交叉编译工具链,将生成的一堆C文件编译为在Linux上可运行的二进制文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号