

Postgres-XL的限制
Postgres-XL是基于PostgreSQL的一个分布式数据库。
相比于PostgreSQL,XL的表的数据是可以分布到不同的datanode上的,对存在于不同的datanode上的数据进行处理,目前还存在很多限制。当然可能在以后的新版本中,会突破这些限制。
下面针对postgres-xl-10r1版本进行测试,看看目前还存在哪些限制。
1. 分布建不能更新
1 select * from test2; 2 id | name 3 ----+------ 4 1 | 1 5 2 | 2 6 5 | 5 7 3 | 3 8 4 | 4 9 (5 rows) 10 11 postgres=# update test2 set name='b' where id=2; 12 UPDATE 1 13 14 postgres=# update test2 set id=5 where name='5'; 15 2018-11-07 18:13:49.533 CST [1831] ERROR: could not plan this distributed update 16 2018-11-07 18:13:49.533 CST [1831] DETAIL: correlated UPDATE or updating distribution column currently not supported in Postgres-XL. 17 2018-11-07 18:13:49.533 CST [1831] STATEMENT: update test2 set id=5 where name='5'; 18 ERROR: could not plan this distributed update 19 DETAIL: correlated UPDATE or updating distribution column currently not supported in Postgres-XL. 20 21 postgres=# select * from test2; 22 id | name 23 ----+------ 24 1 | 1 25 5 | 5 26 2 | b 27 3 | 3 28 4 | 4 29 (5 rows)
2. 复杂查询
在PostgreSQL,表数据只放在一台pc上,当两个表关联查询时,可以直接获取到表数据进行join。但是在Postgres-XL中,表数据是分布在不同的datanode上,datanode又可能分布在不同的pc上;这时候两个表进行关联查询需要从不同的datanode之间进行,如果是多个表进行关联查询,情况更加复杂了。
2.1 非分布键作为条件限制
1 postgres=# select * from test1,test2; 2 id | name | id | name 3 ----+------+----+------ 4 1 | a | 1 | 1 5 . 6 . 7 . 8 2 | b | 2 | b 9 . 10 . 11 . 12 4 | d | 4 | 4 13 (40 rows) 14 15 postgres=# select * from test1,test2 where test1.name='b' and test2.name='b'; 16 id | name | id | name 17 ----+------+----+------ 18 2 | b | 2 | b 19 (1 row) 20 21 postgres=# select * from test1,test2 where test1.name=test2.name; 22 2018-11-08 11:08:08.939 CST [1510] ERROR: cannot wait on a latch owned by another process 23 2018-11-08 11:08:08.939 CST [1405] LOG: server process (PID 1510) was terminated by signal 11: Segmentation fault 24 2018-11-08 11:08:08.939 CST [1405] DETAIL: Failed process was running: Remote Subplan 25 2018-11-08 11:08:08.939 CST [1405] LOG: terminating any other active server processes 26 2018-11-08 11:08:08.940 CST [1436] WARNING: terminating connection because of crash of another server process 27 . 28 . 29 .
当where条件中直接判断两个表字段是否相等时,报错。多次尝试后,还出现过其他错误(例如:“ERROR: Couldn't resolve SQueue race condition after 10 tries”),有时候也能执行成功,证明这一查询还是存在很大的问题。
2.2 非亲和表的限制
亲和表,即两张表的分布类型和分布键都一致,称这两张表为亲和表。
表test3和表test4都是以id列作为分布键、分布类型为Modulo,test3和test4是亲和表。
1 postgres=# \d+ test3 2 Table "public.test3" 3 Column | Type | Collation | Nullable | Default | Storage | Stats target | Description 4 --------+---------+-----------+----------+-----------------------------------+----------+--------------+------------- 5 id | integer | | not null | nextval('test3_id_seq'::regclass) | plain | | 6 name | text | | | | extended | | 7 Indexes: 8 "test3_pkey" PRIMARY KEY, btree (id) 9 Distribute By: MODULO(id) 10 Location Nodes: ALL DATANODES 11 12 postgres=# \d+ test4 13 Table "public.test4" 14 Column | Type | Collation | Nullable | Default | Storage | Stats target | Description 15 --------+---------+-----------+----------+---------+---------+--------------+------------- 16 id | integer | | | | plain | | 17 Distribute By: MODULO(id) 18 Location Nodes: ALL DATANODES 19 20 postgres=# select * from test3 order by id; 21 id | name 22 ----+------ 23 1 | a 24 2 | b 25 3 | cc 26 4 | dd 27 5 | ee 28 6 | ff 29 (6 rows) 30 31 postgres=# select * from test4 order by id; 32 id 33 ---- 34 1 35 2 36 4 37 6 38 8 39 (5 rows) 40 41 postgres=# select * from test4 a inner join test3 b on a.id=b.id order by a.id; 42 id | id | name 43 ----+----+------ 44 1 | 1 | a 45 2 | 2 | b 46 4 | 4 | dd 47 6 | 6 | ff 48 (4 rows)
下面是非亲和表test2与test4的内连接查询。结果是不正确的,而且有时执行查询会报错。
1 postgres=# \d+ test2 2 Table "public.test2" 3 Column | Type | Collation | Nullable | Default | Storage | Stats target | Description 4 --------+---------+-----------+----------+---------+----------+--------------+------------- 5 id | integer | | not null | | plain | | 6 name | text | | | | extended | | 7 Indexes: 8 "test2_pkey" PRIMARY KEY, btree (id) 9 Distribute By: HASH(id) 10 Location Nodes: ALL DATANODES 11 12 postgres=# select * from test2 order by id; 13 id | name 14 -----+------ 15 1 | 1 16 2 | b 17 3 | 3 18 4 | 4 19 5 | 5 20 6 | 21 111 | 22 112 | 23 (8 rows) 24 25 postgres=# select * from test2 a inner join test4 b on a.id=b.id order by a.id; 26 2018-11-08 15:09:19.389 CST [1206] WARNING: Unexpected data on connection, cleaning. 27 id | name | id 28 ----+------+---- 29 2 | b | 2 30 4 | 4 | 4 31 6 | | 6 32 (3 rows)
同样,outer join也存在一样的问题,不支持非亲和表的关联查询。但是,非亲和表可以进行cross join关联查询(没有where条件)。
2.3 子查询限制
子查询也受到非亲和表的限制,与2.2的情况基本一致,就不再去说明了。
特殊说明:2.2和2.3中提到非亲和表的限制问题,我后来增加了一个节点datanode3。结果再进行非亲和表关联时都正常了,没有再报错(上面提到有两个报错),查出来的结果也完全正确。这什么情况,郁闷。后来再尝试把节点datanode3从集群中删掉,也没有重现分亲和表限制的问题。
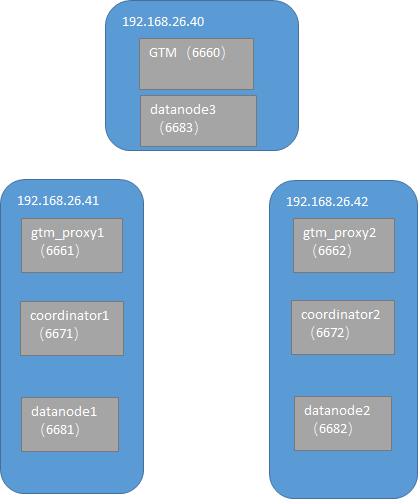
3. 支持特性
这里顺便提一下Postgres-XL支持的特性吧,方便记录一下在测试过程中测试到的项。
- CTE(通用表表达式),支持,但是里面的sql也受到上面提到的限制问题;
- Windows function,支持,同上;
- 集合操作,支持,同上;
- 非分片列count(distinct),支持;
- 支持跨分片更新;
- 支持跨分片事务;
总结
这次针对Postgres-XL去调研它目前存在的限制,主要还是在查询上限制比较大。在测试过程中,没有对所有的sql功能进行测试,也没有太深入去研究。
如果在以上说明存在的限制(或者支持特性)有不符合pgxl实际情况的,可能是我个人的错误,欢迎大牛指出。
希望Postgres-XL在以后的版本中,能把这些限制给解决掉,越做越完善。
