

文件的读取
open(name,mode,encoding)
name:是打开目标文件名的字符串(可以包含文件所在路径)
mode:设置打开文件的模式(访问模式):只读r、只写w(如果没有文件会重新创建)、追加等
encoding:编码格式(推荐使用UTF-8)

1、读操作
read()方法
文件名.read(num)
num表示要从文件中读取的数据长度(单位是字节),如果没有传入num,就表示读取文件中所有数据
readlines()方法
将文件中的内容进行一次性读取,并且返回的是一个列表,每一行的数据为一个元素
read 和readline 会续接上一次读取内容
readline()方法:一次读取一行
for循环读取文件行
for line in open('python.txt','r')
print(line)
#每一个line临时变量,就记录了文件的一行数据
close()关闭文件对象
f.close()
with open语法
with open('python.txt','r') as f:
f.readlines()
#可以在操作完成后自动关闭close文件,避免遗忘close方法
#通过在with open的语句块中对文件进行操作

点击查看代码
单词计数
#我的思路
with open('D:/word.txt','r',encoding='UTF-8') as f:
print(f'itheima出现的次数为{f.read().count ('itheima')}次')
#老师思路
#打开文件,以读取模式打开
f=open('D:/word.txt','r',encoding='UTF-8')
#方式1:读取全部内容,通过字符串count方法统计iteima单词数量
# content=f.read()
# count=content.count('itheima')
# print(f'itheima在文件中出现了:{count}次')
#方式2:读取内容,一行一行读取
count=0 #使用count变量 来累计itheima出现的次数
for line in f:
line=line.strip() #去除开头和结尾的空格以及换行
words=line.split(' ')
for word in words:
if word=='itheima':
count+=1 #如果单词是itheima,就进行数量的累加加1
#判断单词出现次数并累计
print(f'itheima出现次数是{count}')
#关闭文件
f.close()
2、写操作
#1、打开文件,通过w模式打开
f=open('python.txt','w')
#2、文件写入
f.write('字符串')
#3、内容刷新
f.flush()
直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
当调用flush的时候,内容会真正写入文件
点击查看代码
文件的写入
# f=open('D:/test.txt','w',encoding='UTF-8')
# #write写入
# f.write('Hello World') #内容写入到内存中
# #flush刷新
# #f.flush() #将内存中积攒的内容写入硬盘中
# #close关闭
# f.close() #close方法,内置了flush功能
f=open('D:/test.txt','w',encoding='UTF-8')
#write写入,flush刷新
f.write('黑马程序员')
#close关闭
f.close()
3、追加
#1、打开文件,通过a模式打开
f=open('python.txt','a')
#2、文件写入
f.write('字符串')
#3、内容刷新
f.flush()
点击查看代码
文件的追加
#打开文件,不存在的文件
# f=open('D:/test.txt','a',encoding='UTF-8')
# #write写入
# f.write('黑马程序员')
# #flush刷新
# f.flush()
# #close关闭
# f.close()
#打开一个存在的文件
f=open('D:/test.txt','a',encoding='UTF-8')
#write写入,flush刷新
f.write('学Python的最佳选择')
f.write('\n月薪过万')
#close关闭
f.close()
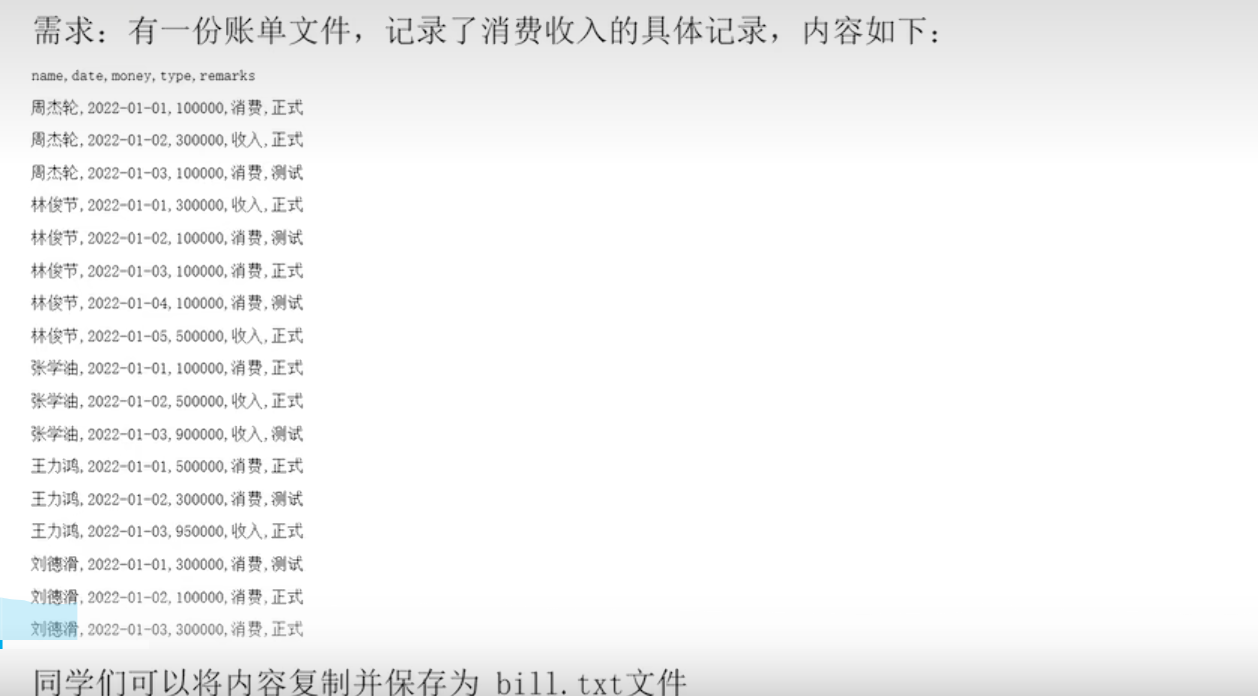

点击查看代码
文件备份
# #我的思路
# #读取文件
# f=open('D:/bill.txt','r',encoding='UTF-8')
# for line in f:
# if '测试' not in line:
# f1=open('D:/bill.txt.bak','a',encoding='UTF-8')
# f1.write(line)
# f1.close()
# #老师思路
#打开文件得到文件对象,准备读取
fr=open('D:/bill.txt','r',encoding='UTF-8')
##打开文件得到文件对象,准备写入
fw=open('D:/bill.txt.bak','w',encoding='UTF-8')
#for循环读取文件
for line in fr:
line=line.strip()
#判断内容,将满足的内容写出
if line.split(',')[-1]=='测试':
continue
#将内容写出去
fw.write(line)
#由于前面对内容进行了strip()的操作,所以要手动的写出换行符
fw.write('\n')
#close2个文件对象
fr.close()
fw.close()

