人工智能基础笔记 · Part C 群体智能和强化学习
C6 群体智能
核心思路 :大自然中的一些社会系统尽管由简单的个体组成,却表现出智能的集体行为。称 Agents 为“智能体”。
对问题的智能解决方案,自然地涌现于这些个体的自组织和交流之中。整个系统的行为是自下而上的,遵循简单规则的简单 Agents 生成复杂的结构/行为,且 Agents 不遵循某个领导者的命令。
通信特征:不能全局交换信息,只能局部交换信息。
基本概念
Boid Rules
-
分离(Separation)
- 避免与邻近同伴太接近。这条规则使得每个个体避免与附近的其他个体碰撞,维持一定的距离。
-
对齐(Alignment):
- 与邻近同伴保持相同的移动方向。个体会调整自己的方向和速度,以匹配周围个体的平均方向和速度。
-
聚集(Cohesion):
- 向邻近同伴的平均位置移动。这使得个体趋向于向群体的中心移动,促进群体的聚集。
基本构成
-
Agents 智能体
- Interact with the world and with each other (either directly or indirectly)
-
Simple behaviours 简单的行为
- e.g. ants, termites, bees, wasps
-
Communication 通信
- How agents interact with each other. e.g. pheromones of ants
总结来看,个体 Agents 的简单行为 + Agents 群体之间的通信 = 群体 Agents 的复杂涌现行为。
基本特点
-
分布式,没有中央控制或数据源 Distributed, no central control or data source。
-
有限的通信。Limited communication。
-
没有(显式的)环境模型。No (explicit) model of the environment。
-
对环境存在感知。Perception of environment (sensing)。
-
对环境变化做出反应的能力。Ability to react to environment changes。
往往采取如下思路来抽象出一种算法来:
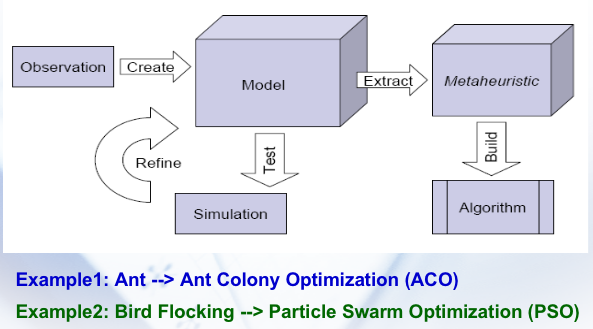
通信 Communication

基本的通信思路
- 计算机通信
在计算机科学中,通信可以通过共享内存或消息传递来实现。共享内存涉及多个处理单元共享相同的内存空间,而消息传递则涉及通过发送和接收消息进行通信。
- 群体智能中的通信
在群体智能系统中,通信不仅仅是简单的信息传递,而是意味着相互作用。环境提供了一个计算基础设施,其中 Agents 之间发生相互作用。这个基础设施包括 Agents 之间通信的协议以及 Agents 相互作用的协议。
- 低级通信
涉及简单信号和痕迹的传递,通常是一些基本的信息传递形式。
- 高级通信
涉及认知 Agents ,通常被视为有意图的系统,更复杂,更灵活。
- 直接通信 vs. 间接通信
直接通信是指 Agents 之间直接的信息传递,而间接通信可能涉及其他媒介或者通过环境中介来实现。
间接通信
类似 Share Memory 的形式。个体的消息均发送到 Blackboard。

直接通信
这一部分需要做到一个 Actor Language,每个 Actor 接收到一个消息后会做一系列动作。
Speech Acts
言语行为有三个方面:
-
Locution(言词)= 说话者的物理表达。
-
Illocution(言外之意)= 说话者的意图含义(履行性的)。
-
Prelocution(言后之果)= 由言词引起的动作。
也有不少模型在研究这个问题。shared languages,有 KIF, KQML, DAML。service models 的 DAML-S 等。
蚁群算法 ACO
Ant Colony Optimization。基于间接通信和信息素。
简单来说,一只孤立的蚂蚁会随机移动,但当它发现信息素踪迹时,这只蚂蚁很可能会决定跟随该踪迹。这个概率取决于信息素的浓度。
同时,一只寻找食物的蚂蚁会在其路线上沉积信息素。当它找到食物来源(目标)时,它会返回巢穴以加强其踪迹。因此,其他蚂蚁更有可能开始追踪这条踪迹,从而在其上释放更多的信息素。蚂蚁在每条走过的路径上都会留下信息素。如果一条路径比另一条短,那么蚂蚁会更快地在这条路径上往返,并且因此在较短的时间内留下更多的信息素。
这个过程就像一个正反馈循环系统,因为路径上的信息素强度越高,蚂蚁开始穿过它的可能性就越高。
解决 TSP 问题
设第 只蚂蚁在 时刻位于点 上,那么它会等概率地向邻居走:
其中 Q 是信息素总量,L 是总的路径的长度。这个的意思是,我们每次加信息素是以路径为单位加的(从起点回到起点,TSP)。
另外, 是 这条边的信息素, 可以是边权也可以是某种启发式的长度, 是走 的概率,上角标 表示第 只蚂蚁, 是 的邻居集合。
大概就这样:

解决 JSSP 问题
Btw,蚁群算法也可以来解决 Job Shop Scheduling (JSSP),即作业车间调度问题。

转化成图问题即可:
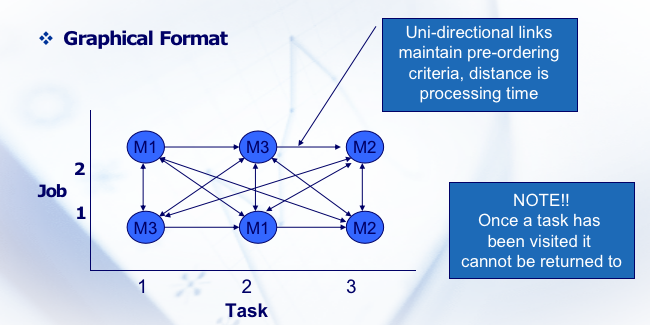

这样一来就还是 TSP 问题了。
一些扩展
接下来是一些基于启发式思路的优化。
1. Elitist Strategy for Ant Systems (EAS)
EAS 特别强调了最佳解决方案的重要性。在EAS中,不仅是所有蚂蚁在其路径上留下信息素,而且历史上找到的最佳路径会获得额外的信息素强化。这意味着最佳路径上的信息素浓度会比其他路径更高,从而更有可能被后续的蚂蚁选择。
特点:
-
强化历史最佳路径。
-
加速向最优解的收敛。
-
增加了算法对于最佳解的搜索强度。
2. Rank-based Ant System (ASRank)
ASRank 根据蚂蚁找到的路径质量对蚂蚁进行排名。在这个系统中,只有排名靠前的蚂蚁(例如,最好的几条路径)被允许在其路径上留下信息素。这样,信息素的更新更加集中于高质量的解决方案。
特点:
-
排名制度减少了信息素的过度分散。
-
专注于更有效的路径。
-
提高了算法的收敛速度和解决方案的质量。
3. MAX-MIN Ant System (MMAS)
MMAS 是一种特别设计来避免过早收敛和探索解空间边界的 ACO 方法。因为 ACO 本身追求快速收敛。在 MMAS 中,信息素的浓度被限制在一个最大值和一个最小值之间。这种限制防止了任何一条路径变得过于“显著”,从而保持了算法的探索能力。相当于是有上下界的蚁群算法。
特点:
-
信息素浓度有上下限制。
-
避免过早收敛和探索的不足。
-
保持了算法的多样性和探索能力。
4. Ant Colony System (ACS)
ACS 是 ACO 的一个高效版本,它引入了局部信息素更新规则和更强的全局更新规则。在 ACS 中,蚂蚁在构建路径时进行局部信息素更新,减少了当前路径上的信息素浓度,鼓励其他蚂蚁探索新路径。而全局更新只由生成最优解的蚂蚁执行,强化了最优路径。
特点:
-
结合局部和全局信息素更新机制。
-
强化最优解,同时保持探索新路径的激励。
-
在快速收敛和多样性探索之间取得了良好的平衡。
粒子群算法 Particle Swarm Optimization (PSO)
PSO 的优先:简单高效。
参考鸟群的模式,“群体”被定义为移动个体的明显无组织的集合(群体)。这些个体倾向于聚集在一起,而每个个体似乎都在随机方向移动。而群体行为的同步性被认为是鸟类努力保持自己与邻居之间最佳距离的函数(避免碰撞,但方向和目标仍和群体一致)。而一个体的移动,往往是根据邻居的移动轨迹来的。

具体而言,是可以在搜索过程中,某个粒子搜索到了较优的路径,即可以把这个路径通信给其他粒子。
基本流程
1. 群体初始化
- 在PSO中,解决方案的候选群体(称为“粒子”)通过随机分配位置和速度来初始化。这些粒子在问题的解空间中移动,解空间可以被想象为一个高维的“超空间”。
- 每个粒子代表了解空间中的一个潜在解决方案,其位置代表了解决方案的候选点。
** 2. 个体历史最佳(pBest)、全局最佳(gBest)和局部最佳(lBest)**
- 每个粒子都会跟踪它在超空间中遇到的“最佳”位置,即它所找到的具有最高适应度(或最优解)的位置。
- “pBest”(personal best),代表了个体粒子在迄今为止的搜索过程中的最佳成就。
- “gBest”(global best)是整个粒子群中找到的最优解。
- 在某些 PSO 变体中,还会使用“lBest”(local best),它代表了粒子在一个定义好的邻域内找到的最佳解。
3. 随机加速和移动
- 在每个时间步,粒子会根据自己的 pBest 和 gBest(或 lBest)的位置来随机地调整其速度和方向。这意味着粒子会“飞向”它自己的最佳位置和整个群体的最佳位置。
- 这种行为模仿了鸟群或鱼群的社会行为,其中个体通过观察和模仿其他个体来改进自己的行为。
细节
关心的实际上是位置和速度。 表示的是维度, 表示当前粒子, 表示当前时间。 是当前位置离 IBest 的距离, 是当前位置和 gBest 的距离。
另外, 和 是 的参数, 和 是随机函数, 是某种惯性权重。这些都是可调的。
C7 强化学习
基础概念
Agents :感知环境,并于环境进行交互。
- Situatedness(情境性)
这意味着 Agent 是在一个具体环境中操作的,需要理解其环境并根据环境状态作出决策,而不是在脱离实际情境的抽象系统中。这种情境性使得强化学习非常适用于需要与物理或虚拟环境交互的任务,如机器人控制或游戏玩法。
- Autonomous(自主性)
自主性是指 Agents 能够在没有外部干预的情况下独立运行和学习。这不仅包括在没有人类指导的情况下作出决策,还包括能够自我学习和适应新环境。
- Proactive(主动性)
强化学习 Agents 不仅仅是被动地响应环境,也可以被设定或被赋予目标,并采取行动以实现这些目标。在强化学习中,这通常是通过最大化所定义的奖励函数来实现的。
- Reactive(反应性)
Agents 需要能够感知并及时响应环境的变化。
- Social Ability(社交能力)
BDI(Belief-Desire-Intention)模型是一种用于模拟 Agents(如人工智能系统)理性行为的框架。这个模型基于哲学家布兰特诺(Michael Bratman)的实用主义理论,旨在通过三个主要组成部分 —— 信念(Beliefs)、欲望(Desires)、和意图(Intentions) —— 来模拟人类的决策过程。
- 信念(Beliefs)
代表 Agents 对其环境(包括自身和其他实体)的知识和信息。信念是 Agents 对世界当前状态的理解,可以是完整的或部分的,确切的或不确定的。
- 欲望(Desires)
这是 Agents 想要实现的目标或结果。在多个可能的欲望中,一些可能是相互矛盾的, Agents 需要选择哪些欲望是最重要或最紧迫的。
- 意图(Intentions)
意图是 Agents 已经承诺去追求的特定欲望。这是一个动态的过程,意图会随着环境的变化或新信息的出现而调整。意图通常涉及计划或一系列行动, Agents 将执行这些行动以实现其目标。
强化学习 RL
Reinforcement Learning, RL。训练难度很大,消耗资源高。感觉抽象弱的话训练难度就会高。
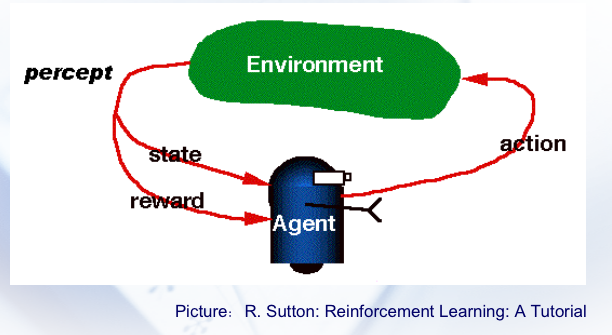
其实就是 Agents 每次做出一次行为,即可获得环境的一次反馈。如果反馈是正向的,则表示该行为对于达到目标是有益的,而 Agents 可以通过学习,增强对于在类似情境中采取相似行为的倾向性。而 RL 能够处理的是 Markov 决策过程。
马尔科夫 Markov 决策过程
决策与历史无关,仅仅和现在有关。例如下棋。
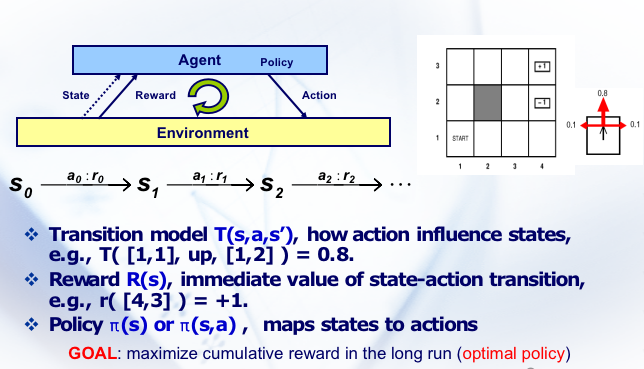
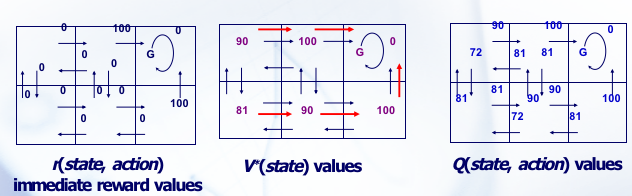
这张图里, 是行动, 是状态, 是 reward, 是策略。
一些函数
是状态值函数。表示在遵循策略 时,从状态 开始的预期累积奖励。在强化学习中,策略 定义了代理在每个状态下选择动作的规则。以下是每种方法的解释:
-
加法奖励(Additive Rewards):
- 公式:
- 在这种情况下,值函数是从时间 开始的 步奖励 的总和。这是一个简单的累积,其中考虑了从当前状态 开始,在遵循策略 的情况下,未来 步内得到的所有奖励。
- 对于持续的任务(也就是永不结束的任务),这可能会导致无限的值,因为奖励会无限累积。
-
平均奖励(Average Rewards):
- 公式:
- 这里,值函数是所有奖励的平均值,计算方法是将时间 开始的 步奖励的总和除以 ,并且 趋向于无限大。这适用于评估代理在长期内的平均表现,这在持续的任务中尤其有用。
-
折扣奖励(Discounted Rewards):
- 公式:
- 在这个公式中,使用了一个折扣因子 ,它是一个介于 0 和 1 之间的数。这个因子决定了未来奖励的当前价值。随着时间的推移,奖励的价值会按指数级别减少。这种方法在实践中非常流行,因为它确保了即使奖励持续不断,累积的折扣奖励也是有界的,只要奖励本身是有界的。
是动作值函数(action-value function),它代表了当代理从状态 开始,采取动作 并且之后遵循策略 时所能获得的预期回报(expected return)。具体来说, 表示在状态 下采取动作 ,然后遵循策略 能够得到的累积奖励的期望值。
在数学上, 可以根据不同的累积奖励方法进行计算:
-
对于加法奖励(Additive Rewards): 是从时间 开始,在采取动作 之后累积的 步奖励的总和。
-
对于平均奖励(Average Rewards): 是所有奖励的平均值,这里 趋于无穷大。
-
对于折扣奖励(Discounted Rewards): 考虑了折扣因子 ,以此计算未来奖励的当前价值。
的一个标准定义,考虑到折扣奖励,是:
其中, 表示期望值, 表示在时间 获得的奖励, 是在时间 的状态, 是在时间 采取的动作。这个期望是基于策略 和环境的动态性质计算的。
总结来看:
-
是状态值函数,它代表在状态 下并且遵循策略 时的预期回报。它只与当前状态有关,并不直接考虑采取的动作。
-
是动作值函数,它代表在状态 下采取动作 并且之后遵循策略 时的预期回报。它同时考虑了当前的状态和被采取的动作。
两者之间的关系可以通过下面的公式来表达:
这个公式说明了状态值函数 是对所有可能的动作 的动作值函数 的期望值,其中动作 是根据策略 在状态 下选择的。换句话说, 是在策略 下,对于所有可能的动作 $ a Q^{\pi}(s, a) \pi s a $ 的概率。
另一种表达这种关系的方式是,如果知道了 对于所有的动作 ,可以通过选择最佳动作来得到最优的状态值:
但这个公式描述的是在最优策略下的情况,而不是在遵循某个给定的策略 下的情况。对于给定的策略 ,你通常会取策略给出的所有动作的期望值来计算 。
小总结
根据 Bellman equation :
对于最终最优的状态 满足最优子结构的特性,从最优出发的最优选择一定也是最优。策略决定 Q,Q 决定 V,我们可以用 Q 来求 V。因此,RL 的本质任务其实是学习一个 也即策略。
Q-Learning
一种无模型的强化学习算法,想法也很直接:学习 Q 的。具体步骤:
-
初始化:初始化 表格,为所有的状态-动作对赋予初值(通常为零)。
-
探索和利用:在每个时刻 ,代理选择并执行一个动作 ,然后观察奖励 和新的状态 。
-
Q-值更新:使用观察到的奖励和最大的 Q-值估计来更新 Q-表中的值,按照以下规则:
其中:
-
是学习率,决定了新信息覆盖旧信息的程度。
-
是即时奖励。
-
是折扣因子,用于衡量未来奖励的重要性。
-
是对下一个状态 可能采取的所有动作的 Q-值的最大估计。
-
-
策略改进:随着 Q-表的更新,代理逐渐学习最优策略,该策略在每个状态下都选择使 Q-值最大化的动作。
Q-Learning 的关键之处在于它是离策略(off-policy)的,这意味着它可以学习最优策略,而不必遵循最优策略进行探索。代理可以通过随机探索来学习,这允许它在尝试新动作的同时学习最优动作。
由于其简单性和有效性,Q-Learning 在许多领域都得到了成功的应用,从简单的环境(如迷宫和棋盘游戏)到更复杂的情况(如自动驾驶和机器人控制)。
T-D Learning
T-D 结合了动态规划(DP)和蒙特卡洛(MC)方法的思想,能够从不完整的序列中学习,不需要等待序列结束即可更新值函数的估计。其特点是在预估未来奖励时,使用已学到的估计值作为部分基础对于某个状态 s 和其后继状态 s' :
其中, 是状态 s 的值, 是学习率, 是从状态 s 到 s' 执行的动作的即时奖励, 是折扣因子。
Reinforce
是一种基于策略概率函数的梯度来进行学习的算法。通过调整策略参数来增加获得高于平均水平奖励的动作的概率,减少获得低于平均水平奖励的动作的概率。其更新规则是:
这里:
-
表示策略参数的变化量。
-
是学习率,控制着参数更新的步长。
-
是获得的奖励。
-
是基线值,用于减少方差并加速学习过程。基线通常可以是0,或者是动作值函数 的估计。
-
是梯度的累加,其中 是在时间 下,关于参数 的策略概率函数的梯度。
这一项称为优势函数(advantage function),它表明了实际奖励与基线(或期望奖励)之间的差异。如果这个值是正的,那么实际获得的奖励比基线高,意味着采取的动作比平均情况要好;如果这个值是负的,则相反。

深度强化学习 DRL
表现最出色。
Value-based DRL
-
Deep Q Network (DQN)
-
Double Deep Q Network (DDQN)
-
Dueling Deep Q Network (Dueling DQN)
Policy-Based DRL
-
Policy Gradient (PG)
-
Asynchronous Reinforcement Learning (A3C)
-
Deep Deterministic Policy Gradient (DDPG)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App
· 张高兴的大模型开发实战:(一)使用 Selenium 进行网页爬虫