
Learning Agent Communication under Limited Bandwidth by Message Pruning 记录
文章介绍了一种提高多智能体之间通信效率的方法(得到最适合的通信带宽)。
首先介绍了多智能体强化学习模型ACML:
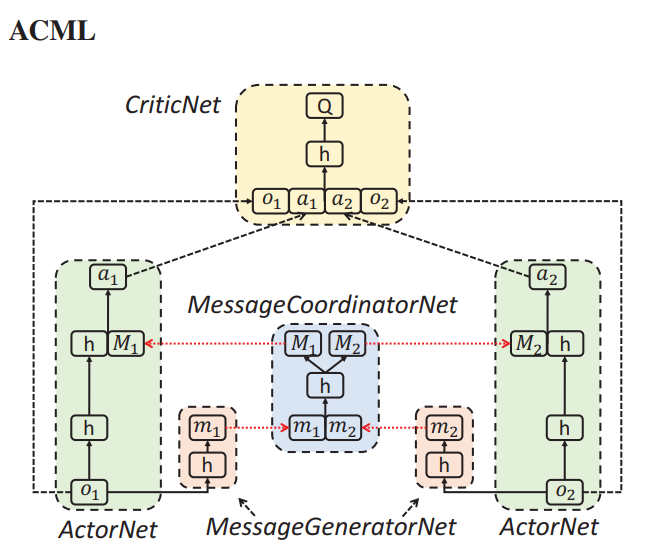
算法跟MADDPG是有点类似的,增加了信息生成网络和信息协调网络,actor产生决策的时候还要考虑协调后的信息,变相得到了全局的信息。
但是这种信息可能是冗余的,下面考虑优化:
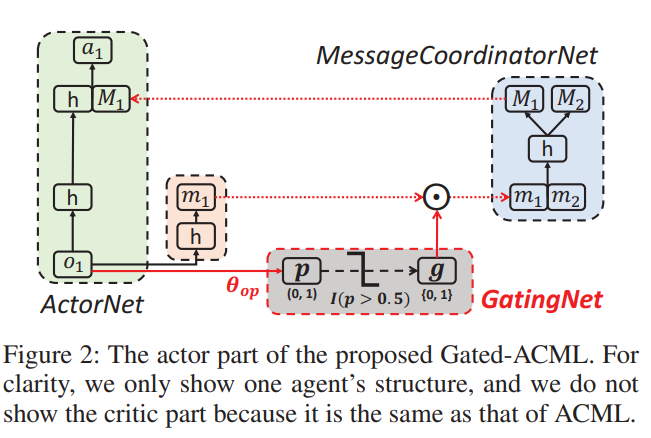
在生成网络和协调网络之间,增加了一个门控,用于过滤信息。这个门控是硬门控(只有0和1),通过随机变量p控制。随机变量p通过θop得到。通过p每一个单元的大小控制门控每一个单元的0或1。对于每一个观察(o),怎么找到最合适的门控呢?门控g是不可导的,但是p可以通过强化学习的辅助变得可导,从而间接控制g。
这里首先定义了一个和优势函数有异曲同工之妙的函数ΔQ(oi),相当于通过控制变量法判断智能体i,得到额外信息和不得到额外信息之前的Q值差,如果差值大于一个阈值T,说明这个额外信息是有用的,就提高它的p值。反之毅然。:
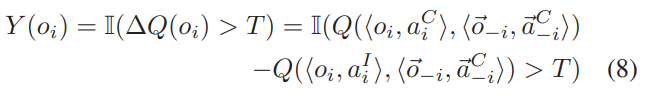
Y(oi)这样的定义把问题变成了一个类似分类的问题。要求p和I(ΔQ(oi))>T尽量接近。
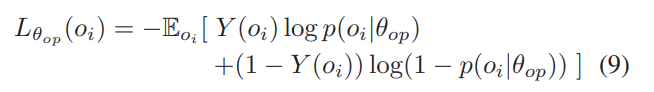
训练的时候,需要得到可靠的估计。首先训练无门控的ACML(g=1),之后强行设置门控g=1和g=0得到式8中的参数,就可以开始训练了。
T有两种方式,一种是静态的,一种是动态的。
静态更新:选择最近的k次观察,经过排序,选择一个想要保留的百分比系数,在百分比位置的边界得到想要的系数T。
动态更新:一种渐进式的更新方式,
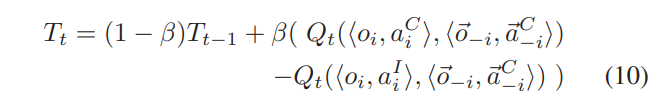

 浙公网安备 33010602011771号
浙公网安备 33010602011771号