

Suphx: Mastering Mahjong with Deep Reinforcement Learning 阅读笔记
参考:https://zhuanlan.zhihu.com/p/129247756
论文原文:https://arxiv.org/pdf/2003.13590.pdf
一、遇到的挑战:
1、复杂的计分系统。每一局麻将游戏包含很多回合,而最后的排名是由这些回合的总分决定的(当玩家在前面的回合产生了巨大的优势之后,玩家可能战术性的输掉最后一局以保证自己是第一名),所以我们也不能直接利用回合得分来学习。除此之外,麻将有很多种胜利的方法,而这些方法之间差异巨大,不同的方法也在每回合产生不同的胜利得分,这种得分规则远比国际象棋、围棋等的规则复杂。一个专业玩家为了权衡获胜几率和胜利得分会谨慎选择胜利的方法。
2、非完全信息。每个玩家有多达13张别的玩家不可见的配牌,还有14张王牌在整局游戏中对所有玩家都不可见。剩下的70张牌将在摸牌和丢牌的过程中逐渐可见。平均下来每个信息集(一个玩家决策点)会有超过1048个隐藏状态。如此多的隐藏信息使得麻将比以前学习过的非完全信息游戏(例如德州扑克)更难。对一个玩家来说,只通过自己的配牌很难确定什么样的动作是好的。因此,对AI来说也很难将奖励信号和观察到的信息建立联系。
3、规则复杂。有不同的动作例如:和牌/吃/冲/碰/杠,丢牌,使得麻将容易出现打乱整个牌局的行为。由于每个玩家有13张配牌,也导致了很难预测什么时候会被打断,所以我们甚至不能构建传统的game tree,就算建起来,这颗树在玩家和连续动作之间会有大量的路径。这阻止了直接应用先前的成功技术例如蒙特卡洛搜索和虚拟遗憾最小化算法。
由于上述的挑战,尽管进行了许多的尝试,最好的麻将AI也远远落后于顶尖人类玩家。
Suphx采用了深度卷积神经网络作为模型。网络先从人类专业玩家的对战数据进行监督学习,之后将网络作为策略,并进行自我博弈的强化学习。我们为自我博弈采用了流行的策略梯度算法并介绍下述几种技巧来应对上面的挑战
1.Global reward prediction 训练了一个预测器,基于当前和之前回合的信息来预测最终的回报(未来几个回合之后)。这个预测器提供了有效的学习信号,因此可以进行策略网络的训练,。除此之外,我们也设计了look-ahead fearures来对各种各样的不同获胜方法的概率和得分进行编码,作为强化学习agent的决策的支持。
2. Oracle guiding。Oracle guiding 介绍了一个oracle agent,它能看到全部的信息,Oracle agent 由于完全信息的一个非常强的AI。在我们的RL训练过程中,我们逐渐从agent中丢弃完全信息,最终将它转化为一个只输入可见信息的政策agent,我们的正常agent比标准的只保留可见信息的RL训练提升快的多。
3.麻将的复杂游戏规则导致game tree不规则,并且阻止了MCTS的应用,我们介绍
parametric Monte-Carlo policy adaptation (pMCPA)来提升agent的及时表现。在在线对战阶段中,当回合的推进之后,更多的信息被观测到(例如公共的牌被玩家看到),pMCPA逐渐的修改和适应离线训练的策略。
Suphx在Tenhou平台上进行评估,这个平台上有超过350,000玩家。Suphx的等级达到了10dan,并且长期维持稳定,这个表现超过了大多数顶尖人类玩家。
2 Suphx概述
这一节先描述决策流,之后是网络的结构,最后是使用的特征。
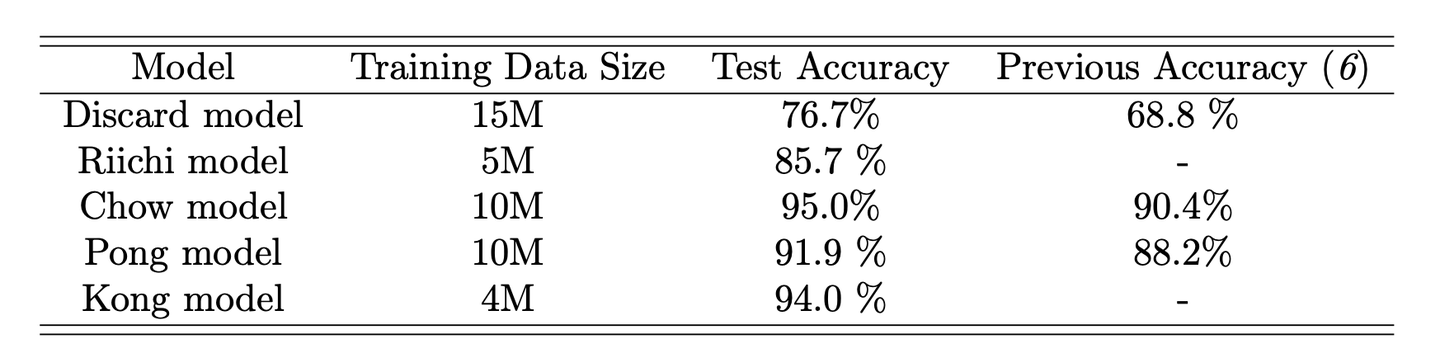
2.1 决策流
因为麻将的规则很复杂,Suphx学习了5个不同的模型以应对不同的情况:丢牌模型,立直模型,吃、碰、杠。
除了5个模型,Suphx也采用了其他的基于规则的模型来决定是否申明一个赢的场面并赢下此局。(和牌)它仅仅只是检查是否可以和别人丢弃的牌或者摸一张牌来组成和牌,通过以下规则来做决定:
如果不是游戏最后一局,和牌并且本局胜利。
如果是最后一局:
如果和牌之后累计的分数是4个人中最低的,就不和牌。
否则,就和牌
麻将的玩家有两种情况需要采取动作,Suphx也一样(详见图表1)
Suphx摸一张牌,如果可以和牌,用和牌模型来决定是否和牌,如果和牌本局结束,否则:
1、杠牌模型:
如果摸一张牌后配牌可以暗杠或者加杠,决定是明杠或者加杠。如果不行,就到立直模型。否则有两个子情况:
(a)如果是一个暗杠,就暗杠并回到摸牌的情况。
(b)如果是加杠,其它玩家可能会使用这个加杠的牌赢得胜利。如果其它玩家赢了,游戏结束,否则加杠并回到摸牌的情况。
2、立直模型:如果摸牌之后可以立直,立直模型决定是否立直。如果不立直,就前往丢牌模型,否则申明立直并前往丢牌模型。
3、丢牌模型:丢牌模型决定丢一张牌。之后就轮到其它玩家采取动作,或者牌山没有剩的牌游戏结束。
其它人丢一张牌的情况其它人丢一张牌。如果Suphx能通过这样牌胜利,就通过和牌模型来判断是否和牌。如果和牌,和牌并且游戏结束。否则,检查是否能冲、碰、杠。如果不行,就轮到其它玩家。否则,冲、碰、杠模型决定采取哪个动作:
1.如果3个模型都没有推荐动作,就轮到其它玩家或者没牌游戏结束。
2.如果一个活多个动作被推荐,Suphx选择最高估计分的动作。如果选择的动作没有被其它玩家打断,Suphx选择这个动作,之后前往丢牌模型。否则,动作被打断就轮到其它玩家。
2.2特征和模型的结构
因为深度卷积神经网络(CNN)已经被证实在国际象棋了围棋中表现出了强大的能力,所以Suphx为了策略也选择了CNN作为模型结构。
不同与国际象棋和围棋,麻将中可获得的信息自然不是图像格式。我们小心的设计了特征集来将观测到的信息编码以便可以被CNN领会。
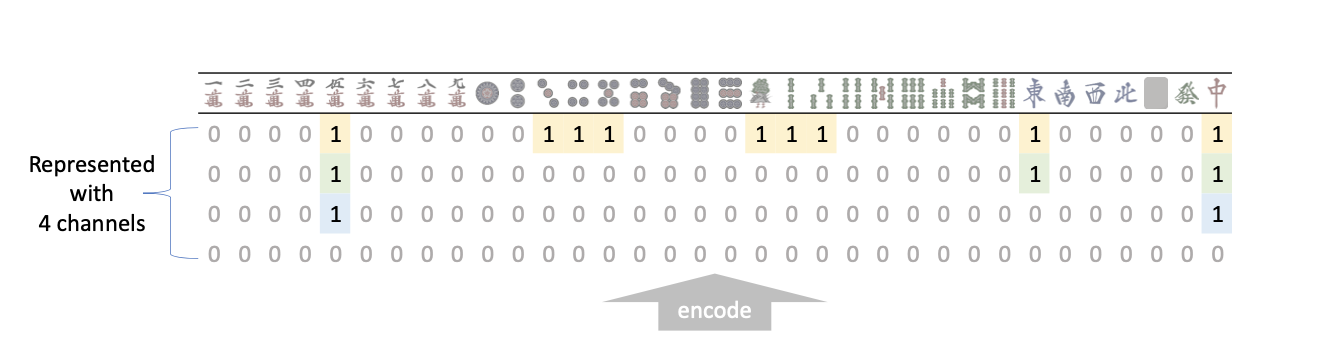

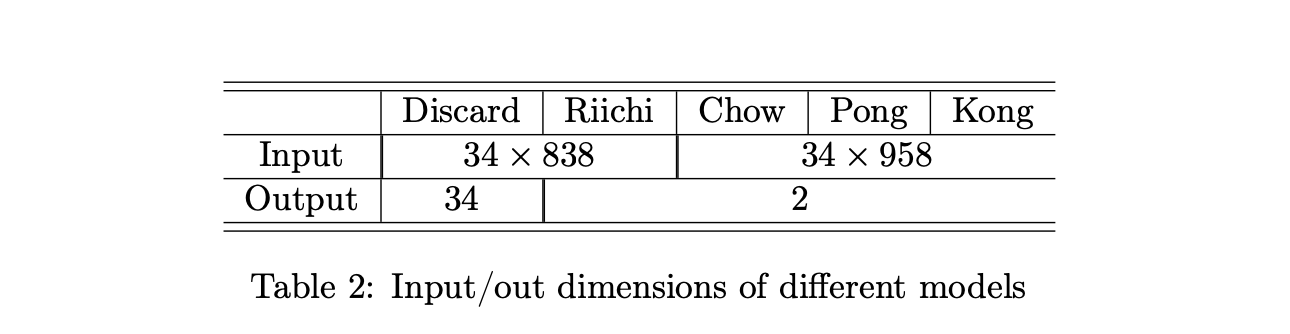
3 学习算法
Suphx的学习包括3步。首先,我们通过有监督学习训练了5个网络,数据来源于Tenhou。其次,我们通过自我博弈RL提升受监督的模型,将模型当作策略。我们采用流行的策略梯度算法,并且介绍了global reward prediction, oracle guiding以便处理麻将的特殊挑战。最后,在在线对战中,噩梦采用run-time ploicy adaption来权衡当前回合的新发现,以便能表现的更好。
3.1 基于熵正则化的分布式强化学习
Suphx的训练基于分布式强化学习。事实上,我们采用策略梯度法和重要度采样来解决异步分布式训练的轨迹陈旧性问题。
我们发现RL的训练对熵很敏感,如果熵太小,RL的训练收敛的太快自我博弈没有很好的提升策略。如果熵太大,RL的训练会变的不稳定,学到的策略方差也会太大。因此,我们在RL训练过程中进行正则化的过程如下所示:
接着这里引入了动态调整的entropy系数:根据经验设置一个entropy的标准值,如果当前entropy小于这个值,那么系数加大,如果当前entropy大于这个值,那么系数减少:
这个系统包括多阔多个自我博弈组件,每个组件包括一组基于CPU多麻将模拟器和一组基于GPU的推理引擎来生成轨迹。策略的更新与轨迹生成是分离的。参数服务器用多个GPU基于重现缓冲区来更新策略。在训练中,每一个麻将模拟器随机初始化一局游戏,RL agent作为玩家和3个对手。当任意一个玩家需要采取行动,模拟器将当前状态给GPU的轨迹推理引擎,之后返回一个模拟器的操作。GPU轨迹推理引擎定期从参数服务器中提取最新的参数,以确保自我博弈策略和最新策略足够接近。
3.2 Global Reward Prediction
在麻将中,每一局游戏有很多轮,(8-21轮。每一轮开始时,每个玩家有13张配牌,轮流摸牌和丢牌,当玩家和牌或者牌打完了游戏结束,每个玩家获得回合分数。例如,和牌的玩家会获得正的分数,其它玩家获得0或者负的分数。当所有会和结束后,每个玩家获得的游戏收益取决于累计分数之后的排名。
玩家在每回合结束之后获得分数,在8-12回合之后获得游戏的收益。然而,不管是回合的分数还是游戏的收益都不能很好的作为RL的信号。
. 因为多个回合在相同的游戏中有相同的收益,使用游戏的收益作为反馈不能区分玩的好的回合和玩的不好的回合。因此,我们需要更好的测量将每回合的表现。
. 尽管回合分数在每回合独立计算,它也不能反映动作的好坏,特别的顶尖的专业玩家。比如,
例如,在一场比赛的最后一轮或两轮中,累积回合得分领先的排名第一的玩家通常会变得更加保守,可能会有目的地让排名第三或第四的玩家赢下这一轮,这样他/她就可以安全地保持排名第一的总体水平。也就是说,一轮得分为负并不一定意味着一项糟糕的政策:它有时可能反映出某些策略,因此与一项相当好的政策相对应。
3.4 Paramertic Monte—Carlo Policy Adaptation
顶尖玩家的策略会随着初始状态的不同而大不相同。比如,在好的局面下将更具有进攻性,而不好的局面下将比较保守。这和之前的游戏比如围棋和星际争霸是完全不同的,因此,我们相信如果我们能将离线的策略变成及时在线的,麻将AI将变得更强。
蒙特卡洛树搜索(MCTS)在围棋中有良好的表现。很不幸,正如之前所说,麻将的游戏顺序不是确定的,很难建立game tree。因此,MCTS不能直接应用在麻将中,我们设计了一个新的方法pMCTS。
当一轮游戏开始,agent知道了初始的
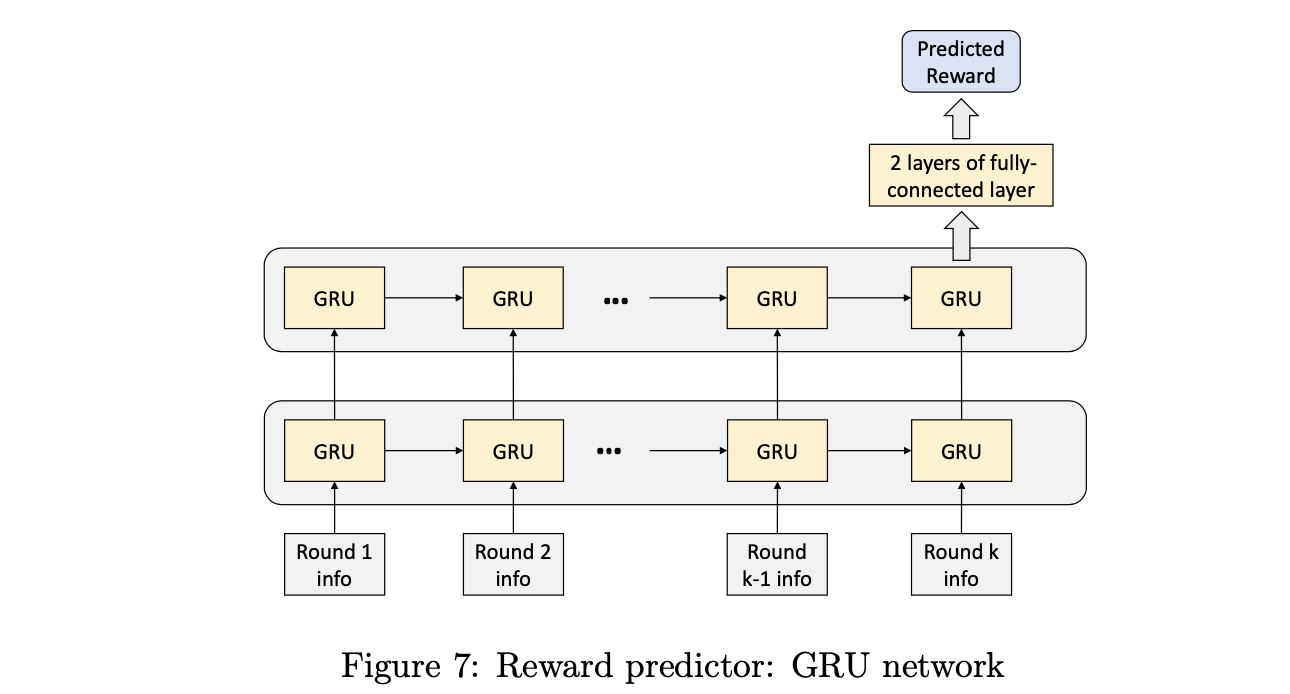
训练数据来源于顶尖玩家的对战记录,预测器则最小化以下的式子:

N代表了训练集中的游戏总数,Ri代表了第i个游戏最终的收益。Ki代表了第i个游戏的轮数,
xki代表了第i个游戏第k轮的特征向量,包括这轮的得分,当前已经累计的得分,东家的位置,东家连庄次数和立直的点数。
训练好之后,只需要做差即可得到每一轮的收益。
3.3 Oracle Guiding
麻将中有非常多的隐藏信息,不利用好这些隐藏信息就很难做出好的动作,这也是麻将是一个非常难的游戏的基本原因。在这种情况下,虽然agent能通过强化学习学习到策略,学习会变的很慢。为了加速RL的学习过程,我们介绍Oracle agent,这是一个能看到所有信息的agent(1)玩家的配牌(2)玩家丢弃的所有的牌(3)其它的公共信息例如已经累计的分和立直的点数(4)对手的配牌(5)牌山中的牌 这些构成完全信息。
通过这种不公平的接触信息的方式,Oracle agent在RL之后很容易成为麻将大师。挑战变成了这么让Oracle agent指导和加速正常agent的学习。在我们的学习中,简单的知识蒸馏效果并不好:对于一个只能获得有限信息的ganent来说,很难和Oracle agent有相似的表现。所以,我们需要一个更好的方法来指导正常agent。
为此,将会产生不同的方法,在Suphx中,我们首先需要做的是通过强化学习训练oracle agent, 之后我们逐渐drop out完全信息之后oracle agnet就会逐渐变成非完全信息。

xn(s)代表正常的特征而x0(s)是完全信息的特征,δt是t时刻的dropout矩阵,元素是伯努利变量P(δt(i,j) = 1) = γt,γt会逐渐衰减到0,这时agent就变成了正常agent了。
当γt变成0的时候,我们继续训练正常agent一个固定的代数。在继续训练中我们采取两个小技巧。首先,我们将学习率下调到原来的1/10。其次,如果某些状态-动作对的重要度值大于了预设的范围,就拒绝这样的动作。通过我们的实验,没有这些小技巧,继续的训练将变得不稳定也不能产生更进一步的提升。
3.4 Parametric Monte-Carlo Policy Adaption
对于一个顶尖玩家来说,不同的初始情况所采取的策略是不一样的。例如,当初始局面很好的时候,玩家将变的富有进攻性,而当初始局面不好的时候,玩家的打法将比较保守,这与围棋和星际争霸等游戏有很大区别。因此,如果我们采取一些在线的方法应用在离线策略上AI将变的更好。
蒙特卡洛搜索(MCTS)在围棋等游戏中有很好的表现。但是,正如之前所提到的,麻将的顺序是不固定的,所以很难建立传统的game tree。因此,MCTS不能直接应用在麻将上。我们设计了一个新的方法叫 pMCPA。
当一个回合开始并agent的到初始的配牌的时候,我们通过以下步骤来训练:
1.仿真:随机初始化3个对手和墙山中的牌,之后使用训练好的离线策略产生一个轨迹。最终产生K个轨迹。
2.适应:利用产生的轨迹使用梯度下降更新离线策略。
3.推论:使用优化过的策略对抗其它玩家。
h代表我们每回合的配牌, θo代表离线策略的参数,θa代表适应之后的最终的策略参数,可得以下式子:

其中T (h)是轨迹的前缀集合,p(τ;θ)是策略θ产生轨迹τ的概率。
根据我们的研究,仿真的次数K不需要太大,pMCPA也不需要收集本轮游戏的全部信息。由于pMCPA是一个参数化的方法,这个更新方法可以产生一个对未访问的状态的更新的估计,这种在线的适应方法可以帮助我们从有限的信息获取。
请注意策略适应每回合说独立的,也就是我们的策略调整只适用于本回合,下一个回合将会重置。
4 离线评估
4.1 监督学习
在Suphx中,5个模型先独立的进行监督学习,每一个训练样本是从专业选手中得到的,状态作为输入,动作作为标签。例如,在训练丢牌模型的时候,一个样例的输入是全部的可观测的信息(和look-head features),标签就是人类选手采取的动作,即丢弃的牌
训练集和测试集的大小在表3中。
4.2强化学习

