

sd9
1、Knowledge Distillation in Iterative Generative Models for Improved Sampling Speed
提高采样速度2种方法:schedular优化、蒸馏
本论文基于DDIM,DDPM训练出来的epsilon theta 可以直接用于DDIM。由于DDIM的降噪过程是确定的,但是step多,由此定义了一个确定的教师分布,因此训练一个学生模型使得最终分布和教师分布一样。
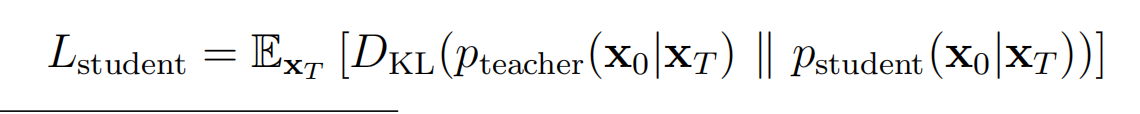
将2个分布视为高斯分布,学生分布为具有可训练参数的均值的分布,因此上式等价于:
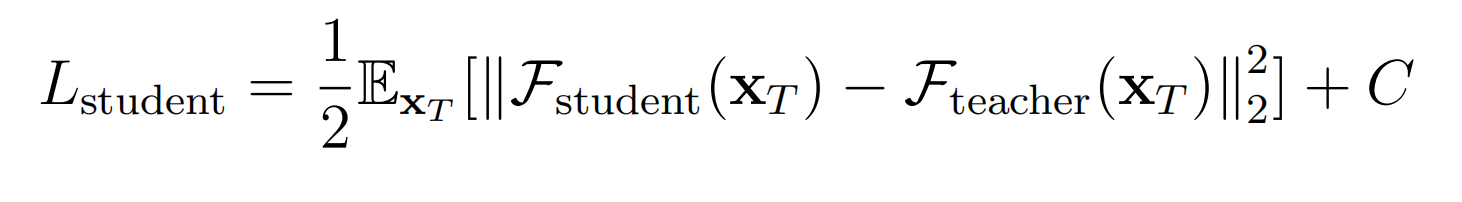
学生模型的网络可以是任意的,这里直接设置为和教师的 epsilon theta 的架构和权重一致,以便加速。
训练过程:将教师网络输入XT,然后迭代很多step算出X0,训练学生网络输入XT后直接算出逼近X0。
缺陷:因为教师网络要跑完所有step才能开始训练,因此速度太慢
2、Progressive Distillation for Fast Sampling of Diffusion Models

(基于DDIM)先训练一个学生,学老师2步的输出,学完之后自己做新的老师,再训练一个新的学生,步数再减半:

缺点:只考虑了DDIM下的推导,且没有考虑 classifier - free guidance
3、On Distillation of Guided Diffusion Models
一阶段蒸馏:
教师分布的输出是考虑了 classifier - free guidance 的,学生模型接受 guidance strength 参数作为额外输入(像时间t一样)。具体的:

二阶段蒸馏:
上述阶段的蒸馏模型作为教师模型,采用 Progressive Distillation for Fast Sampling of Diffusion Models 一样的分布蒸馏方式,区别仅仅是多了 guidance strength 参数作为额外输入,还是基于DDIM。
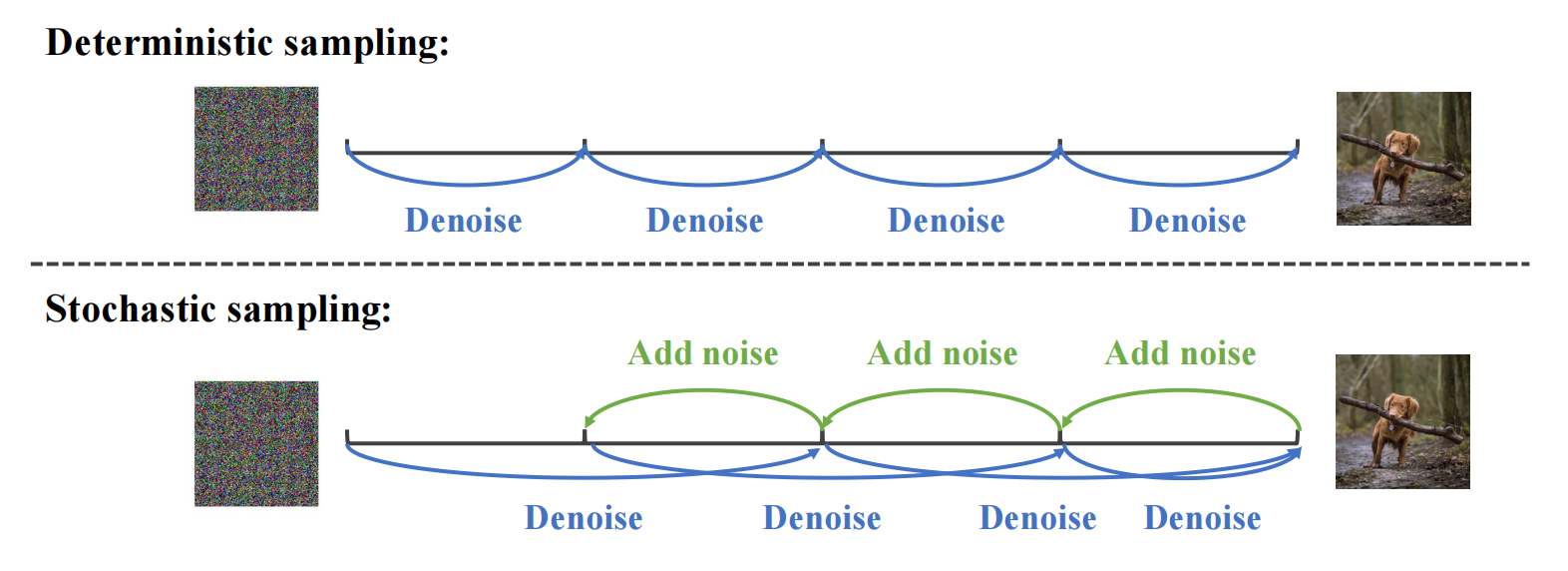
采样阶段,用了 N-step stochastic sampling 技巧,2倍降噪再一倍加噪...目的是:在采样过程中引入了随机性,由于随机扰动的存在,生成的图像也会具有一定差异,从而增加了样本的多样性。:
4、score distillation sampling (SDS)
NeRF 渲染阶段:
输入一个视角的(图片,相机参数),光线从相机出发穿过图片的1个像素后设置多个采样点,这些采样点的空间坐标通过训练好的 MLP 输出预测的颜色和密度信息,密度信息借助物理模型输出采样点的权重,通过预测的颜色加权求和得到预测的图片的像素,遍历多个像素就输出了该视角下的预测的图片。由于输入的视角可能是有限的,可以利用这种渲染方法渲染出没有提供到的视角图片,因此能实现完整的3D渲染
Textured mesh:
给定3D 物体的三角形网格信息以及多张纹理图像,为了渲染出某个相机视角下的2维图像,首先从相机发射出光线穿过这个2维图像的每个像素直到三角形网格上得到交点,通过该交点找到纹理图像对应的颜色,该颜色就作为这个2维图像对应像素的颜色,遍历每个像素之后,这个视角下的2维图像就渲染出来了,如此类推到其他视角。
【方法】
设 某个视角下的图片 = g(theta,相机视角),g 是NeRF渲染过程,theta是渲染中的可训练参数(NeRF parameters)
给一个已知的相机视角c(以参数形式表示),得到 yc(视角文本),随机初始化 theta ,通过 g 得到预测的x0,再加噪声:
![]()
用梯度下降更新法只优化 theta,不动已有的 noise prediction network:

5、variational score distillation (VSD)

【推导】
初始的目标是让两个分布一致:带有可训练参数(θ采样自µ)的 3D 渲染后的分布(左)和 pretrained text-to-image diffusion model 算出来的预测x0的分布,注意优化的是训练参数的分布µ(优化完后θ从中采样),而不是SDS的单个θ:
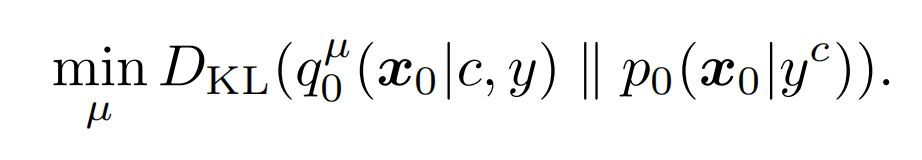
这属于 variational inference problem 。
由于p0非常复杂,所以使用扩散模型将上式转为多个优化问题的组合,即对于任意的时间 t,两个分布在 t 时刻的带有噪声的分布一致:
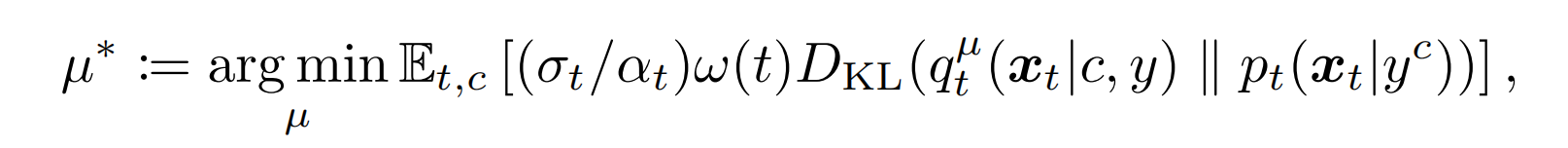
使用ODE方法将分数代替为分布,同时不断迭代更新训练参数,迭代到无穷次就收敛了,τ 时刻(迭代时刻,即ODE time,不是xt的t)的训练参数的变化率满足:
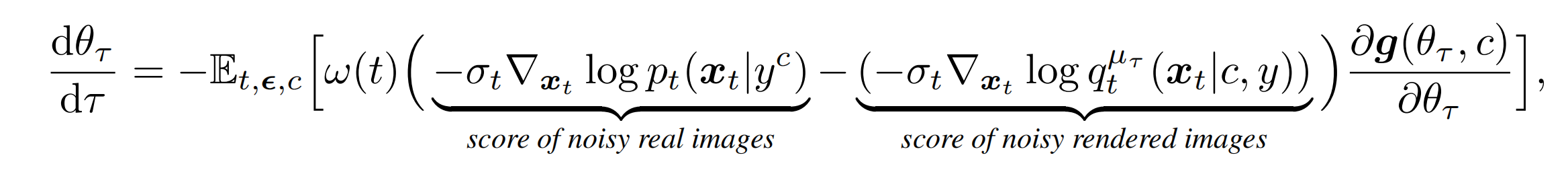
根据Score-SDE,第一个分数可以用:ϵpretrain估计
第二个分数用可训练的ϵϕ估计,通过训练ϵϕ来跟踪当前渲染分布:ϵϕ是把g渲染后的图像(包括所有theta)作为训练集进行的 lora 训练,用ϵpretrain初始化,其中ϵϕ的损失函数:
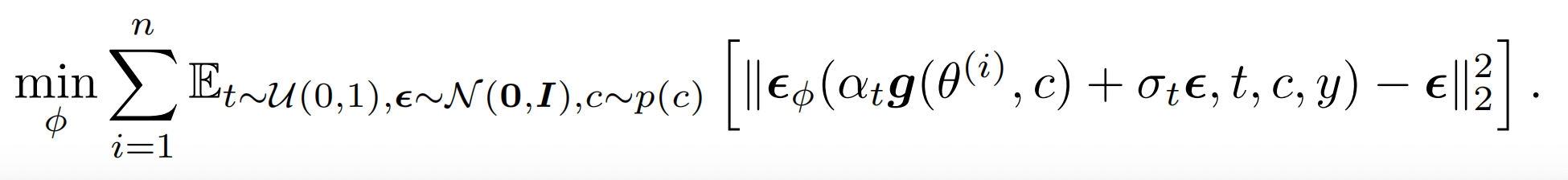
更新 theta 的梯度(即VSD的更新规则):
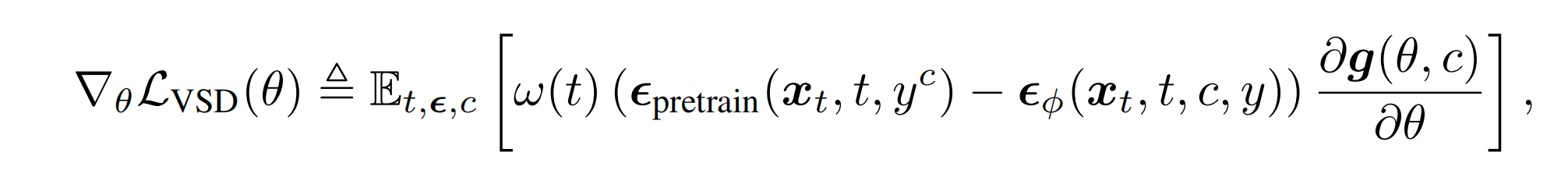
训练时, theta 和 ϵϕ 交替更新即可。
其中θ采样自µ,而µ看成是 n 个θ(pariticles),即将原来的单个参数用多组参数代替,这是为了提高3D场景的真实性和多样性,也可以理解为 n 种 nerf。
【与SDS的区别】
(1)SDS 仅优化一个参数,如果看成分布的话,可以看成是狄拉克分布:Dirac distribution µ(θ|y) ≈ δ(θ−θ (1))。VSD推广到了n个参数,梯度更新更加准确,ϵϕ还能用到 text prompt y,SDS只有单纯的ϵ,VSD更能对起文本。
(2)由于VSD是从分布角度解题的,而训练出来的分布逼近于ϵpretrain,ϵpretrain对2D下的CFG友好,那么促使VSD对3D下的CFG友好(7.5);而SDS的CFG通常特别大(100)
6、DMD
2D下的 diffusion 蒸馏任务

推导:
对于 VSD 的 G 换了个新定义:一步图片生成器,其输出是假分布,G 用预训练好的 diffusion 降噪模型 ubase(z, T-1) 初始化,ubase是将zt输出到zt-1,是图片降噪的预测,不是噪声预测,由于是一步生成,所以 G 没有时间 t 的条件了。
训练目标是使得g的分布pfake和真实分布preal一致(Distribution Matching Loss),计算出2个分布对应的分数,sfake是假分布的分数,sreal是真分布的分数:
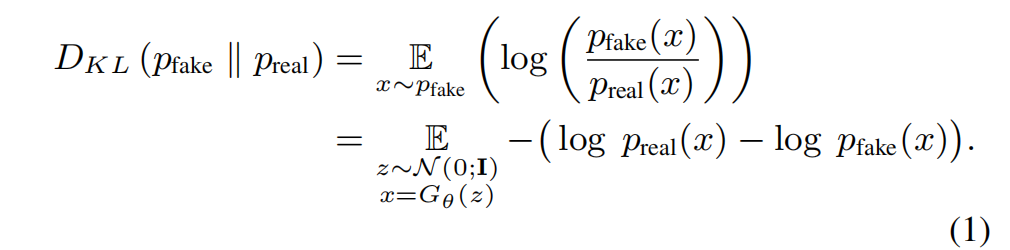
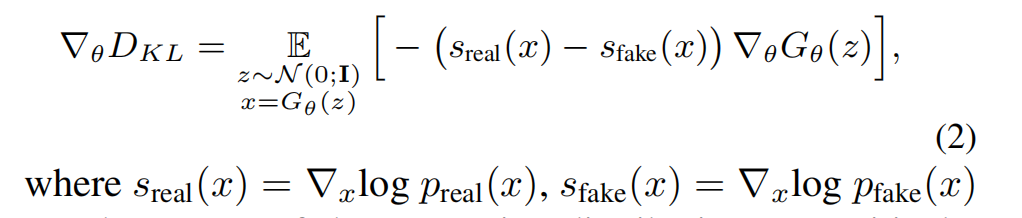
按照VSD类似的推导方法进行推导:根据Score-SDE引入扩散模型估计分数,此时可训练的 ϵϕ 变成了可训练的 ufake(diffusion model),ufake 也用 ubase做初始化,但它有t做条件,可训练是为了代表假分布,由于自然界的真实分布是无法获取的,所以论文是用预训练模型所产生的分布去模拟真实分布,通过让一步生成器的分布趋向于预训练模型的分布,从而趋向于真实分布,此处就把真实分布看成是预训练模型所产生的分布:
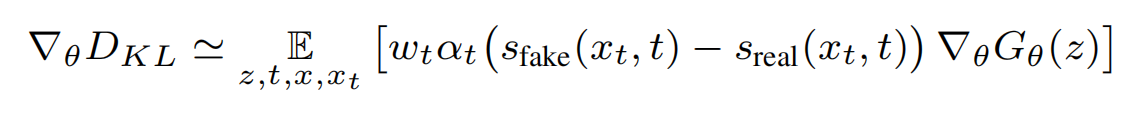
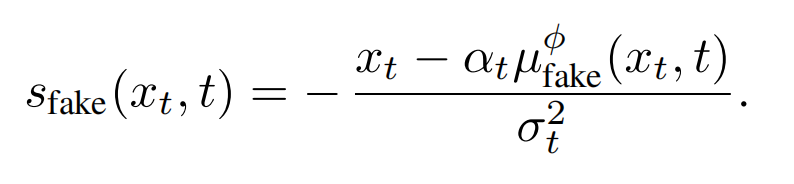
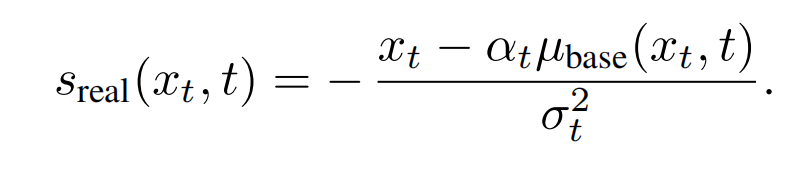
算出梯度后更新theta,这是训练的整体目标(期望2个分布相等)。也是同样的,以(渲染出来的)g的输出做为训练集,更新可训练的ufake, ufake被期望输出预测的x0,这也是为了跟踪当前(渲染)g输出的分布,即代表假分布( denoising score-matching loss on samples from the one-step generator):
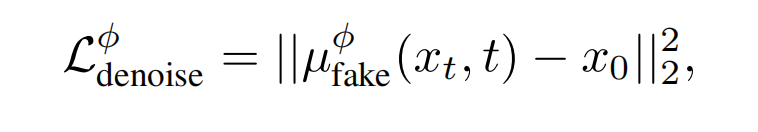
作者对推导过程做了理论和可视化证明:
假定真实分布有2个模式,如果只有sreal,则梯度只指向真实分布的某个高概率密度方向(真实分布的某类图片集),则g生成的样本就会趋向单一模式下的某个区域,对应图(a);

加上 - sfake,-sfake指向真实分布的高概率密度的反方向 或者 低概率方向(由于 sfake 和 sreal 是期望一致的),所以样本会更散一点,g生成的样本就会趋向单一模式下的大部分区域,得到图b。
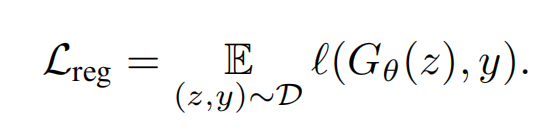
这两个loss一个是从分布的角度训练,一个是从结果的角度点对点训练,但是 DMD2 认为:This regularization objective is also at odds with DMD’s goal of matching the student and teacher in distribution, since it encourages adherence to the teacher’s sampling paths.
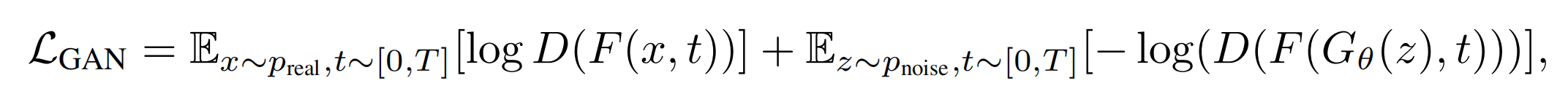
(4)太大的模型比如SDXL没法用一步蒸馏出来,因此把一步生成器G改为多步生成(那速度不就慢了啊)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】凌霞软件回馈社区,携手博客园推出1Panel与Halo联合会员
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步