
sd6
1、blip-diffusion
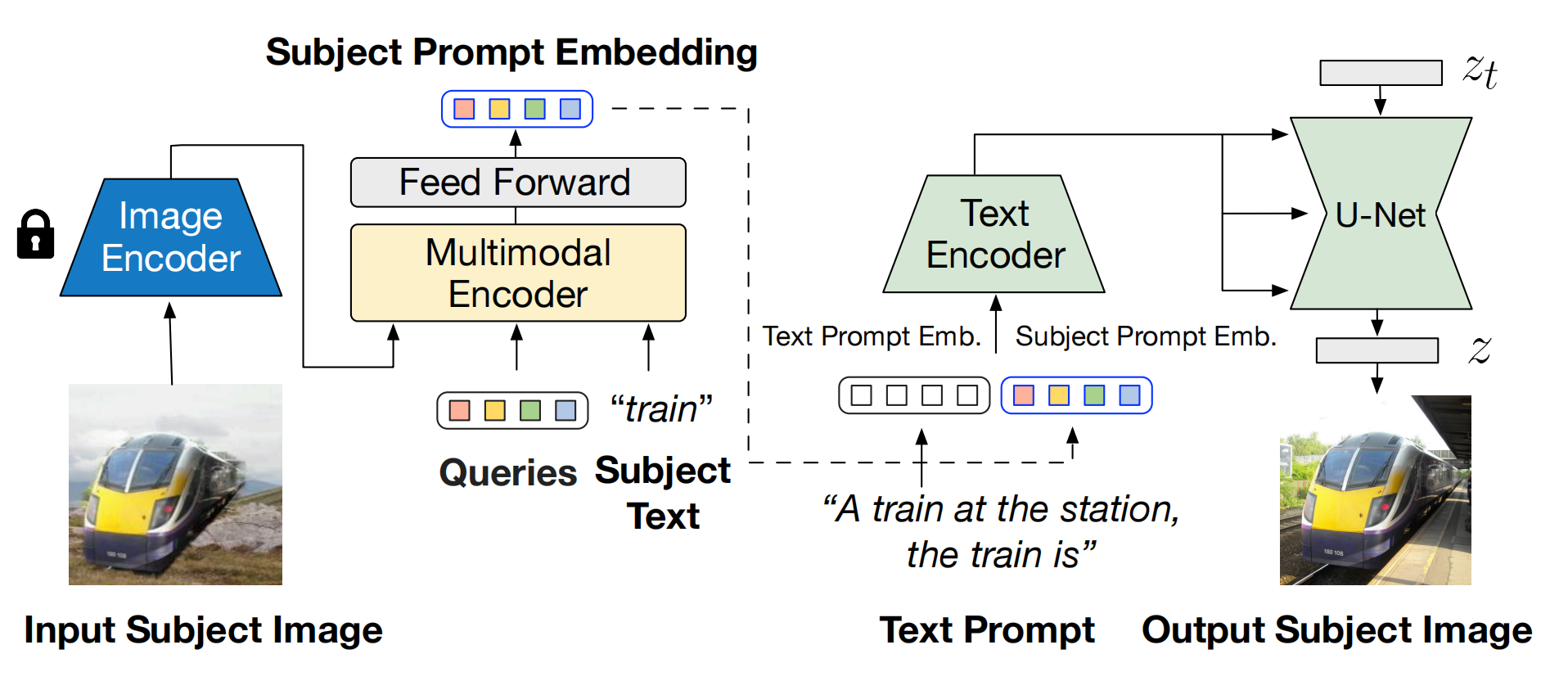
训练:
图片向量注入变为多模态向量注入:给概念“train” 和对应的5张照片,通过Blip(image encoder + multimudal encoder)得到5个subject prompt emb,然后取平均。原图的背景需要做随机替换以防止copy现象
text emb : 把 subject prompt emb 拼接到 text prompt 后面
监督:原图,需要一些微调以便记住 概念“train”。本质是引入了多模态向量降低了微调步数,但是还得微调。
2、SDinpainting
原图,mask,文本=》按照文本生成的东西放到mask上
mask resize to 的 mask(64*64),mask 黑色区域在原始图片中的区域 再通过 vae encoder 得到 masked_image_latents
采样的时候,对每一步的 xt 做厚度拼接mask 和 masked_image_latents(除了x0)
3、MAGICDRIVE
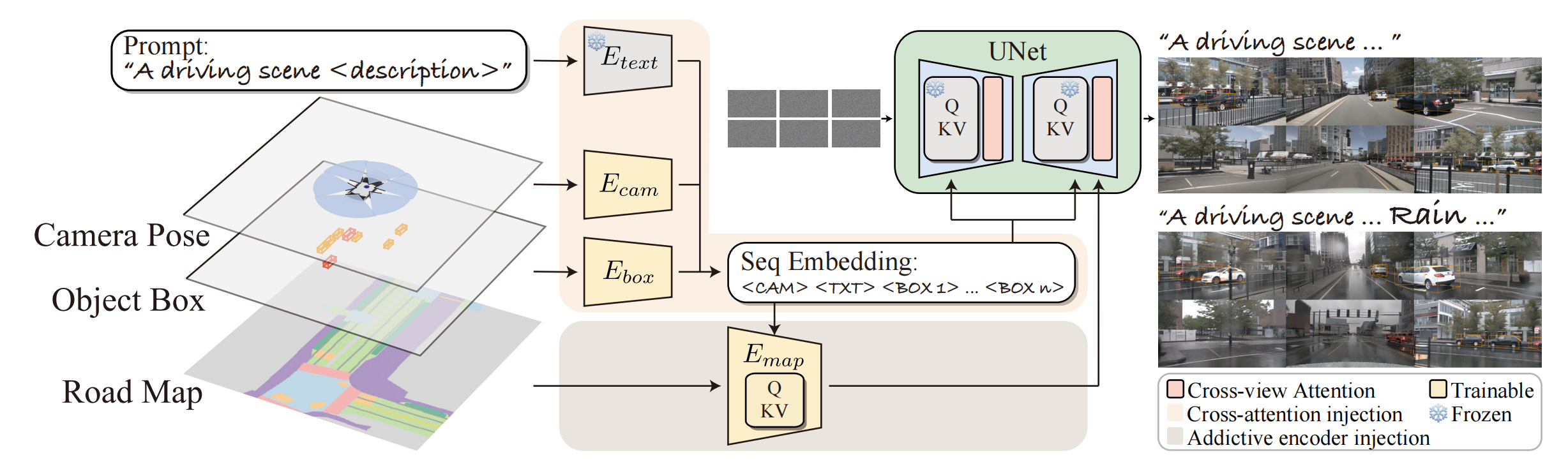
Camera pose:有 K(相机的内部参数,用于相机坐标系和像素坐标系的转换),P(旋转矩阵,表示相机的转向,用于世界坐标系和相机坐标系的转换),T(相机在哪,即相机光心相对于世界坐标系原点的平移距离)参数,一起拼接,然后通过 Fourier (以便捕获高频变化)和 MLP 编码
Box:类别编码 拼接 Fourier(8个定点位置),再通过 MLP编码。Box、Camera pose、text emb 组成Seq,然后通过cross attn 注入Unet
road map:新开一个分支,接受 road map 和 Seq ,然后注入Unet
Cross-View :全景图的一致性。Unet 里面看到的是1个全景图(Front、Front Left、Front Right image),Front image 通过 attn (自己是Q,其他是K,V)得到 Left 和 Right 的信息,然后加过来。
2、HumanSD
和 controlnet 功能类似,但是只研究了姿态的视觉条件。
认为 controlnet 无法解决复杂姿态问题,证明了视觉分支得学习更多的知识(自己希望生成什么样的姿态图且还得过度一点,抑制住冻住的分支所生产的矛盾姿态)。所以作者就改造sd ,把视觉条件直接拼到噪声上,另外对 loss 乘了个权重矩阵,权重矩阵反应姿态,这是为了让模型重点关注姿态要符合,权重矩阵是随着采样步数动态变化的
3、BEVControl
BEV sketch + text =》 全景图
Unet 每层新增Controller块 和 Coordinator块,BEV 通过 Controller 注入,Coordinator用于确保 view 之间的一致性。通过V个相机角度将 BEV 映射出 V个视图,每个视图包含相机的前景信息M和背景信息R, M由所有box的归一化坐标、box类别、当前视角下的box转向角度构成,背景信息就是当前视角下的车道线图。
M-》F:box的坐标通过傅立叶编码、类别通过CLIP、角度通过傅立叶,然后三者相加再通过线性映射
R-》B:通过一个预训练的CNN
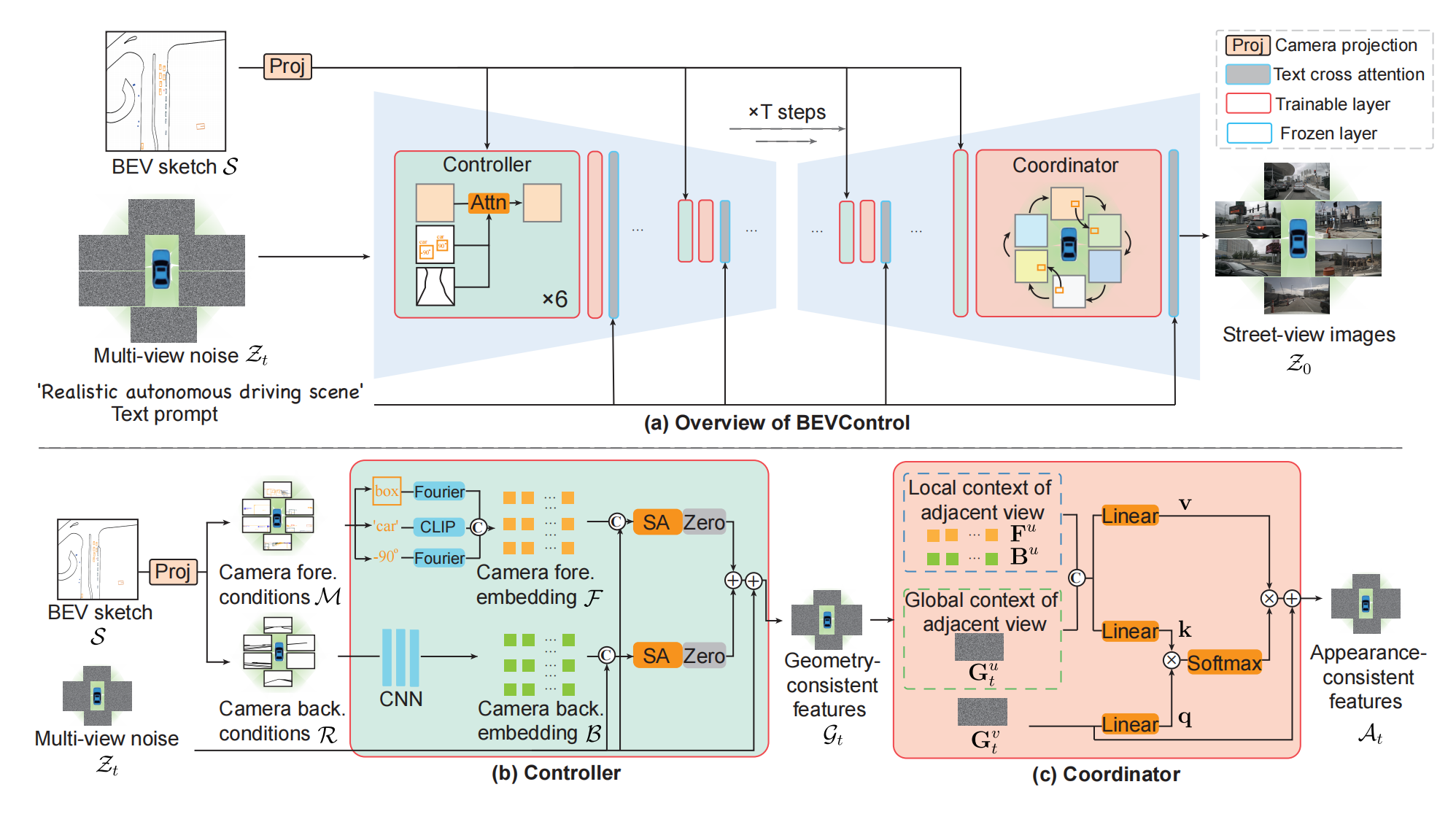
F、B分别和噪声向量拼接,再过自注意力SA,最后再加上噪声向量:
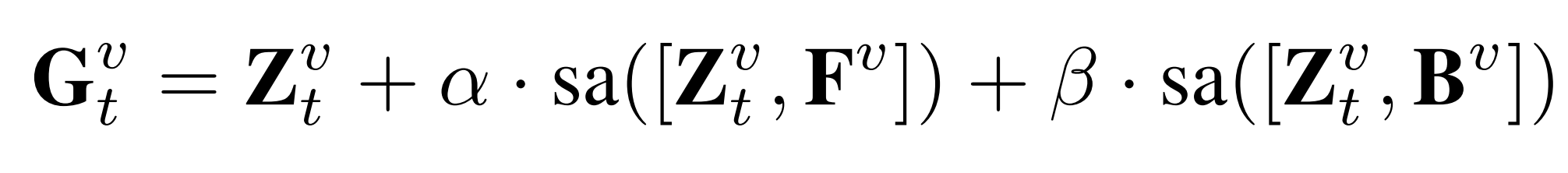
Coordinator: V个视图中前一个视图把信息传递给后一个视图来做交互。假设当前视图是v(能得到q),前面的视图是u(能得到k,v),要更新v,交互的方式是注意力机制,u视图还分了全局的信息(它自己)和局部的信息(F,B)注入:

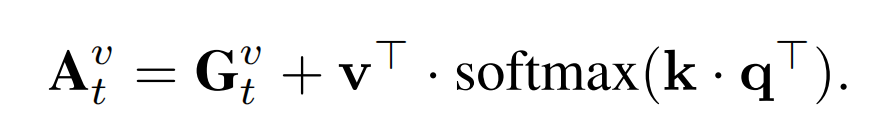
4、IPAdapter
文本+图片prompt=》图
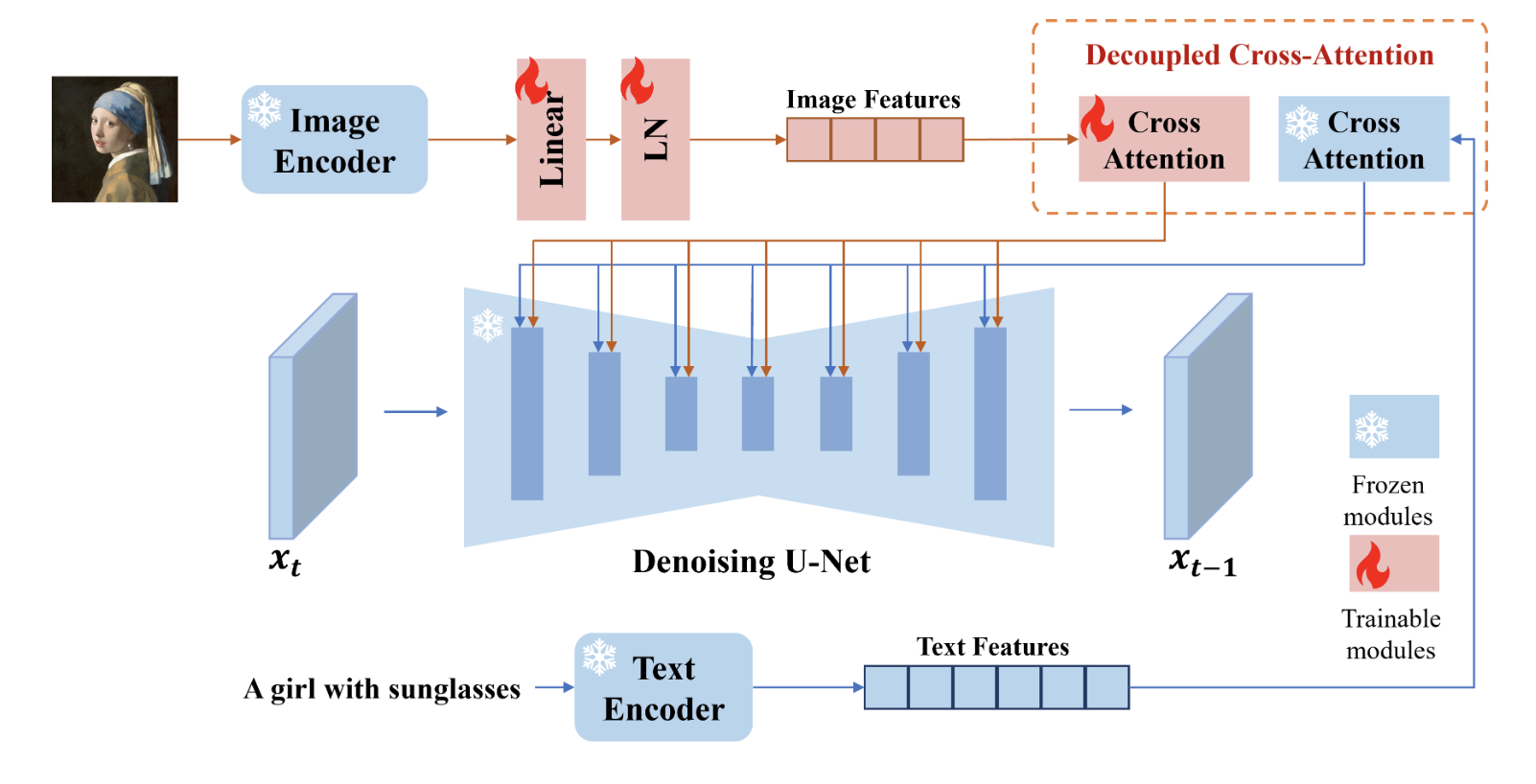
训练一个通用的adapter:理想的训练集是(图1,图2,文),但是这样的数据集收集困难,所以作者用(图,文)转为(图1,图1,文)训练了一个一个基于sd1.5的通用的adapter来实现准确的记住风格照片并注入到sd1.5中:新开一个分支,把图片prompt通过clip+mlp之后映射成id tokens,然后和文本向量拼接通过crossAttn注入,新分支除了CLIP可训练,其他地方冻住。这样就基于sd1.5训练了一个通过 图片prompt 注入模块(adapter),推理的时候把训练好的adapter拿走,然后注入到各种风格的sd版本上(都微调与同一个sd)直接嫁接,就能实现记住这个人,然后按照文本转为对应sd风格版本的风格化人。
其他应用:
variation:给它配个文字“高质量,清晰”就行:

两个图片融合(风景+女人):配个文字“高质量,清晰”,先对女人加点噪声,然后从该处去燥,此时用风景图传crossattn

两个图片融合:配个文字“高质量,清晰”,一个图片进controlnet,另一个图传crossattn:

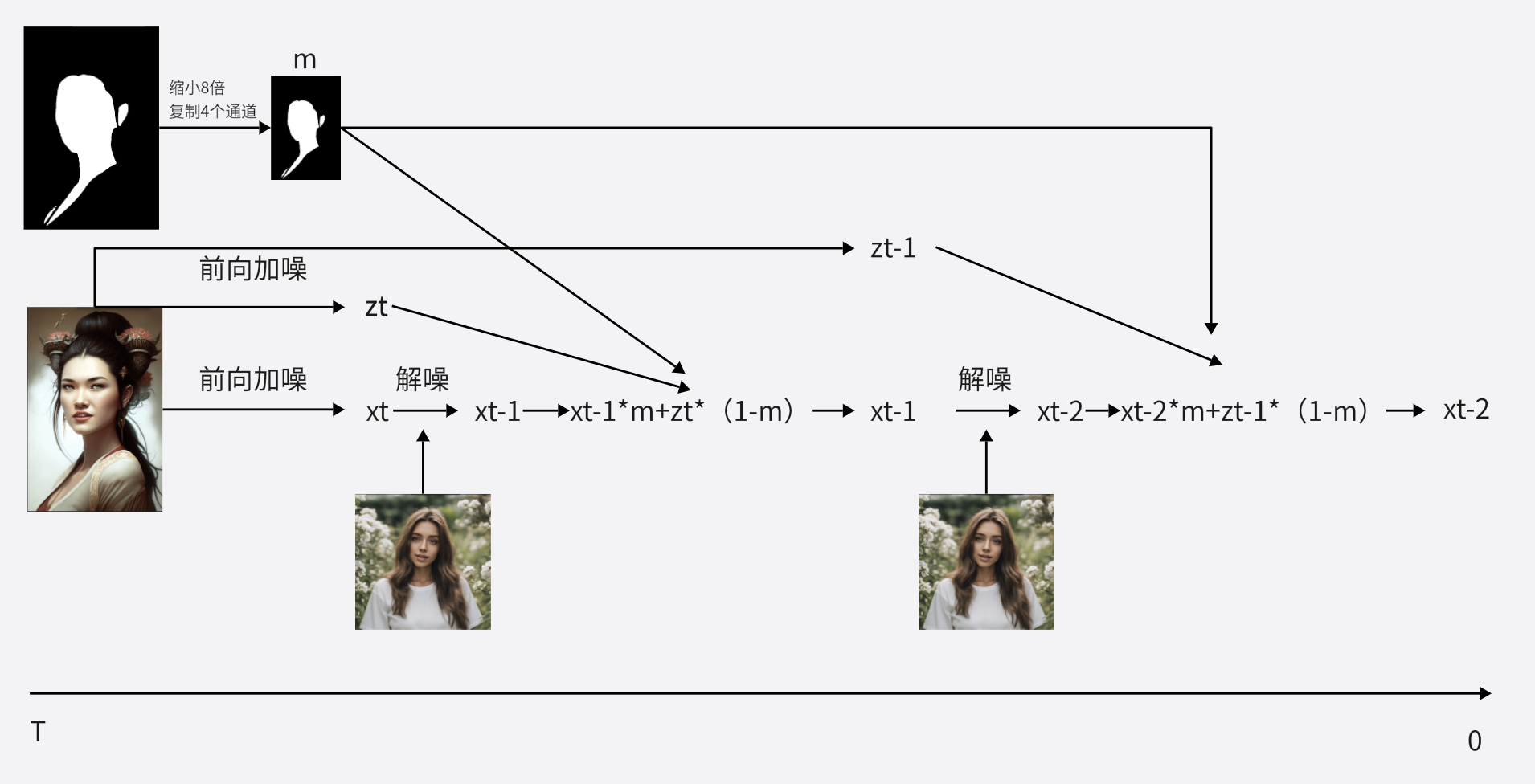
inpainting:

一开始对图1加噪来确定解噪的起点,这是为了定结构(优化版本去掉了,因为这样前几步没有用到图2,导致id信息没有用好),然后每个解噪都做mask融合;优化版本把image encoder的结构换成了insightface,图2 换成了大脸照片,更好的提取了图2 的 id;
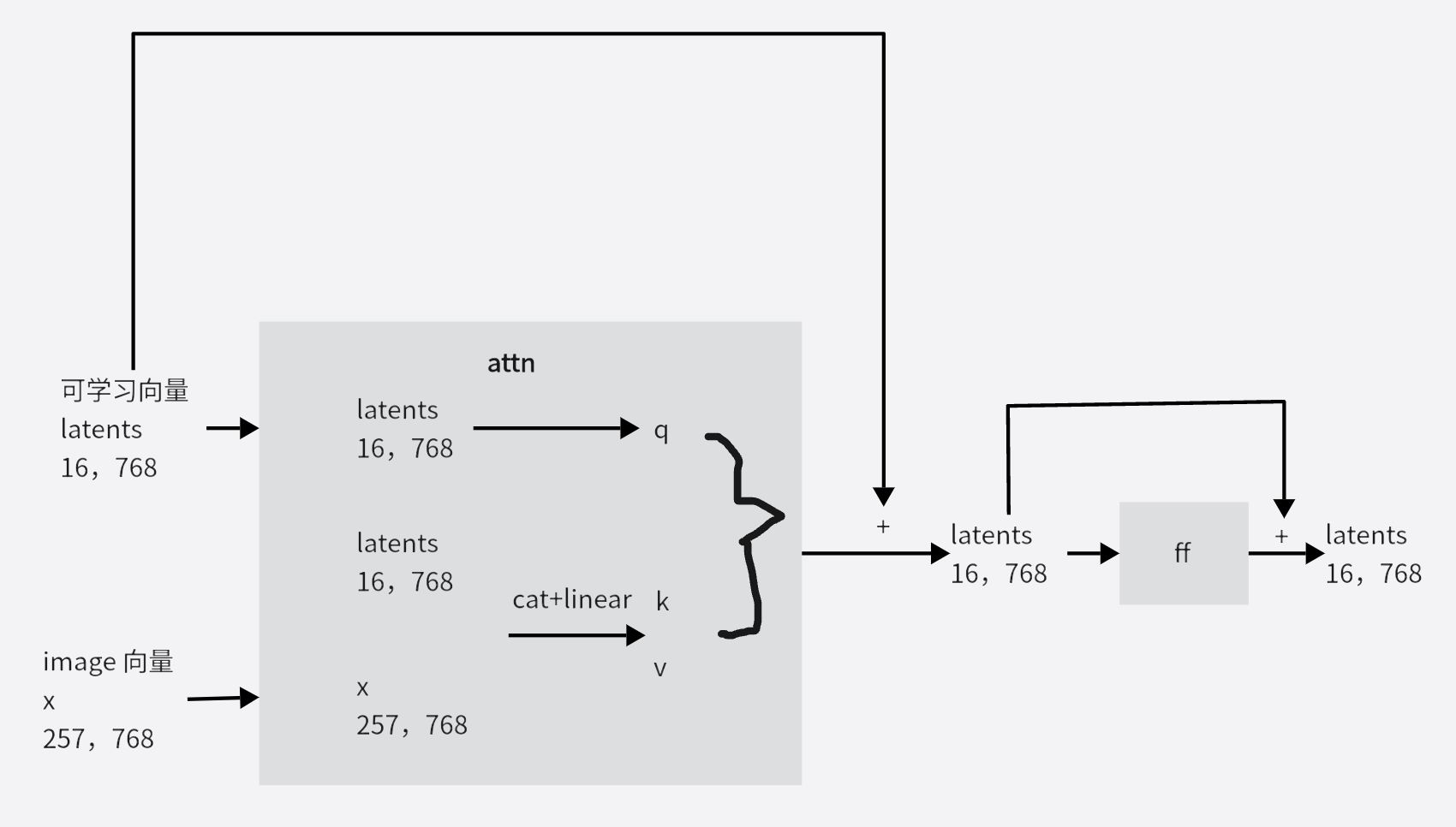
IPAdapterPlus改进:
在上面image分支的 ln 后面仿照Qformer 新增多层的下图以实现更好的把图片对齐到文本空间:
5、lcm
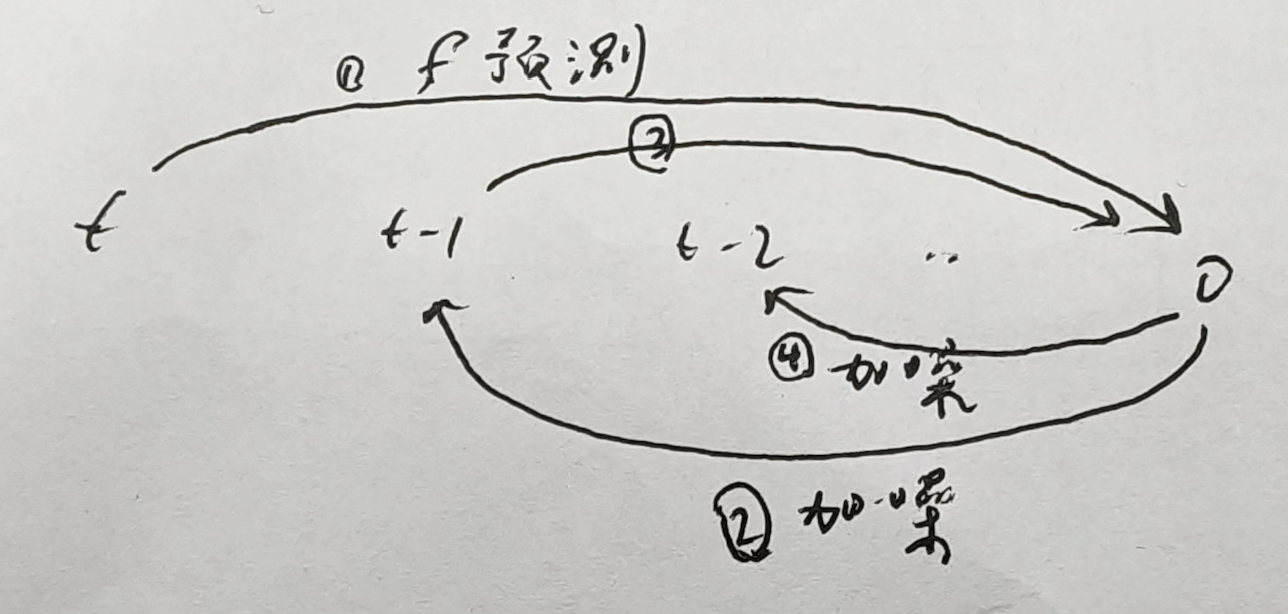
一致性预测函数可以预测输出初始的x0,从而达到一步采样,其中 z = xt:

首先从某个模型中蒸馏(给定一个数据集,即输入和GT,学生模型训练2个loss,一个是直接学习数据集的loss,另一个是同一个输入,学生的输出要尽可能的和教师的输出一样,所以教师模型之前用什么数据集训练的,学生就用那个数据集)出新模型(LCM模型)(如果训练过程只训lora权重,则叫LCM-lora),原理是两个在trajectory上临近(时间间隔为k)的点(tn,tn+k)都通过一致性预测函数的话应该是一样的,那么就用差值去做loss,更新梯度的时候采用 ema 方法,即对f theta复制一个f theta-,更新梯度的时候只更新f theta,然后f theta- 通过公式来更新:更新后的f theta 和 f theta- 通过线性相加,蒸馏当中还用了classifier-free guidance,负条件用的空,tn对应的隐状态用numerical augmented PF-ODE solver:

训练完之后的模型就可以推理了(如果是LCM-lora,则可以和其他风格的 lora 做线性叠加,从而具备相应的风格),多步推理可以提高图片质量:根据当前步用 一致性预测函数 预测好的x0,然后对它前向加噪到上一步=从高斯分布中采样,然后再用一致性预测函数...最后用vae解码。详见:

图形化展示:
推论:只要和 lcm_lora 结合了都能直接用 lcm 推理;lcm_lora_sdv1.5 可以和 sdv1.5 / sdv1.5微调后模型 结合;
5、custom diffusion
db思路,但是只微调crossAttn中的Wk,Wv权重(文本对应的)
6、ZipLoRA
融合一个主体lora(q,k,v的AB权重矩阵)和一个风格lora:认为两者按照权重相加,这个权重得人为调,很麻烦。而是对两个lora矩阵分别分配2个可学习的权重向量,这个向量和lora矩阵是元素积,然后再加权求和。另外对于这两个向量乘完之后的2个lora矩阵,2个矩阵的对应2列应该是正交的,这样就不会使得信息重叠。因此训练方式是拿base+主体lora+风格lora训练,只训练权重向量,损失函数包括三部分,前两部分是融合lora的效果分别接近主体lora(主体lora对主体图片预测的噪声 和 融合后lora对主体图片预测的噪声 的mse)和风格lora(风格lora对风格图片预测的噪声 和 融合后lora对风格图片预测的噪声 的mse),第三部分是为了正交(2个lora权重向量之间的余弦):

另一个trick是发现lora权重是稀疏的,去掉一大堆接近0的元素不影响效果。
7、sdxl
相比较sd,改动的部分有:
8.1、SVD(diffusion系列)
介绍了造大量文本-clip对的好方法:对WebVid-10M的长视频切分成多个clip(叫LVD,580M),有3个caption方法:clip中间的帧用Coca标柱\通过V-BLIP获取视频标题\通过LLM对前两帧的标题做概括来做为clip的标题,训练的时候3个方法产生的标题随机取,其中Coca的概率=0.5,其他2个方法的概率是0.25;最后去掉动作较少的(光流强度较小),字幕太多的,美学价值较低(取首,中,尾帧的clipembding 算美学分数)的对,处理完后的数据集叫LVD-F(152M)。
介绍了好的训练范式:VLDM模型,即基于sd模型新增时间层和注意力层(使用预先训练好的文本-图像的模型权重初始化);用LVD-F方法精制的大数据集做预训练,调整模型的所有参数;在高质量小数据集做微调
引入Elo Score评分来比较多个消融模型的效果,这个评分适用于多个模型在比较之前可以用分数量化,比如含有动作因素多的A模型具有分数1.3,含有动作因素少的B模型具有分数0.5。假定有4个模型,设初始分数为R1,R2,R3,R4,现在俩俩竞赛比较,假如模型1和模型2 比较,那么比完之后的评分会进行更新,更新第i个模型的评分方法是:
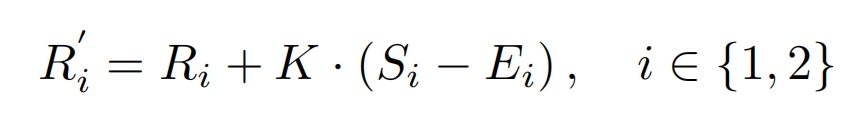
K是权重常数,Si表示该比赛i赢了(=1)还是输了(=0),Ei是本次比赛根据之前得分来预测 i 的结果:
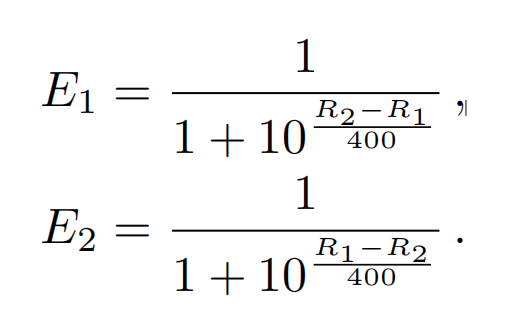
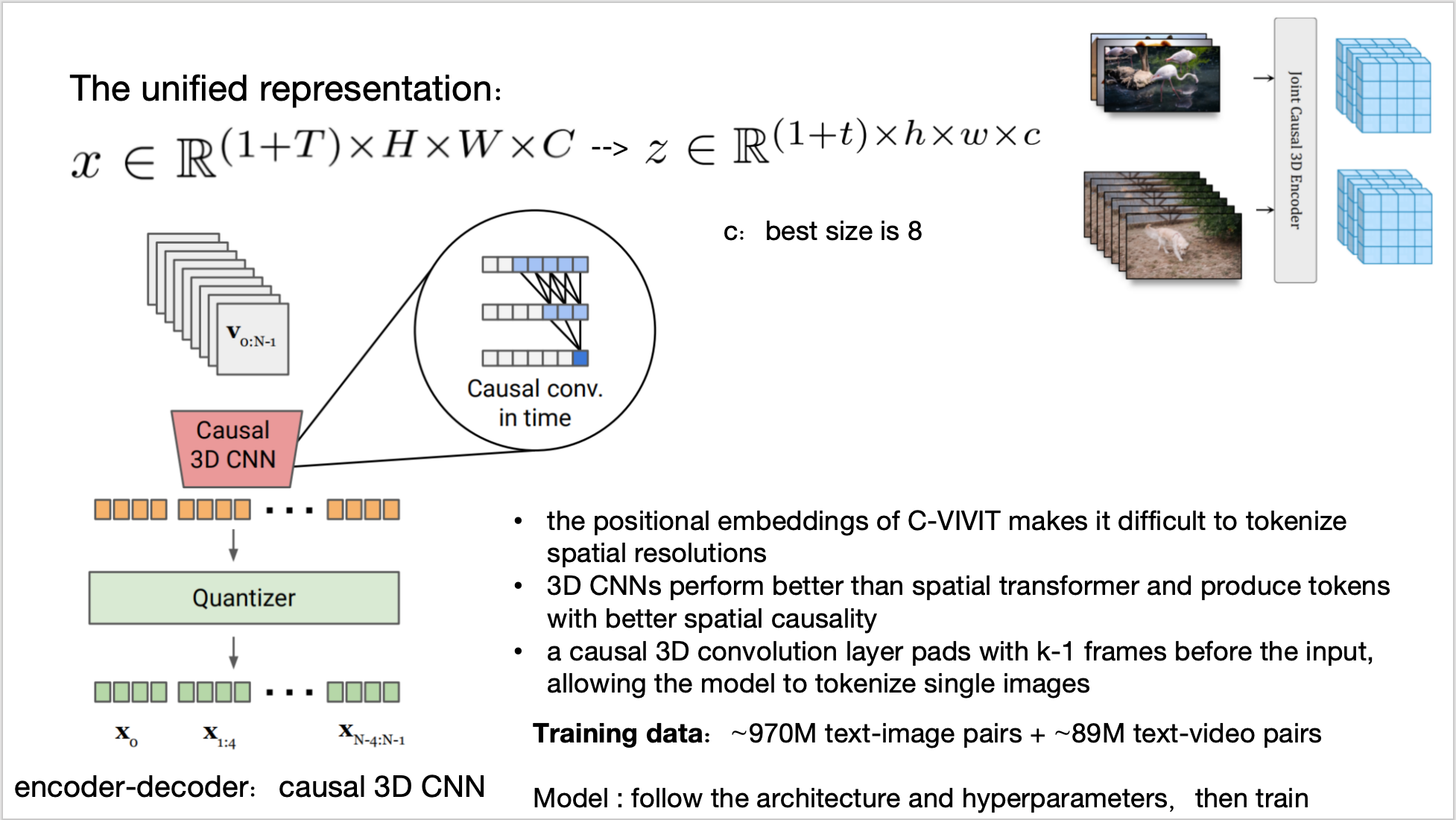
8.2、WALT(diffusion系列)
由于缺乏高质量文本视频对,就将视频\图像映射到统一的隐空间,即将图像视为1帧视频,此处就采用了 MAGVIT-v2 tokenizer 的encoder和decoder,因为它能独立编码视频的第一帧;
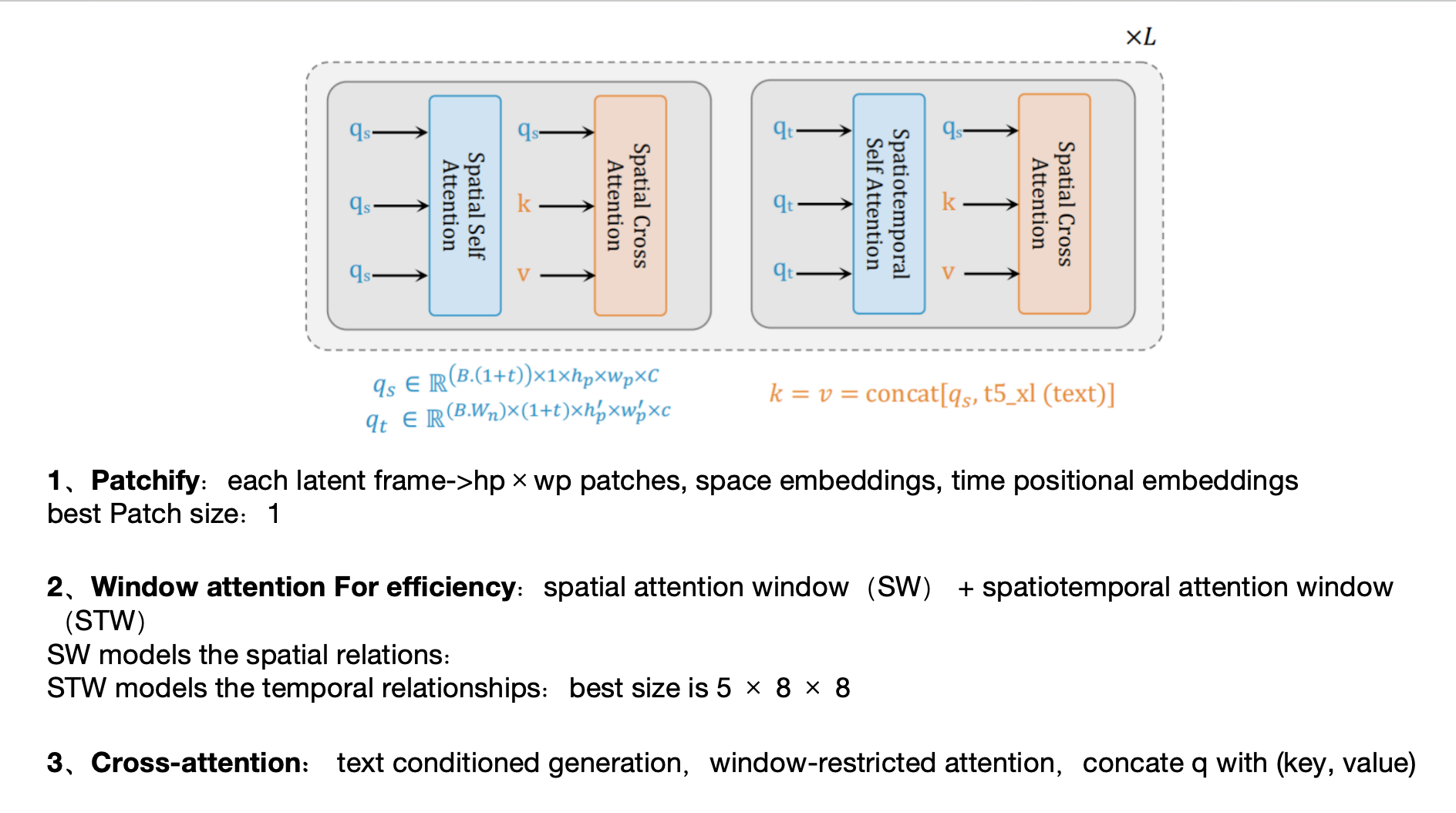
模仿 DIT,把unet换成了Transformer,并做了改动——spatial attention window(SW) + spatiotemporal attention window(STW),以便更好的进行统一图像和视频训练同时实现时空压缩,这是Unet做不到的:每帧分别patchfy,SW对帧内做空间自注意力,STW对多帧做时间自注意力
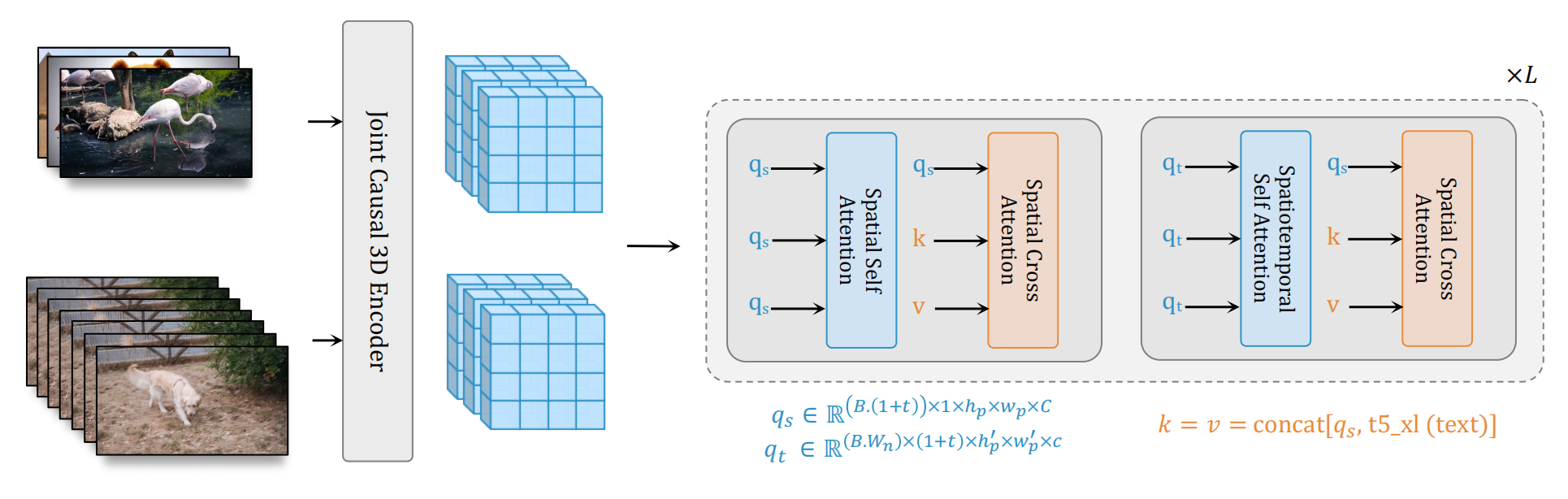
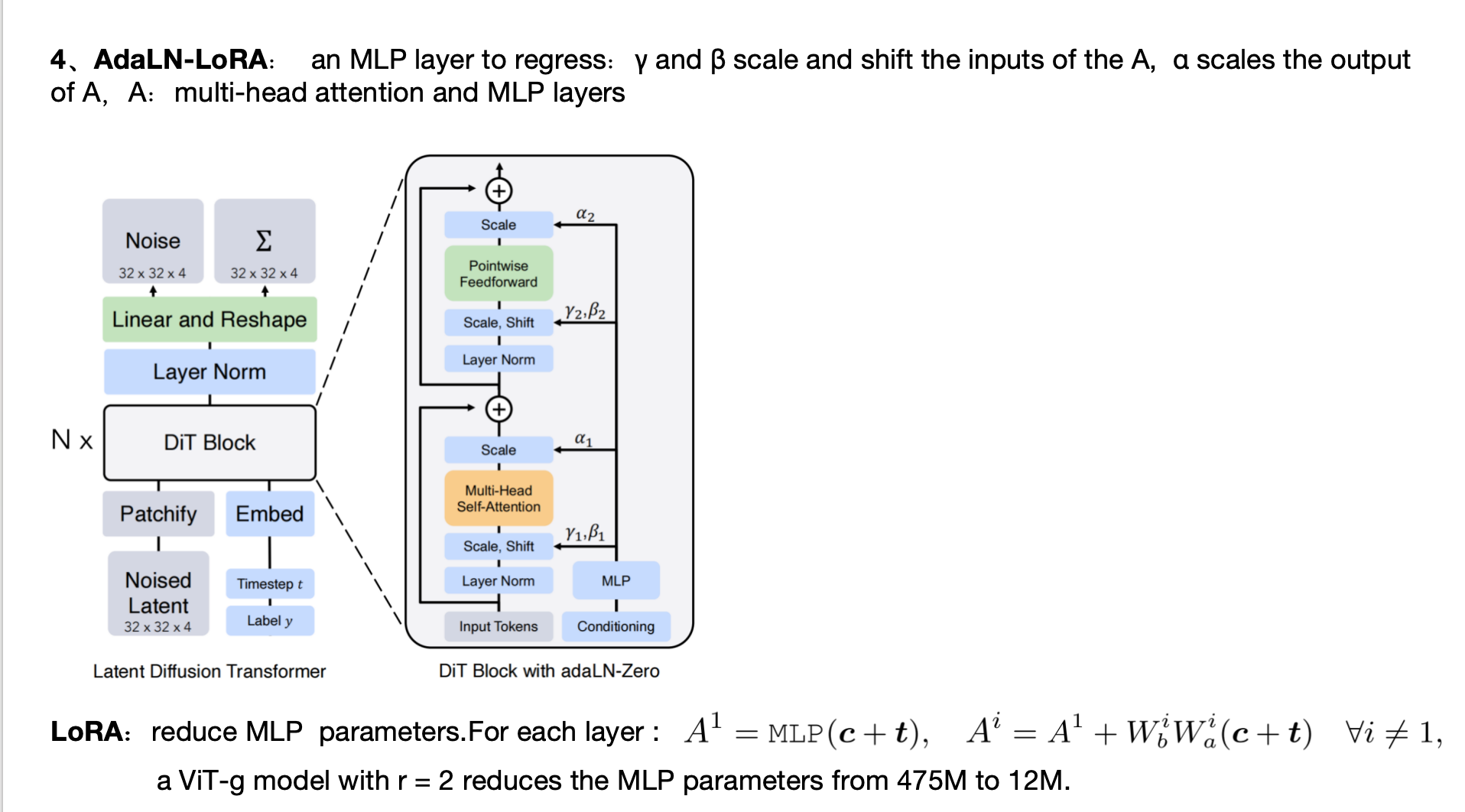
条件生成:Transformer内设计crossattn接受文本条件,crossattn也放到window里,q是input;k,v是文本条件 concat input;延用了DiT的AdaLN支持class label条件生成,并对MLP加了个LoRA;沿用了Self-conditioning 以提高样本生成质量——采样时,由xt生成xt-1时,需要先计算预测的x0,当xt-1算xt-2时,刚才那个预测x0不要丢掉,而是和xt-1拼接作为此时的预测x0,然后用它来采样xt-2,如此的话训练过程也要改动,训练时,以概率p不用self-conditioning,以1-p用:先生成t时刻的预测x0,再和xt拼接生成预测的噪声
image2video/长视频生成:训练时以一定概率实现帧预测任务——用 mask 和 zt 得到可以看到哪些帧,然后拼到zt前面,如果是image2video,可以看到1帧,如果是视频预测,可以看到2帧
超分辨率视频生成:一次性生成计算消耗太大,所以先生成128x128的,然后生成视频通过depth-to-space做个上采样,然后以此为条件再通过2个超分辨率阶段实现高分辨率+上采样
调比例:训练低分辨率模型的时候先用正方形数据集,然后微调的时候如果是其他比例的数据集,可以加入位置嵌入,这样就是适配各种比例大小的数据集了。
由于Noise schedule 在最后一步并没有将图像完全变成随机噪音,这使得训练过程中学习是有偏的,但是测试过程中,我们是从一个随机噪音开始生成的,这种不一致就会出现一定的问题。所以作者通过zero terminal SNR强制使得训练的最后一步变为噪声
Self-Attention 中 Query 和 Key 的计算过程添加了归一化,以帮助大模型做稳定训练
9、
ae:Encoder 到一个特征,然后通过decoder还原,缺点建模不了中间的分布,只学习了离散的点
vae:改进ae,Encoder 到特征分布,然后通过decoder还原,这样就建模了分布,从而分离了编码器和解码器
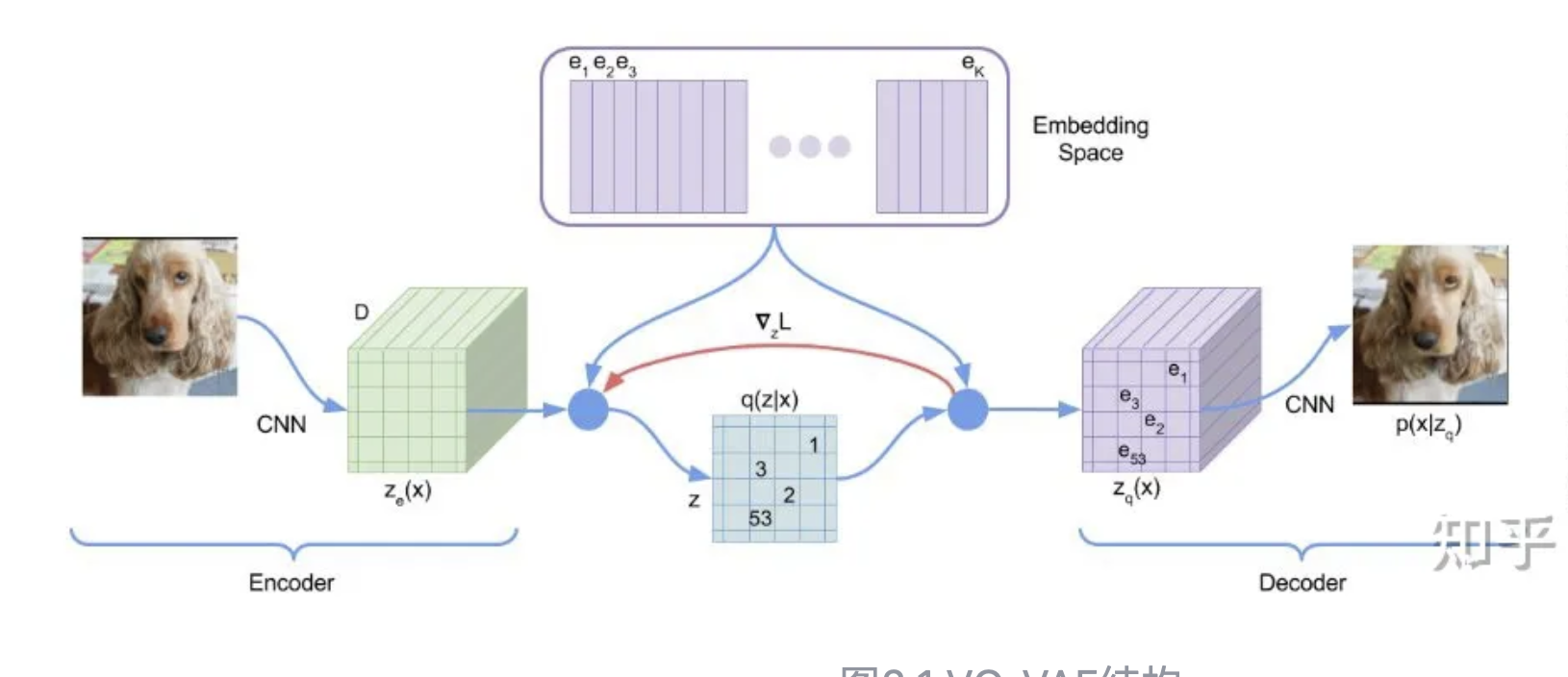
vqvae:改进vae,由于vae分布比较复杂,为了降低学习分布的难度,引入codebook来量化(包含8192个可学习向量,即8192个聚类中心),Encoder 到一个特征,然后看和codebook哪个向量最近,用它代替,然后再decoder解码。训练时codebook的向量也在被训练,以便接近编码器的输出。损失函数包括输入输出的重构损失(形式为MSE),codebook 与 编码器输出的 MSE。由codebook产生的向量很难随机采样出来,所以引入PixelCNN来建模编码器的输出,这是第二步训练PixelCNN。推理的时候就是先用PixelCNN(根据前i - 1个像素输出第i个像素的概率分布)采样,然后通过解码器输出图片。
vqgan:改进vqvae,改进1是:形式为直接MSE的重构损失改为感知误差(perceptual loss)以便提高清晰度,计算方法是把两幅图像分别输入VGG,取出中间某几层卷积层的特征,计算特征图像之间的MSE。改进2是引入了PatchGAN(判别器对图像的每个patch都打分,然后再综合评分)的对抗训练机制;改进3是把PixelCNN换成了Transformer,因为Transformer对小特征图学习到全局信息,至于细节信息可以由编码器解码器负责,Transformer以自回归方式建模编码器输出,根据特征图前i-1的值预测第i个值;针对带条件(约束)的图片生成,条件的编码特征就放到Transformer 原来输入的最前面。
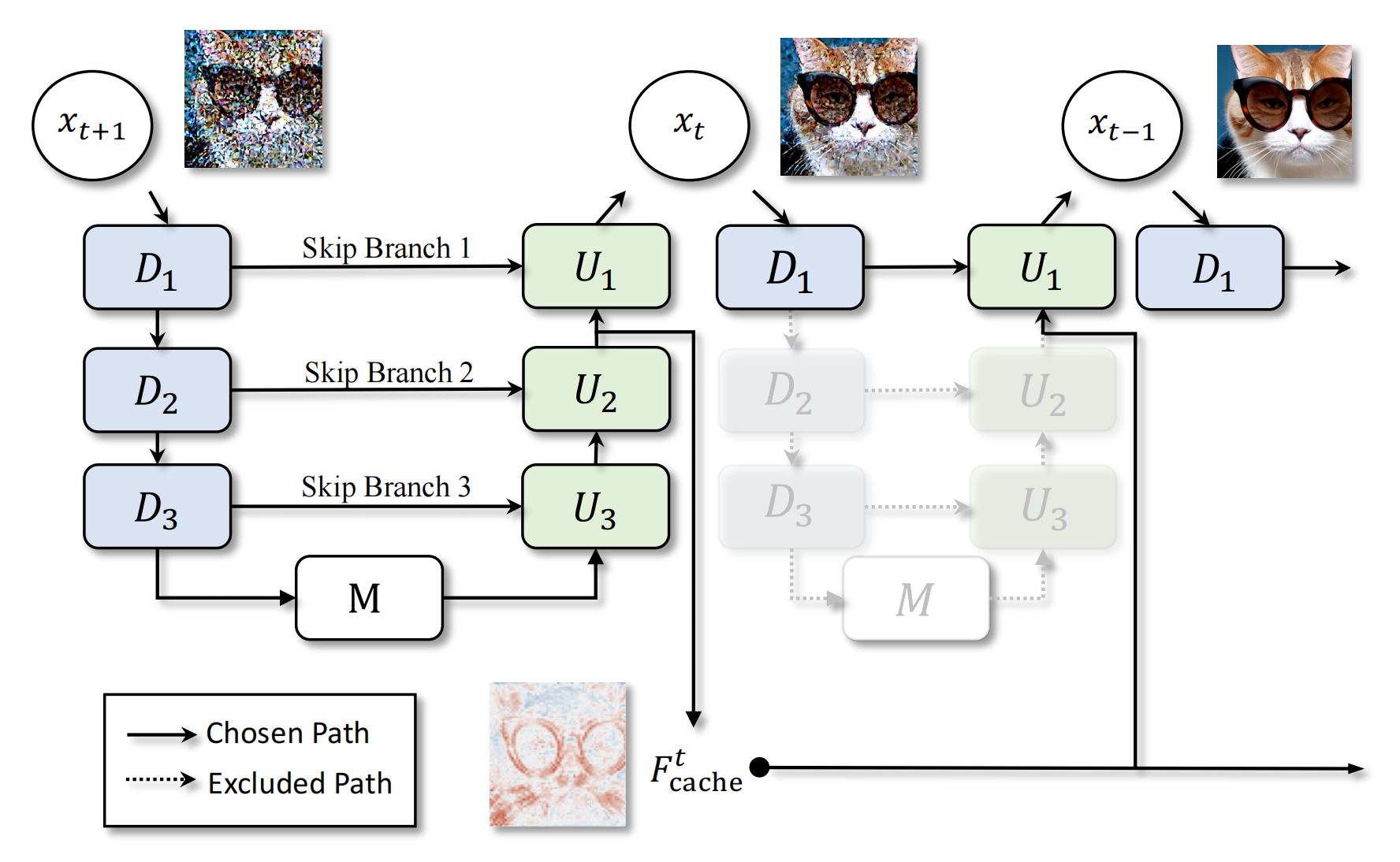
10、deepcache
观察到在推理过程中,邻近的step的UNET中间层特征有很大相似性,因此缓存前一步的中间层特征,在下一步预测的时候直接传到unet中:
11、FaceStudio
文+style图+id图=》风格化的图
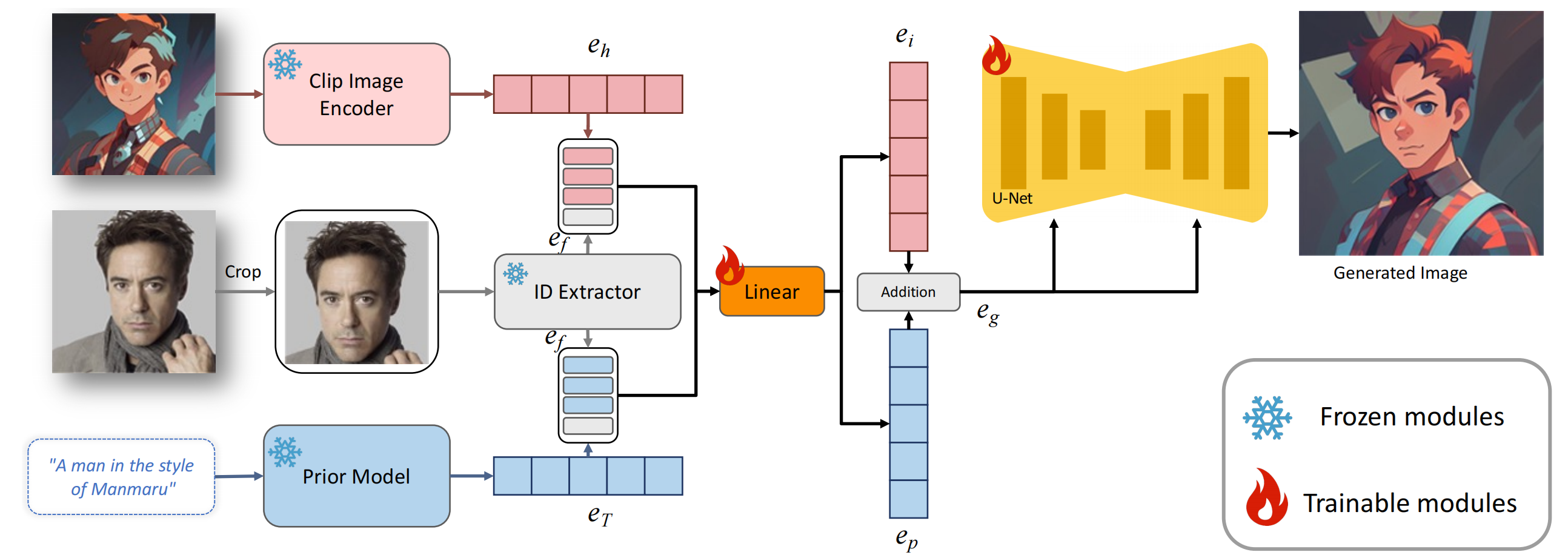
style图 通过clip 再和 ef 拼接(视觉空间),再通过线性层映射;文本先通过clip+Prior 再和 ef 拼接(视觉空间),再通过同一个线性层映射,eg是2者的混合:
![]()
推理时,alpha 可实现插值,是更像文本还是更像 id+style
训练时,FFHQ(主要):同一个图mask脸做style图,单取脸做id图,再做gt,完成一个重建任务,文本就不需要了;LAION dataset (次要)对于没有人脸的图片,人脸向量变0,完成重建,以学习不同风格
对于多人推理,ef是每个人的ef的加权求和;在UNET中,每个人用自己的qkv
12、textual inversion
新增一个 S* 对应的 token embedding,模型先学习概念,此时只微调该 token embedding ,其他参数不变
13、PhotoMaker
能够实现多个id混合
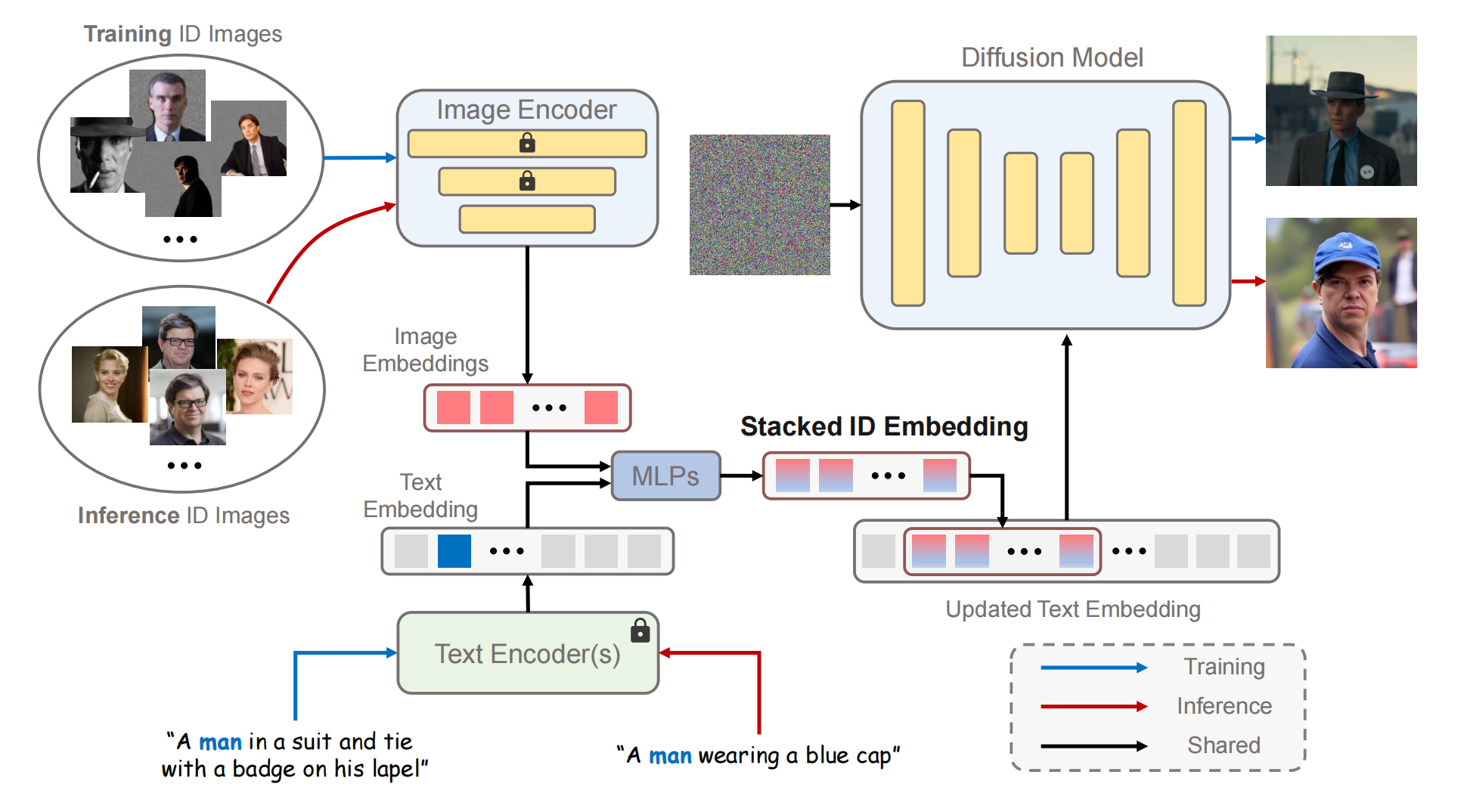
训练时,输入同一个人的N张图片,文本,然后将这N个id向量和man通过mlp融合为N个向量,这样就把id注入了文本,gt就是对应场景下的人
推理时,可以输入不同人的图片进去
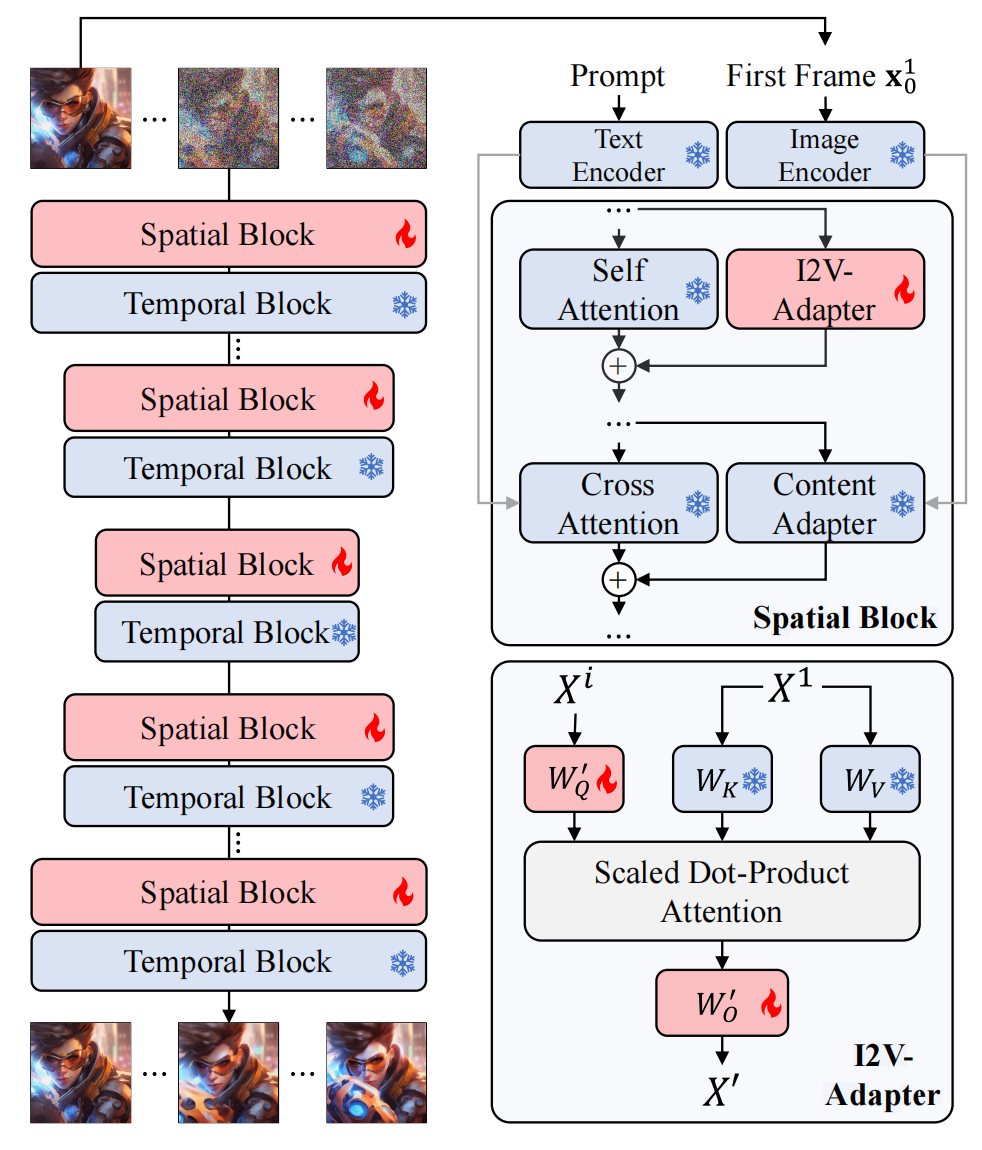
14、I2V-Adapter
image+text->video
在AnimateDiff上改的,只微调部分空间权重。spatial block 的 自注意力层(controlling the layout, object shapes, as well as fine-grained spatial details)旁边新增 I2V-Adapter,让每一帧都注意到参考图的细节部分;crossattn旁边加上冻住的Content Adapter(ipa),注入参考图的高级语义; 采样的时候,对参考图模糊再加噪,以此作为其他帧采样的起点,模糊的方式是直接模糊与原图的按mask的加权;
训练集是WebVid-10M + 自己收集的无水印视频
训练好的I2V-Adapter可以实现热插拔,和controlnet,dreambooth 底膜结合
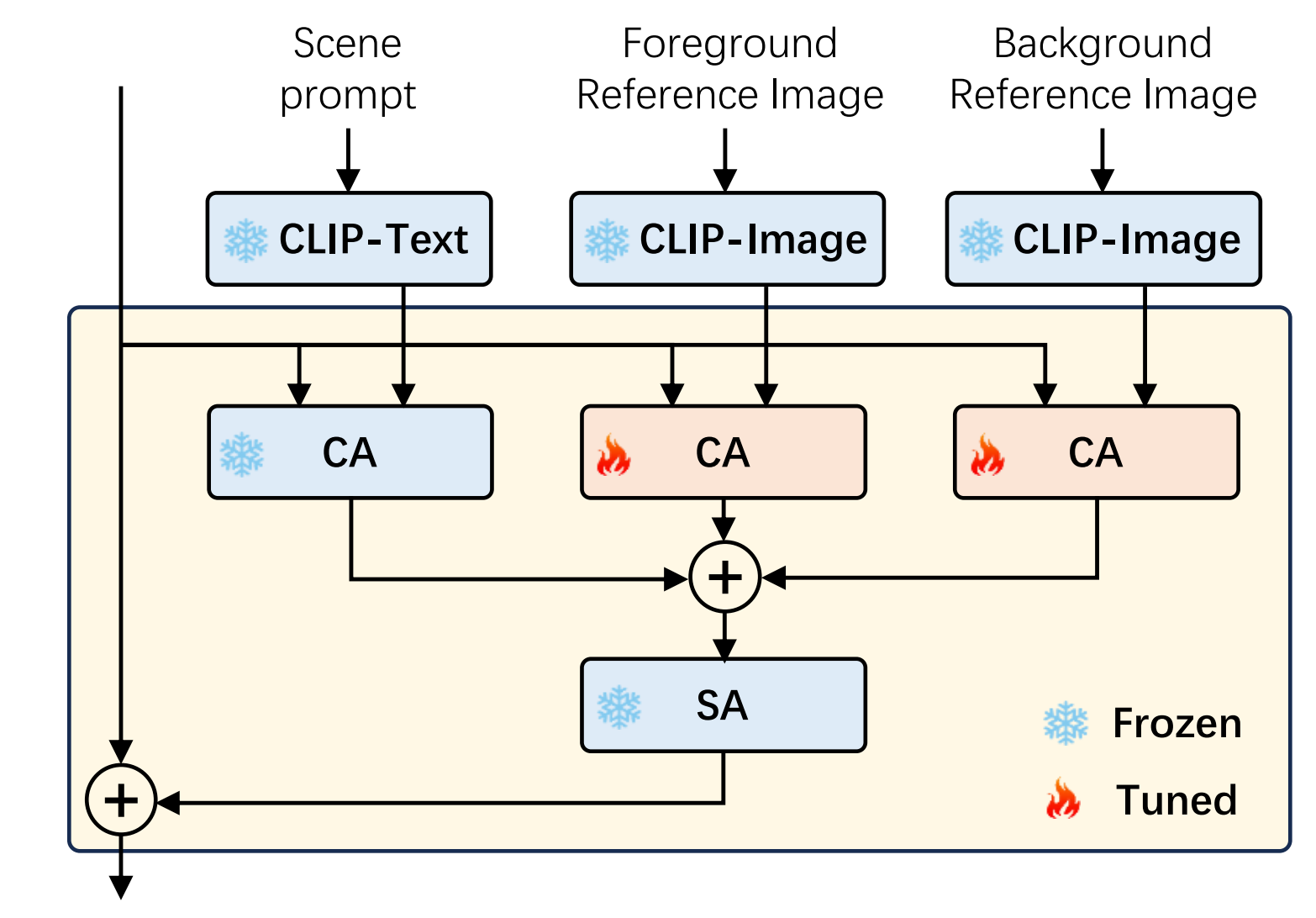
15、VideoDrafter
text-film
先给个主题prompt,用LLM生成每个场景prompt(内容,前景物体,背景物体,相机移动方向)以及每个实体的详细描述;对于一个场景来说,把所有实体描述输入到T2I模型中分别生成实体图片,每个实体图片再用U2-Net检测和分割出所有前景和背景区域;第三部将每个场景制作成clip再拼起来,分为2个阶段,第一阶段IMG生成场景图片,第二阶段VID让该图片动起来,IMG接受场景描述,该场景下的所有前景图和背景图(多个前景图feature做concat),模型对sd做了改造,新增了2个crossattn,训练集是LAION-2B,IMG阶段可以确保多个场景下的实体一致性:
VID接受场景图片和动作,动作就是标签,总共有400种动作,因此动作向量长400,取值0/1,再经过一层线性映射作为Action-embed,模型对 Stable Diffusion XL + inserting temporal attentions and temporal convolutions 做了改进,训练集合是WebVid-10M和HD-VG-130M:
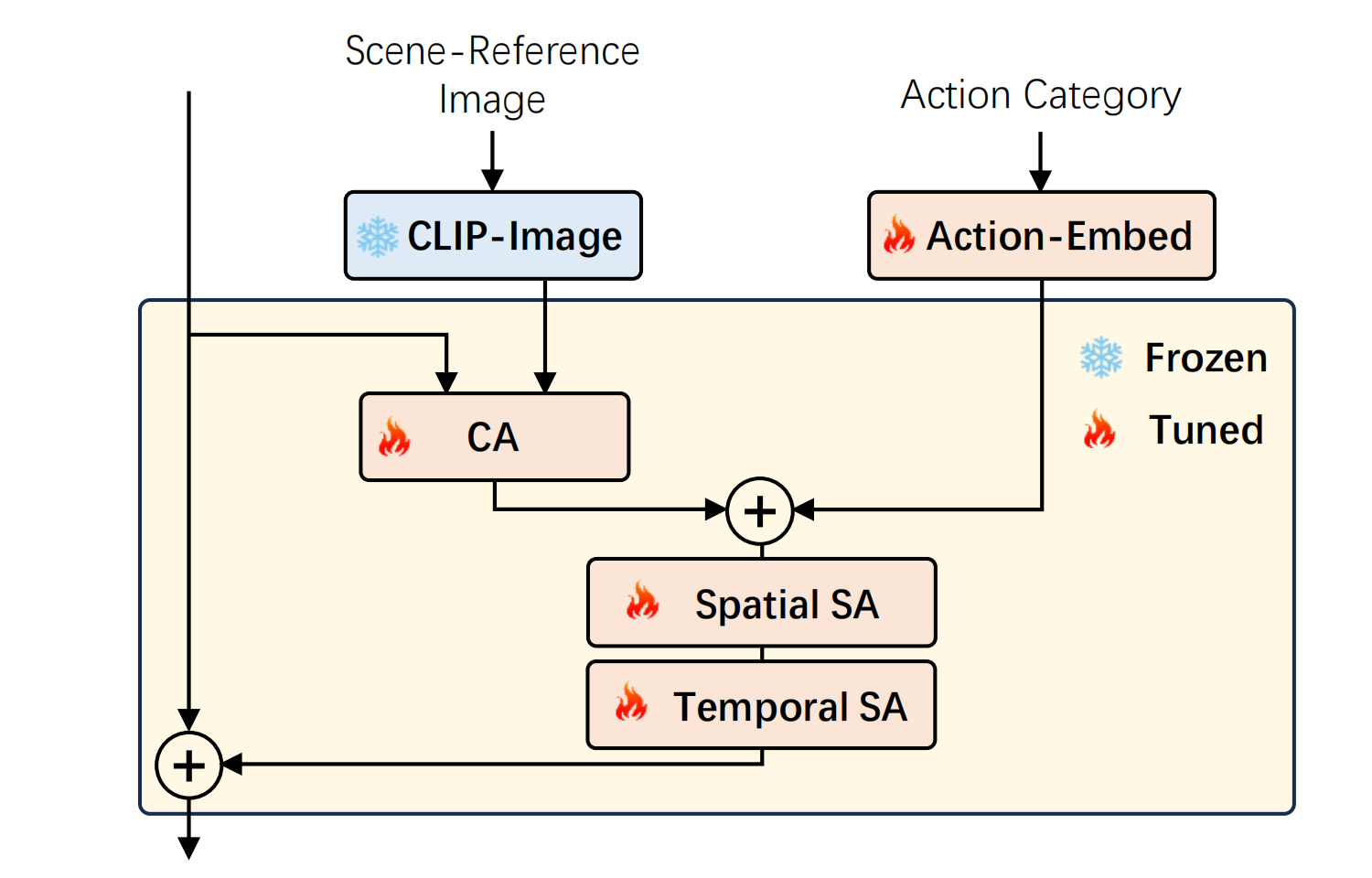
最后采样时,经过初始步去噪后引入warp来加入相机动作。
16、pixelDance
对ldm加入时间层来扩展到视频领域,训练时给定文本、视频第一帧过vae再加噪、可选(为了丰富视频动作,同时避免过于依赖最后一帧,即直接复制过去)的加噪的视频最后一帧过vae再加噪,然后把第一帧和最后一帧中间pad空帧形成视频条件,该条件直接拼在zt上。推理时一个一个clip生成,前一个clip的最后一帧用于后一个生成的视频条件,所以可用于生成长视频。训练集是webvid-10m
17、nuwa-xl
vae新增时间卷积层和时间注意力层,初始化为 id 映射,然后用视频训练。分层结构: 先用global diffusion (3d unet)生成粗粒度L帧视频,它接受文本和空的(0)视频条件。然后再用 local diffusion生成细粒度视频,它接受文本和视频条件,该视频的首尾帧是global diffusion输出的第一和第二帧,中间是空的,如此迭代。具体的,接收视频条件和文本的方式如下,对于unet的每个分辨率下的BLOCK:
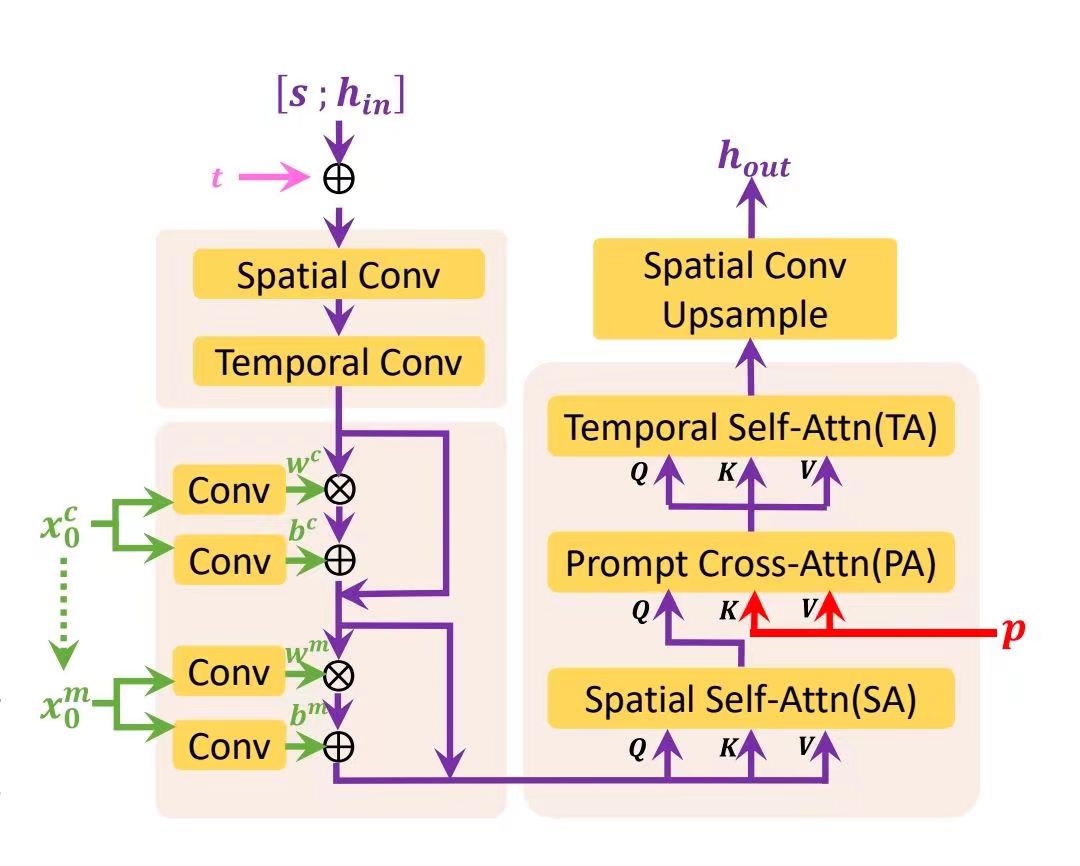
s是跳跃连接,x0c是视频条件,x0m是二进制掩码,表示视频条件的哪些帧能看见,视频条件通过scale和shift注入,SA层把时间纬度做bz,TA层把 hw作为bz
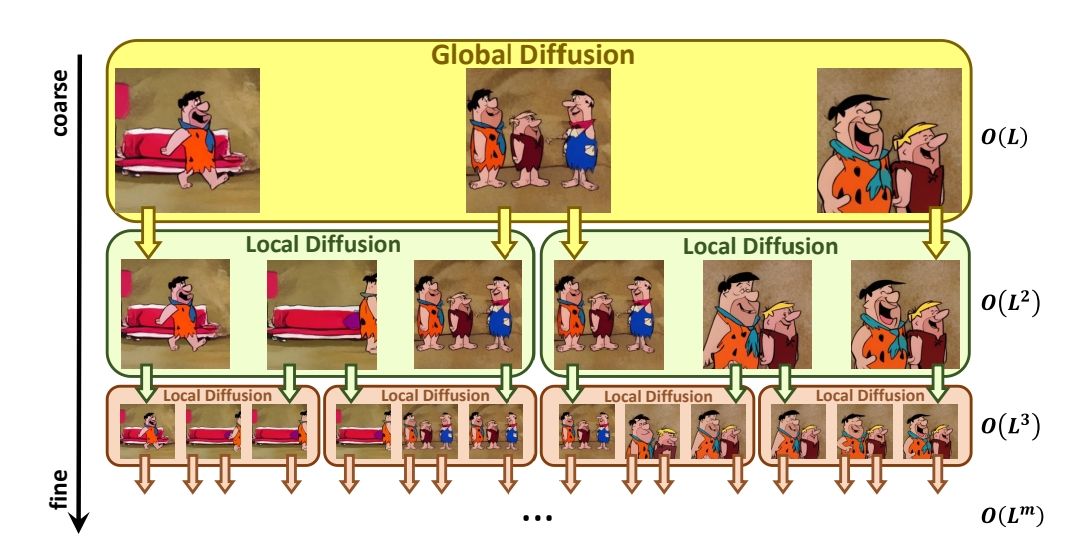
训练global diffusion时,是训文生视频,训练local diffusion时,是训练插帧任务
缺点是生成的视频不是很连续
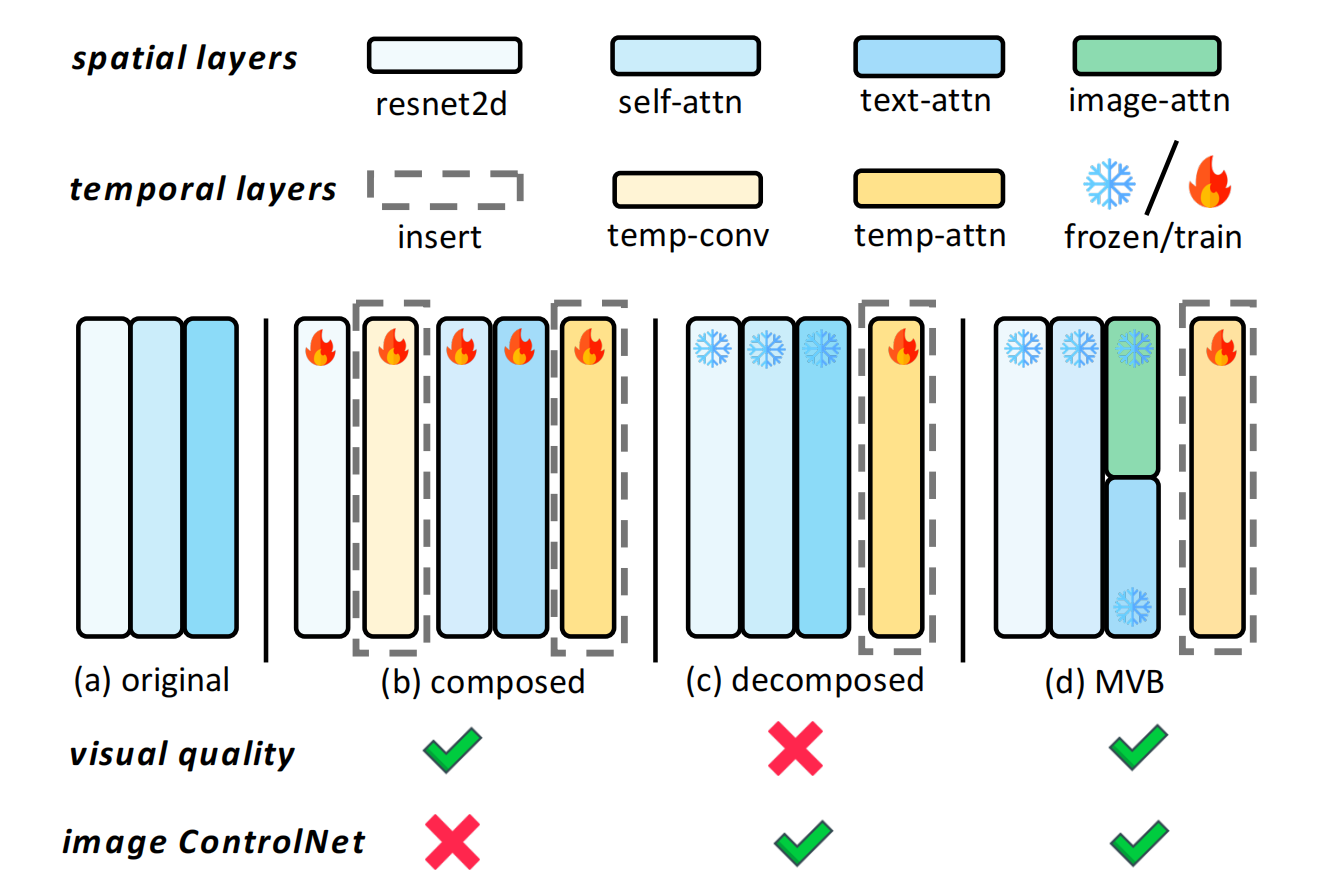
18、MoonShot
文+图=》视频,同时兼容controlnet
由于animatediff兼容controlnet,所以对animatediff改的,就是在text-attn再加上一个图像的attn,图像条件做k,v
下图的a:2dunet,b:3Dunet(Make-a-scene, Tune-a-video,Magicvideo),c:3Dunet(animatediff),d:3Dunet(MoonShot)
19、WALT
magvitv2+diffusion+Transformer

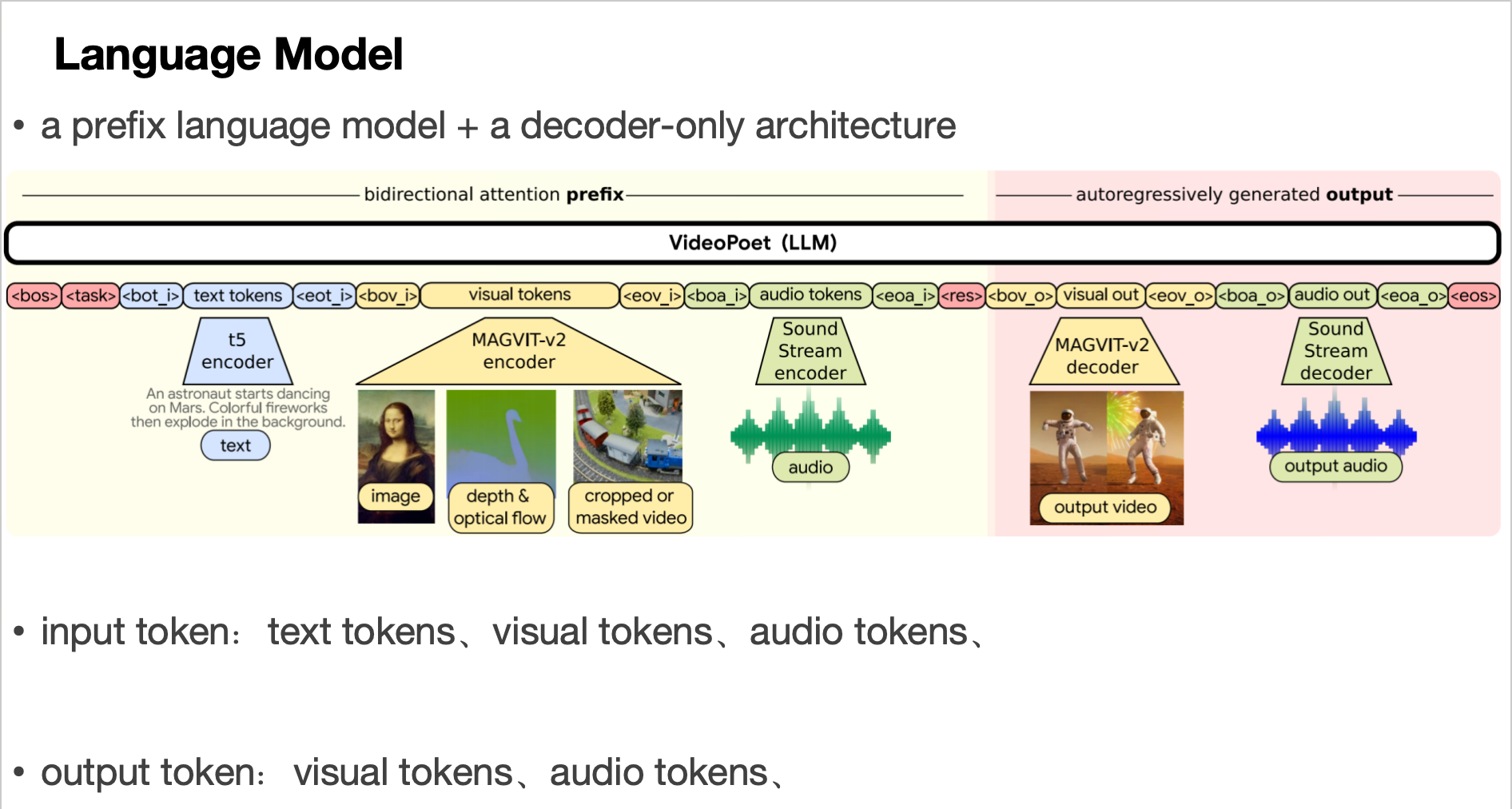
19、VideoPoet
magvitv2+LLM






 浙公网安备 33010602011771号
浙公网安备 33010602011771号