
sd3
1、diffface:任务是原来的脸xsrc不怎么变,就背景变成 xtarget 的背景,但是脸上的神情要和 xtarget 新脸的神情类似,更重要的是人还是同一个人xsrc
训练ddpm方面:
采用基于id的 ddpm,即在epsθ(xt,t)里面加入了脸的 id 向量vid(通过预训练好的模型D提取,如ArcFace、CosFace)=>epsθ(xt, t , vid)
另外新定义一个损失||D(x0~)-vid||加到噪声损失上:x0~指的是,抽到 xt 以后,通过 q(xt|x0) 倒推出预测的x0~:
![]()
完成的训练算法:

基于Classifier-Guidance进行采样,针对第 t 步:
此处的条件y = xsrc,sim(xt,y)从3个角度定义为3个“距离”的带权求和之负:Gid,Gsem,Ggaze
Gid:期望由 xt 可以推出预测的x0~的 id 信息能与xsrc的 id 信息越近越好,这样就能保留xsrc的人脸特征了,Gid = 1 − cos(D(xsrc),D(x0~))
Gsem:期望 预测的x0~ 能和 xtarget 中的新人脸在表情、神态、结构上相似 ,Gsem = || DF(xtarget) - DF(x0~)|| , DF是face parsing model,用于识别脸部的五官
Ggaze:期望 预测的x0~ 能和 xtarget 中的新人脸在眼神上相似 ,先用现成的脸部检测工具裁剪出2张图的眼睛截图,Ggaze = || DG(xtarget) - DG(x0~)|| , DG是眼神网络,用于提取眼神向量
由p(xt-1|xt,y)生成出xt-1~后,还要和 t-1时刻的 xtarget 目标图像(通过p(xt-1|x0) 公式,只不过x0是xtarget)融合,这是为了将背景变成 xtarget 的背景,同时Mt 是掩码,表示将两个图像混合的程度,是动态变化的,一开始Mt=0,表示全部遮住生成的合成图,全部用目标图,到后面逐渐趋于1:
xt-1~ * Mt + xtarget * (1-Mt) => xt-1
完整的采样算法:

2、clip
能通过图片的编码器提取带有文本语义的图片特征向量
能通过文本的编码器提取带有图片语义的文本特征向量
训练方法:
先采用对比学习(定义正负样本,正样本特征向量会类似,负样本特征向量会不类似)做预训练:拿n个图片文本对,文本一般都是句子,分别通过text encoder 和 image encoder 得到n个文本向量(T1,T2,...,TN)和n个图片向量(I1,I2,I3,...,IN),做相似度计算得到一个相似度矩阵,目标是使得对角线上都相似,其他地方都不相似
zero-shot:
将plane,car,..变成 a photo of a plane, a photo of a car....,然后输入到预训练好的text encoder 得到句子向量(T1,...,TN),拿一张图片输入到预训练好的 image encoder 得到特征向量 I1,和每个T算相似度,取最相似的
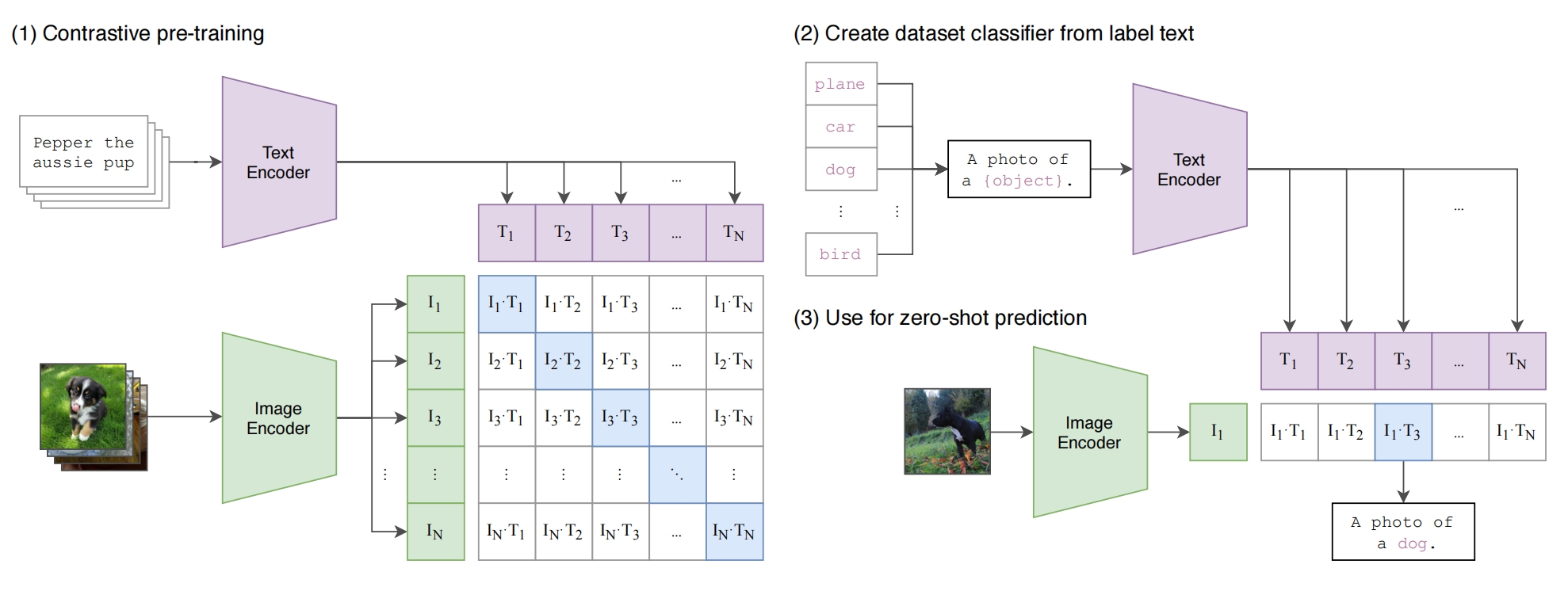
改进的 clip 新增对同一个图片的 loss,假定 image encoder 是VIT,同一个图片通过VIT两次(区别仅仅是一开始的数据增强的随机性:随机色彩变换、随机灰度、随机水平翻转、高斯滤波、随机裁剪、标准化),第一次输出p1,p2,...,p33,第二次输出k1,k2,...,k33,期望 p1 在p2,p3,...p33,k1,...,k33 里面(除了自己)与 k1 要最相似(相似度用两个向量乘积表示),期望 p2...,期望 k33...
3、BLIP2
将图片向量通过 QFormer 对齐到文本向量空间,然后就能和文本特征进行直接融合!能够完成vqa,image encoder 用的是 ViT, LLM用的是T5(xxl:11B,xl:3B,xl 是实际用的)
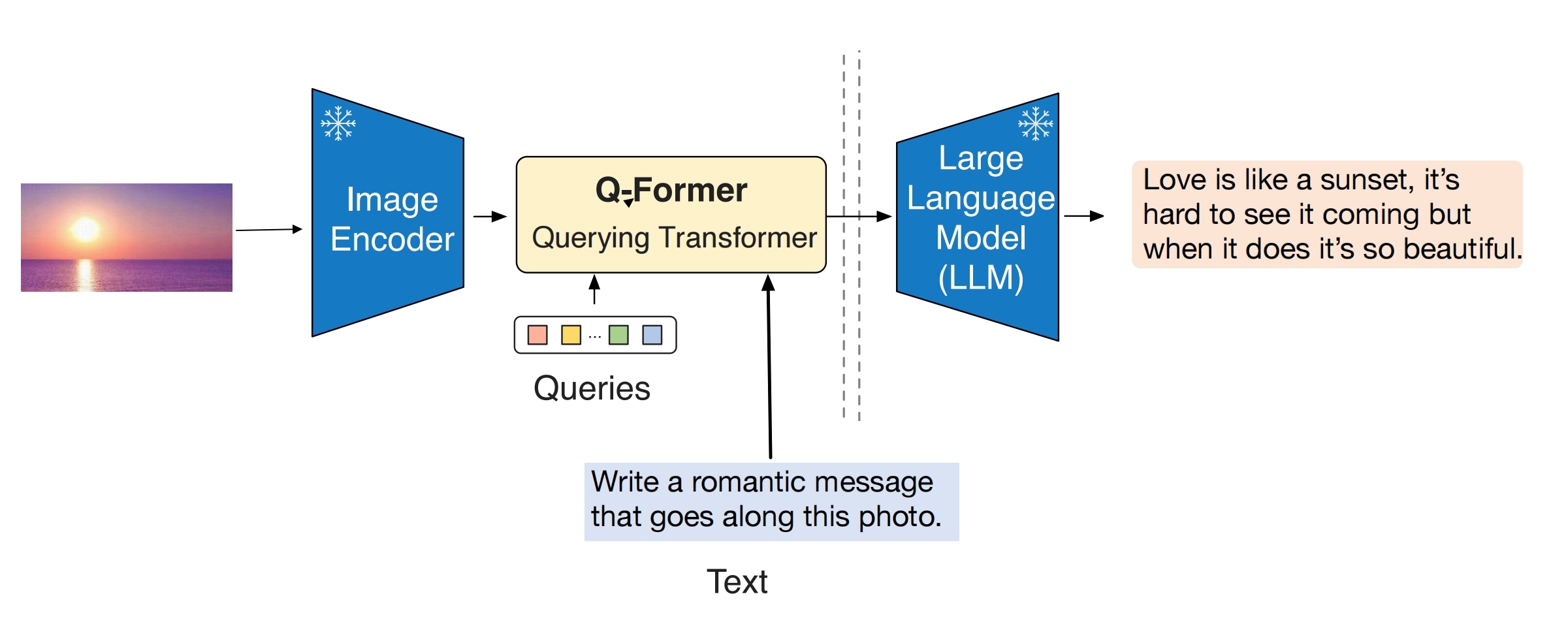
下图是预测阶段的图,图中除了冻住的模型,其余部分叫Qformer,在最后一部分实现了图文对齐!训练阶段就是训练Qformer,额外多了个Transformer(图中没画),通过训练图文匹配 loss + 文本生成 loss 以达到将图片向量映射到了文本向量空间的目的
3、miniGpt4
也能完成vqa,就是 Blip2的 LLM 由T5换成了Vicuna(基于 LLaMA 13B微调,其中 LLaMA 是 transformer decoder,改进了:input处进行正则化,SwiGLU激活函数,rope编码 ),另外对 Qformer 的输出新增了 可训练的 linear 层,以实现Qformer 对 Vicuna 的对齐,其他地方全是冻住的

4、llave
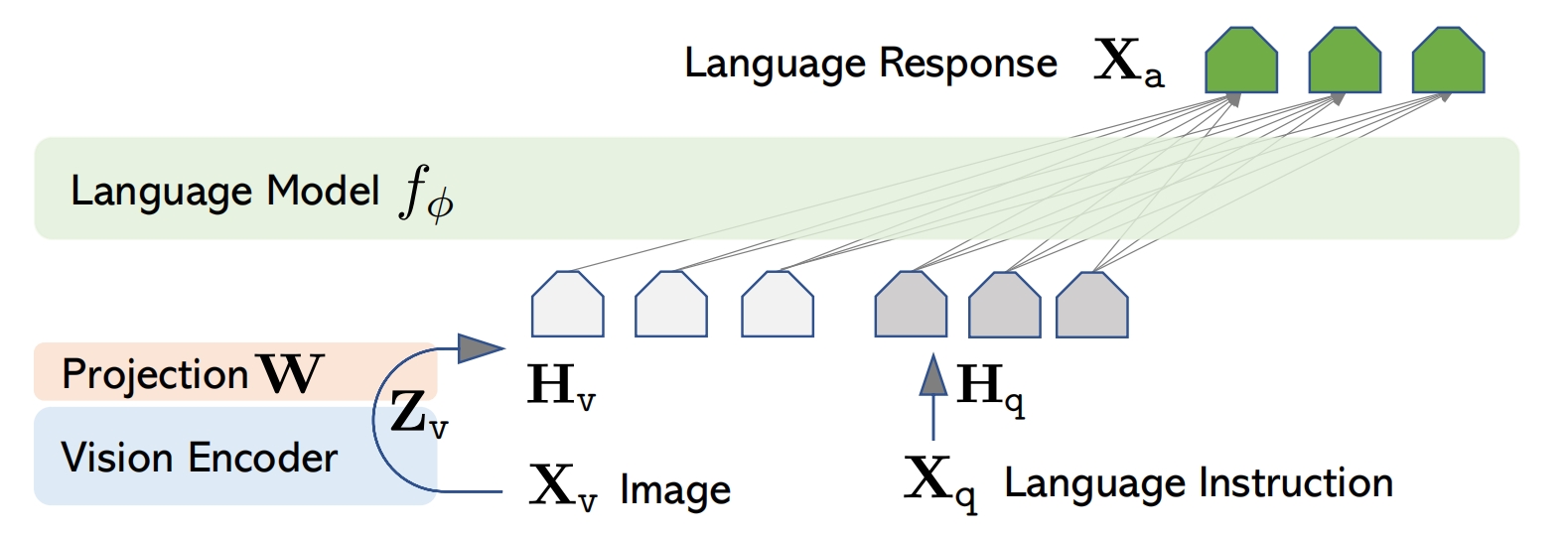
也能完成vqa,图片通过vit之后直接接了1个线性层映射到图片token了,没有用到Qformer
4、Dalle2
文生图模型
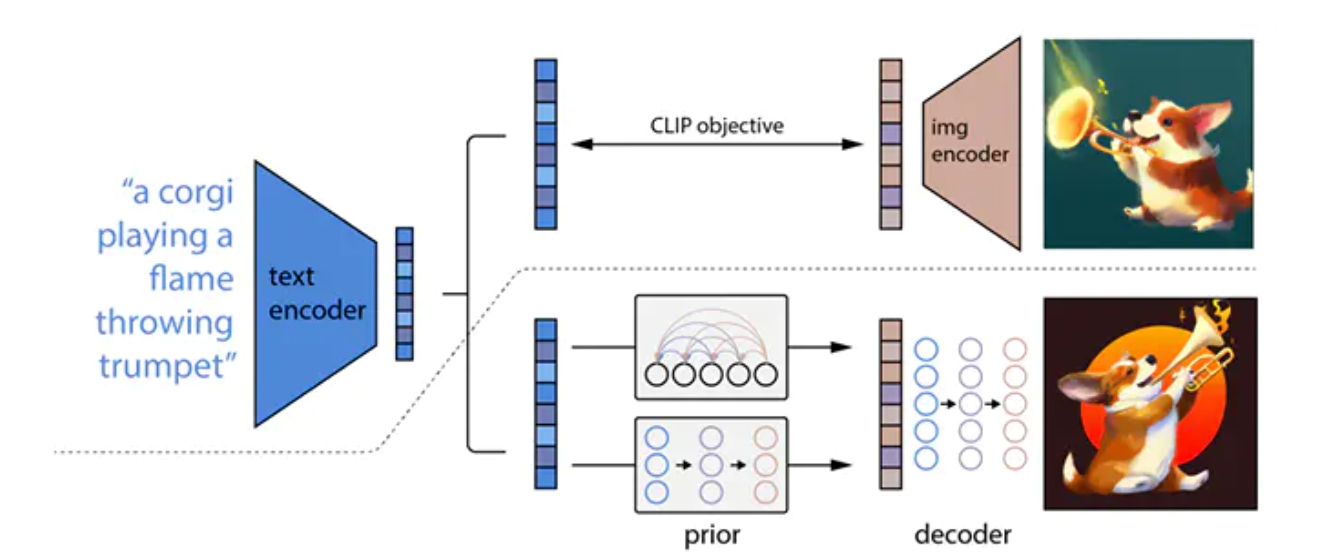
上面是训练好的CLIP模型,拿过来直接用,下面是Dalle2模型,分为 prior 和 decoder 部分
训练阶段:
假定图片1和文本1是配对的正样本
decoder 用于将图片向量还原为图片,采用条件扩散模型(不是通常意义的那种扩散),条件是图片1通过clip的图片编码器的 cls 向量,输出的目标是图片1
prior 用于将文本向量转为图片向量,采用条件扩散模型(不是通常意义的那种扩散),条件是文本1通过clip的文本编码器的向量,输出的目标是图片1通过clip 的图片编码器的 cls 向量
预测阶段:
给定一个文本标题,先通过clip的文本编码器得到文本向量,作为 prior 模型的条件,通过 prior 模型生成预测的图片 cls 向量,该向量作为decoder的条件,通过 decoder 输出图片
5、controlnet
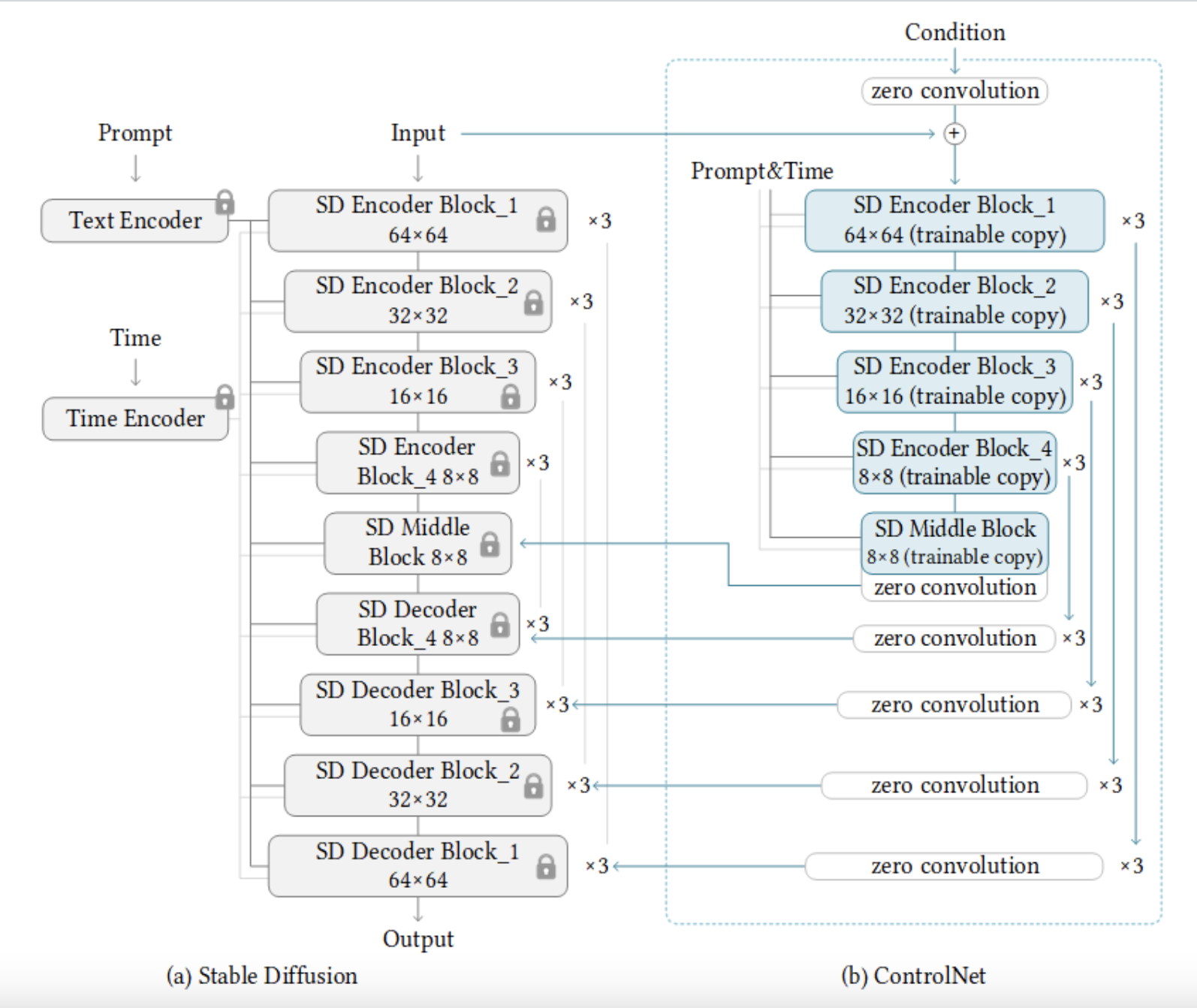
对条件 unet 的改进,可以再新增个条件(此时就是文本条件再加个条件,比如文➕控制图生成图,但是因为它是相加的结构,所以控制图都是轮廓图,比如canny边缘等,所以只能根据轮廓+prompt,来填补轮廓细节),模型方面就是复制并冻住了条件unet的原始权重,新建了很多可训练的 zero 卷积层,只训练新增的神经网络就好了,这样不仅保留了原始的能力,还能微调到特定任务。如果新增的条件是一个图,则让它通过7个(conv+silu)+zero conv,然后直接加到 xt 的那个分支上,文还是通过cross attention交互。
下图中,Unet 下采样有4块,前三块是 CrossAttnDownBlock2D(需要文本向量),第四块是 DownBlock2D;中间是1个UNetMidBlock2DCrossAttn(需要文本);上采样有4块,第一块是UpBlock2D,后三块是CrossAttnUpBlock2D(需要文本),这四块还接受对应的上采样的中间结果(skip branch),接受方式是先和hidden state拼接,再进块内
6、e4t
训练数据集:tag(如art)风格的图+tag,训练让模型知道这个图片的风格是tag
预测的时候模型输入:tag风格的图片+含有tag的prompt,模型输出prompt希望的图片
7、T2I
冻住扩散模型,新建一个adapter用于处理结构化条件,比如canny图,通过adapter生成4个编码向量f[0],f[1],f[2],f[3],直接加到unet对应的编码层中,训练阶段就只训练adapter就行

8、edit
直接拿一个训练好的ddpm,采样的时候用 Classifier-Guidance 方法,假设原图片是x,编辑区域是 mask,采样的中间结果是 xt
先将x0通过q(xk|x0)加噪到xk:
![]()
对xk采样解噪:

9、farl
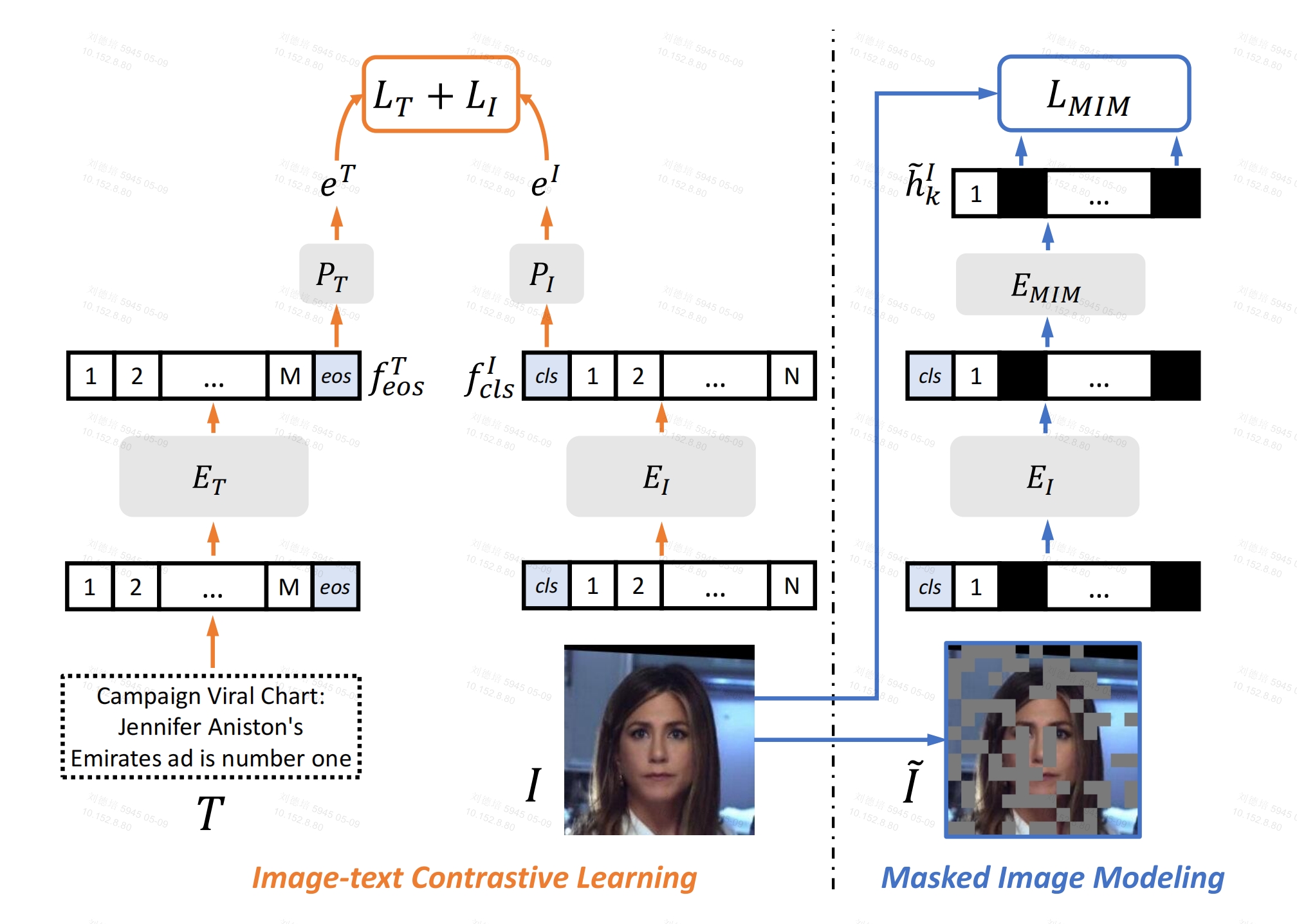
训练一个人脸领域通用的 image encoder和 text encoder,然后应用到3个下游任务中:Face parsing(根据人脸生成分割图)、Face alignment(根据人脸生成关键点)、Face attributes recognition(根据人脸预测多个属性,如性别,种族,年龄)
作者先从LAION中过滤出有人脸的图文对,做了新数据集LAION-FACE
image encoder(EI)基于 vit,text encoder (ET)基于 Transformer(结构和clip一样),针对LAION-FACE做预训练
总损失是两个损失加权和,ITC损失和 MIM 损失
ITC损失:包括2个小损失:文本到图像损失,图像到文本损失,假定B个图文对
文本到图像损失:取文本的eos向量fteos,这个向量要和对应pair的图像cls最相似(相似度要大),和其他 B-1 个图片的cls不相似(相似度要小)
图像到文本损失:取图片的cls向量ficls,这个向量要和对应pair的文本fteos最相似(相似度要大),和其他 B-1 个文本的fteos不相似(相似度要小)

MIM 损失:
对图像打成patch,随机对部分patch掩码,通过EI之后,再通过EMIM(1个Transform block),最后被遮掩的patch向量分别通过一个分类层,这个分类层输出这个被遮掩的patch应该是哪个patch(索引表示)。在dvae空间中,有固定个数的向量,每个patch通过dvae都有唯一的索引,此处的索引就是patch 在 dvae空间中的索引。
10、多概念sd
和db训练方式类似,只不过不再是sks一个概念了,数据集可以变多个,同时只微调注意力参数,其他不变(db是微调所有,除了vae)
11、collaborative diffusion:
生成:文+fp图=》图
原理:就是把eps看成是多个eps叠加求和而已。
具体的:把文,fp图看成2种模态(m=1,m=2),对应2个unet,能够得到eps1,eps2;再来两个unet(论文叫做dynamic diffuser),得到i1,i2,i1和i2再通过softmax得到i1',i2',分别作为eps1,eps2的权重,然后加权求和作为eps

编辑:原图(input image)+文(条件1)+fp图(条件2)=》图(edited image)

思路:借鉴了 Imagic 的思路。
针对第m个模态,比如文本C,只训练sd的 text encoder 参数,sd其他参数固定,这是为了得到更接近原图的文本向量Copt;
然后用Copt,固定sd的 text encoder 参数,训练 sd 其他参数,这是为了让sd在Copt的基础上更接近原图;
最后文本向量int=Copt和原始文本向量的线性差值
在采样的时候,条件用int,sd用上面前面训练过的 sd

12、PIDM
原图+姿态图=》图
训练:
训练集是:(原图xs,姿态图xp,目标图),Hn和He共同用于预测噪声。He是Unet编码器,会输出不同层的特征向量,然后把这些向量注入到Hn的所有层中,Hn也是unet结构,注入的方式是通过注意力机制注入,Hn做Q,He提供的特征做K,V。Hn接受(姿态图,目标图),这两个先拼接起来再送给Hn。
采样:
仅对条件的噪声估计做更改:
![]()
其中:
![]()
![]()
style要xs,不要xp,也是要减去无条件的噪声


 浙公网安备 33010602011771号
浙公网安备 33010602011771号