
评论
1、AGPC
针对一篇博客,可以根据用户画像个性化输出用户的评论
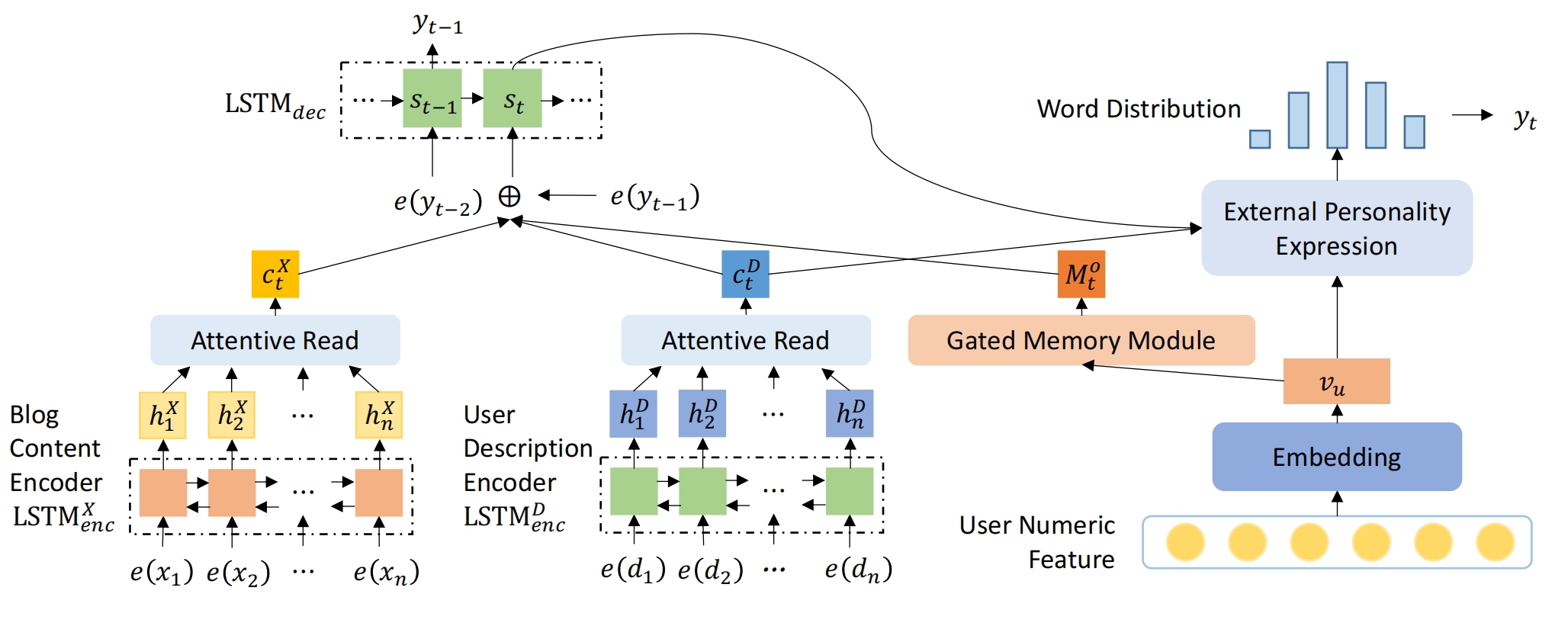
数据集格式:1个博客,该博客下的所有评论,评论由评论内容和评论者的信息组成
e(x1)...e(xn):博客的分词+id映射+embeding
e(d1)...e(dn):用户个人介绍(比如个性签名)的分词+id映射+embeding
User Numeric Feature:用户的一些属性,包括连续型属性(Age,Birthday)和离散型属性(Gender, City,Province),连续型属性直接拼接作为连续型向量,离散型属性分别转为onehot,再把多个onehot拼接作为离散型向量,最后连续型向量和离散型向量拼接起来 ,其中某个属性的onehot的转换方式,比如求某人的City是6,提前定义一个city的范围,如47,则该样本的 City 的onehot长47,第6个元素是1,其他位置是0
Encoder LSTM使用双向LSTM,输出所有单词的向量
Attentive Read:使用注意力机制(比如BahdanauAttention)输出一个句子向量
Embedding:1个全连接层做降维
LSTMdec:用于解码,使用单向LSTM网络,当前时间步 t 的输入= 上一个时间步的输出 拼接 ctX 拼接 ctD 拼接 Mto,当前时间步的输出可以映射为字典向量再通过sof得到当前时间步预测的词(我认为这个就可以了,但是作者没有这么做,而是加了个External Personality Expression)
Gated Memory Module:当时间的推进( t 的增大),Vu应该逐渐减弱,即当一句话开始生成时,Vu的很重要,然而随着单词的不断生成,Vu的重要性逐渐下降,所以 t 时刻的用户数字特征为Mt,而初始时刻的M0就是Vu:

其中 st 是LSTMdec 在 t 时刻的状态(比如 t 时刻的 c和h 拼接),gut每个元素的范围在0-1,用于弱化上一个时间步的用户数字特征 Mt ,此处是元素积
t 时刻需要有选择的吸收用户数字特征,所以定义带注意力的用户数字特征Mto,用权重向量gto元素积和它做元素积,gto是将LSTMdec前一个时刻的状态,前一个时刻的输出,当前时刻的ctX拼接再映射,再sigmoid:
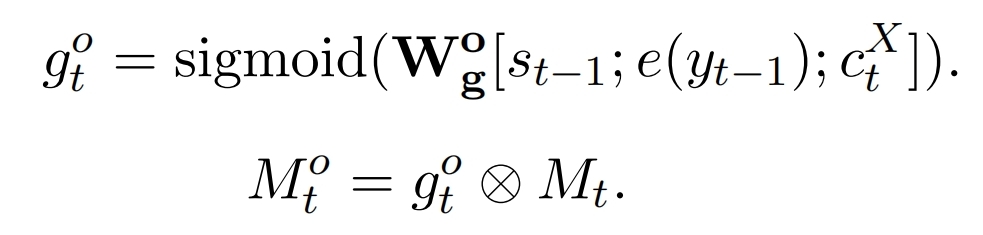
External Personality Expression:对LSTMdec的yt做进一步包装,强化了用户对评论的重要性(我感觉没必要多这个模块),当前时刻 t 的预测输出单词是:

模型的整体损失就是yt的交叉熵损失
2、给个标题,文章内容,生成不同主题(有多少主题是学出来的)对应的评论
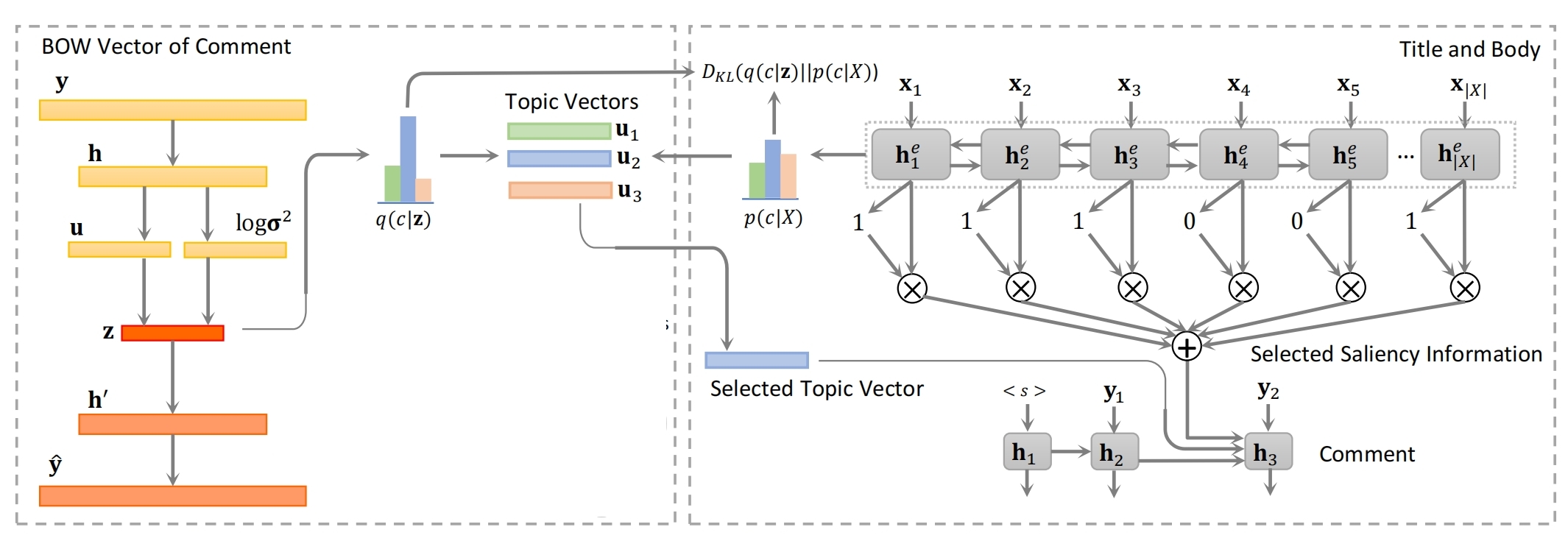
整体由 vae(左边)+注意力机制的 rnn(右边)构成
训练阶段:右边由 rnn 的解码器生成1个个的评论词,编码器的词 xi 的权重由两部分决定:门和注意力权重,门决定这个词的重要性(与标题相关性),通过把标题embedding和该词embedding拼接再映射来实现的。左边的vae主要作用是将评论映射为z向量,然后把z向量映射到不同主题,得到1个分布,左边的RNN编码器向量也映射到不同主题,利用KL散度将2个分布变一致,这样rnn编码器就知道一则新闻的所有评论可能涉及到哪些主题。
预测阶段:去掉VAE,由RNN编码器算出可能会涉及到哪些主题,然后分别用这些主题生成对应的评论。
3、Graph2text1
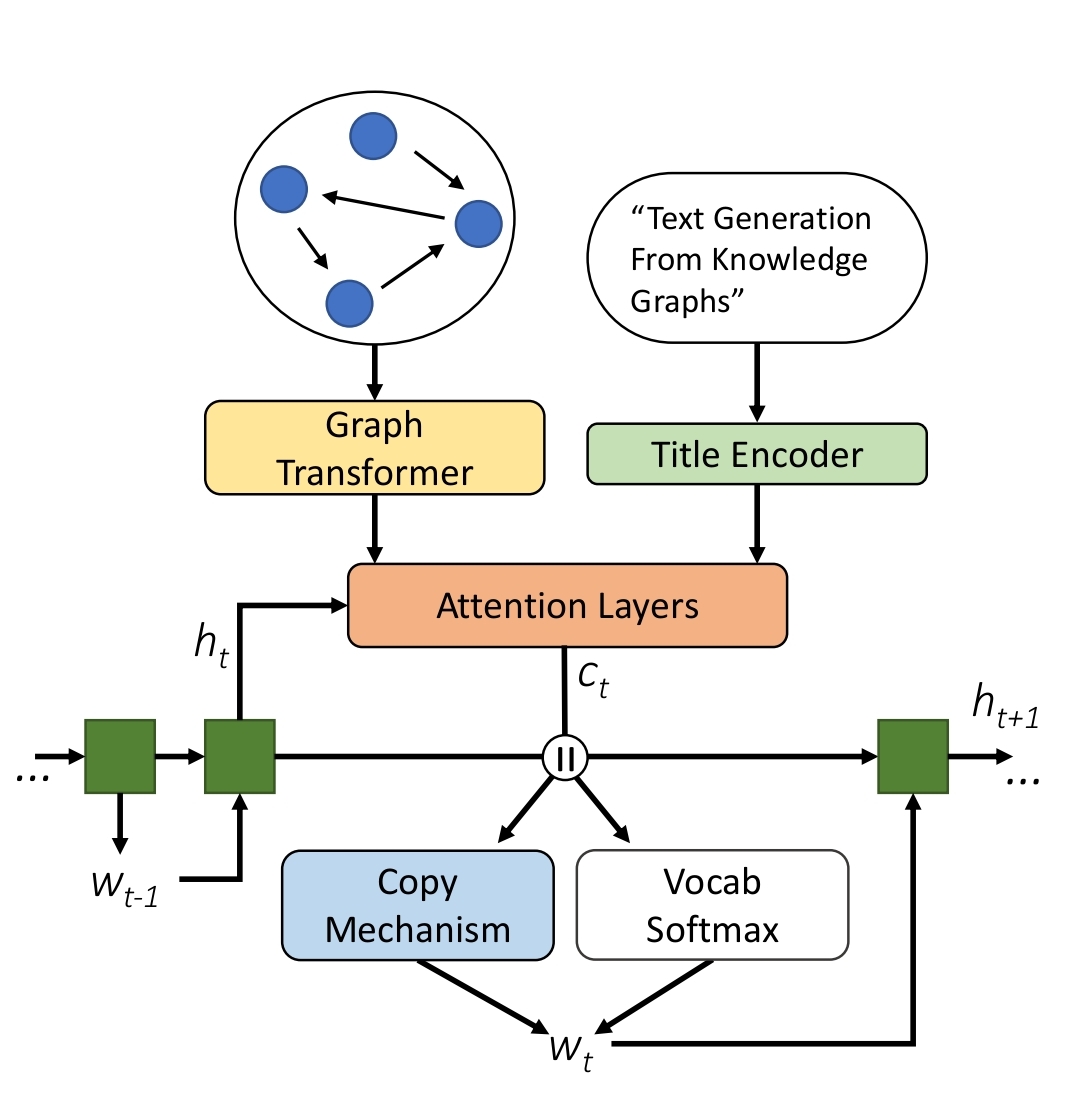
输入标题title和知识,输出文本,title是基于双向rnn编码得到标题向量(绿色),知识是将知识图谱(由实体关系对构成,如药物a-用于-疾病b)组织成图的形式,组织方式:
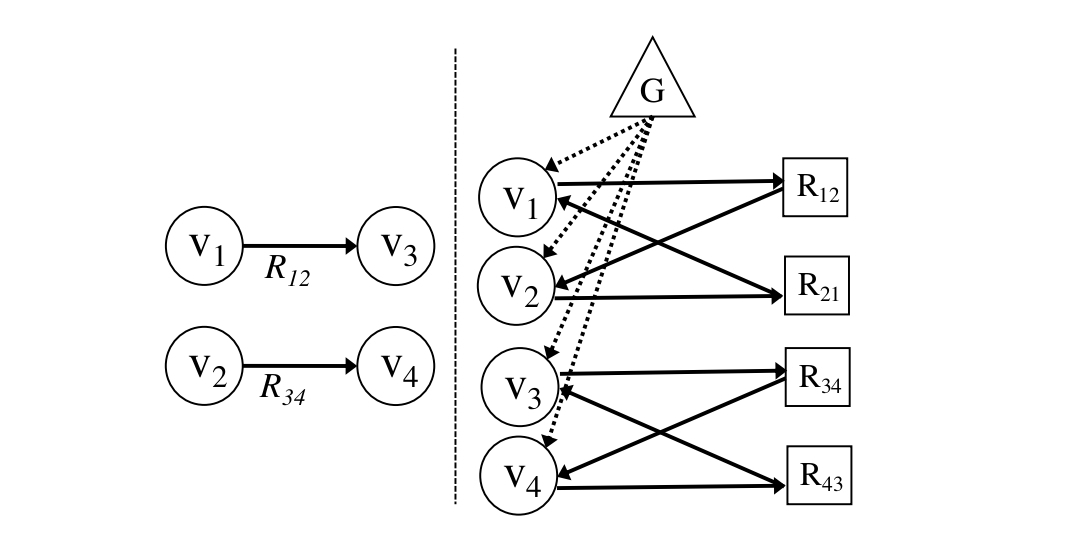
若节点v1有关系r12指向v2,则关系r12变成关系节点r12和逆向关系节点r21(比如used_for_inv),v1指向r12指向v2,v2指向r21指向v1。再新建1个全局节点指向所有的实体节点v1,v2…
节点向量v:节点短语单词们通过双向rnn,然后通过Graph Transformer,该结构中先由注意力机制聚合周围节点信息:

针对vi,与它相连的邻居节点先线性映射再按权相加,同时采用N个head机制来拼接向量,计算vi对vj的注意力权重a时,每个节点通过线性映射放大后再切割就有了自己的qkv向量,然后qi和kj的相关系数结果除以qi和所有邻居节点的相关系数和,然后通过ln和ffn:

解码器:单向rnn结构,用图的全局节点向量初始化,在生成第 t 步的词时,重点考虑了标题和知识,用ct和上一个隐状态输出ht来生成词,ct是知识向量cg和标题向量cs拼接而成的,cg是之前算好的图节点向量先映射再加权求和,再加ht的结果,依然基于多头机制:
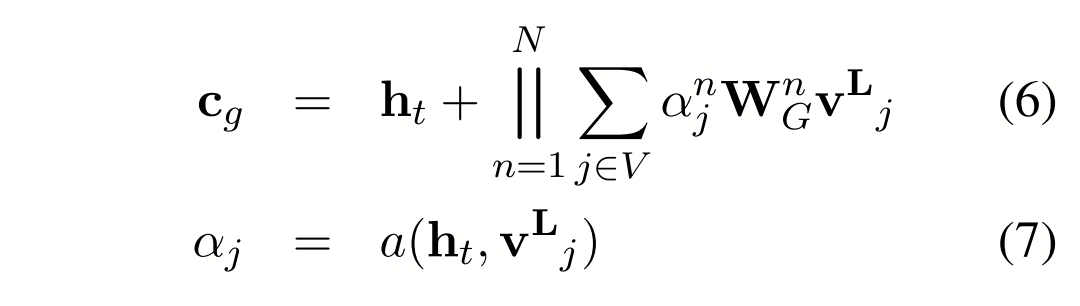
ct和cg的计算方式一样,只是把图节点向量换成了标题单词向量
词汇表的每个单词都有两个概率,最后按权相加得到最终概率,第一个概率是 ht拼ct 映射到字典长度+softmax,第二个概率是 :如果是知识或者标题单词,则概率是 a(ht 拼 ct,之前算好的词向量xj) ,如果是其他词,概率是 0。第1个概率的权重是 1-第2个权重,第2个概率的权重是 将 ht 拼 ct 映射+sigmoid,即:
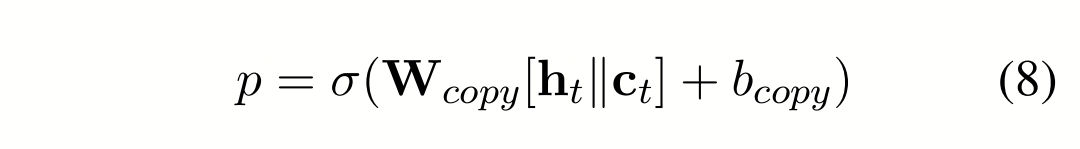
生成的词会继续把该词向量wt输给下个时间步的rnn
4、Graph2text2
输入由知识构成的KG,KG由实体和关系构成,再将KG转为图(与上面不同),由于实体有多个词,将实体拆分形成新的图G1,这个新图G1中,如果原来实体A指向实体B,则此时实体A的所有词分别指向B的所有词,1个词是1个节点,节点向量初始化为 token向量+该token在实体中的位置向量。进行L层的GNN迭代:比如第1层的节点v1,先通过v1的周围的0层节点向量以及边向量 通过聚合函数 算出v1的上下文向量,然后通过结合函数 将上下文向量和v1的第0层向量结合作为v1的第1层向量。
此处有2个GNN(Global Graph Encoder,Local Graph Encoder),分别用于计算节点的全局向量和局部向量。
Global Graph Encoder:针对节点v向量,采用Transformer + GAT结构:
先利用注意力机制算出上下文向量:所有节点向量先映射再按权相加,权重是v向量对于该向量的注意力权重:

再通过ln和ffn:
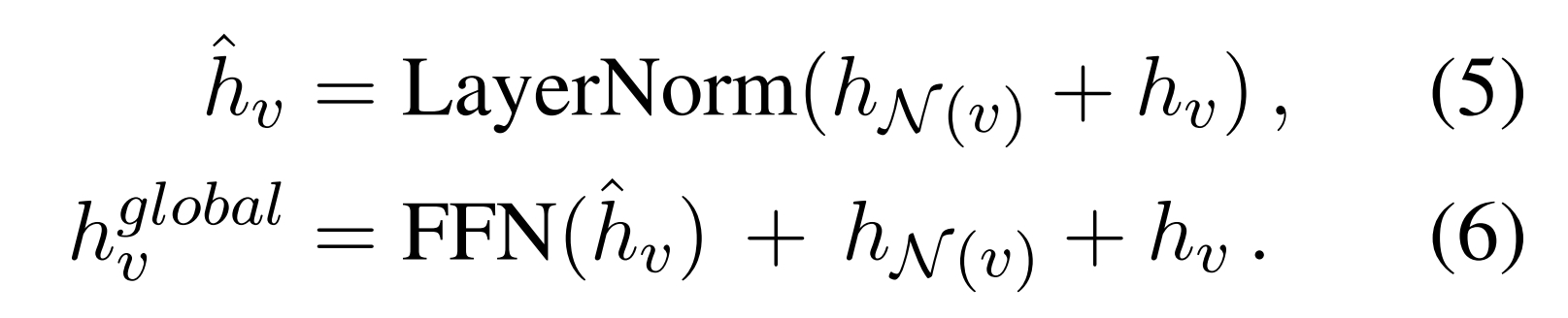
Local Graph Encoder:针对节点v向量,采用 改进的GAT结构:
先利用注意力机制计算局部上下文向量:与v相邻的所有节点和v先映射再按权相加,映射矩阵Wr是对两者关系边的编码,计算evu时,两个向量分别映射(通过W)再拼接再映射(通过a):

该上下文向量与原来的v向量再共同通过rnn:
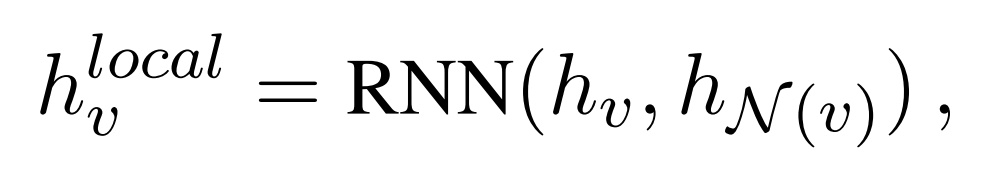
由于这2个GNN都是有多层的,需要将两者结合,作者提出了4个方案:PGE、CGE、PGE-LW、CGE-LW

PGE:
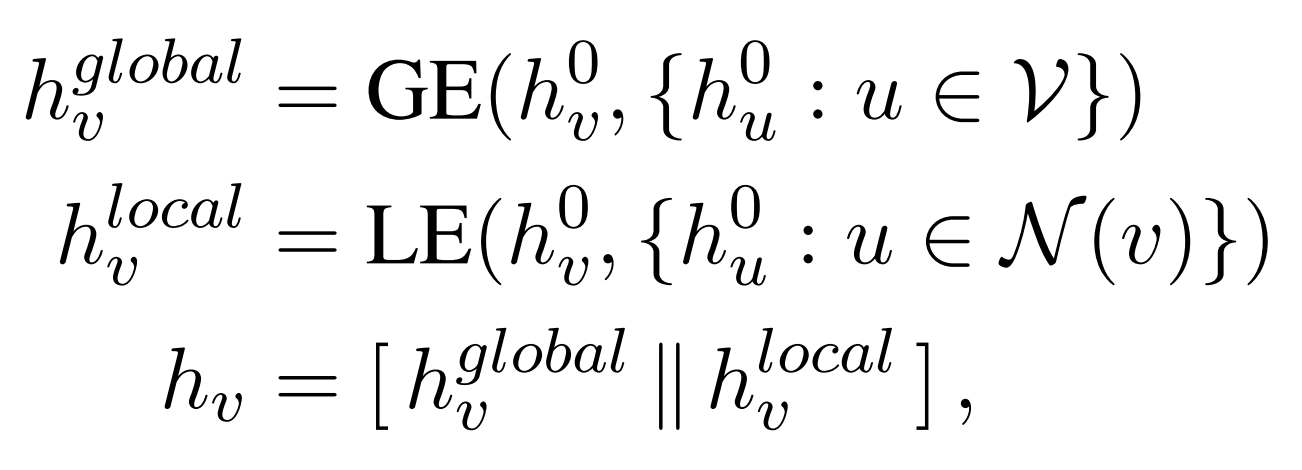
Global Graph Encoder 和 Local Graph Encoder 各自独立算,比如对于节点v,从初始向量到 Nx 层 的 Global Graph Encoder 得到最终全局向量,从初始向量到 Mx 层 的 Local Graph Encoder 得到最终局部向量,然后 最终全局向量 和 最终局部向量 拼接作为 v的最终向量
CGE:

先通过 Global Graph Encoder ,输出的全局向量作为 Local Graph Encoder 的初始向量
PGE-LW:
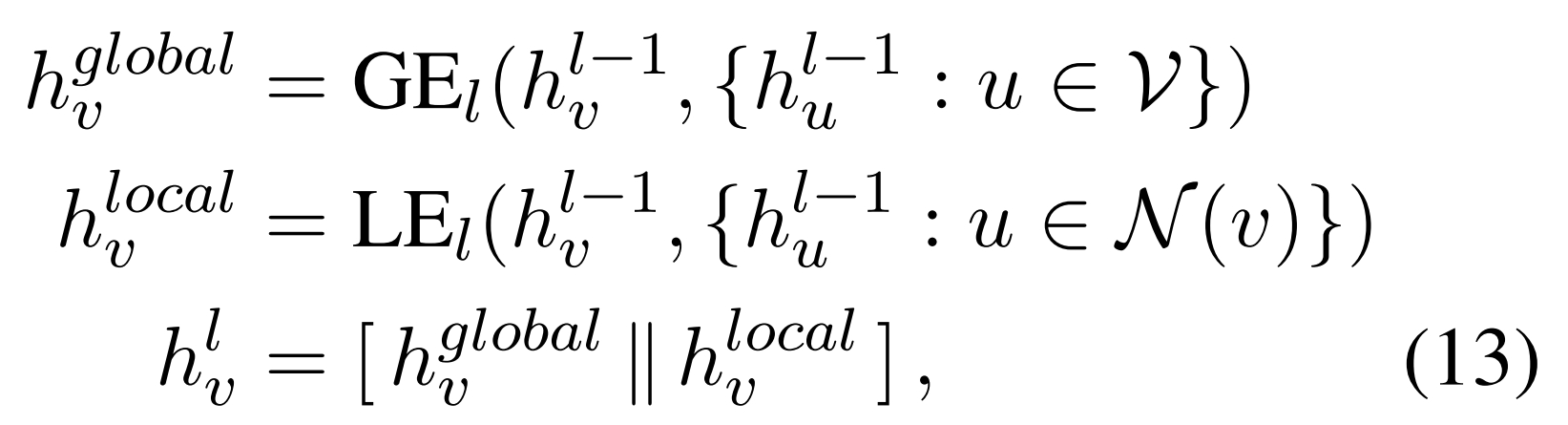
共Nx 层, 对于第 l 层,l-1层向量分别通过 Global Graph Encoder 的第 l 层 和 Local Graph Encoder 的第 l 层 然后拼接 作为第 l 层的向量
CGE-LW(效果最好):
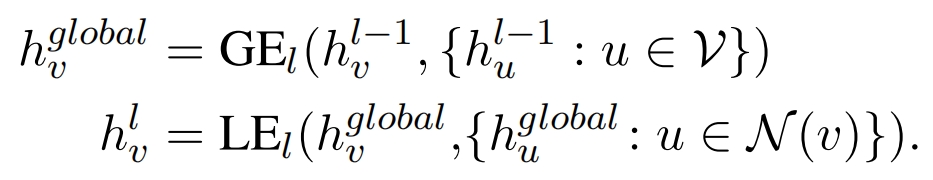
共Nx 层, 对于第 l 层,l-1层向量先通过 Global Graph Encoder 的第 l 层 得到第 l 层的全局向量,这个全局向量再输入到 Local Graph Encoder 的第 l 层 得到第 l 层的向量
基于Transformer decoder 进行解码,前面的所有图节点的向量映射一倍再切割成2份,作为节点自己的 k 和 v 向量,一个一个词输入到decoder中,算出来的k,v保留,对所有节点和 decoder 之前生成的 token 实现注意力机制,输出下一个 token 可能是什么。
5、title&body2comment
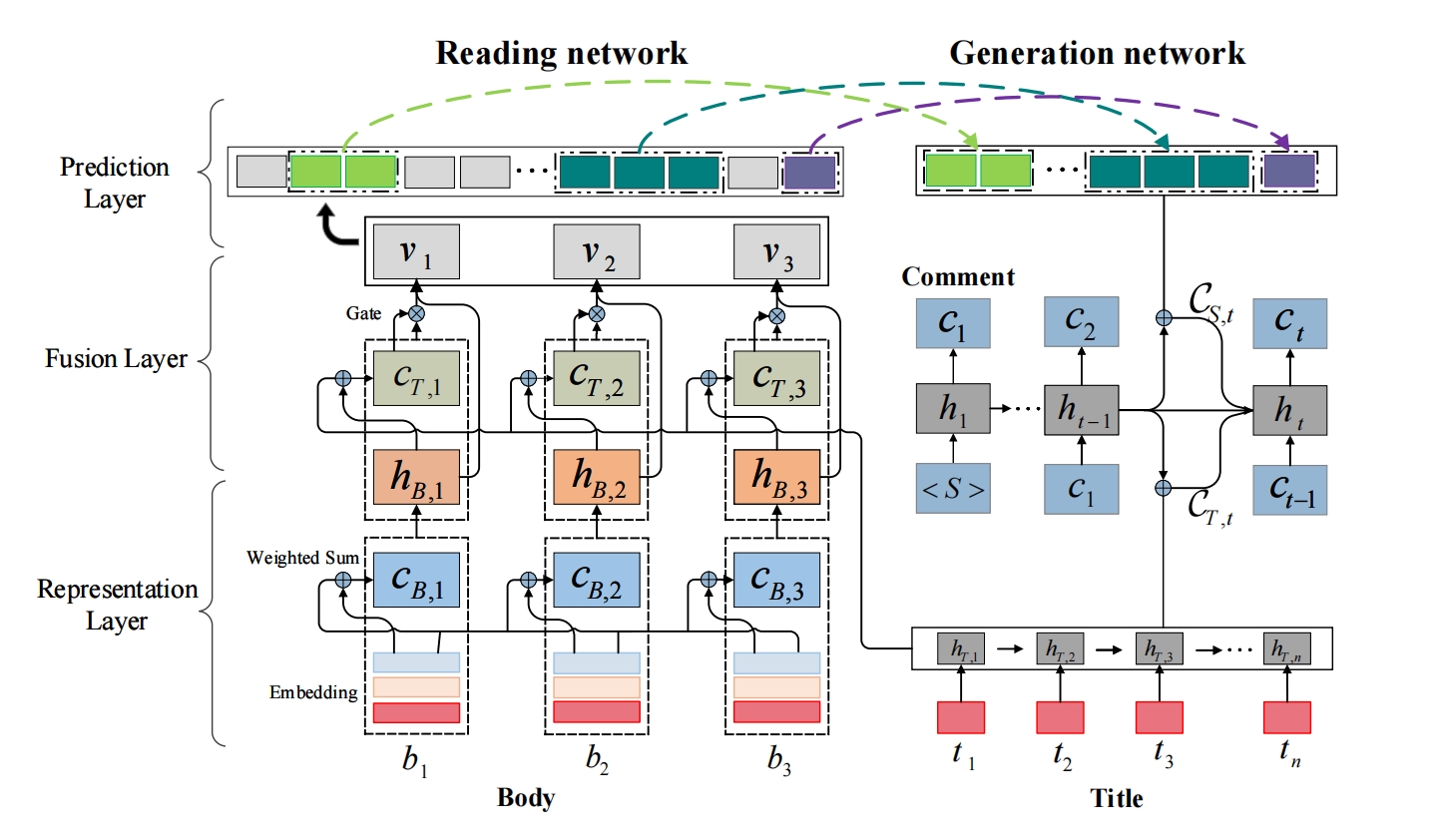
B是新闻体,第 k 个单词的向量由token向量、位置1向量、位置2向量 拼接再映射,位置1是该单词在所在句子中的位置,位置2是所在句子的开头在整个新闻体中的位置,最后形成e~B,k
T是标题,通过GRU生成每个标题单词的词向量
新闻体单词e~B,k 需要和所有加权后的新闻体单词向量cB,k 拼接再映射 得到hB,k,权重是e~B,k对新闻体单词的注意力系数:
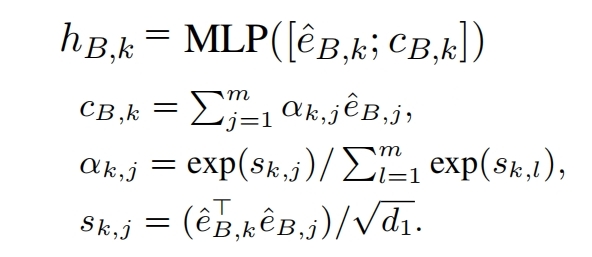
fusion layer将body和title融合,针对 Body 第k个单词向量,对标题所有单词向量按权求和,求和方式和前面公式一样,得到cT,k,再通过gate得到标题的重要信息,最后再相加:
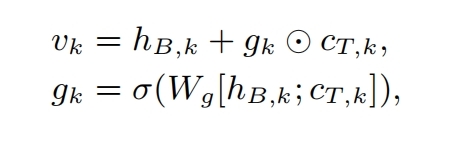
Body最后要输出一些重要的短语,每个单词先输出自己可以作为短语起始单词的概率(向量映射到1维度+sigmoid),设定1个阈值之后就知道哪些单词会作为起始单词了,如果第ak个单词能作为起始单词,就需要找它对应的尾部单词是谁,以便组成1个短语
和第j个单词组成短语的概率是αak,j,下面公式中,c0是所有v向量按权求和,权重是h0向量对齐的注意力系数:
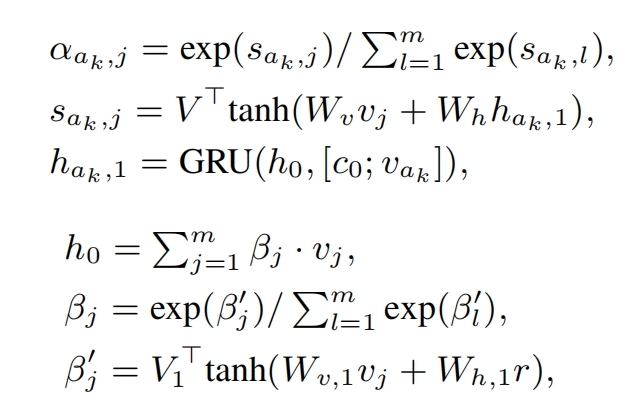
解码:基于GRU,在第t步输入第t-1步的隐向量ht-1,和另一个向量————t-1时刻预测的token向量 拼接 cT,t-1 拼接 cS,t-1 ,其中 cT,t-1:标题所有的单词向量加权求和,权重是标题ht-1 对单词的注意力系数,公式如前;cS,t-1:所有预测的重点短语的所有单词(比如短语1:hello world,短语2:big city,变为4个词汇hello world big city)的向量加权求和,权重是标题ht-1 对单词的注意力系数,公式如前
第t个词汇的预测:ht 拼接 cT,t 拼接 cS,t 再映射到词典+softmax
gru的初始状态h0是对所有短语的所有单词向量和标题的所有单词向量的加权求和,权重是一个可训练向量对其注意力系数,公式如前

 浙公网安备 33010602011771号
浙公网安备 33010602011771号