
GAN
【JS散度】
由于KL散度的不对称性问题使得在训练过程中可能存在一些问题,在KL散度基础上引入了JS散度,JS散度是对称的,其取值是 0 到 1 之间。如果两个分布 P,Q 离得很远,完全没有重叠的时候,那么JS散度值是一个常数( log2),此时梯度消失(为0)。JS散度越小,2个分布越相似
JS散度相似度衡量两个分布的指标,现有两个分布和
,其JS散度公式为:
原始的GAN损失可以用JS散度来表达(先训练判别器,再训练生成器):

原始GAN缺点也是JS的缺点:当两个分布不重叠时,JS为常量,会导致:当判别器最优时,此时JS是常量,导致生成器损失是常数,导致梯度消失,从而无法训练生成器,从而生成器学不到东西了。如果判别器训练得不好,生成器梯度不准,四处乱跑。只有判别器训练得不好不坏才行,但是这个火候又很难把握,所以GAN才那么难训练。
改进的生成器损失(上图右边项变为 :E[-log(D)])会产生 collapse mode 问题:生成器总是生成一些重复的样本,不去生成多样性的样本。
原始GAN缓冲方案:通过给2个分布加噪声使得两个分布能有重合,这样JS散度就能发挥作用了,但是无法提供衡量训练进程的数值指标。
【Wasserstein距离】
由P分布转换成Q分布所需要的最小代价,越小,分布越接近,数值>=0。Wasserstein距离 优越性在于: 即使两个分布没有任何重叠,也可以反应他们之间的距离,而JS散度无法做到。
wgan是基于Wasserstein距离,原理:先通过判别器 fw(=critic=D)学习两个分布的Wasserstein距离,即最大化下面公式使其逼近 Wasserstein距离,其中 fw 是个神经网络 且 fw 末尾不是sigmoid 且 fw 满足 Lipschitz连续条件(即 fw 的导数绝对值永远小于某个数,即 fw 的在任意位置都不会剧烈变动,通过weights clipping可以实现李普西斯条件条件,即所有参数w不超过某个范围[-c, c],即大于c的置为c,小于-c的置为-c):
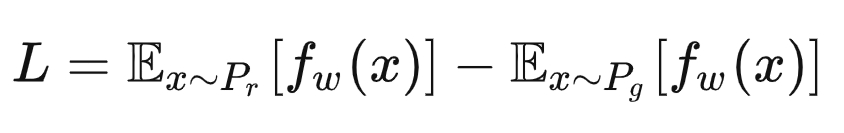
等价于判别器损失为 -L。然后再以最小化L(近似的 Wasserstein距离)为目标函数来训练生成器G,由于L第一项和生成器无关,等价于最小化第二项,即生成器损失为:

【WGAN-GP】
最终效果:生成器生成出更像数据集的样本
仅仅把 WGAN 中的weights clipping 变换为:在判别器损失(-L)后面加一个梯度乘法项(GP,gradient penalty)也能实现Lipschitz连续条件,具体实现就是:
现在真实样本x和生成样本x~中取一个之间的值x^,然后判别器对x^的梯度的模长-1 再取平方作为GP项,加到原来的D损失(-L)后面:
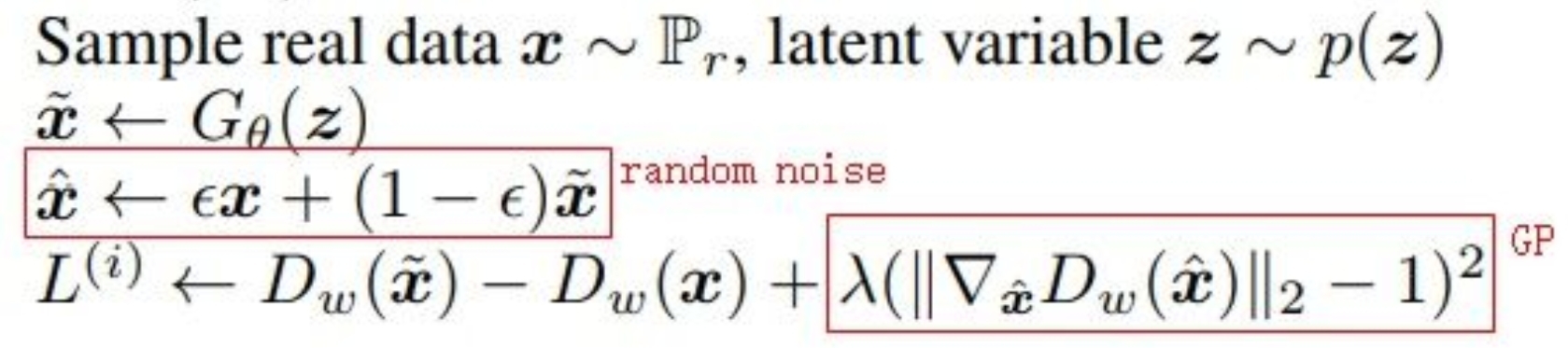
【stylegan1】
判别器,输入 3*8*8 的图片:
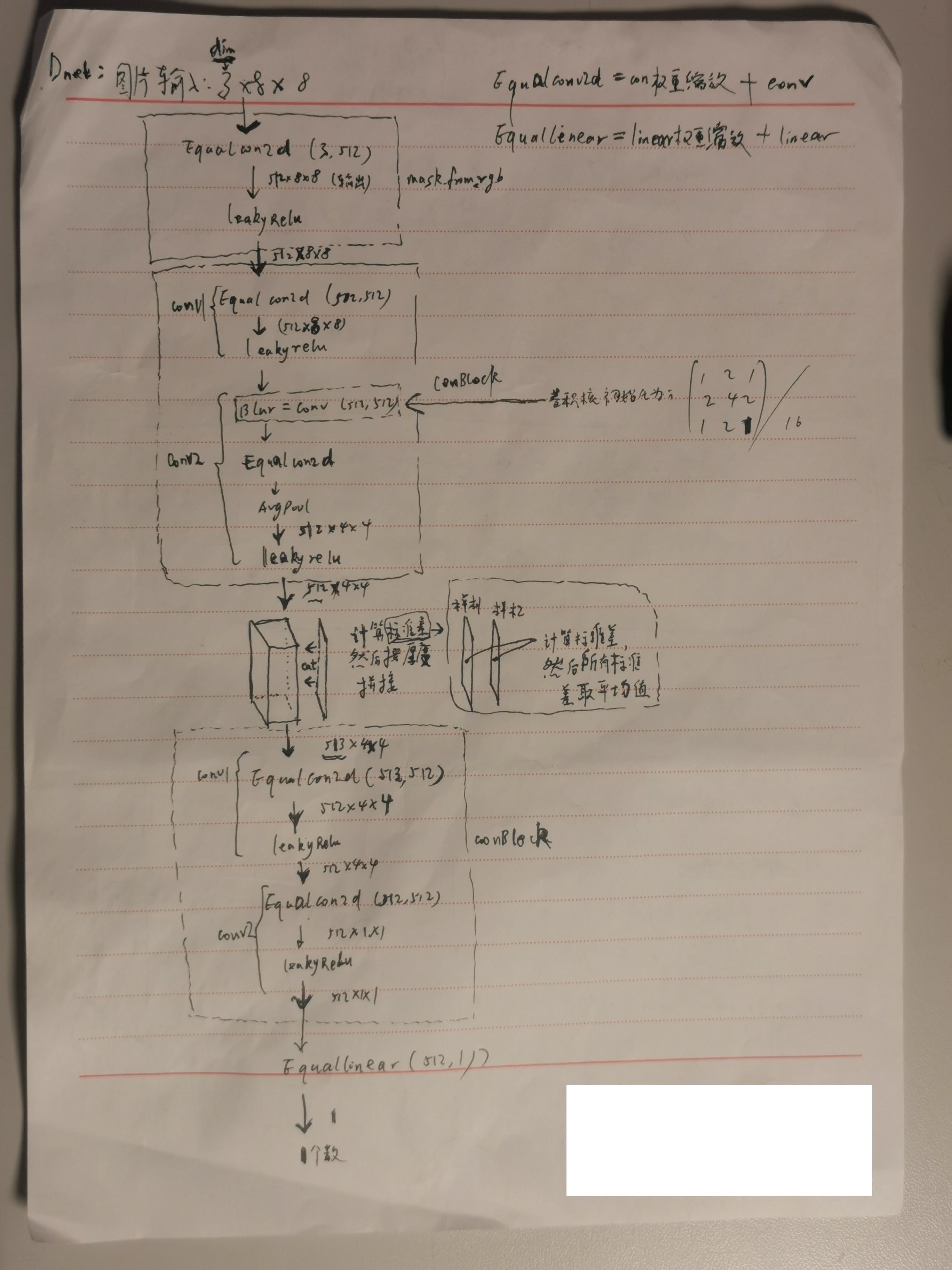
判别器损失:设输入的第 1 张图片x~来自判别器,第 2 张图片x 是真实图片,随机产生ε生成x^,计算D对于x^的梯度,带入【WGAN-GP】中的损失,先训练判别器 n_critic 次,再去训练生成器
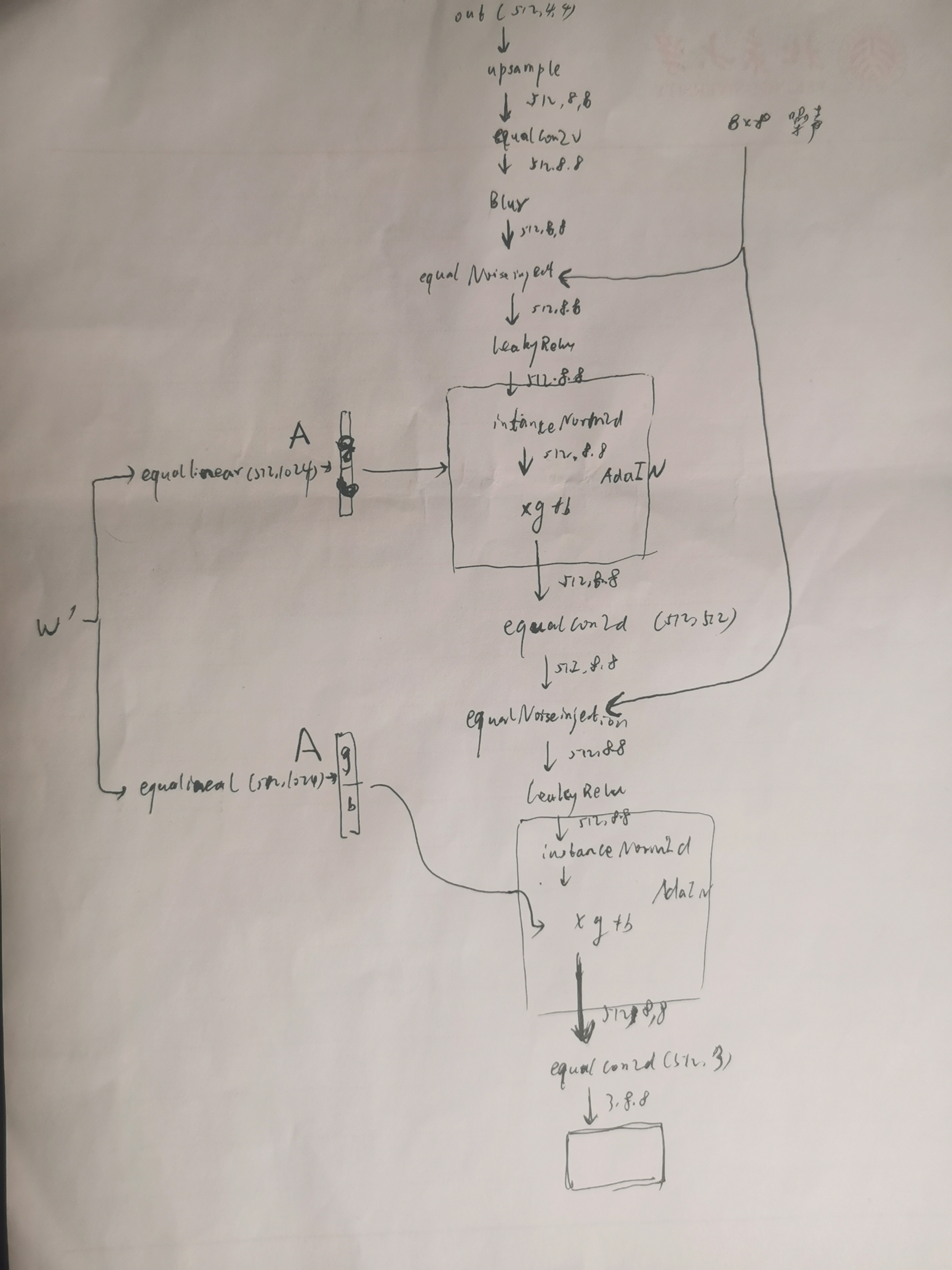
生成器:
将1个随机向量输入 Mapping network ,Mapping network 的作用是对人物特征解耦,将输入的512维度的随机向量映射到512维度的向量w,此时w的每个维度被赋予了人物特征的意义。w输给右边网络,假设右边网络有2块,第一块用于生成低分辨率特征(姿态、脸型、配件等style),第二块用于生成高分辨率特征(肤色、头发颜色、背景色等细节style),噪音用于生成一些随机的细节特征(雀斑、发髻线的准确位置、皱纹)以使图像更逼真。w通过 A 对于每个块的 style 进行控制。
样式混合:先后分别将2个随机向量通过Mapping network得到w,w' ,以实现将2个图片(1个随机向量代表1个照片)做合成,其中第一个w通过它自己的A控制第一块,第二个w' 通过它自己的A控制第二块。

每个块(阶段)都会受两个控制向量(A )对其施加影响,其中一个控制向量在 Upsample之后对其影响一次,另外一个控制向量在 Convolution 之后对其影响一次,影响的方式都采用 AdaIN (自适应实例归一化)。Adain 这种影响方式能够实现样式控制,主要是因为它让 𝑊 影响图片的全局信息(注意标准化抹去了对图片局部信息的可见性),而保留生成人脸的关键信息由上采样层和卷积层来决定, 因此 𝑊 只能够影响到图片的样式信息。
第一块:
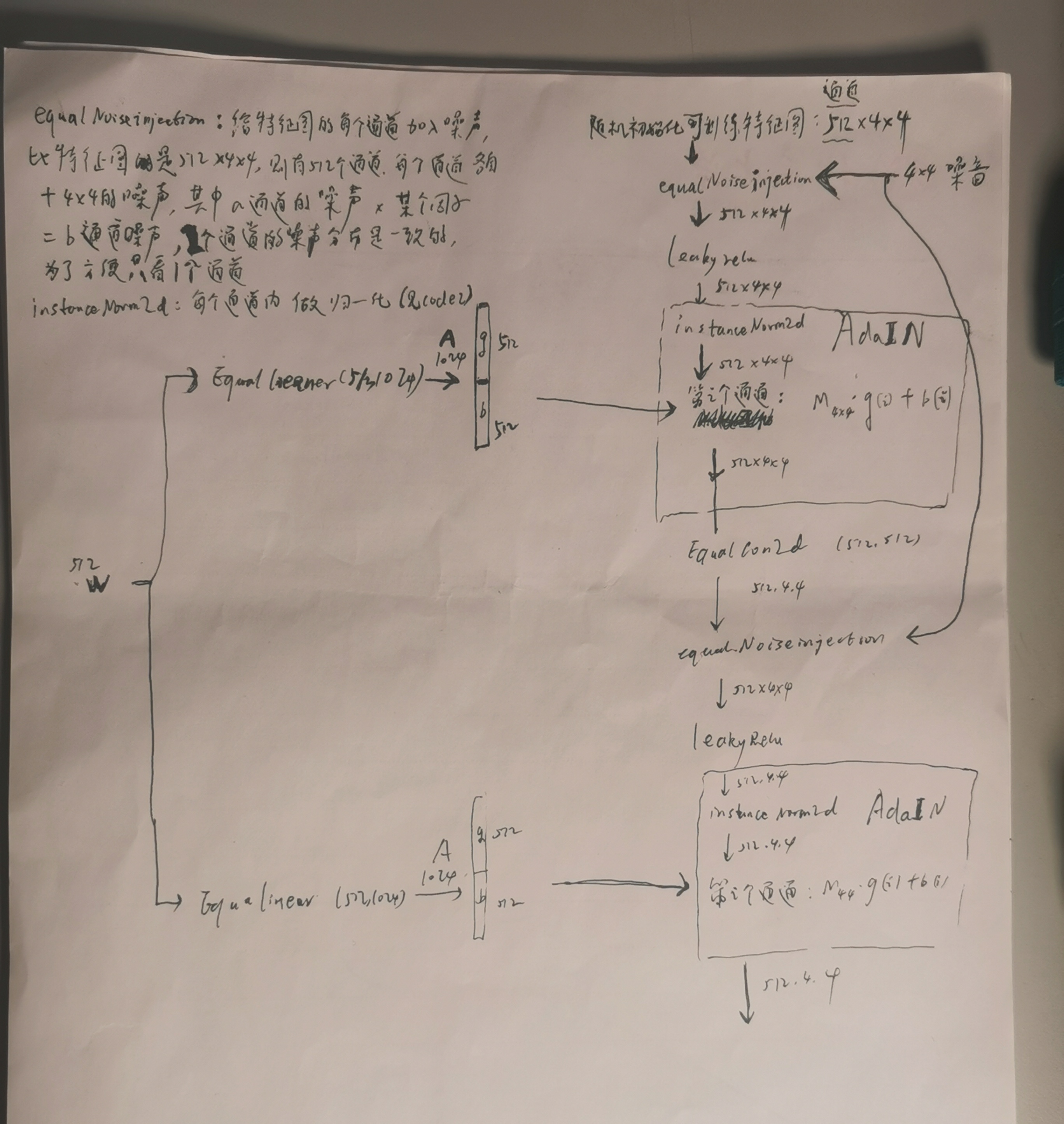
第二块:
生成器损失:- D(G(z))
模型参数更新采用ema方法以消除偶然变动因素,即当得到下一次要更新的模型参数值时,还要考虑到原来的模型参数值,再得到最终的(假设迭代1次)模型参数值,公式:
newvalue = decay * oldvalue + (1-decay) * nowvalue,decay通常设置为0.999,越大的话模型参数更新越稳定(越靠近旧值)
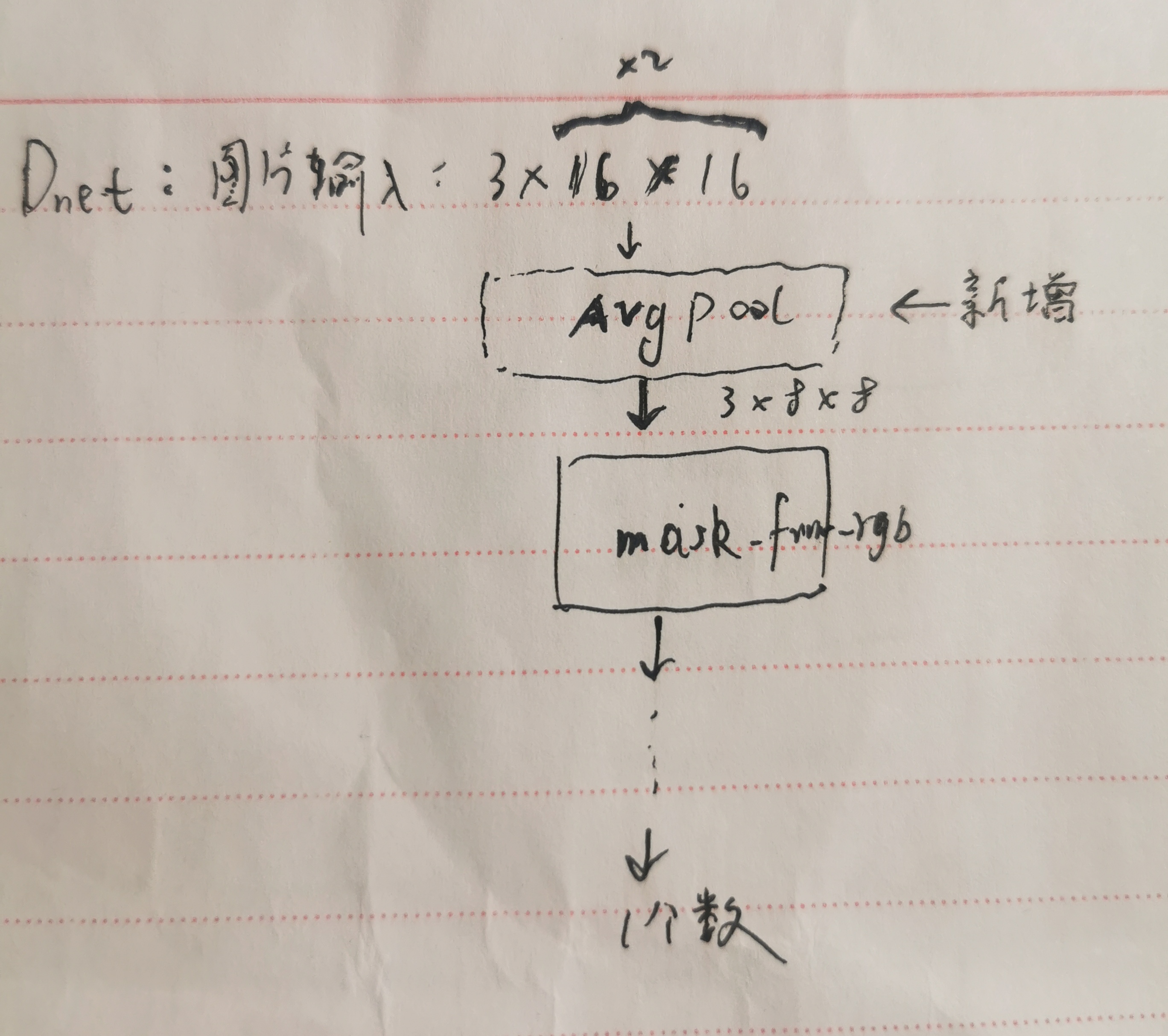
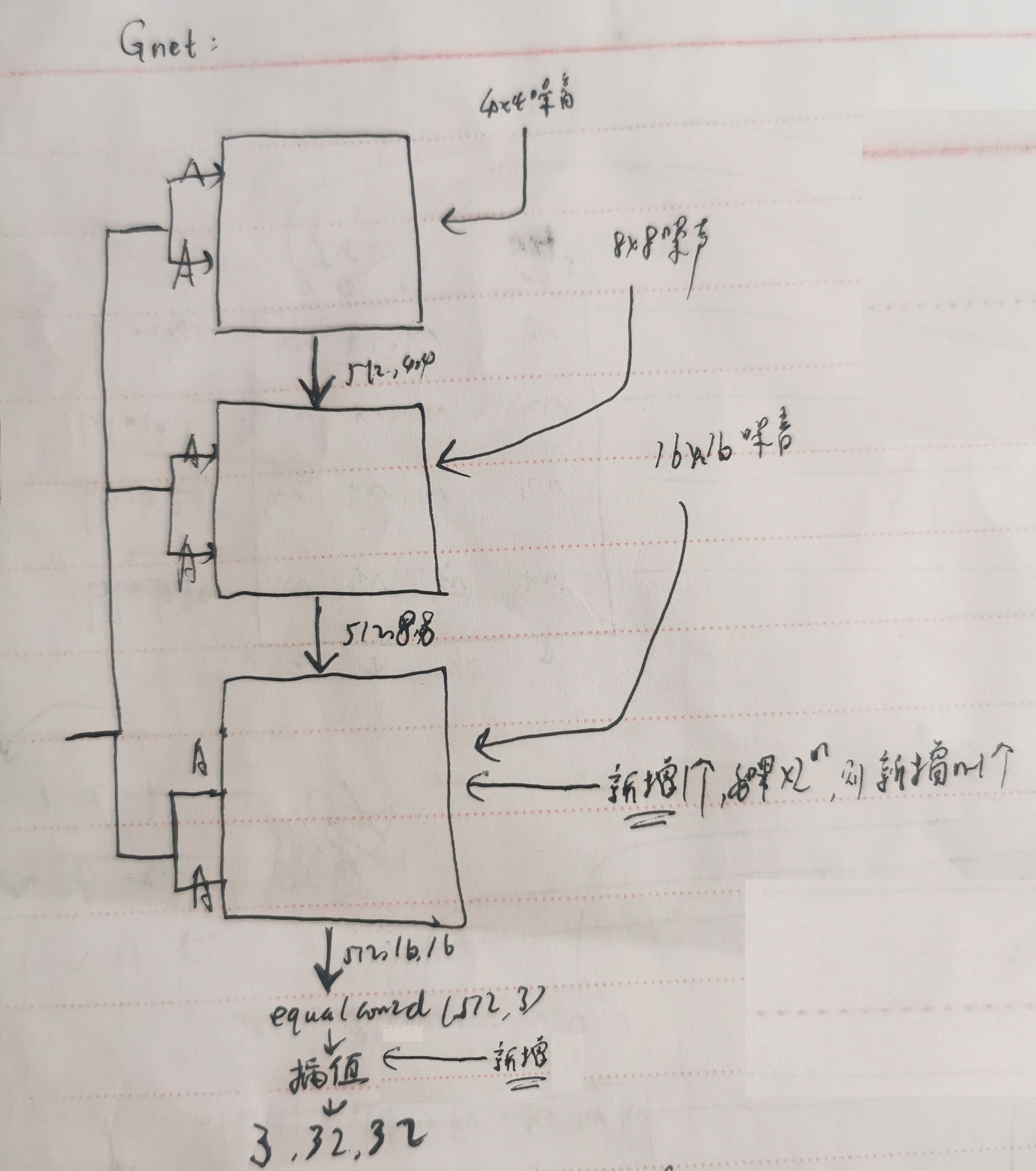
注意:随着输入图片的w,h的变化,g和D的网络结构会动态变化:
如果输入的图片是 3*16*16的(图片的w,h从 8 扩大2倍),则D最前面新增avgpool层,其他不变:
如果输入的图片是 3*32*32的(图片的w,h扩大4倍),则D:

如果输入的图片是 3*16*16的(图片的w,h从 8 扩大2倍),则G的synthesis net 的最尾巴的 equalcon2d(512,3) 后面新增线性差值层(w,h放大2倍),其他不变,输出 3*16*16(原样的图片大小)
如果输入的图片是 3*32*32的(图片的w,h扩大4倍),则G的synthesis net 的最尾巴的 equalcon2d(512,3) 后面新增线性差值层(w,h放大2倍),synthesis 还要新增1块,输出 3*32*32(原样的图片大小),具体的G:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号