
m15
一阶段模型(yolo系列)
【yolo1】
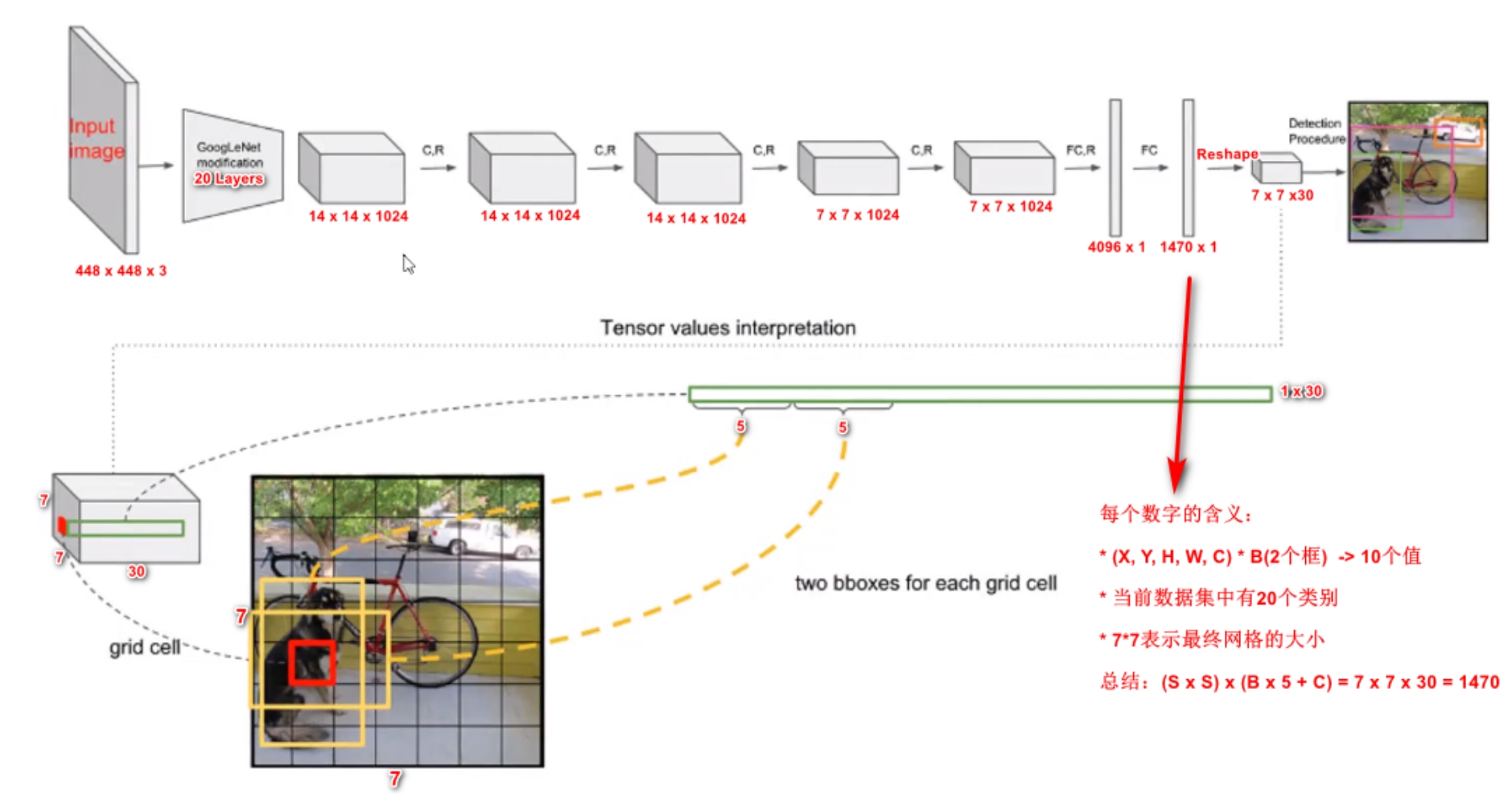
1、图像归一化为448x448x3,先通过Googlenet:
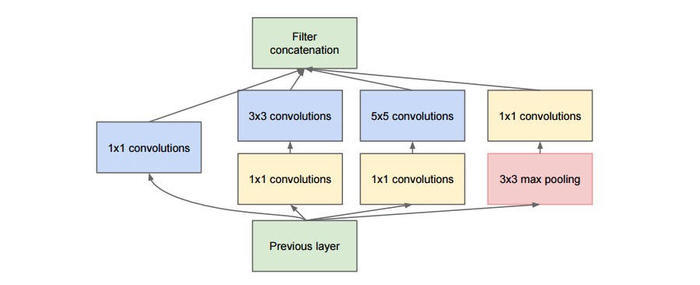
inception(也称GoogLeNet)是2014年提出的,由多个下图的 inception模块串联,感觉是spp的前身,1*1卷积可以视为对单个像素的全连接运算,提升了非线性能力,多个分支用多个不同大小的卷积核能在多个尺度上同时进行卷积,然后拼接提取到不同尺度的特征,特征更为丰富,注意卷积核在移动卷积的时候卷积参数不动(权值共享),一开始核参数随机初始化,之后就有反向传播进行更新了。新增1个池化分支是采用与卷积不同的特征提取方式,更多角度提取特征。
然后通过一堆卷积+全连接层,生成7x7x30的特征图:
7x7是把原图(448x448)划分为7x7的网格,30是一个网格对应1个30维度的向量,针对一个格子(1x1x30的向量)而言
产生2个长宽比不同的anchor,面积一样,中心是格子中心
每个 anchor 有5个数值(位置变换的值,是否检测到物体的置信度),2个anchor共10个值,如果物体的中心(GT的中心点)落在该网格内(yolo1假设网格内最多有1个物体中心),则该物体分别属于20个具体类别的概率
所以总共是5+5+20=30,即向量厚度
训练时:
anchor的置信度标签为:

若有个物体中心落到该网格里了,第一项为1,第二项为落进来的GT与该anchor的 IOU 值,所以若有物体,则置信度标签=iou(注意不是1),若没物体,置信度标签为0,2个anchor中与GT 的IOU最大的anchor独家的负责该物体(不管具体什么类别,1个GT只有1个anchor负责)
损失函数为
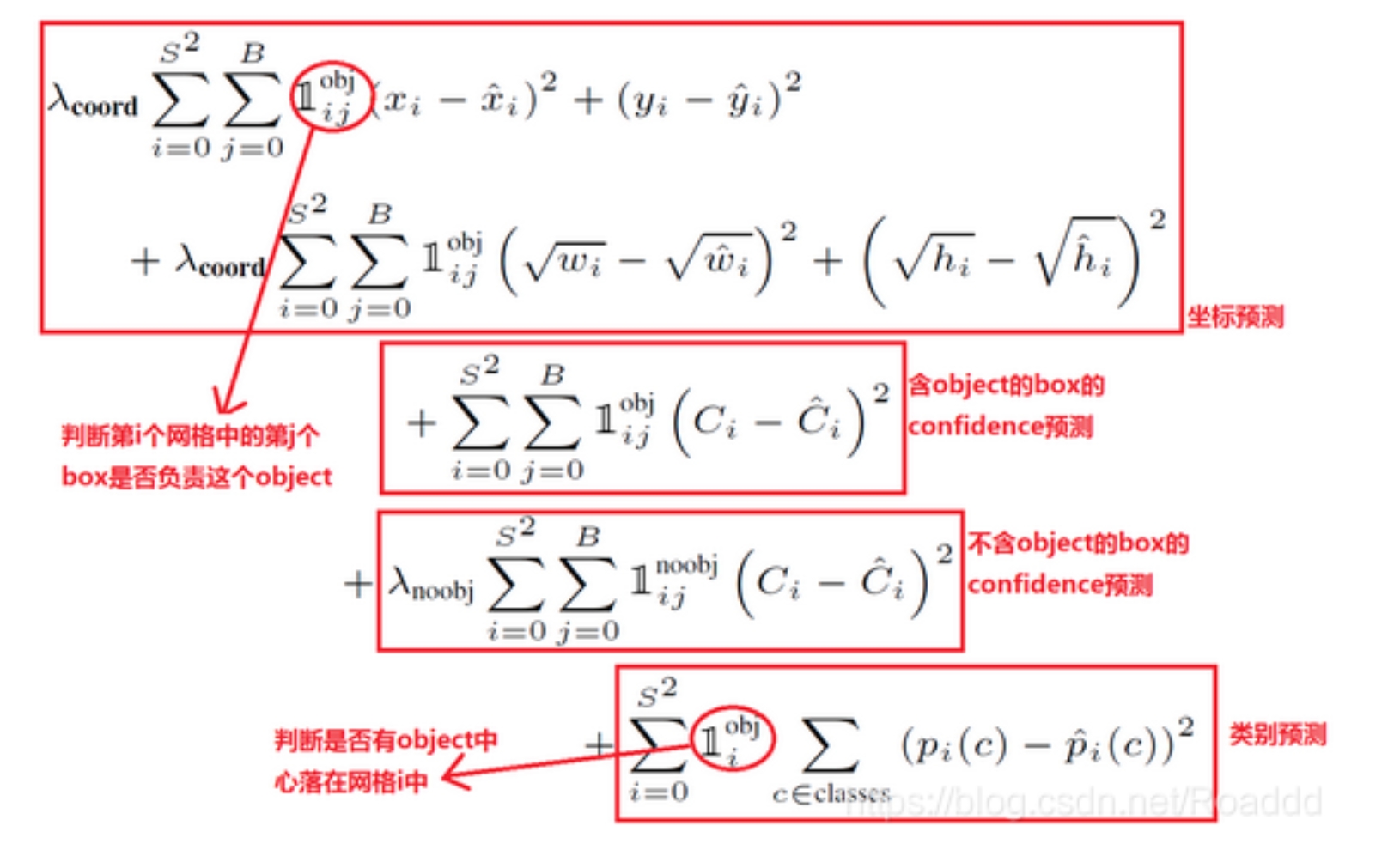
其中两个求和表示遍历所有网格的所有anchor,前两个损失是针对独家负责GT的回归损失(负责的系数是1,不负责的系数是0),回归损失中给宽度高度加根号是使得对小物体的检测更重视
第3个损失针对独家负责GT的置信度损失,第4个损失针对不负责GT的置信度损失,第5个损失针对网格里有落入物体的具体类别损失
2、测试
计算每个anchor的class-special confidence score:该anchor 的confidence x 所在网格的最大具体类别概率,并定义该anchor检测到的物体(yolo1假设就1个物体)就属于最大具体类别,设置一个阈值,去掉得分低的anchor,再进行NMS
FLOPs :floating point operations,模型需要的浮点计算量,用来衡量模型的复杂度,越大越复杂
【yolo2】
设定聚类的 k 为5,最终得到 5 个GT框,就得到了 5 个长宽,此时每个格生成5个anchor,anchor 中心的格子的中心,anchor 长宽是这个5个长宽
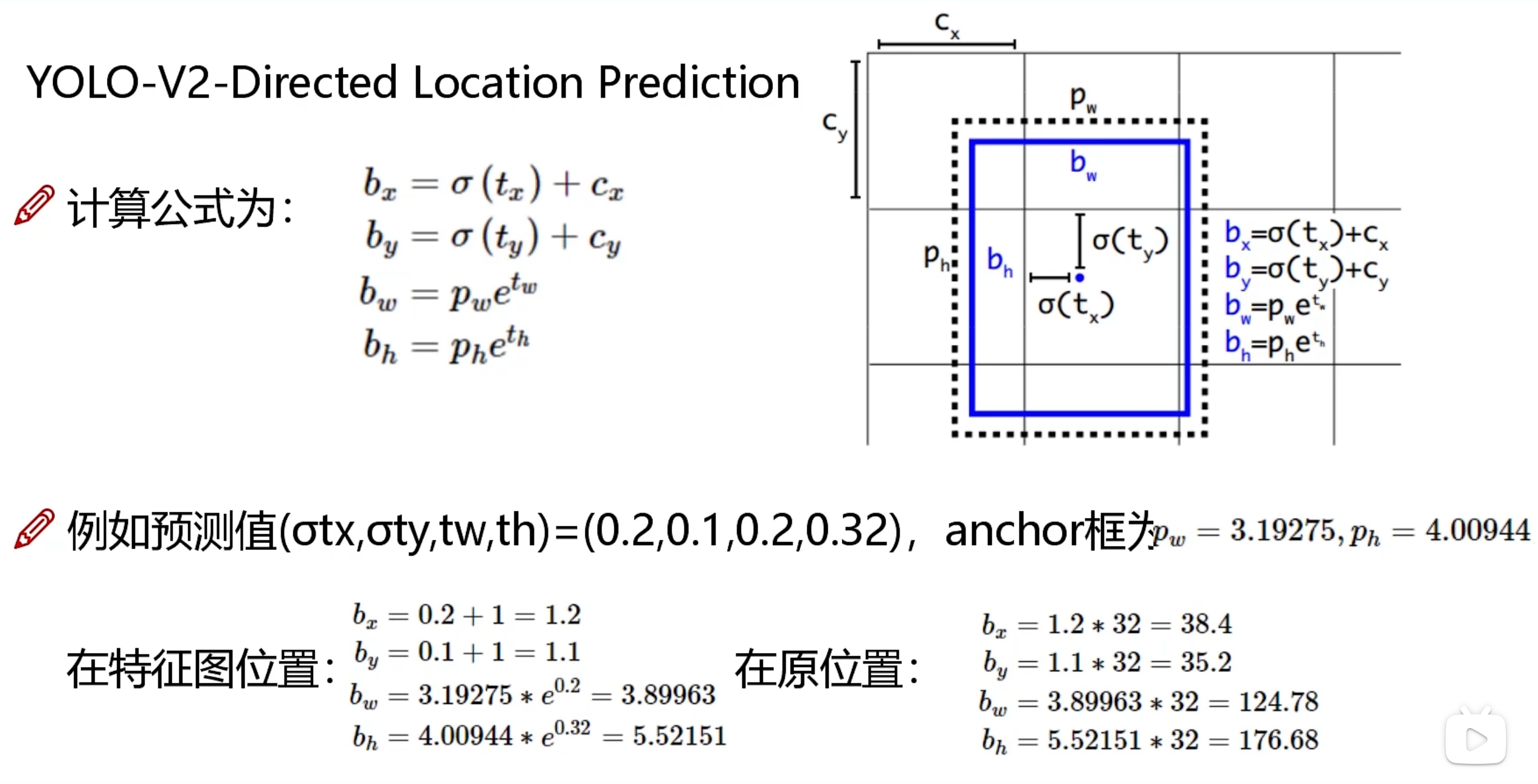
8、为了使得预测的位置变换值不至于变的太远(训练初期容易变的离谱),把变换的anchor中心点,只局限于格子里面,位置变换公式做了修正:
先把GT框映射到特征图上作为蓝色框,GTx=GTx/32,GTy=GTy/32,GTw=GTw/32,GTh=GTh/32
黑色虚线框是预测的anchor(特征图的尺度),cx,cy是从左上角开始第几个格子了,x和y的预测值还要再经过 sigmoid,才能作为x和y方向的位置变换预测值,标签是GTx-cx,GTy-cy
w和h的标签=log(GTw/pw),log(GTh/ph)
9、将大感受野和小感受野进行的特征融合
将前面的特征图拆成长宽都是13的几条,然后把这几条和最后的13x13x1024的拼在一起
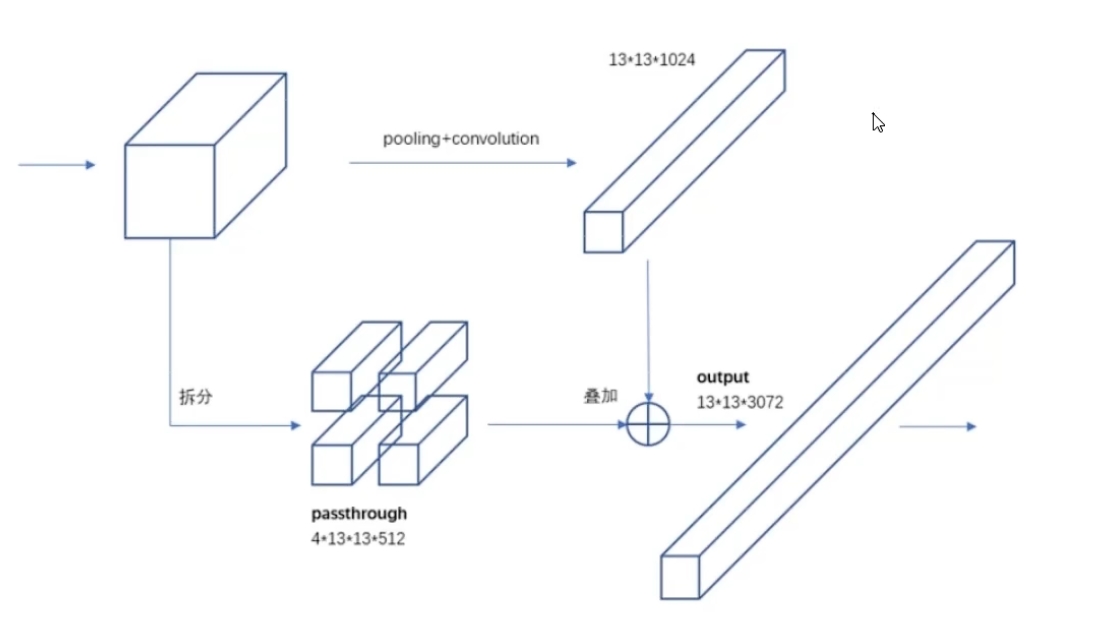
10、多尺度训练,使得模型学会适应不同的尺度:对于新数据集,每过一定的迭代次数,就 resize 成不同的大小{320...416...608},由于没有全连接层,输入大小可以不固定
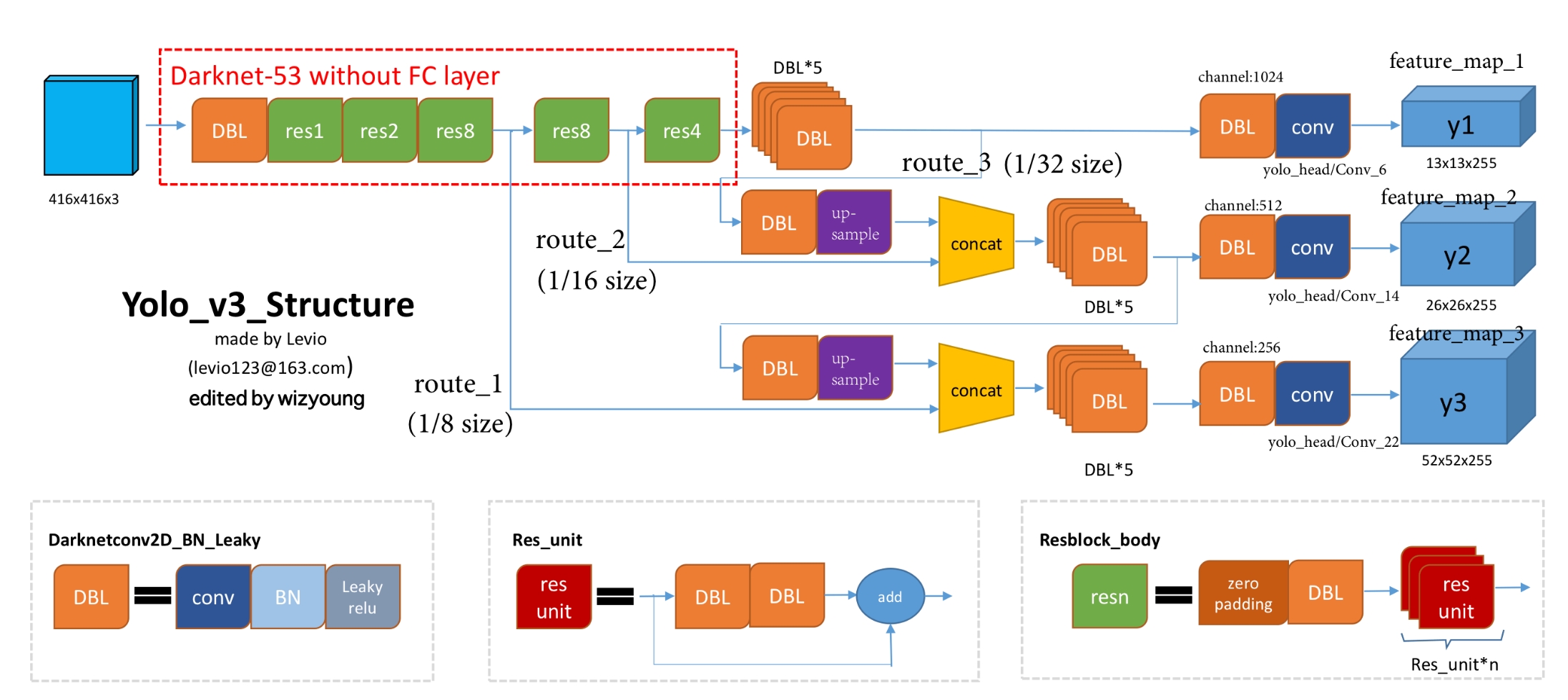
1、输入416x416大小的图片
2、Darknet53 去掉池化、全连接,采用卷积+残差模块,下采样用 stride=2 实现,分别得到原图像1/8(大小:52×52)、1/16(大小:16×26)、1/32(大小:13x13)的特征图
最上面的分支输出:13×13×255特征图,同时特征融合:给一个分支进行上采样,下中间的分支拼接,这是为了把一些全局信息传给下面的...
最后三个分支分别输出13×13×255(Y1)、26×26×255(Y2)、52×52×255(Y3)的特征图
3、生成 anchor
对 GT 聚类,k=9,最后按照面积大小降序排练,最大的三个框放缩到 13x13 的特征图上后的长宽作为每个像素的anchor长宽,以像素格子中心作为anchor的中心,按照3个长宽生成三个anchor,此时特征图上每个格子就有 3个anchor(或者直接定义好anchor长宽,不聚类了)
13x13x255的255 = 3个anchor x (5+80),即每个anchor有85维度向量
训练时,GT在3个特征图提供的所有anchor中找到离自己IOU最大的anchor,该 anchor 负责该GT,anchor向量的前4维度的标签是该anchor与GT的位置偏移值,计算一个MSE损失loss1
该anchor向量的第5维值的标签 = 1* 该anchor与该GT的IOU值,计算一个MSE损失作为loss2,该anchor向量的最后80维度的值表示检测到的物体属于80个类别概率,实现的是多标签的分类,这个概率不是用softmax算的,而是对每个类单独用sigmoid算的,如果GT标的类是:{狗,斑点狗},则标签则是{0,0,1,0,1},2个对应地方的 -log 加起来作为loss3(基于交叉熵)
对于没有负责GT的 anchor,意味着检测到的是背景,只计算第5维度的损失,第5维度的标签是0,损失就是 -log(1-预测值),作为 loss4(基于交叉熵)
总loss就是=loss1+loss2+loss3+loss4
4、预测
把每个anchor第5维度的值降序排列,去掉值小的,剩下的按照前四维度做位置修正,然后根据80个类别预测值,设置一个阈值,有多少类别预测值比阈值大,就预测该物体同时具有这几个类别,最后NMS
【yolov5】
yolov5 和下图的 yolov4 结构差不多
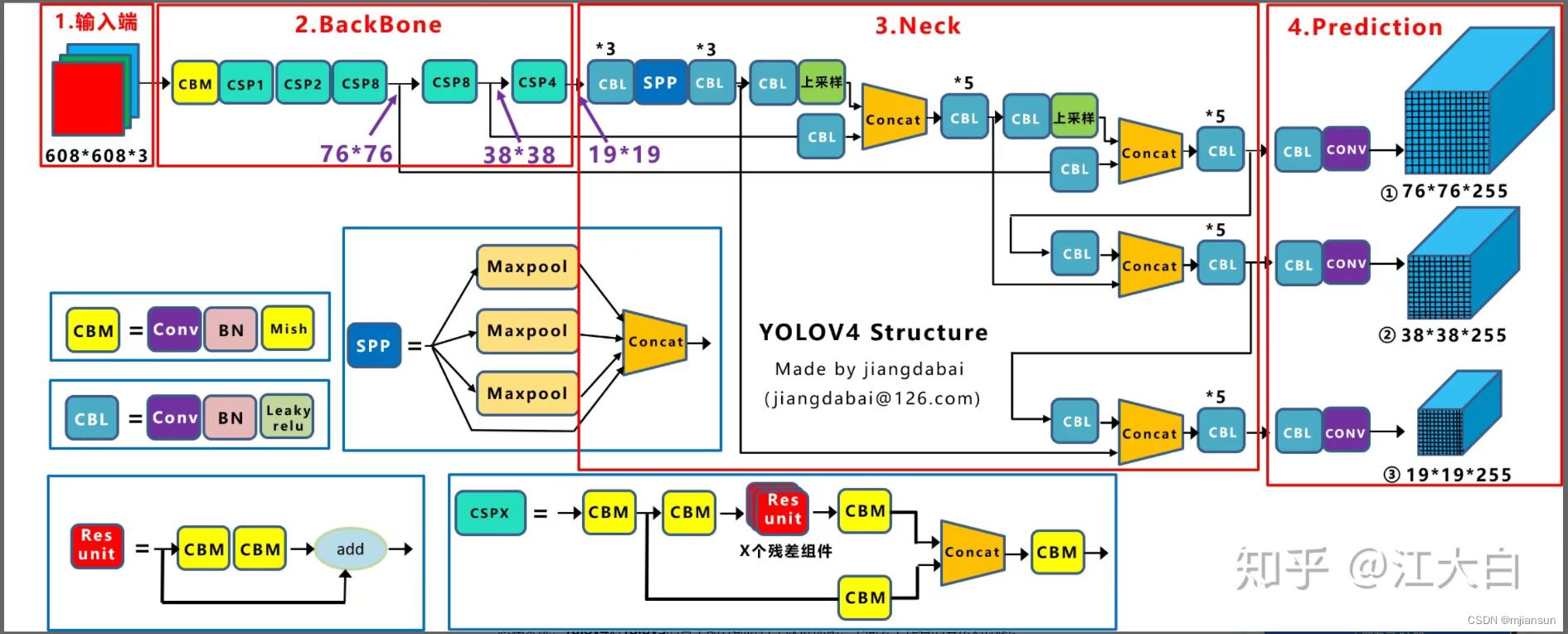
改进的点:
1、输入端
Mosaic数据增强:假定图像输入大小是640*640*3,随便选3张图片和当前图片组成4张小图,小图都进行放缩,在1280*1280的大图中心点附近随便取一点做中心点,然后把4个小图凑到中心点处,重新调整小图的标签检测框的位置,超出边界的检测框让它边界置零,对大图和它的标签随机旋转、平移、缩放、裁剪,最后再放缩回 640*640*3,新图就有了很多小目标,因此大大丰富了小目标的数据集,让网络的鲁棒性更好
SAT数据增强:给图像添加随机噪声
dropblock :使用一个矩形随机遮住图像的一块(数据增强的作用)以及后续的所有特征图上(正则化作用,因为在全连接层上效果很好的Dropout在卷积层上效果并不好,卷积层仍然可以从相邻的激活单元学习到相同的信息。)
2、网络结构
以yolov5n为例,分为 backbone 和 head,head 类似于 yolov4 的head + prediction,它们主要由下面的模块组成
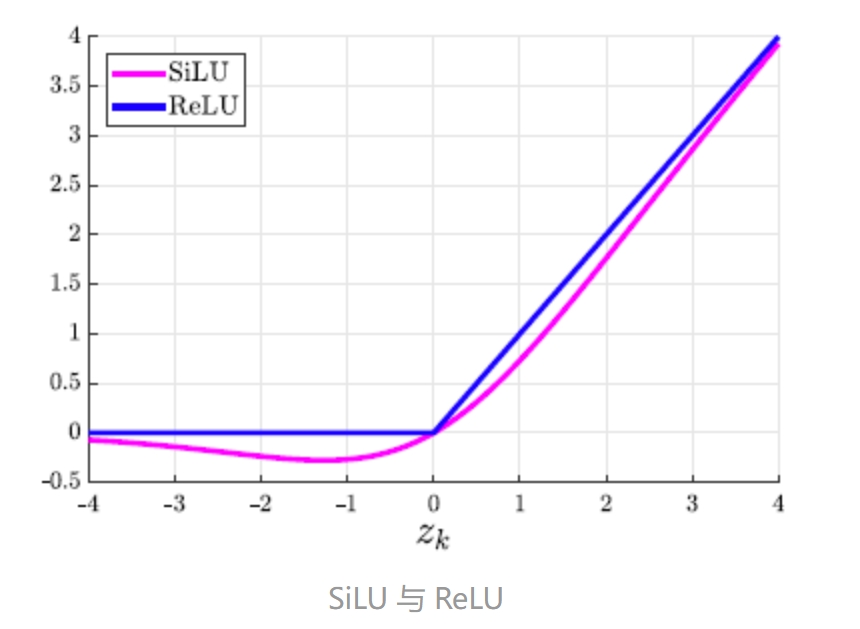
cbl:类似于yolov4的CBM,卷积+bn+SILU激活函数,SiLU 的一个吸引人的特点是它具有自稳定特性:
Bottleneck:是一个残差模块,输入经过2个cbl,再加上输入
C3:类似于yolov4的CSP,上面通过 cbl+n 个 Bottleneck,下面通过1个cbl,两者通过Concate合并,最后再通过 1个cbl
SPPF:类似于yolov4的SPP(不管输入尺寸是怎样,SPP 可以产生固定大小的输出),先通过cbl,然后并行4个最大池化(未池化,池化1次,池化2次,池化3次),四者通过Concate合并,最后再通过 1个cbl,目的是分离不同的感受野。
上下采样操作:为了特征图融合
Focus:将输入进行划分,使得长宽变小,厚度边大,然后通过一个卷积层,目的是加速计算
Detect :类似于 yolov4 的 prediction ,并行三条线,分别通过3个卷积层,输出3个不同wh的特征图
3、损失
模型最后生成(假如1个图片):3个特征图80*80,40*40,20*20,对于80*80特征图,每个格子生成3个anchor(检测框),每个anchor对应 7 个数=(5+2个类别)
处理 gt 和 anchor的配对:假设一张图片的真实gt有20个,先后放缩到3个特征图上,每个特征图都有20个gt,针对其中一个特征图,gt 复制3份,此时每个 gt 中心的所属格的anchor 负责该 gt
把和anchor的宽高比相差很大的gt去掉,对于剩下的gt,再复制三份,假如该 gt 中心在格子中偏向左上,那么这三份 gt 的3个负责anchor是:一份是原先负责的 anchor,一份是上一个格子的同比例anchor,一份是下一个格子的同比例anchor,gt 和 anchor 的中心坐标是以 anchor 所在格子的左上角为原点来表示的,这个操作目的是用3个anchor(分别来自于3个格子)对同一个gt进行拟合
gt 和 负责它的anchor要计算三个损失:回归损失、类别交叉熵损失(1个anchor可能分别预测了多个类,每个类的概率个算个的,加起来不一定是1,即1个 gt 可以有多个类,然后损失就是每个类的交叉熵损失的平均值)、置信度损失(anchor的预测置信度 与 anchor和gt的ciou 做交叉熵),然后把这三个损失按照权重加起来作为该 gt 的综合损失,最后3个特征图的所有 gt 的综合损失加起来作为总损失
其中一个 gt 和 负责它的anchor 的回归损失计算方法:
将 anchor 预测的 cx,cy 通过 pxy.sigmoid() * 2 - 0.5 映射到[-0.5,1.5]区间内,这是因为gt的中心坐标值就在这个区间内
将 anchor 预测的 w,h 通过 (pwh.sigmoid() * 2) ** 2 * anchors 映射到[0,4]区间内再乘以anchor大小,这是对预测的负数能进行处理,加速收敛
采用CIOU代替 yolo3 的 MSE的位置损失,它能考虑:重叠面积、中心点距离、长宽比,公式:
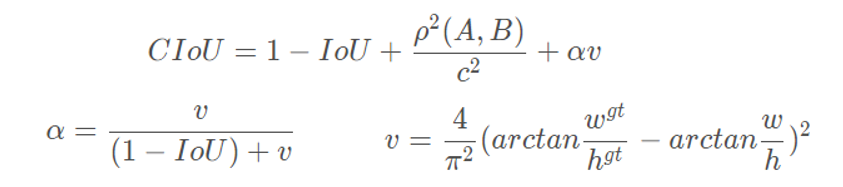
其中,w、h和w(gt)、h(gt)分别代表预测框的高宽和真实框的高宽,p(A,B)是两个框中心点的欧氏距离,c是两个框的最小包裹框(同时包含两个框且最小)的对角线距离
4、预测
读取图片im0s,经过pad,resize,HWC to CHW, BGR to RGB 到 n*640(n比640小就行,或者 640*n)大小(网络卷积不要求固定输入),归一化 :0 - 255 to 0.0 - 1.0;视频的话是遍历处理每一帧,然后一帧一帧地写到同一个视频文件中
对1个图片而言,得到预测的 17640个检测框,每个检测框对应 85=80(类别概率)+5(置信度,回归值)
先根据检测框的置信度是否大于conf_thres=0.25过滤掉检测框,取检测框概率最大的类别,如果类别概率大于conf_thres=0.25,则该检测框保留,最后用 NMS 得到 剩余的检测框,每行是一个检测框,对应 4个位置,预测的类概率,预测的类编号
此处的 nms 变为DIOU_nms(在测试过程中,并没有groundtruth的信息,不用考虑影响因子,因此直接用DIOU_nms即可,不需要CIOU_nms):把IOU换成如下公式,不仅能考虑IOU,还能考虑中心点的距离
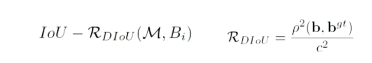
将相对于 n*640(n比640小就行,或者 640*n)的检测框还原到原始图片大小,在原图上画上检测框,标上类和概率
5、map 指标
mAP@0.5: 即将IoU阈值设为0.5
对于a类,对一张图片,统计能够满足:与该图片上的任意 gt 的 iou 能大于0.5,且检测框类别和 gt 类别都是a类,且1个 gt 不能有多个检测框 的检测框,类似统计出1个batch(来自验证集)的所有图片的符合这个条件的检测框,符合条件的检测框就属于TP,此时得到1个batch的结果
计算当只有1个 a类 的检测框时(等价于 iou 阈值非常高,只有1个检测框大于阈值)的 pr 和 recall ,pr的分母就是属于 a类 的检测框总数1,recall的分母就是当前 batch 的 a类 的 gt 的总数,此时对应 pr 图上一个点:

TP:检测器输出的结果中正确的个数
FP:检测器输出的结果中错误的个数
FN:ground truth中未被找出的个数 = ground truth总数 - TP
计算当只有2个 a类 的检测框时(等价于 iou 阈值高,只有2个检测框大于阈值)的 pr 和 recall ,pr的分母就是属于 a类 的检测框总数2,recall的分母就是当前 batch 的 a类 的 gt 的总数,此时对应 pr 图上一个点,....(代码种直接给出了300个检测框作为最大范围)
然后可以画出一条 pr 曲线:
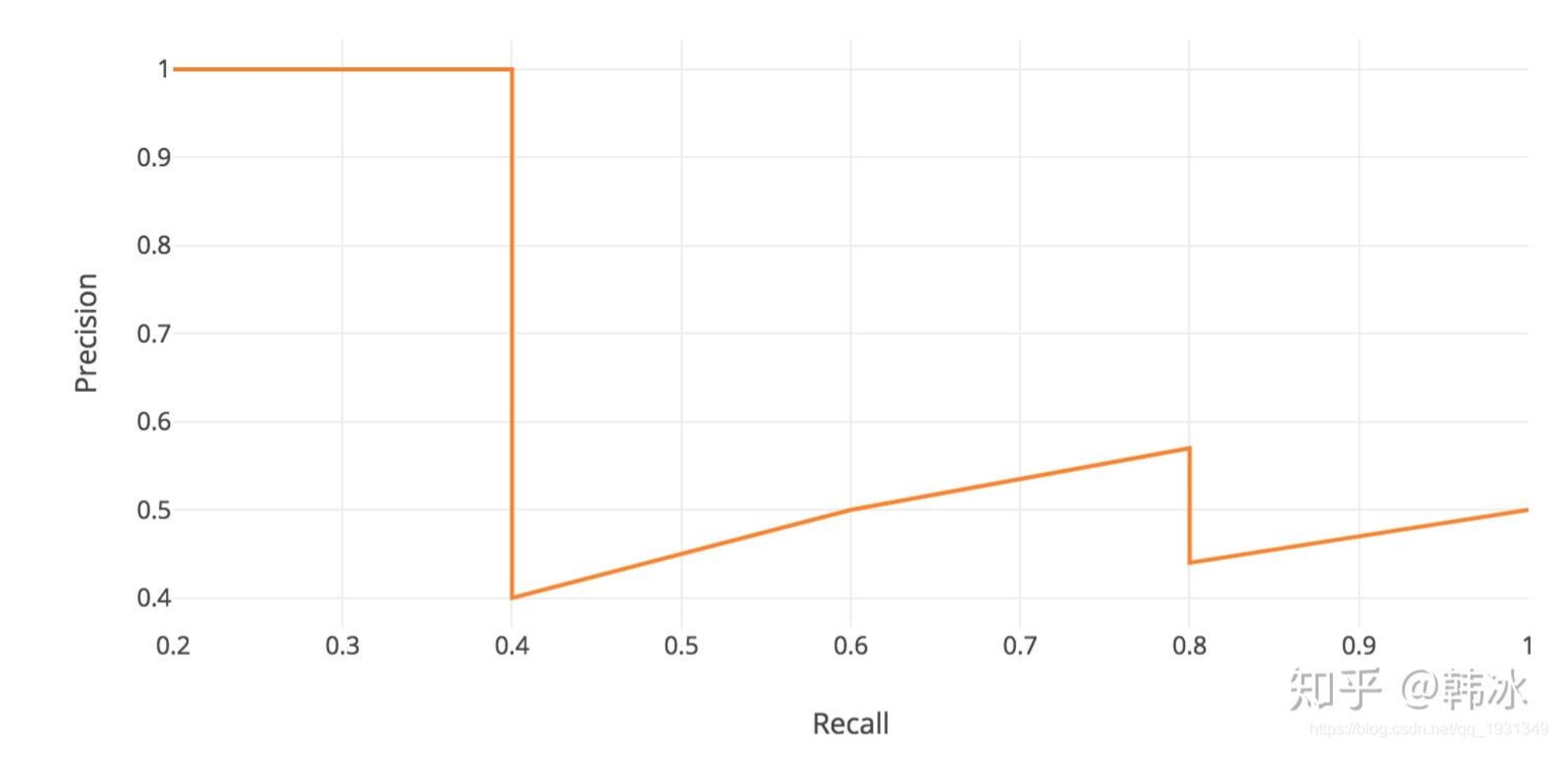
a 类的 ap = 该曲线下面积,所有类的AP取平均,得到 map
mAP@0.55:即将IoU阈值设为0.55,....
mAP@.5:.95:1个类的ap0.5,ap0.55,ap0.6,...,ap0.95取平均,然后所有类取平均
有:mAP@0.5<mAP@0.55<...<map@0.95,map值越大表明预测的越准
【yolov6】
yolov6 和 yolov5 整体结构类似,模型的具体模块不同:CBL,REP-I,REP-II(两个都属于RepVGGBlock),RVB1_X,RVB2_X,RVB3_X,SPPF,Head-Detect,网络结构上最大改进是Head-Detect,将anchor 的置信度,4个回归值,分类概率解耦为3个部分,以提高收敛速度。
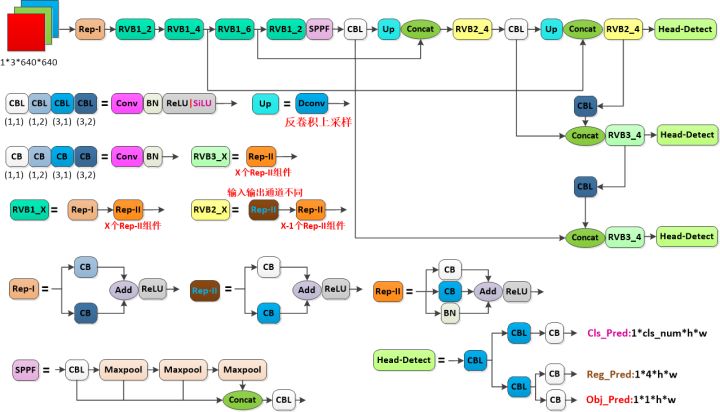
【yolo7】
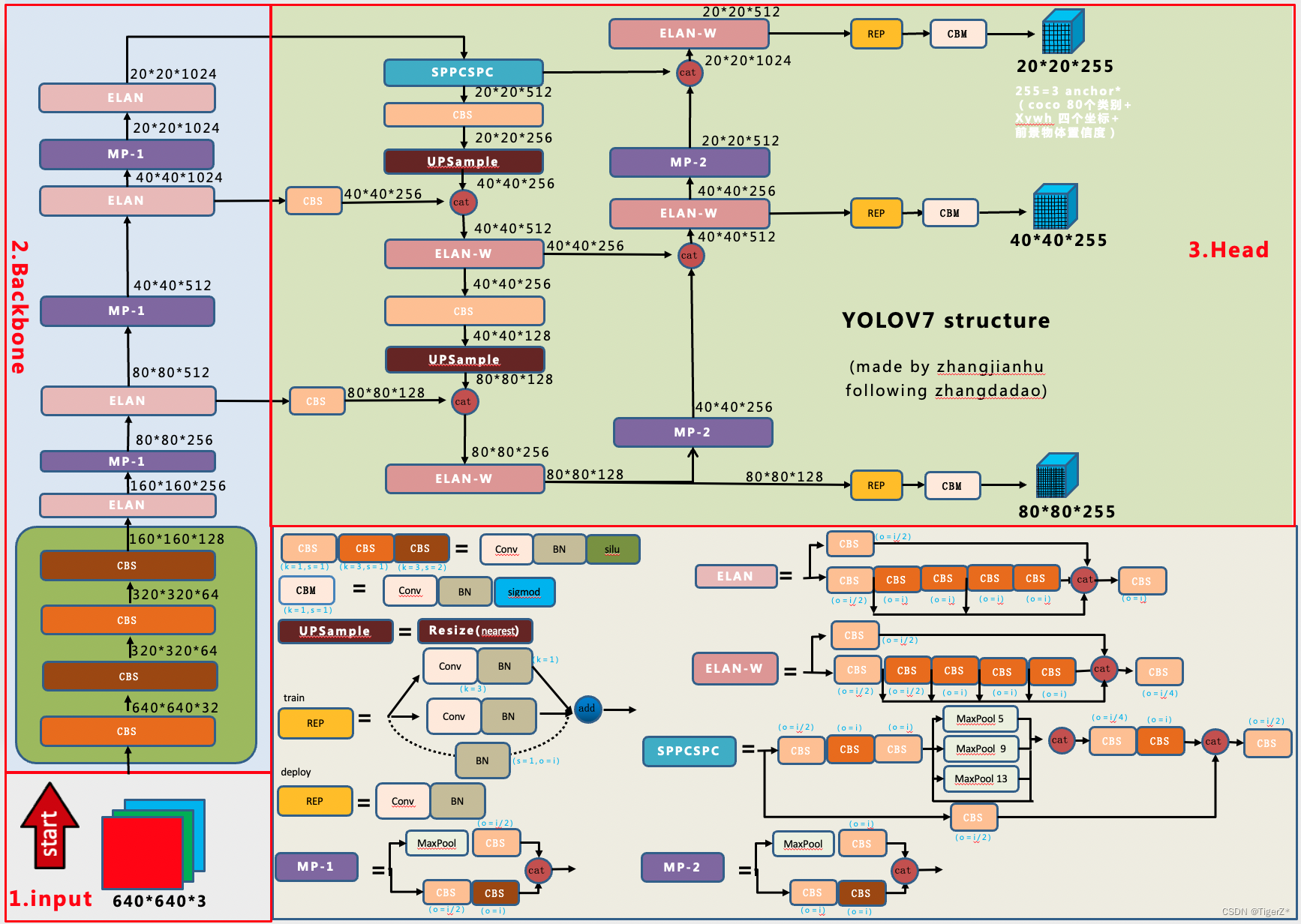
基本结构类似5版本,具体组件不同,backbone主要是使用ELAN和 MP 结构,MP同时使用了max pooling 和 stride=2的conv,neck & head采用 SPPCSPC,ELAN-W,mp,rep
【PP-YOLOv2】
1、输入前,新增了mixup做数据增强,即把两张图按权重相加合成一张图,训练一张图片时,先后进行如下增强:Mixup, 随机色彩变换,随机padding,随机裁剪,随机水平翻转,随机大小变换,像素归一化;
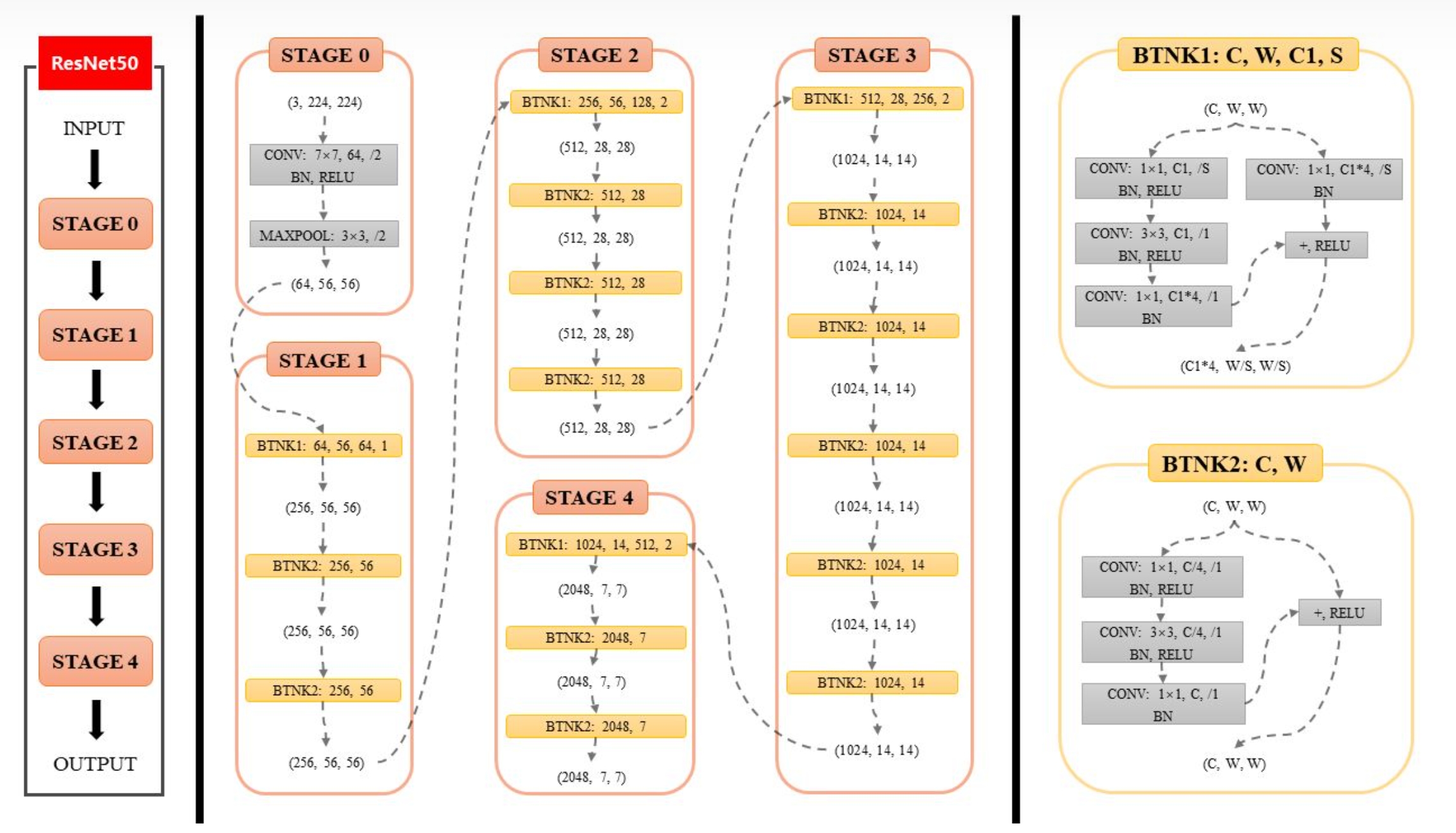
2.1 结构上首先是 Backbone ,结构是 ResNet50-vd-dcn 或者 ResNet101_vd_dcn (替换掉yolov3的Darknet53) ,vd 是 resnet 的一个变形版本,是将 ResNet50 的 stage0 的 ConvNormLayer层(conv+bn+relu) 由 1层 变为 3层 ,即不是直接把厚度变为64,而是先将厚度变为32,再不变,再把厚度变为64,这样逐步的增加厚度。50是总层有:49个卷积层+1个fc层
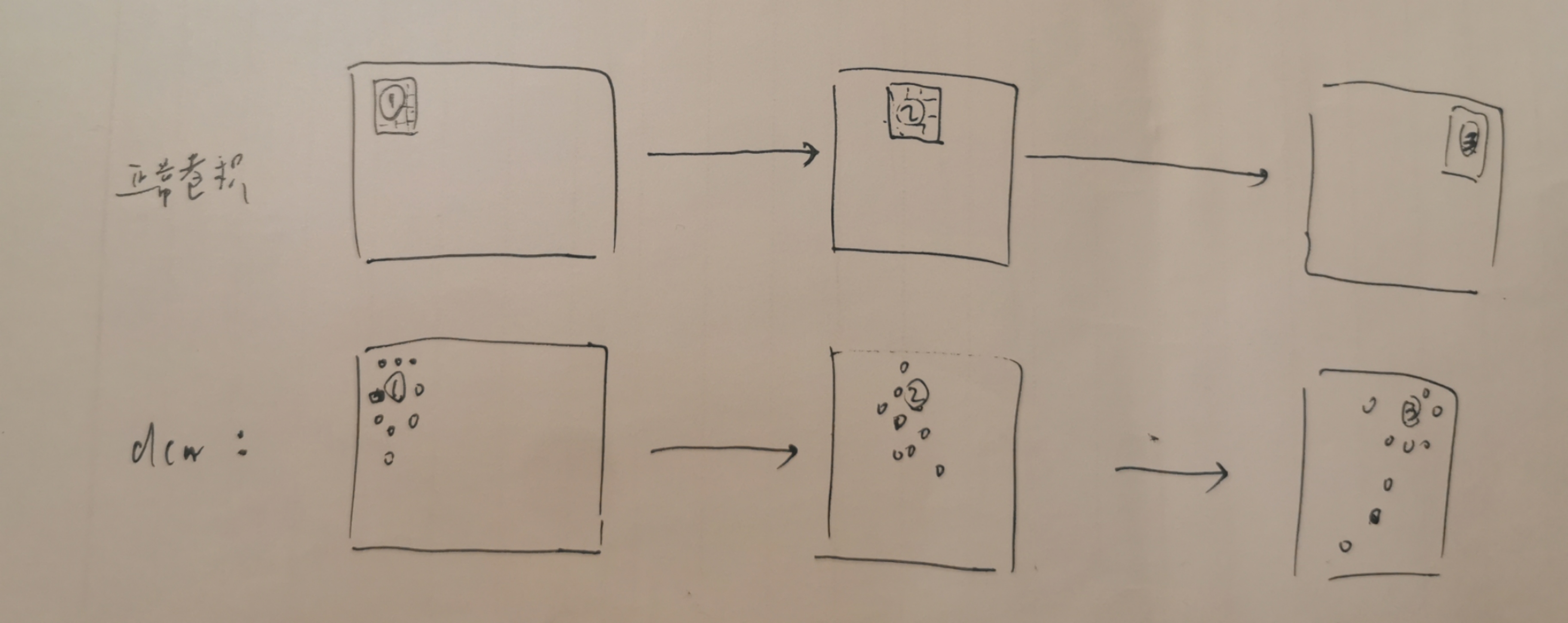
ResNet50-vd-dcn 将 resnet50_vd 中的最后1层(stage4)的 3*3卷积替换为 dcn(Deformable Convolutional),dcn是可变形卷积,卷积核的行进路线和正常卷积核一样,唯一区别在于卷积核在行进的过程中,核的形状会不断的变化,即核里面每个元素要卷积的位置会变来变去(核元素自己的元素值是不变得),这种变化是学习到的,最终核元素会学习到它得落在要卷积的图的某些物体上(学习方法是:先记住原来核元素要卷积的位置,然后让输入通过一层卷积得到核元素的要卷积位置的偏移量,两者相加得到核元素最终要卷积的位置,假定下图是3*3的核,那么核元素有9个):
核元素最终要卷积的位置所在的像素值(即,核元素值和什么像素值乘)是没有的(因为该位置一般不是整数),该处的像素值就用双线性插值来计算,比如下图某个核元素要乘以(x,y)处的像素值P(x,y),那P(x,y)就通过所在格子的四个顶点的像素值推算:

所以dcn相比普通卷积更能知道自己要卷什么,能根据图像的内容自适应的变化。
ResNet50-vd-dcn 把最后 3个 stage 分别输出的3个特征图C5,C4,C3,传给 PAN 结构
2.2 PAN 结构:是 FPN 的升级版本,FPN只能单向的融合不同尺度的信息,而 PAN 可以实现双向融合,既有从上到下,又有从下到上,应用了 Mish 激活函数,SPP,DropBlock(通过乘以掩码矩阵来随机遮掩掉一部分值,功能和dropout一样,具体理论:https://arxiv.org/abs/1810.12890)等新模块,论文结构图:
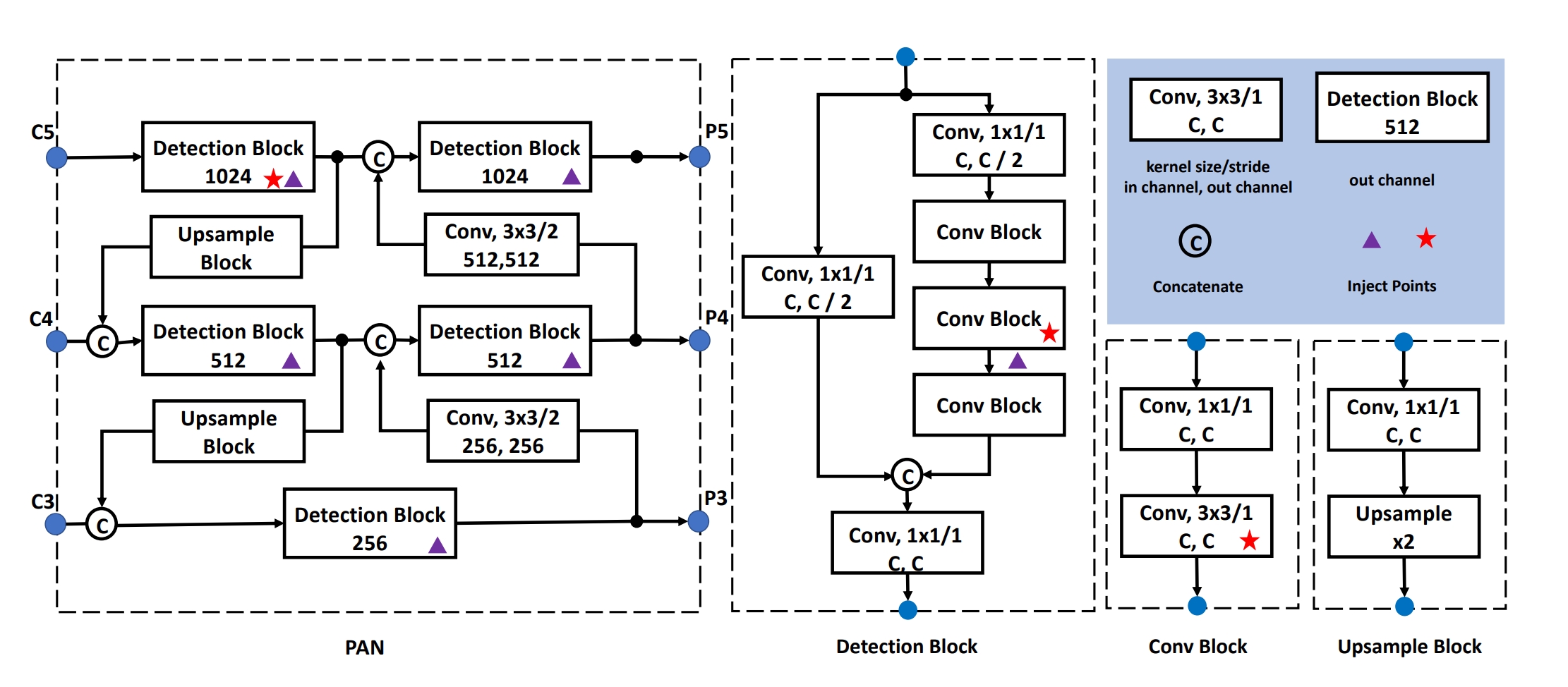
具体细节图(参考代码):
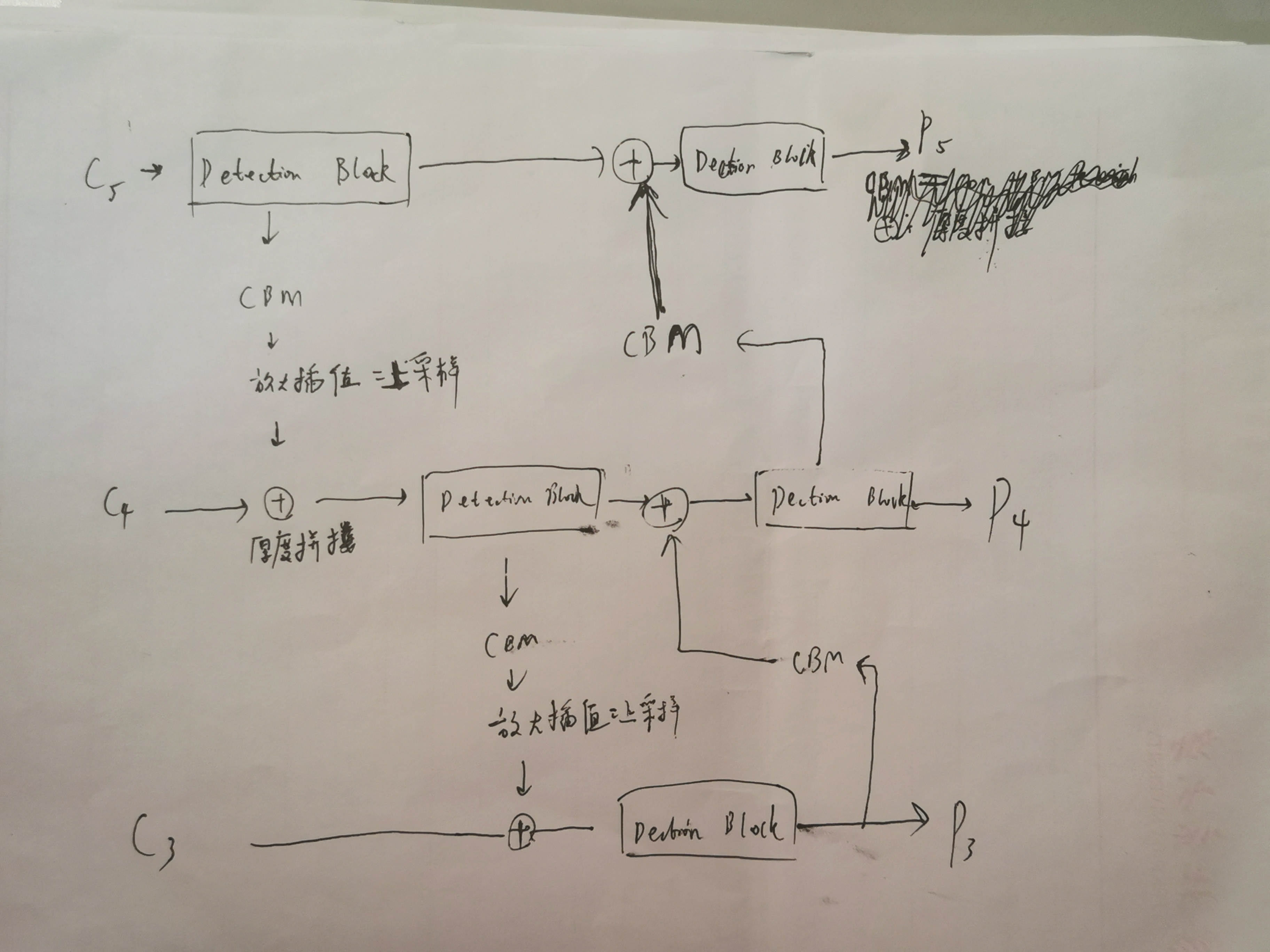
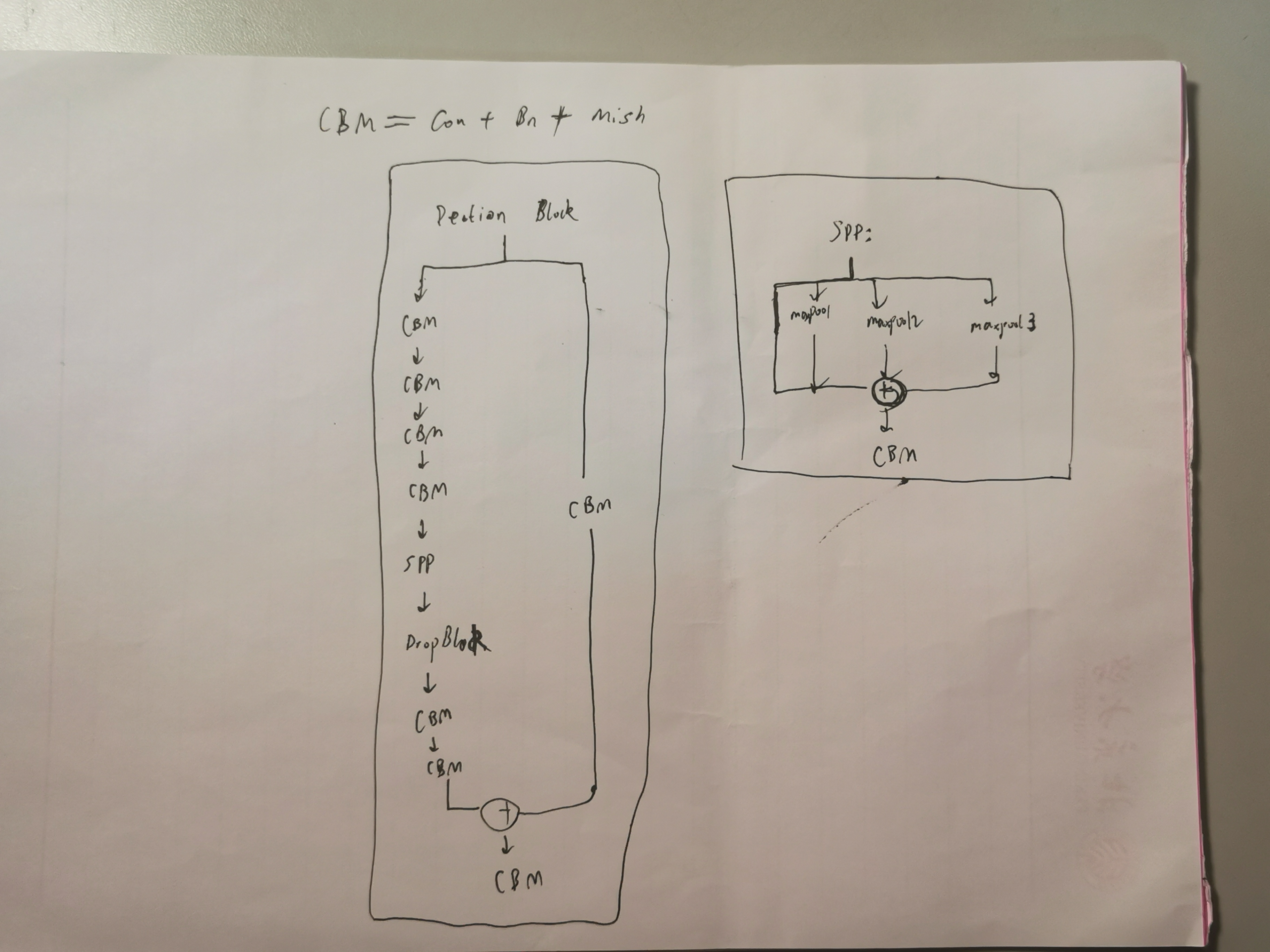
2.3 最后是 Head 结构:P5,P4,P3分别通过 con 得到 anchor 的7维度向量,1个anchor为了描述它的预测框,具有7维度数据:(4个修正回归值,预测的 iou,置信度,类别1的 logit )
如果是训练模式:分别计算每个特征图的损失,再把3个特征图的损失加起来作为总损失
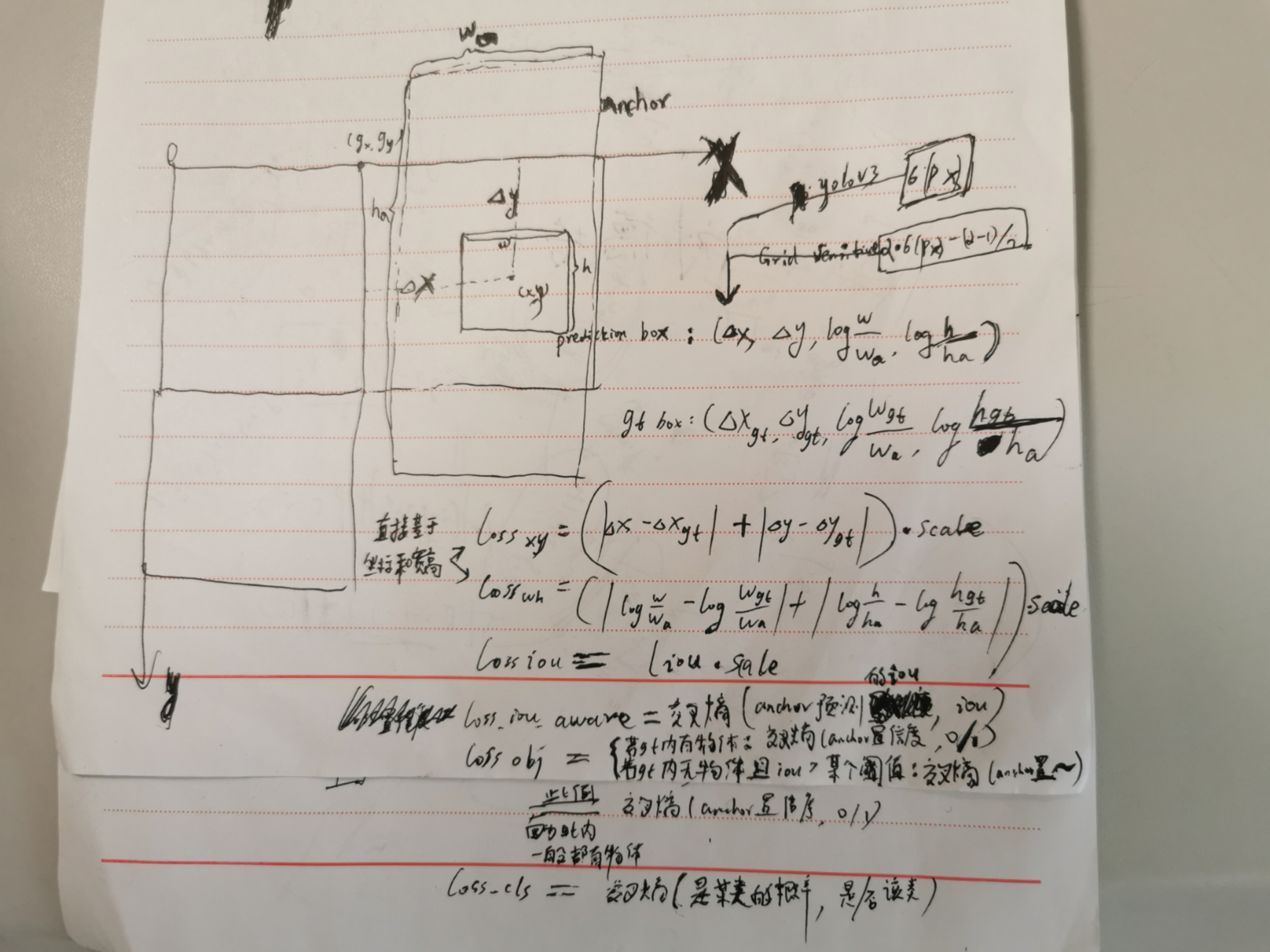
计算单个特征图的损失时,针对负责(gt 中心和anchor中心一致,且与gt 的 iou 最大) gt 的anchor,将 anchor 和 gt 对的损失分为6类,其中引入Grid Sensitive 将Δx,Δy映射到 (-0.1,1.025),该数值是相对于所在格子的左上角点,这样 anchor 预测的框的cx,cy也可以落在格子的边界上,但是效果提升并不显著,而原先的yolov3是映射到 (0,1),scale是把当前所在的特征图与原始图片的比例,一般计算损失是在特征图的尺度上计算的:
训练阶段采用EMA,始终计算参数的滑动平均值,最后在预测阶段采用参数的滑动平均值Wema来代替最终的训练参数W,效果会比较好
![]()
如果是测试模式:
每个格子都有3个anchor对应的3个预测框,预测框 prediction box 的位置:

预测框 prediction box 的 score ,该 score 融合了 iou 定位信息:
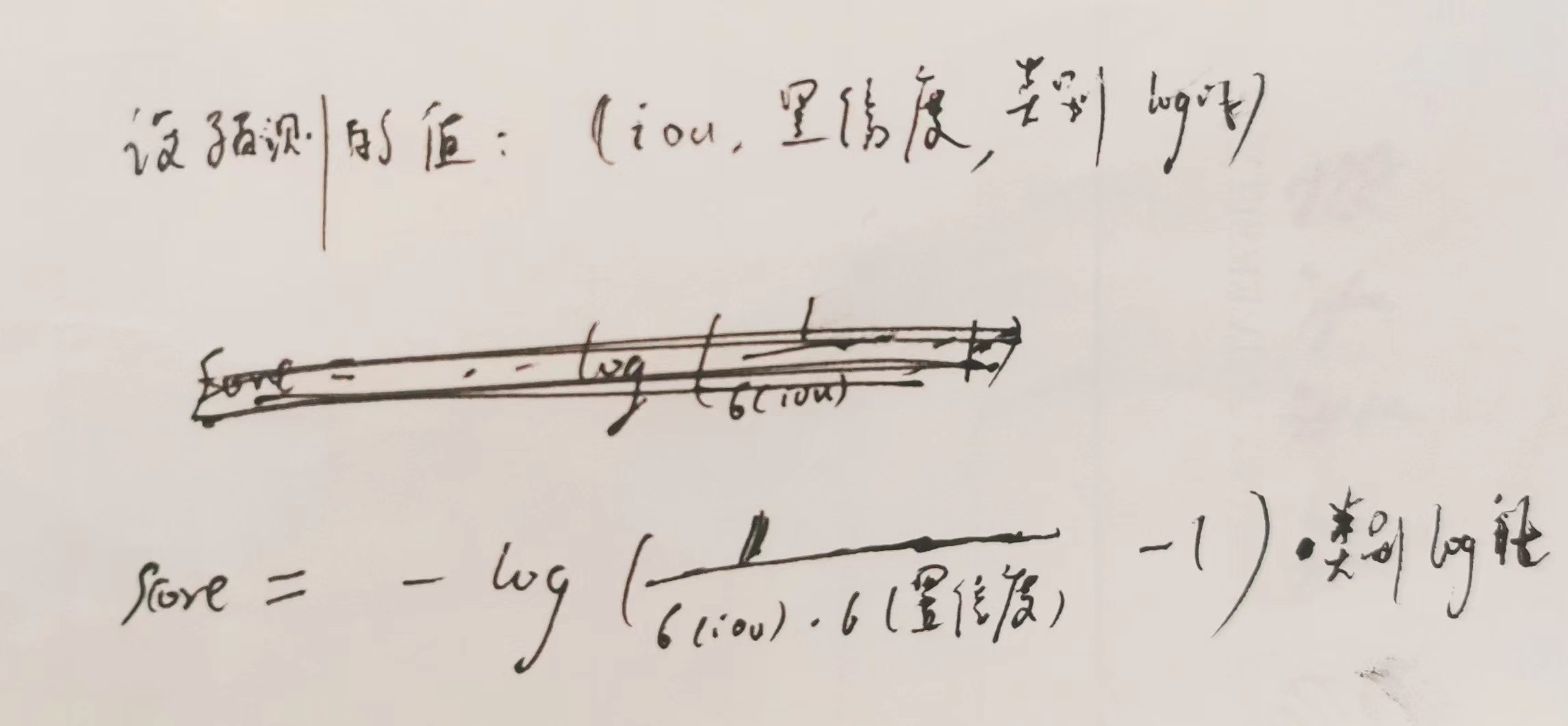
所以3个特征图每个像素产生3个prediction box,代码中产生了22743个prediction box,然后根据 score 进行 NMS,一个框对应:类别编号,score,左上角坐标,右下角坐标,由于 nms 之后还是太多了,对score设置阈值再过滤检测框

 浙公网安备 33010602011771号
浙公网安备 33010602011771号