

code2
1、闭包
注意:f(...):先执行括号里面的,再外面


输入原函数,输出是对原函数的增强函数,增强函数具备很多新的功能,采用了面向切面编程AOP思想,切面就是原函数
例子,下图的 cuont_time_wrapper 就是闭包,print_odds就是原函数,闭包里面的improve_func就是增强函数

等价写法:
装饰器就是闭包的语法糖
通过在原函数上加装饰器,即@闭包名,通过装饰使得原函数变成增强函数(实际在被调用的时候才被增强,否则不管它,增强也只增强一次)
第一次增强的时候会调用闭包里函数外的操作和增强函数的内容
后面再调用的时候,只调用增强函数的内容
如果闭包内函数外没有操作,则原函数完全等价于增强函数:
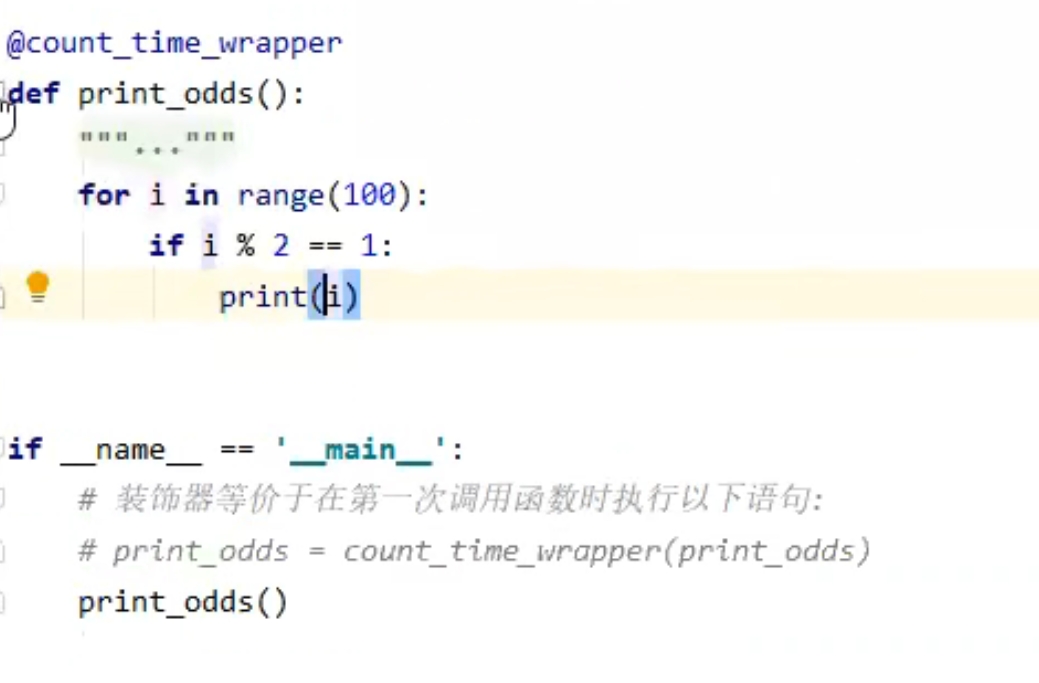
考虑到传入参数和返回值,一般的闭包定义为:

例子:base经过ct1装饰后,再给ct2装饰:

原理:第一个base()等价于:
base=ct2(ct1(base))
base() # 从上往下执行了
3、anaconda可以创建多个环境,不同环境完全隔离,a环境装的包b环境用不了,每个环境可以设置自己的python解释器,项目都是跑在某个环境下的,大部分项目的base环境是C:\Users\JARY\Anaconda3,个别项目的环境如tensorflow_1.11.0环境(自定义的),在C:\Users\JARY\Anaconda3\envs\tensorflow_1.11.0,conda源在C:\Users\JARY\.condarc中配置
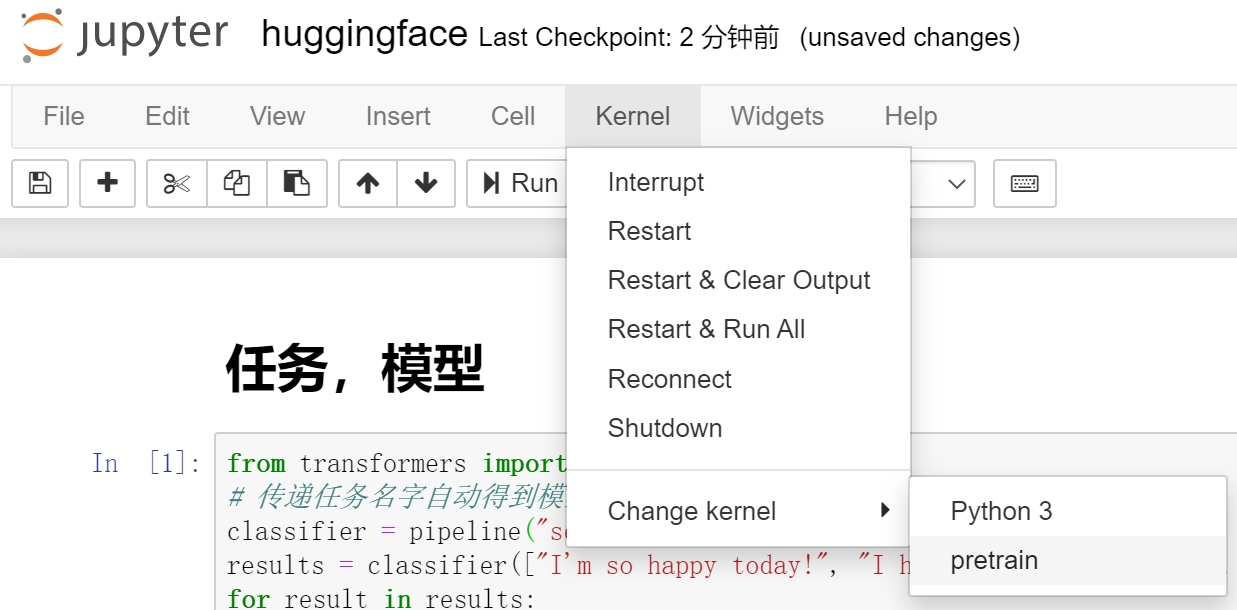
jupyter 的环境更换:

5、@classmethod
定义类方法,注意cls在python中表示类本身,self为类的一个实例
@classmethod # 此处定义类方法,注意cls在python中表示类本身,self为类的一个实例
6、list(zip([1,2,3],[3,2,1])):两两组合:[(1,3),(2,2),(3,1)]
7、:-1:2 从头到尾(不要尾),步长2 1::2 从1开始到尾(要的),步长是2
8、查看gpu 显存使用情况:nvidia-smi
查看gpu 使用的进程:fuser -v /dev/nvidia* 或者 htop
9、PyCharm连接远程服务器:https://blog.csdn.net/qq_36667170/article/details/121716527,不用管那个mappings同步了,用它自己生成的
zzz
直接 pip install 新版本的东西 会覆盖旧版本的,不需要 uninstall
torch.zeros(3,2) :3行2列的0;
torch.zeros(3) :3个0
torch.arange(3) # tensor([0, 1, 2])
torch.arange(3).float() :把每个数再转成 float
tensor.view(5,2):转成 5*2 的shape,如果是参数是 -1,则自己推算 shape
tensor.repeat(2,3,1) :把 tensor 视为1个单位,填到 shape = 2*3*1 里面
enumerate(list) : 遍历时,前索引,后元素
list.index(元素):得到第一个元素的索引值
os.listdir(path):获取路径下的所有文件
open(file_path, 'r', encoding='utf-8').readlines() : 获取 file 的所有行的内容,每行是 list 的1个元素,行后面的/n也读进了
字符串.strip():去掉首尾的空格,\n,\t
dict(zip(..)): 将 zip 转成 dict
([2,3,4])==[2,3,4]
for name in dict # 遍历的是 key
@property装饰器会将方法转换为相同名称的只读属性,这样可以防止属性被修改
tensor.t_():转置(只能对2维转置),.T能对任意维度转置
由于转置是基于浅拷贝的,如果后面跟上.contiguous() 可以深拷贝出来,这样可以避免出错,所以一般都是 tensor.t_().contiguous()
tensor shape=a*b*...*n,说明 tensor 最里面的数有 n 个
[...]代表了前面所有纬度的数据,而 [:] 只是代表一个纬度的数据
[...,0,1]:前面所有纬度都要,要其中的第 0,1 处的数据,shape为前面的纬度乘积
tensor[..., 4]:最后的那维只要第4个数,若tensor shape = 16*3*80*80*7,现在是 16*3*80*80,那7个数据只取了第4个数
若a是二维,a[...,2]:等价于取第二列数
[...,None]:结尾增1维度,shape=原来shape*1
假如a.shape=[2,3,4],a[None,:]==a[None] ,看None在第几维度,shape=1*2*3*4,a[ : , None] ,shape=2*1*3*4, a [: , : ,None] ,shape=2*3*1*4
torch.cat( [tensor1,tensor2], dim=n):将2个tensor在对应维度上拼接,如tensor1,2的shape=2*3,dim=1 , 则结果是 2*6 ; dim=0 , 则结果是 4*3,换成 (tensor1,tensor2) 也一样
a[0]:取第一维度数据,shape是后面的维度相乘,对于二维的,是取第0行,对于3维的,是取第0个batch
torch.tensor(torch.Size([2,3]))=》tensor([2, 3]),以size作为实际的值
a[ [2,1,2] ]:取 a 的第2,1,2个数,a是2维,则取行
tensor1 * tensor2:对应数各自乘,如果 tensor2 是一个数,则 tensor1 每个数都 * 该数;如果2维 tensor * 1维tensor,则把 1维tensor 乘到 2维 tensor 的每个行;反正两者的最后一维要相等,除法/操作一样
torch.max(tensor1,tensor2):对应位置的元素取最大的,输出同样的 shape
tensor.max(n):取第 n 个维度上的最大值,并降 1 维度,返回2个参数:值,索引
2.6 % 1=》0.6,只要小数
a,b,c,d=q:即a=q[0],b=q[1],c=q[2],d=q[3]
torch.ones_like(tensor):大小和tensor一样, 数据都是1,zeros_like类型
torch.stack((q,q)) :默认dim =0, 相当于batchsize=2,每个样本是q,若 q 的shape是 a*b,则现在 2*a*b,如果是dim=1,,则shape = a*2*b,如果dim=2,则sahpe = a*b*2
tensor.chunk(2,1):如果tensor 是3*5的,则会沿着维度 1 切割出 2 份,即 3*3 ,3*2
tensor.split((2, 2,1), 1):如果tensor是3*5,则沿着第1维度,切2列,2列,1列:3*2,3*2,3*1
tensor.clamp_(a,b):把tensor中小于a的置为a,大于b的置为b,中间不变,注意它会作用到 tensor 自己,而 clamp 不会
tensor[[1,0],[2,1],[2,3]]:取 tensor 第1个中的第2个中的第2个,和第0个中的第1个中的第3个数
tensor[[1,0], 1:]:取 tensor 第1个中的1:,和第0个中的1:
tensor.sigmoid():每个数通过 sigmoid()
torch.pow(tensor,3) : tensor 的每个元素取3次方
with torch.no_grad()则主要是用于加速和节省显存的作用,具体行为就是停止gradient计算,但是并不会影响dropout和batchnorm层的行为
tensor.squeeze():去掉 tensor 维度是1,数据不变,如果没有维度为1,则不变,torch.randn(2,1).squeeze():(2,1)=>2,torch.randn(1,2).squeeze():(1,2)=>2
tensor.squeeze(dim) :如果dim指定的维度的值为1,则将该维度删除,若指定的维度值不为1,则返回原来的tensor
torch.rand(2,1,3).squeeze(2)=》shape:2*1*3
torch.rand(2,1,3).squeeze(1)=》shape:2*3
a = b.detach():a 不计算梯度了
tensor.argsort() 返回的是升序后 原来的 index
torch.full_like(tensor,3) : 把 tensor 的每个数据用 3 代替,大小不变,生成新数据
import argparse;
parser = argparse.ArgumentParser() # 创建1个参数解析器
parser.add_argument(
"--cfg", # 以 --cfg 形式接受参数
dest="cfg_files", # 变量名定义,没有这行的话变量名就是 cfg
help="Path to the config files",
default=["configs/Kinetics/SLOWFAST_4x16_R50.yaml"],
nargs="+", # 可以参数后跟多个值(至少1个),用 list 接收,如 --cfg a b c ,结果就是 ['a','b','c'],如果是 = argparse.REMAINDER,则不加值的话就是[]
)
add_argument 定义参数,没有的话就用 default
arg = parser.parse_args() # 获得解析结果
parser.print_help():输出参数定义的相关信息
import sys; sys.argv 是获取运行的命令行参数,且以list形式存储
"{}".format(变量) :把变量值替换了 {}
os.path.abspath(filepath):得到绝对路径
hasattr(对象, "name"):对象是否有name属性或方法
os.path.join('path1', "path2"):路径拼接生成新字符串,根据所运行的系统加 \\ 或者 /
import platform;a=platform.system() 查看所运行的环境是window还是linux
torch.multiprocessing.spawn(main_worker, nprocs=4, args=(4, myargs)):开启了 nprocs=4 个进程,每个进程执行 main_worker 并向其中传入 local_rank(当前进程 index)和 args(即 4 和 myargs)作为参数
list("asd"):['a','s','d']
tensor.transpose(0,1):shape的第0维度和第1维换顺序,如果tensor shape = a*b*c*d,现在是 b*a*c*d
" a b c \n ".split()=> ['a', 'b', 'c']:先strip,再分割
len(dict):字典的元素个数
tensor.unsqueeze(0):在第0维度新增1维,若tensor shape = a*b,现在是 1*a*b
random.sample(序列,n):从序列中随机抽取 n 个不同的数
model.named_parameters():返回模型的所有参数(权重和偏置)的名称和值,返回的是一个迭代器,可以外面再套个 list,其中model 类需要继承 nn.Module(import torch.nn as nn)
any(序列):序列有1个True就返回True;not any:序列没有一个 True 就返回True
nn.BCELoss()(pred, label) : 返回 pred 所有样本的平均交叉熵损失,pred[i]是第 i 个样本,pred[ i ]表示第 i 个样本分别预测为各个类别的概率(一个数加sigmoid表示预测为该类的概率),概率是单个类预测概率,不一定相加为1,如 [0.6,0.6,0.3] 表示 该样本属于三个类的概率分别为0.6,0.6,0.3 ,label[i]是第 i 个样本是不是对应的类,取值为0/1(正负样本),如[ 1 , 1 , 0] 表示该样本属于前2类,所以1个样本的损失是各个类的损失的平均值
nn.BCEWithLogitsLoss()(pred, label):返回 pred 所有样本的平均交叉熵损失,比BCELoss提前加了 sigmoid ,如果已经加了sigmoid,就用 BCELoss,否则就是 logit ,就用这个。等价于 binary_cross_entropy_with_logits
nn.BCEWithLogitsLoss(pos_weight=torch.tensor([10])):不加 pos_weight 参数表示计算1个样本的损失=各个类的损失的平均值,加了则是为了缓解样本不均衡,此时计算1个样本的损失时,正样本(某类的标签=1)的损失算完还要再乘以10,再往后算
nn.CrossEntropyLoss()(pred, label):返回 pred 所有样本的平均交叉熵损失(使用softmax),pred[0]:第0个样本在每个类的 logits,label[0]:第0个样本属于哪个类
F.cross_entropy(logits, labels, reduction = 'sum'):先对logits的每行分别做softmax得到概率,labels每个值是每行的实际值索引,对第 i 行概率的第 i 个labels做-log,最后所有的-log加起来
tensor.item():将tensor变成数值,注意 tensor 只能有1个元素
np.random.seed(1) ,torch.manual_seed(1) 每次项目启动后, np 和 torch 生成的随机数都一样
torch.cuda.is_available():能不能用 gpu
torch.cuda.device_count():能用 gpu 个数
model = model.cuda(device=torch.cuda.current_device()):把模型放到当前 gpu 上
time.time() :1970年到现在的秒数
random.shuffle()用于将一个列表中的元素打乱顺序,值得注意的是使用这个方法不会生成新的列表,只是将原列表的次序打乱
m=nn.Embedding(3, 4):创建可训练的 3*4 矩阵(作为lookup table),即3个向量,每个向量维度是4,每个数符合标准正态分布,m(torch.LongTensor([2,0,1])) : 取出第2,0,1行的向量(ID为2,0,1的词转成词向量),若Embedding的 padding_idx=n,则矩阵的第 n 行为0向量
tensor.size():输出shape
nn.ModuleList():用于 append 一些层,如nn.Conv1d
torch.rand(2,3,4,5).permute(3,2,0,1).shape : torch.Size([5, 4, 2, 3]),permute将不同维度换顺序,能实现转置
nn.Linear(4,3):将4维向量映射为3维向量
Conv1d:卷积核只能横向运动
conv1 = nn.Conv1d(in_channels=256,out_channels=100,kernel_size=2):输入bs*h*w,词向量维度 h=256,词向量个数是 w ,100个卷积核,每个核大小是256*2,每个卷积核生成1行,输出bs*100*(w-1)
input = torch.randn(32,35,256).permute(0,2,1):得到shape = 32*256*35
out = conv1(input):shape:32*100*34
Conv2d:卷积核能平面运动
conv2 = nn.Conv2d(1,4,(2,3)):输入bs*厚度*h*w,输入的厚度(通道数)h=1,输出的厚度 = 卷积核个数=4,卷积核的h=2,w=3,卷积核的厚度=输入的厚度 h =1
input=torch.randn(3,1,5,4)
out = conv2(input):shape:3*4*4*2
nn.MaxPool2d(3, stride=1):核大小 3*3,平面移动
fun(*(1,2,3)):*解构元组,等价于fun(1,2,3)
torch.from_numpy(a) : 把 numpy.ndarray 转为 tensor
model.eval() : batchNorm层,dropout层等用于优化训练而添加的网络层会被关闭,从而使得评估时不会发生偏移
os.system("nvidia-smi"):输出显存使用情况
Mixed Precision Training 能将最新的GPU上的显存消耗降到一半,并且加速训练过程
m = nn.Dropout(p = 0.5)(input) : input 每个元素有 p=0.5 的概率b变为0,如果没有变0,则 再除以 (1-p) 进行放大
tensor.reshape([3,-1,4]).shape:把Tensor shape 变为 3*推断*4 ,reshape 不需要 contiguous()方法 限制
tensor1.mul(tensor2):对应位置相乘
tensor1.expand(3,4):将 tensor1 的 shape 变到 3*4,需要复制的话就复制元素
torch.index_select( tensor1 , n ,indices):在tensor1的第n个维度上,选取索引 indices
"asdqqq".endswith("qqq"):字符串的结尾是否是 qqq
f'str{a}str' :f+{}表面要把 变量a解析一下
torch.linspace(0,11, 10):返回10个数,数之间距离一样,范围是[0,11]
tensor.numel(): tensor 里面的元素个数
'字符串%s字符串' % 'Class':将后面的Class 替换了 %s
tqdm 用于观察迭代的进度,第一个参数是迭代内容,通过后面的 for 可以一个个取出,desc放到显示的前面,bar:10是中间的格子最多有10个,每次迭代一次就会动态显示进度,和迭代了%多少步
from tqdm import *
pbar = tqdm(range(10),desc='进度',bar_format='{l_bar}{bar:10}{r_bar}') # 新建对象就会打印出来,只是进度是0%
for i in pbar:
print(i)

with 通常用于自动关闭文件或者连接,不用单独调用 close(),在进入的时候会调用__enter__() ,如果该方法有返回对象,则可以用as接收,然后是with里面的代码,在结束的时候会调用 __exit__() 方法,有定义__enter__() 和 __exit__() 方法的对象都可以放到with 后面
torch.tensor((2, 3, 4, 5))==torch.tensor([2, 3, 4, 5])
torch.tenor( 1 ):没有 shape
torch.tenor( [ 1 ] ):shape:1
shape(2,3) / shape(3):tensor 每行都除以这三个数
shape(2,3) / shape(2,1):第一行都除以第一个数,第二行都除以第二个数
tensor.tolist():把 tensor 转为 list
dpkg -i xxx.deb:安装某个 deb 包(已经提前下载好的)
nvcc -V:查看 cuda 版本
cat /proc/version:查看 Ubuntu 版本
which 命令:查找命令的绝对路径,其中环境变量PATH中保存了查找命令时需要遍历的目录
pip:通过调用 pip文件 里面的 python 解释器来执行,不同的 conda 虚拟环境下会调用对应环境下的 pip (conda activate 会更新 pip,如果没有的话,只能:虚拟环境地址/pip install ...)
tensor.log():每个数取 log
os.makedirs('./路径名'):创建目录
~布尔tensor:取反
外网a连接外网b中的虚拟机中的Ubuntu:Ubuntu 安装好openssh-server并启动 ssh 服务(如果需要配置Ubuntu源,则https://blog.csdn.net/liangzc1124/article/details/124580600,然后 sudo apt update),在ubuntu中下载cpolar,并建立tcp隧道,记住隧道地址,比如1.tcp.cpolar.io:10972,此时在a中输入:ssh jary@1.tcp.cpolar.io -p 10972 就能登录了(或者在xshell中配置主机:1.tcp.cpolar.io,端口号:10972)
im = cv2.imread(图片路径):读图片,但是BGR格式
cv2.cvtColor(image, cv2.COLOR_BGR2RGB) : BGR格式-》RGB
cv2.resize(image, (608,608) ):变换图像大小到608*608
loss.backward():计算梯度,loss是tensor
optimizer.step():根据当前梯度更新网络参数
optimizer.zero_grad():清空过往梯度
学习率更新 :scheduler.step(),学习率调整一般在参数更新之后
LambdaLR(optimizer, lr_lambda, last_epoch=-1, verbose=False):lr调度器,base_lr是optimizer里面的lr,下一步的学习率 = lr_lambda(last_epoch) * base_lr,每次 step() 之后,last_epoch+=1
[i for i in range(10) if i%2==0]:先for,再if,只要 if 成立的数
tensor.numpy():tensor->numpy
local_rank:进程号
os.path.split('C:/soft/python/test.py')=>('C:/soft/python', 'test.py'),分割出目录和结尾的文件名
torch.cuda.get_device_capability() : GPU算力,越高越牛逼
{**dict} : **拿出出 dict 的所有key:value
{123,321,'s'} : 制成1个set
a=[2,31,4,2] ; a.insert(2,5) # 在第2个索引位置前插入5,会改变list自己 => [2, 31, 5, 4, 2]
d = collections.deque(maxlen=4) # 双端队列总长度为4,超出了则挤掉一些元素;d.append('a') # 在最右边添加一个元素,此时 d=deque('a');d.appendleft('b') # 在最左边添加一个元素,此时 d=deque(['b', 'a']);queue.pop()右边出元素
torch.meshgrid(
torch.tensor([1, 2, 3]),
torch.tensor([4, 5, 6])) # 生成2个tensor,这两个Tensor对应位置的元素组合,可以描述:(1,4),(1,5),....等 3*3 = 9个点的位置
torch.flatten( tensor ):将 tensor 铺成1维度
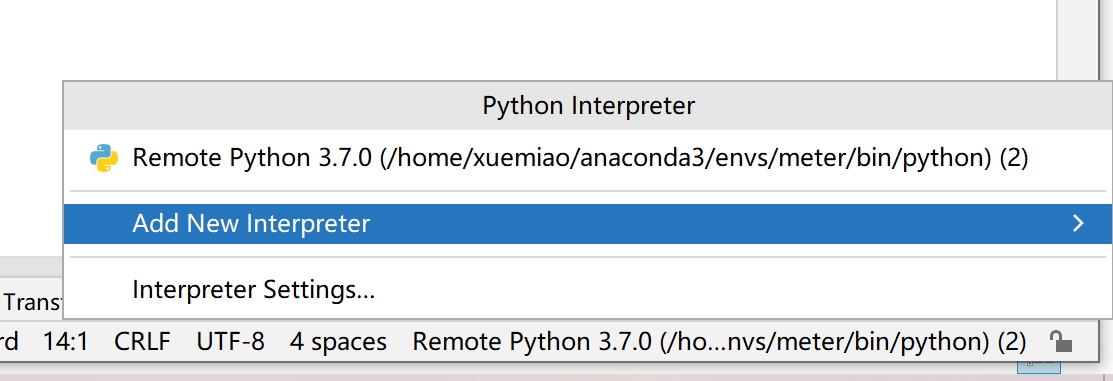
为了解决pycharm总产生/tmp/随机值/,选python解释器时,先add:
Path("C:/asd.jpjg").with_suffix(".asdlll"):把后缀名替换(没有的话则添加)为asdlll=>WindowsPath('C:/asd.asdlll')
Path('a.mp4').resolve():返回a.mp4在项目中的绝对路径
pd.read_csv('clinic.csv',index_col = 0) :原样读入csv文件
dataframe.head() # 打印前五行数据
dataframe.drop("ID卡号", axis=1, inplace=True):去掉"ID卡号"列(axis=1),且作用到自身(inplace=True)
dataframe.columns.str.match('挂号'):对于所有列,是否以'挂号'作为列名的开头
dataframe.isnull():对于所有的元素,如果没有元素则为True,否则为False;dataframe["Age"].isnull():对于该列的每个元素,如果没有元素则为True,否则为False
dataframe.sum():分别统计每列的样本总和,等价于 dataframe.sum(axis=0),即把所有行加起来
dataframe["Age"].sum():把该列的所有值相加
pandas,tf,torch 的维度计算都一致的
dataframe['接诊科室名称'].value_counts():统计该列中,各个值分别出现多少次
dataframe.fillna(123):把所有空值用123写入
dataframe.Age.unique():Age列的所有不重复值,包括空值
dataframe.loc[1]:第1行,loc[[1, 3]]:获取第1,3行,loc[0,'Age']:第0行第Age列
y=dataframe.pop('Age'):把age列给y,dataframe自己没了这列
dataframe.columns:得到所有列名
dataframe.sort_values(by='Score', ascending=False) # dataframe 按照score列的值降序排序
dataframe.dropna(axis=0,how='any',inplace=True) # 删掉至少(any)有1个空值的行
dataframe.loc[dataframe["姓名"]=='阿萨德','age'] = 123:姓名列是阿萨德的行,把age列赋值为123
torch.where(布尔数组):返回True的横坐标索引,纵坐标索引
torch.where(condition,a,b):如果满足condition条件,则选择a,否则选择b作为输出。
np.unique([2,0,4,4,3,1,4], return_counts=True):去掉重复的值,然后升序排列,并输出每个值在旧数组中出现的次数
dataframe.values:转ndarray
dataframe.iloc[0, :] #选取第0行
keras.utils.np_utils.to_categorical([2,1,0]) # 分别转为onehot,2->001;1->010;0->100
from sklearn import preprocessing;enc = preprocessing.OneHotEncoder();enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]]) # fit来学习编码 ;enc.transform([[0, 1, 3]]).toarray() # 把所有列分别转化成one-hot,比如第2列总共可以取0/1/2,所以把1编码为one-hot形式,如010,各个列的转化相互独立,fit是学习一下,transform即预测0,1,3分别要转成什么样子
cap = cv2.VideoCapture(0) # 创建摄像头对象 , 0表示笔记本摄像头,还可以填写视频路径,如'a1.mp4'
ret, frame = cap.read() # 读取一帧,ret表示是否读取成功
'2123'.isnumeric():是否是数字字符串,返回True
dataframe:最左边是index,最上面是columns
pd.DataFrame.from_dict(dict,orient='index'):dict 转 dataframe,每个key,value 是一行
pd.Series(dict):dict 转 series,每个key,value 是一行
dataframe[列名]:返回Series类型
dict 转 dataframe,每个key,value 是一行
dataframe2 = dataframe1:浅复制(共内存), dataframe2 = dataframe1.copy(deep=True):深复制(拷贝一份)
dataframe['学号']==123]['第一组']:取出学号列是123的行的“第一组”的列的取值
pd.read_csv('a.csv',encoding = "GBK",skiprows = 1):有的文件打不开,需要指定编码方式,如GBK,如果不指定的话,默认采用 utf-8;skiprows =1 是跳过开头的1行不读
dataframe.to_csv('res.csv'):保存为csv文件
os.listdir(目录):返回该目录下的所有文件(夹)名
json.load(open( jsonpath )):读取 json 文件
字符串.find('a'):找到a的索引位置,没有的话返回-1
字符串.count('str'):字符串含有str的此处
'''可以定义换行的字符串,内部包含了换行符
map(function,iterable,...)把函数依次作用在list中的每一个元素上,得到一个新的list并返回
a[-3:] :【倒数第 3 个到结束】
dir(对象):返回对象的属性和方法
torch.cumsum:累加
JSON.stringify(对象):对象转成 json 字符串
JSON.parse(字符串) :将字符串转换为 JavaScript 对象
localStorage.getItem(key):获取指定key本地存储的值;localStorage.setItem(key,value):将value存储到key字段,localStorage属于永久性存储
nn.Conv2d(16, 33, (3, 2), (2,1)) torch.randn(10, 16, 30, 32):输入:bs=10,通道=16,height=30,width=32的图像,用33个(=输出的特征图厚度)的 size =(3,2)卷积核以stride = (2,1)去卷积
output,(h_n,c_n) = nn.LSTM(input_size=300, hidden_size=1024, num_layers=1, bidirectional=True, batch_first=False) shape(31 * bs * 300):将1条有31个词的输入文本通过 num_layers = 1 层的双向(bidirectional=True)LSTM,output:返回每个词的结果,其中300维的词向量被映射为2 * hidden_size=2048 维的词向量,h_n是每一层的最后1个单词输出,如果bidirectional=True,则一层输出2个
torch.masked_select(x,mask):把x中mask对应位置是True的元素拿出来
datetime.now().strftime("%Y-%m-%d %H:%M:%S"):当前的年月日时分秒
ls | wc -l:当前目录下有多少文件
train_loader = Dataloader(dataset , collate_fn=pad_collate,shuffle=True,batch_size=8,drop_last=True)for data in train_loader:先随机产生index,然后通过Dataset类里面的 __getitem__ 函数获取该 index 的单个数据,然后组合成batch_size=8的batch,再使用collate_fn所指定的函数对这个batch做一些操作,比如padding之类的,返回1个batch给data。drop_last=True:剩余的不够组成1个batch就不要了
torch.gather(input, dim, index):二维情况下, if dim == 0=》out[ i ][ j ] = input[ index[i][j] ] [ j ] ;if dim == 1=》out[ i ][ j ] = input[ i ][ index[i][j] ]
tensor.scatter(dim, index, src):二维情况下,if dim == 0=》self[ index[i][j] ][ j ] = src[ i ][ j ] ; if dim == 1=》self[ i ][ index[i][j] ] = src[ i ][ j ]
torch.narrow()函数是用来返回Tensor的切片的:

perl mteval-v14.pl -r ref.xml -s src.xml -t tst.xml:使用 NIST(BLEU的一种改进),BLEU进行评测,src.xml:要翻译的文档,ref.xml:标准翻译后的文档,tst.xml:模型翻译后的文档
np.where(condition,x,y) : 第一个参数表示条件,当条件成立时where方法返回x,当条件不成立时where返回y
roc_auc_score(true_binary, score_binary) # 模型的AUC= ROC曲线下的面积,true_binary[i]:第 i 个样本标签实际属于0 or 1,score_binary[i]:预测第 i 个样本标签是 1 的概率
shell脚本: set -u (检查脚本内的变量,如果有变量未被定义将终止脚本),set -x:显示脚本执行过程并将脚本内的变量的值暴露出来
group = parser.add_argument_group("BPETextField");group.add_argument("--vocab_path", type=str, required=True, help="The vocabulary file path."): # 创建 1 个分组BPETextField,下面的小参数放到 BPETextField 里面
os.path.splitext(path) 分离文件名与扩展名;os.path.splitext('c:\\csv\\test.csv')=> ('c:\\csv\\test', '.csv')
os.path.basename('c:\test.csv') =>'test.csv' 返回path最后的文件名
parser.add_argument('-b', '--batch_size',metavar=‘asd’ ,choices=[32,64]...), # 命令行可以以:-b 64 接受64,然后赋值给 batch_size,当然也可以 --batch_size 64,metavar:控制参数的help信息的显示,不影响参数加载,choices:参数值只能传32或者64
parser.add_argument('--no-cuda', action='store_true', default=False, help='Disable cuda for training'):action='store_true',只要命令行出现了--no-cuda,则自动设置 --no-cuda=True,否则就是default,store_false 完全相反。
parser.add_argument('--batch_size','-b'):可以以-b 接受参数,变量名还是 batch_size
vars(parser.parse_args()):转成字典形式
'%s_%s_asd' % (变量A, 变量B)=》A的值_B的值_asd
for key in dict:key是 dict 里面的 key
json.loads:json字符串转为字典
subprocess.check_output(["python3", "xx.py"], universal_newlines=True):执行shell命令python3 xx.py,universal_newlines=True:把返回的结果转码为字符串
all(list) list所有元素是否都为 TRUE
[2,3,1,10,32][-8:] : -8超过了长度,所以就返回全部
filter(lambda x: x%2==0,range(10)) =》[0, 2, 4, 6, 8] : 保留符合条件的元素
requires_grad是Pytorch中通用数据结构Tensor的一个属性,是否保留对应的梯度信息
glob("a/*.png"):筛选a里面符合条件的文件名
pbar.set_postfix(字典) # 把字典显示到进度条上
pbar.update(10):进度条手动加10
plt.subplots(nrows=2, ncols=3, figsize=(18,4)):2行3列的子图,子图大小是 figsize
python -m test --a b:运行 test.py 文件,--a b 都传给 test,sys.argv:【 test.py的路径,--a,b】,argparse 解析的是 --a,b
pad_sequence([a,b,c],batch_first=True,padding_value=1):先看a,b,c谁最长,如c,然后把a,b用 1 pad到对应长度
torch.addmm(M, mat1, mat2):mat1 矩阵乘 mat2 + M
a.eq(b):对应位置如果相等,则是True,否则False;ne相反
0%| | 3569/2725991 [30:13<363:53:02, 2.08it/s] : tqdm:目前过去了30分钟13秒,还剩下 363个小时 53分钟2秒 才能完成,目前1秒处理2.08个,目前进展 0%
nohup /home/xuemiao/anaconda3/envs/gpt2/bin/python /tmp/pycharm_project_411/preprocess.py --train_path dataset/train_data.txt --save_path dataset/train_data_all.pkl --deal 1 >out.log & : 后台不中断执行该文件,输出给out.log,运行完了就能直接退出了
代替nohup:1、tmux new -s asd:新建并打开一个叫asd的会话,此时该会话的状态是attached,可以通过tmux ls查看,2、在会话里面运行程序,Ctrl+b c会话里面新建1个窗口,再里面运行程序,此时下面的状态栏显示会话名称以及会话里面的所有窗口,Ctrl+b <number>:切换到指定编号的窗口再工作,3、快捷键Ctrl+b d将会话分离,此时会话状态没有attached了,4、下次使用时,重新连接到会话tmux attach-session -t asd,5、不用了则杀死该会话,tmux kill-session -t asd
tmux a //进入最近的会话
ps -ef:列出正在运行的任务
jobs -l:列出当前连接在后台运行的任务,如果又开启了新的链接,则不会显示
for i , item in enumerate(b,2):b正常遍历,只是 i 是从2开始算的,也就是 (2,b[0]) , (3,b[1]) ...
open()文件对象:
f .seek( n ) 是从文件开头游标偏移了n个字符
f.seek(offset, where):offset:开始的偏移量,where参数表示offset参数的意义,0:表示从文件起始位算起(绝对位置),1:表示从当前位置算起(相对位置),2:表示从文件尾开始算起
f .tell():当前游标所在的索引
f.readline():读取1行后,游标会跑到下一行
tensor.data.masked_fill_(mask,-1):对tensor,把mask中True的位置的元素置为-1
torch.from_numpy():把ndarry 转换成 tensor
1e10: 1*10^10
torch.topk(input, k):返回 input 中最大的 k 个数 和 对应索引
set -e # 这句语句告诉bash如果任何语句的执行结果不是true则应该退出。
set -u # set -u 就可以让脚本遇到错误时停止执行,并指出错误的行数信息。
os.walk(路径):返回指定目录下所包含的子目录和文件
for root, dirs, files in os.walk(path):当前所在目录,有多少文件夹,有多少文件
zip -r data.zip data : 压缩
datasets.ImageFolder(root):分类读取文件夹下的图片:比如
root/dog/xxx.png
root/dog/xxy.png
root/dog/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/asd932_.png
optim.Adam( generator.module.generator.parameters(), lr=args.lr, betas=(0.0, 0.99) # 第一个参数指定要训练哪些参数,后面指定用什么指标训练这些参数
"2".zfill(3):'002'
model.named_parameters :模型的所有参数名字和参数值
model.parameters:模型的所有参数值
loader = DataLoader([2,4,1,5,10,52,222,555,111,222,4444,55555], shuffle=True, batch_size=3, drop_last=True):12个元素随机组成12/3=4个batch
data_loader = iter(loader) # 变成可遍历的
print(next(data_loader)) # 得到第1个batch
print(next(data_loader)) # 得到第2个batch
print(next(data_loader)) # 得到第3个batch
print(next(data_loader)) # 得到第4个batch
module.register_forward_pre_hook(fn):调用 forward 前要通过 fn 函数
torch.flip(input,[2,3]):翻转 input 的第 2 维度的数据,再第 3 维度
@staticmethod或@classmethod,可以不需要实例化,直接类名.方法名()来调用。
F.conv2d(x, w, b, stride=2, padding=2):2d卷积运算,其中输入图像 x.shape:(1, 3, 28, 28) ,1张3通道的28乘28的图像,w.shape:(16, 3, 5, 5) 16(输出的特征图厚度)个3通道的5乘5卷积核,b.shape:(16),是偏置,stride,padding描述卷积核的运动。最后输出的特征图大小:1, 16, 26, 26
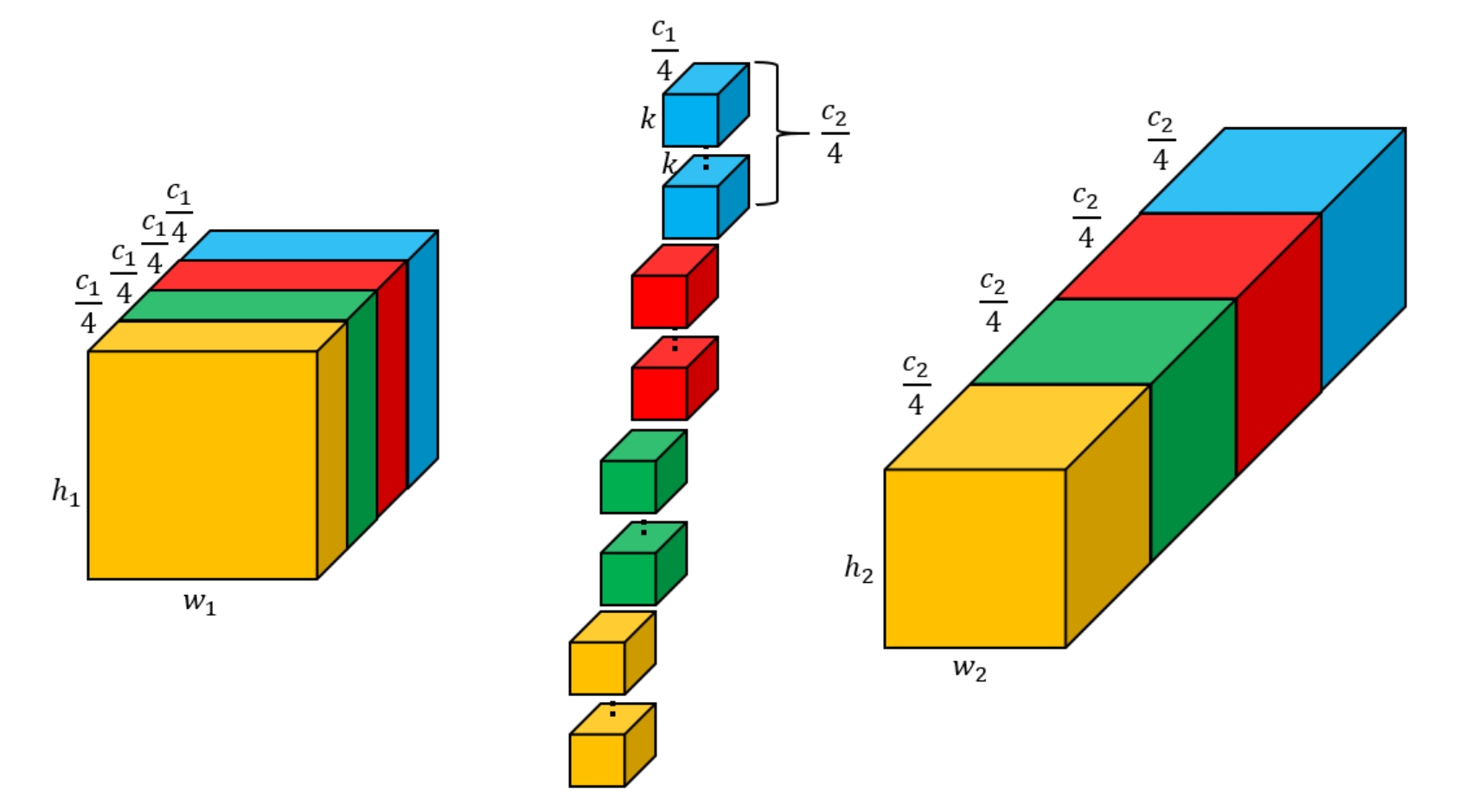
nn.Conv2d(c1,c2, groups=4):group默认为1,即不分组:

分组卷积(不改变输入输出大小,目的是减少参数量、且不容易过拟合):此处分4组,则把输入图像和卷积核沿着厚度平均切成4块,各自卷积各自的,最后再拼起来:
nn.Parameter((torch.rand(4, 2)))可以看作是一个类型转换函数,将一个不可训练的类型 Tensor 转换成可以训练的类型 parameter ,并将这个 parameter 绑定到这个module 里面,.data得到具体的tensor数值
nn.InstanceNorm2d(3)(torch.randn(size=(1,3,2,2))):归一化:输入1个特征图,该图3个通道,hw是2*2,针对每个通道,该通道内的(2*2)的元素求出均值和方差,然后该通道的每个元素x:
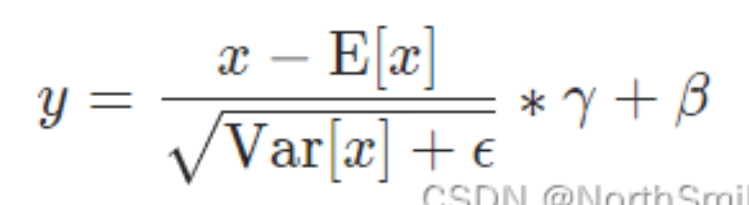
torch.autograd.grad(outputs=z, inputs=x, retain_graph=True)[0]:z对x求导后的导数值
tensor.norm(2, dim=1):对向量的第一维度,求模长
tensor.add_(10, 4):10*4+tensor
windows传输任意文件(比如FFHQ.zip)给linux(比如/tmp/pycharm_project_943/ffhq/ 目录下):先在FFHQ.zip目录 按住shift+右键,点击powershell,
scp -P 3722 .\FFHQ.zip xuemiao@222.29.68.23:/tmp/pycharm_project_943/ffhq/
从服务器上下载文件到window的d盘,31079是服务器端口:
scp -P 31079 root@10.31.118.166:/root/miniconda3/envs/pytorch/lib/python3.9/site-packages/bert4vec.tar.gz d:
zip -s 100M mariadb.zip --out mariadb_test:zip 将mariadb.zip分卷(分割),每个卷100M大小,分卷后的结果:mariadb_test.zip、mariadb_test.z01、mariadb_test.z02
zip -s 0 mariadb_test.zip --out full.zip:将分卷后的(mariadb_test.zip、mariadb_test.z01、mariadb_test.z02)再合成为full.zip
ln -s a b:创建软连接b,指向a
'fhqqqq'.rstrip('q')=>去掉结尾的qqq
Path('路径').rglob('*'):列出路径中的所有文件夹+子文件
head -n 10 文件:显示前10行,-c显示前10字节
os.path.relpath('D:\\source code\\SR\\experiments\\S', 'D:\\source code\\SR') # 第一个参数去掉第二个参数,输出 'experiments\\S'
os.getcwd() :返回当前工作目录
ctrl+alt+l:pycharm自动格式化
netstat -npl | grep "8889":查看8889端口占用的进程
apicloud studio:网站控制台创建应用,选择native app,取消avm.js,studio导入-从云端检出,导入到本地,弄完项目后右键实时预览,打开手机上的apploader,通过二维码连接上项目,右键wifi真机实时预览,手机上就能看到预览了。通过git同步到控制台,然后点云编译,下载app,可以更多人看到了。
json.dump(字典, 文件对象):把字典写到文件中去
torchrun能实现分布式训练,rank 0是第一个进程或者主进程,其它进程分别具有1,2,3不同rank号,是绝对号,local_rank指在一个node上进程的相对序号,nnodes指物理节点(机器)数量, nproc_per_node指每个物理节点上面开多少进程,其中默认每个进程占一块GPU,因此local_rank可以当作GPU号
$变量:将变量内容视为命令并执行
2.6B=26亿
$#:传入参数的个数
conda create -n B --clone A:A环境复制给B环境
pip install -U:如果已安装就升级到最新版
tensor.to('cuda:6'):指定放到第6块gpu上
bash ...sh:运行脚本
model.load_state_dict:加上false,则不管训练好的参数有没有完全匹配,都能加载进来
p = Process( target=read, args=(a,b) ):新建1个进程,当p.start()时,会执行read,args是给read传递的参数
multiprocessing.Queue(10):建立1个队列,各个进程可以往里面放put东西或者拿get东西,满足多进程对它可读可写,注意无法进行多进程调试!
q.get_nowait ():直接使用get (),如果此时队列中没有元素,那么会阻塞等待,使用get_nowait ()后,如果队列中没有元素,那么会报错
json.loads()将str类型的数据转换为dict类型
readline() 读取整行,包括 “\n” 字符。
readlines(),读取所有行,存储在一个list中
re.sub('正则表达式', 'aaa', s):对字符串s,把正则表达式所匹配的所有结果用"aaa"替换掉
re.match(正则表达式,s):对字符串s,只返回第1个匹配对象,用.group()获取
re.findall(正则表达式,s):对字符串s,返回所有匹配对象
re.finditer(正则表达式,s):返回所有匹配对象的索引,需要遍历并用i.span() 得到
jsonl的每行是一个字典
json.dump(字典,文件对象,ensure_ascii=False):往文件写1个字典
open('w'):覆盖写,'a'追加
wc -l 文件:统计文件行数
json.dumps(东西):将任何东西(一般是字典)转字符串
文件对象.write(字符串):往文件里面写入字符串
rm -rf `ls | grep "pycharm"`:先执行``里面的命令
lxml 负责解析html内容,此时可以代替正则:
from lxml import etree html = etree.HTML(test) # test含有html标签,如<p> p = html.xpath('//p') # 获取所有的p标签
p = html.xpath('//p/text()') # 获取所有的p标签的内容 p = html.xpath('/html/body/p') # 顺着节点找到p标签 p = html.xpath('/html/body/p/@href') # 获取p标签中的href属性值 a = html.xpath('/html/body/a/text()') # 获取所有a标签的文本内容 p = html.xpath('/html/body/p[@class="p1"]/text()') # 获取p标签中class属性为p1的标签的文本内容
<p>A<a>B</a>C</p>:p的Element.text 能获得A, a的Element.text 能获得B , a的Element.tail能获得C
python3默认用unicode编码,\u则代表unicode编码,可以通过print解析,utf8是可变长的编码,一般用在文件存储或网络传输
查看内存:cat /proc/meminfo
torch.masked_fill(a, mask, -1):把a中的对应位置的 mask为1的元素置为-1
pickle.dumps(字典):将字典序列化(转为二进制)
struct.pack("I", 22):将22序列化
占位符,返回Tensor 类型:tf.placeholder(tf.float32, [3, None]):类型是float32,行数3,列数不定
tf.constant(1):值为1 的常量
tf.variable_scope('scopename') # 所有变量都在范围 scopename 内
tf 中的 LSTM:

batch_size = 2 cell = tf.nn.rnn_cell.BasicLSTMCell(num_units=10) # 每个单词词向量映射到10维 zero_state = cell.zero_state(batch_size, dtype=tf.float32) x_length = [3, 1] # 第一个样本实际有3个单词,第二个样本实际有1个单词(另外2个是pad的),这样输入的 pad 部分不参与LSTM的计算 a = tf.random_normal([batch_size, 3, 4]) # 一个样本有3个(step=3)单词,每个单词4维度 out, (state_fw, state_bw) = tf.nn.dynamic_rnn( # out:所有单词的输出向量 [batch_size, 3, 10],最后一个时间步(最后那个单词)的输出向量 c [batch_size, 10],最后一个时间步(最后那个单词)的输出 h [batch_size, 10],h=out的最后1个单词的输出向量 cell=cell, initial_state=zero_state, sequence_length=x_length, inputs=a )
(output_fw, output_bw),(output_state_fw, output_state_bw) = tf.nn.bidirectional_dynamic_rnn(cell_fw=cell, cell_bw=cell, dtype=tf.float64,
sequence_length=X_lengths, inputs=X)
(output_fw, output_bw)分别代表前向LSTM和后向LSTM,形状都是[batch_size,max_len,hiddens_num]
(output_state_fw, output_state_bw)分别代表前向LSTM和后向LSTM,由(c,h)组成,output_state_fw的h = output_fw的最后一个单词的输出向量,output_state_bw的h = output_bw的第一个单词的输出向量
tensorflow提供BahdanauAttention 注意力机制,输入1个序列(n个词向量)和1个向量q,首先将序列的所有词向量通过全连接层映射到给定维度(比如1024),将向量q通过另一个全连接层映射到1024维度q',然后将q'分别加到序列的每个向量上(交互),再通过tanh,然后将每个词向量映射到1个数,这n个数通过softmax,得到序列的每个词向量对应的权重,序列的每个最开始的词向量*对应权重再相加,得到最后的1个输出向量,另一个版本的注意力机制很简单:只接受1个序列,对序列的每个词向量分别映射再经过softmax得到每个词的权重,然后词向量按权相加
tensorboard:激活环境之后,输入tensorboard --logdir D:\logs,后面这个目录是图标存放的目录
from torch.utils.tensorboard import SummaryWriter w=SummaryWriter("D:\logs") for i in range(100): w.add_scalar("y=2x",2*i,i) # 针对标题为"y=2x"的图表画一个点,横坐标(step)是i,纵坐标(value)是2*i w.close()
如果服务器运行tensorboard服务,要在本地的浏览器打开:
服务器上运行tensorboard服务,并指定tensorboard要读的服务器地址,和服务器的端口:tensorboard --logdir /yinxr/ldp --port=8091 cmd中运行:ssh root@10.31.118.166 -p 31079 -L 8090:127.0.0.1:8091,前面的root@10.31.118.166 -p 31079是服务器的登录方式,8090:127.0.0.1:8091,是把远程的8091端口映射到本地的8090端口 浏览器打开:http://localhost:8090/
bash test.sh a b c:$# 是参数的个数,为3,$0是test.sh,$1是a
shift+上:linux界面向上翻看
os.system(linux命令):执行linux命令
rm -rf `ls | grep "a"`:匹配删除
cp -r wen/ /yinxr/ldp/newresults/tmp:创建tmp,复制文件夹wen,文件夹的名字改为tmp
s.rfind(substr):在s中找到 substr 最后一次出现的位置,如果没有则返回-1
try: ... except IndexError as ie: # 捕获越界异常 ... except StopIteration as se: # 捕获遍历完了的异常 ...
Exception:是捕获各种异常
conda install ..:安装的包可以被各种虚拟环境使用
cuda是工作台,cudnn是工作台上的工具(基于cuda的深度学习GPU加速库)
开多个vpn会降低速度
os.makedirs(path):创建多级目录
$RANDOM:随机数
引用当前目录下的a.py(模块)中的class A:import a; a.A()
app包(目录+__init__.py)下有模块A.py,里面定义了class B,如果要引用B:
import app.A as q a = q.B()
或者:
from app import A
a = A.B()
__init__.py:import后会自动执行,初始化的作用。
__init__.py:__all__ = ["A","C"],从别的文件 import * 的时候,就只能引入模块A和模块C(import * 只会看__all__里面有什么就导入什么):
from app import * C.C()
点击某个文件夹a 右键 Mark Directory As Sources root 之后:当前目前就设置为 文件夹a
watch nvidia-smi:动态打印
pycharm远程终端:“Tools”->“Start SSH session...”
Path(p).mkdir(parents=True, exist_ok=True):在linux上建立目录p,若存在,则不管了
from functools import partial
borrowPenFromWangwu=partial(borrow,student2="王五"):partial 返回:固定了参数student2="王五" 的 borrow 函数
borrowPenFromWangwu("李四"):返回“李四找王五借了一只铅笔!”
tensor1.type_as(tensor2):将tensor1的类型转为tensor2的类型
torch.triu(a):保留右上对角线(包括)的元素,其他位置置为0
tensor.max():所有元素的最大值
self.register_buffer('aa', torch.Tensor([123, 2, 5])):注册一个属性aa,该值是torch.Tensor([123, 2, 5])
tensor.type(dtype):tensor转为指定类型
torch.as_tensor(data):根据data,生成 tensor 类型
b = nn.Identity()(a):b永远==a,如果后面 a 又变了,则b也变
混合精度训练能节约内存,且速度更快
rearrange(tensor, 'b (h w) c -> b c h w', h=14, w=14):将tensor的shape(64,196,768)从原来的b (h w) c 变到 b c h w,其中h,w都是14,即64,768,14,14
F.normalize(tensor, p = 2, dim = -1):针对最后一维求向量长度(平方和再开根号),然后每个数除以长度
torch.randperm(10):将0~n-1(包括0和n-1)随机打乱后获得的数字序列,tensor([2, 3, 6, 7, 8, 9, 1, 5, 0, 4])
tenror.t():转置
@:矩阵乘法
torch.bincount(a):0在a中出现了多少次,1在a中出现了多少次,...
reversed(range(10)):反转列表
torch.cumprod(torch.tensor([2,1,4]),0):累积乘法,[2, 2*1 , 2*1*4]
tensor.new_zeros(size):返回size大小的全零向量,并且与 tensor 的 torch.dtype 和torch.device一致
若把 a.detach()提供给 loss ,则提供了一个requires_grad=False 的Tensor,loss就不对该 tensor 求导了,所以就不会更新 a 的数值了;
新建 torch.tensor 的时候,默认 它的 requires_grad = False
map(函数f, [1,2,3,4,5]):把list里面的元素分别通过f,所有运算的结果放到1个迭代器里面
dict1.update(dict2) :如果dict1己包含dict2对应的键值对,那么原 value 会被覆盖;如果不包含,则该键值对被添加进 dict1 去。
np.prod(a):返回指定轴上的所有数的乘积,不指定轴默认是所有元素的乘积
数值法求解常微分方程组:
import matplotlib.pyplot as plt from scipy.integrate import solve_ivp import numpy as np # 定义dx/dt = [t] def fun(t, x): dxdt = [t] return dxdt # 初始条件:x(t=0)=2 x0 = [2] # 数值法来求解常微分方程(组),t的范围在(0,10) yy = solve_ivp(fun, (0, 10), x0, rtol=1e-05,atol=1e-05,method='RK45',t_eval = np.arange(1,10,1)) t = yy.t # t的范围在(0,10) data = yy.y # x(t)在(0,10)的对应取值,按列分布 plt.plot(t, data[0, :]) # 此处的x(t)就是1个数值,不是向量,所以data用0 plt.xlabel("t") plt.legend(["x"]) plt.show()

LambdaLR


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人