
对话
1、对话系统
分为闲聊型对话系统(chit-chat dialogue)和任务型对话系统(task-oriented dialogue systems)
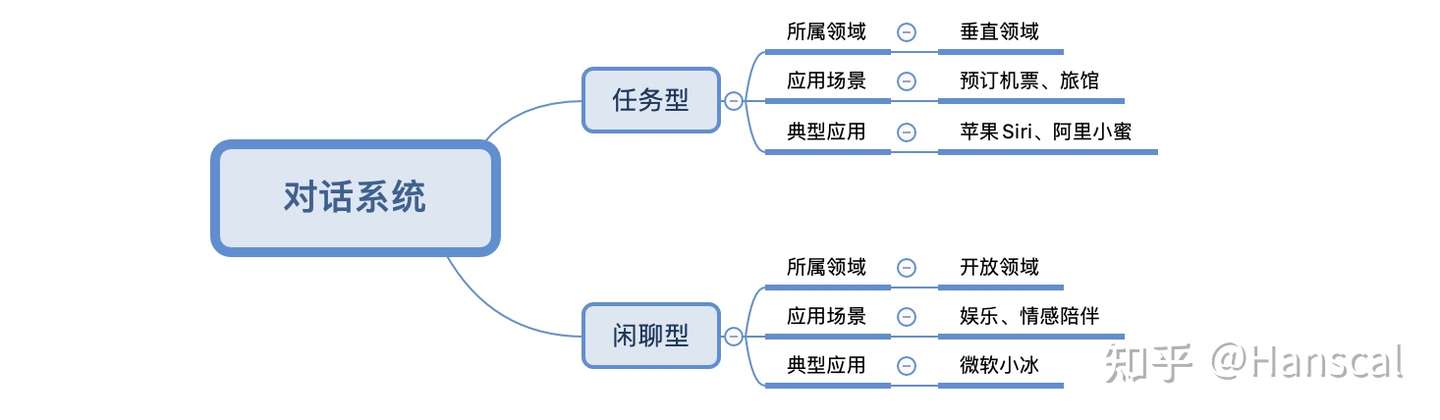
2、闲聊型
分为:检索式聊天,规则式聊天,生成式聊天
检索式聊天,选出所有回复中最合适作为回复的选项
规则式聊天:
总框架: 文本问题输入一个大的知识图谱,在KG中,每个场景(如黑牛)对应1个节点,每条边对应一个扩展问(如是什么),属于一个标准问意图(什么产品),DM先确定场景(节点),然后意图识别(采用规则+模型)匹配对应的边(扩展问),然后命中答案(回复),KG输出答案给TTS

一句话有1个意图(如果不细分,意图=领域,如果细分了,领域下有多个意图),意图有多种可能的标签:如订外卖、订酒店、订旅游门票、订电影票、订机票等类别。意图识别的方法有规则匹配(每个意图值有一个用正则编写的意图模板,先将用户的输入语句进行分词、词性标注、命名实体识别、依存句法分析、语义分析等操作后,看看和哪个意图模板最匹配,就认为属于哪个意图,该方法精确率较高,但是召回率较低,需要大量人工参与制定规则模板,不易自动化,更难以将其移植),模型识别,模型识别通常采用QQ匹配,语料库中的每个Q都有标注好的所属意图,流程一般为召回(比如用es找出最匹配的前30个query)、表示型文本匹配模型DSSM(能提前计算库中的语义向量,这样在线上就只需要对 query 进行计算语义向量就行了,然后使用向量索引工具进行召回)、交互式文本匹配模型(如MRPC任务,性能更强,但更慢),这样3层叠加可以逐层加强语义层面的识别。其中DSSM是双塔结构,输入是用户问题和候选query,经过embedding、再经过CNN、RNN、FCN的组合/或者直接求词向量平均(fasttext)等,分别得到2个句子的语义向量,然后计算相似度作为输出:
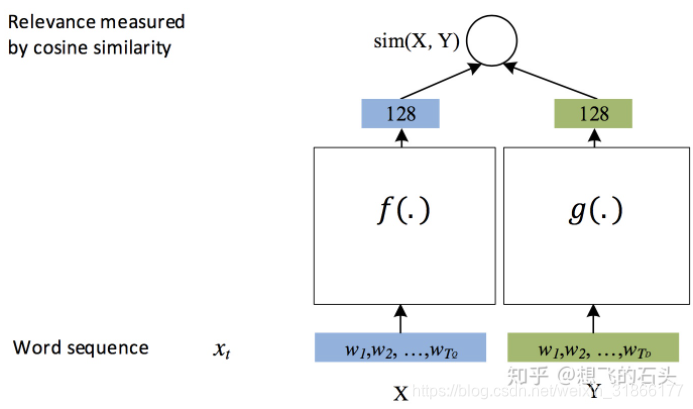
双塔结构能直接应用负采样方式计算损失函数,假定正样本(X1,Y1)通过模型后的结果是h1,负样本(X1,Y2)、(X1,Y3)通过模型后的结果为h2,h3
方式1:h1,h2,h3通过softmax得到三个概率值,然后极大似然法(等价于损失函数最小)使得h1(1-h2)(1-h3)最大,梯度下降求对应的参数
方式2:模型输出层加一个sigmoid层,这样直接得到h1',h2',h3',然后使得h1'(1-h2')(1-h3')最大
意图识别的难点
虽然说意图识别就是文本分类,但是和文本分类还是有点区别的,这个区别造就了它更“难一些”,主要难点如下:
-
输入不规范:错别字、堆砌关键词、非标准自然语言;
-
多意图:输入的语句信息量太少造成意图不明确,且有歧义。比如输入仙剑奇侠传,那么是想获得游戏下载、电视剧、电影、音乐还是小说下载呢;
-
意图强度:输入的语句好像即属于A意图,又属于B意图,每个意图的的得分都不高;
-
时效性:用户的意图是有较强时效性的,用户在不同时间节点的相同的query可能是属于不同意图的,比如query为“战狼”,在当前时间节点可能是想在线观看战狼1或者战狼2,而如果是在战狼3开拍的时间节点搜的话,可能很大概率是想了解战狼3的一些相关新闻了。
每个意图对应1个语义槽,有的语义槽就是一句话,则答案返回这句话就行(如实习项目),这种意图用来回答一些常见问题,如什么平台,有的语义槽是一个槽位模板,用于回答一些负复杂的任务型问题,比如用户的话是“订一张今天下午场次的战狼电影票”,识别出是“订电影票”的意图,该意图的语义槽为:

先根据序列标注(电影名是“战狼”,时间是“今天下午”)来填空,注意序列标注任务比NER识别的更细致:

剩下的空根据槽位预测(根据用户当前的位置,将其预测为XX影院或YY影院)来填空
针对没办法预测的槽位,预测到槽位值不唯一,识别到的槽位存在歧义的问题,则就使用该槽位事先预定义好的话术去“发问”,直到语义槽的空都明确下来,然后进入DM中利用知识库回答用户问题或者完成某种操作
生成式聊天,主要解决长尾query的应答。它应答的范围比较广,但最大的问题就是生成的内容不可控,容易产生一些安全性的问题
生成式聊天的挑战:

流程:
当Q出现之后,首先我们会去判断这是否是首轮。如果是首轮,我们会优先用检索去应答。如果检索没有生成答案的话,我们就用规则去应答。如果规则没有答案,我们就会用生成式应答。如果不是首轮,我们就会去判断它是不是上下文相关的。如果上下文不相关的话,我们认为它还是一个独立的Q,那么我们还是像首轮一样处理。如果它是上下文相关的,那么我们优先会用生成式去答。在输入到生成式之前,Q需要通过安全检测,而且生成式返回的答案也得通过安全检测才能返回给用户
生成式模型:端到端方法
【RNN-based seq2seq,2014】
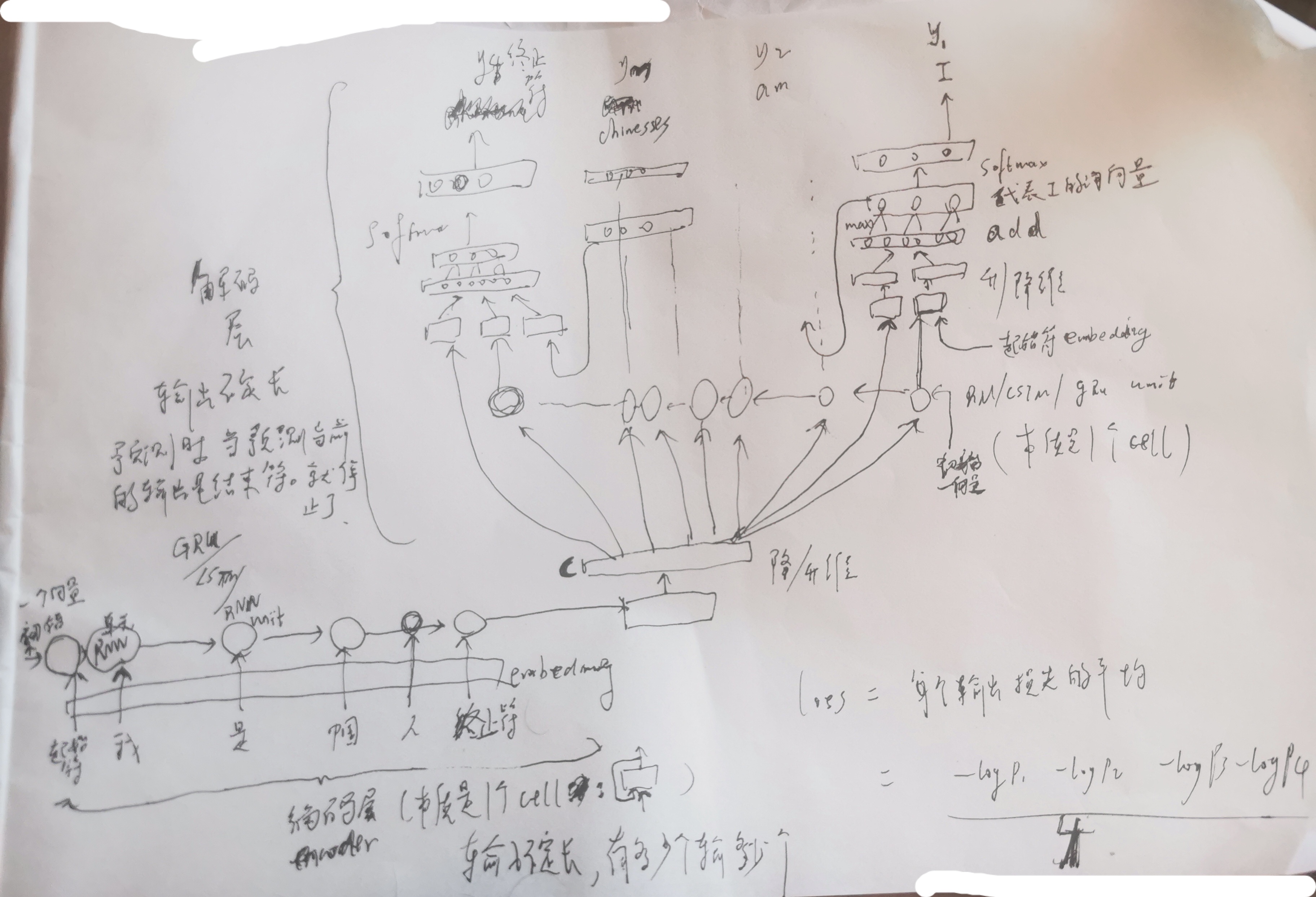
【rnn seq2seq+Attention,2015】

【tensor2tensor,2017,谷歌】
就是采用了Transformer结构的encoder+decoder,经典的聊天机器人如Google Menna、Facebook的Blender均采用这种结构
【GPT系列】
见m2,目前最先进的是DialoGPT,基于GPT2开发
【Unilm模型,2019年,微软】
ELMo模型学习两个单向语言模型(left-to-right LM,right-to-left LM);GPT学习到的是left-to-right LM,是单向解码模型,可以跑在长文本生成任务上;BERT学到的是bidirectional(双向) LM,双向编码编码模型,可以跑在GLUE基准数据集(包含9项NLU任务)、抽取式QA(答案在原文本中),虽然BERT模型已经显著地提高了大量自然语言理解任务NLU的效果,但是由于它需要获取上下文信息使得很难应用于自然语言生成任务NLG;UniLM集大成,能学到left-to-right LM,right-to-left LM,bidirectional LM,还有seq2seq LM,此处的seq2seq LM是一个基于双向编码的单向解码模型,seq2seq LM可以跑在生成式摘要(abstractive summarization)任务(摘要是根据文档由机器生成的)、生成式QA、Question Generation任务(根据文档生成问题)。
UniLM模型的框架和tensor2tensor一致,但训练方式不同。在预训练阶段,UniLM模型在三种语言模型的场景下训练(双向语言模型,单向语言模型和序列到序列语言模型),去共同优化同一个Transformer网络,而且对于这三种语言模型使用了不同的segment embedding(双向对应0和1;单向left-right对应2;单向right-left对应3;序列对应4和5),输入也有位置向量和词向量:
单向语言模型:输入是一个单独的本文。模型分为从左到右和从右向左两种,从左到右,即仅通过被掩蔽token的左侧所有本文来预测被掩蔽的token;从右到左,则是仅通过被掩蔽token的右侧所有本文来预测被掩蔽的token。具体操作,是使用一个上三角矩阵来作为掩码矩阵,即self attention mask矩阵,该矩阵的 表示遮盖 ,0表示模型能看见。
序列到序列语言模型:输入是一个文本pair对。如果被掩蔽token在第一个文本序列中,那么仅可以使用第一个文本序列中所有token,不能使用第二个文本序列的任何信息;如果被掩蔽token在第二个文本序列中,那么使用第一个文本序列中所有token和第二个文本序列中被掩蔽token的左侧所有token预测被掩蔽token。例如,我们预测序列 中的【mask1】时,除去【SOS】和【EOS】,我们仅可以利用
、
、
和它自身进行编码;预测【mask2】时除去【SOS】和【EOS】,我们仅可以利用
、
、
、
、
、
和它自身进行编码。
在模型预训练过程中,在一个训练batch中,使用1/3的数据进行双向语言模型优化,1/3的数据进行序列到序列语言模型优化,1/6的数据进行从左向右的单向语言模型优化,1/6的数据进行从右向左的单向语言模型优化。
总结一下,就是对于不同的语言模型,我们可以仅改变self-attention mask,就可以完成联合训练。 通过不同任务,去优化同一分模型参数,在不同任务中,模型参数是共享的。百度的plato系列是基于这种模型结构进行优化。plato2目前被市场广泛使用,plato2在训练的时候,先通过1v1训练,对相同context的多个答案进行随机抽取,抽取出一个答案来进行训练,这样的话就降低了整个学习的难度,再1vn训练,这样能实现给机器相同的问题,能输出不重复的答案
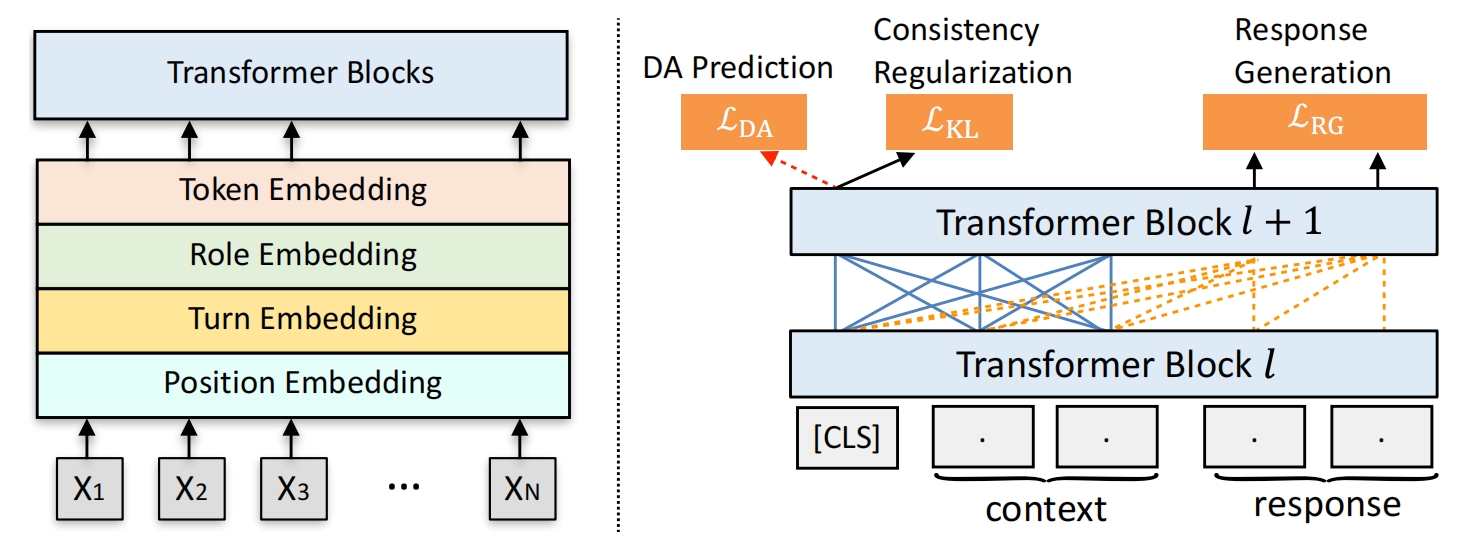
Unilm用对话生成系统,分为2个阶段,预训练+微调,模型结构:
预训练(就是在一些任务上训练,训练好的模型供后面任务使用):
用2个数据集,unida,undial ,unida的1个样本是1个对话,src是开始连续的几句,tgt是对话末尾且由系统发出,act是tgt要做哪些动作,可以是多个动作,act_list是act的索引:
{"ID": "msre2e-mov-1090", "turn_id": 3, "src": ["i need to request 3 tickets for gods of egypt tomorrow night in orlando.", "would you prefer to see it in standard or 3d format?", "standard.", "there is a 7:00pm 10:10pm showing at the fashion square premiere cinema 14 3201 e. colonial drive, orlando, fl 32803, would one of those work for you?", "10:10pm", "i have purchased your tickets. thank you and enjoy the show.", "thanks."], "tgt": "have a wonderful day!", "act": ["bye"], "act_list": [6]}
undial 的1个样本也是1个对话,src是开始连续的几句,tgt是对话末尾且由系统发出:
{"src": ["Hi! I need to return an item, can you help me with that?", "sure, may I have your name please?", "Crystal Minh"], "tgt": "thanks, may I ask the reason for the return?"}
先处理数据集 unida,undial,每个对话经过分词以及 id映射 且给句子加入起始符和结束符,并对对话的句子数,每个句子的单词数做了限制,act_list 转成one-hot向量 act,act[i]==1 表示该 tgt 发生了第 i 个动作,tag:0 表示该对话来自 unida;tag:1 表示该对话来自 undial,最终1个对话的格式为:{"src": src, "tgt": tgt, "act": act_one_hot, "tag": tag}
数据再处理:
src的1个对话里面 的所有句子组成1个大句子作为 src_token,其中长度向batch里面最长的大句子长度用pad 0 看齐;
src的1个对话的大句子的每个单词是否不来自 pad 作为 src_mask;
src的1个对话的大句子中每个词相对于自己所在小句子的位置作为 src_pos,其中小句子句首单词的位置是0;
src的1个对话的大句子中每个单词是机器的回复还是人的回复,这里假定对话是机器和人一人一句,且对话最下面是人说的话,且人记为 1,机器记为 0 作为 src_type
src的1个对话的大句子中每个单词所属的小句子序号,这里假定对话里面最下面的句子序号是1,再往上是2... 作为 src_turn
1个对话的 tgt 的文本作为 tgt_token;
1个对话的 tgt 的每个单词是否不来自 pad:tgt_mask;
1个对话的 tgt 的每个单词相对tgt的位置作为 tgt_pos;
1个对话的 tgt 的每个单词每个单词是机器的回复还是人的回复(这里 tgt 都是机器 0 说的话 )作为 tgt_type;
1个对话的 tgt 的每个单词所属的小句子序号,此处 tgt 的句子序号为0:tgt_turn;
1个对话的 act(DA) 信息 作为act_index;
1个对话的 tag 信息作为 tag ;
模型输入:
1个对话的 src_token(id形式) 作为 unilm 的context,tgt_token (id形式) 作为response,其中tgt_token要去除最后1一个单词
单词embeding:单词的 src_token 、src_pos 、src_type、src_turn 分别映射成768维度向量,4个向量相加,再通过 ln,最左边加一个cls token向量(该向量初始化为768维向量且通过了ln),见上图左边;
用 mask 构造 unilm 图中的蓝线和虚线:在注意力机制中,计算context的每个单词的 v 向量时,context 的每个(非pad)单词都会考虑到(有权重),response 的单词不会有贡献(单词权重为0),在计算 response 的第1个词的v向量时,context的非pad单词对它有贡献,和它自己的贡献,它后面的单词不会对它有贡献,即 response 的这个单词之前的都对它有贡献,该机制用 mask 表示:若 mask[i][j]=0 ,则计算第 i 个token的v向量时,第j个token是有贡献的,若mask[i][j]=1 ,则计算第 i 个token的v向量时,第 j 个token是不贡献的
然后通过 uniLM 10 层 的 TransformerBlock:1个TransformerBlock的组成:mask 注意力层(把gpt2的masked self attention 的mask换一下就行),ffnn,drop,add&normalize(add注意力层前),ffnn+gelu+dropout+ffnn+dropout,add&normalize(add 前一个add&normalize的输出)
DA Prediction任务:cls对应的向量映射到20维度+sigmoid,表示该对话中,预测每个动作发生的概率(动作与动作之间独立,是多标签分类问题),与标签计算动作交叉熵损失Lda,其中该对话得来自unida
response generation任务:传入 response 对应的向量,每个词向量映射到30522维度的字典向量+softmax,得到每个词对应的字典概率向量, 由于 tgt_token 是除去最后1一个单词的,label是去掉第一个词的,所以进行错位预测,tgt_token 的1个token预测的词要是挨着该token后的1个token,得到回复生成1个词(非pad)的平均交叉熵损失 Lrg
Consistency Regularization任务:用于确定模型稳定性:同1个样本输入2次到模型得到2个结果,这两个结果应该尽可能一样,此处的结果是该对话的动作概率分布,两个分布用q和p表示,用KL散度衡量分布损失,损失Lkl就是=0.5*(KL(q,p)+KL(p,q)),由于不知道是否来自哪个数据集,最后再乘以ood(异常样本)分数,ood分数用于衡量该对话(样本)是ood的可能性(0-1),ood分数越小,越是 ood,此处无标注(没有动作标签)的数据就是ood样本,此处即UnDial数据集,意在把异常样本(UnDial样本)剔除掉,ood分数计算方式:根据该样本(对话)内的数据(动作概率分布)计算 ood分数g, 即
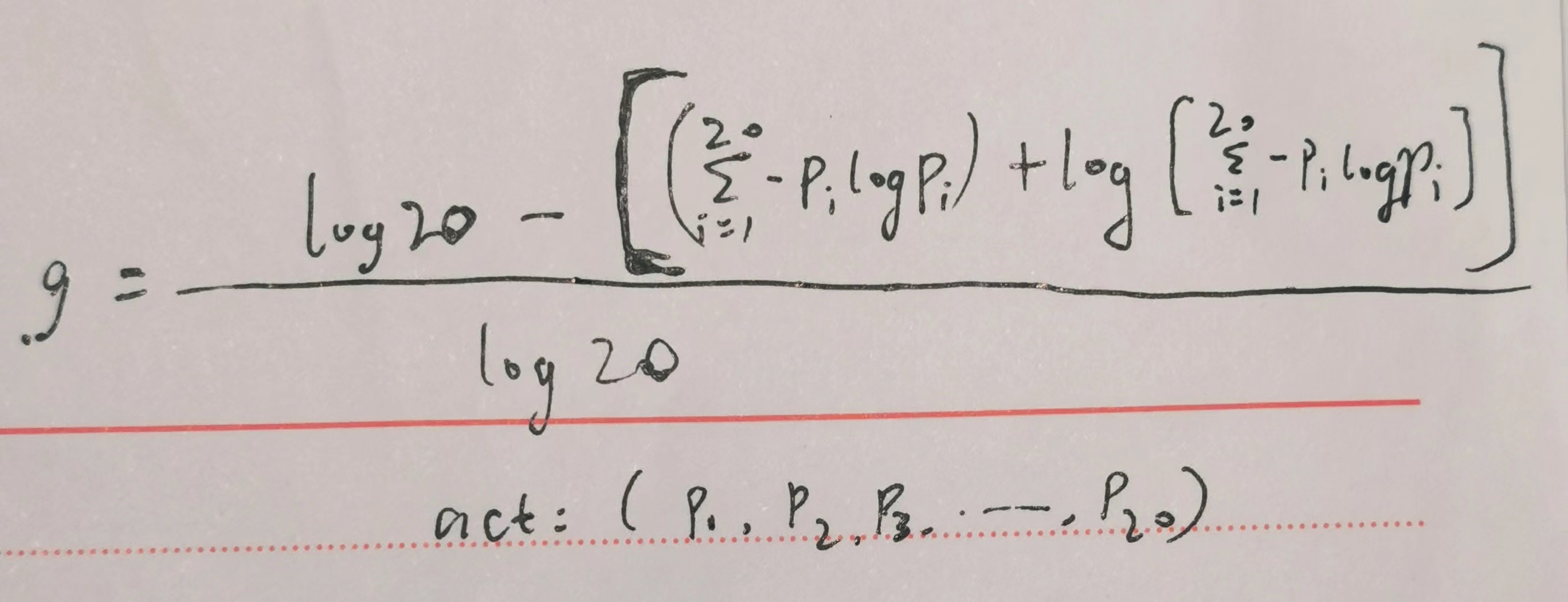
总损失 = Lrg + Lda + Lkl * 5,作为预训练的半监督(有监督+无监督)损失,因为在有监督损失中加入了无监督的Lkl,Lkl不是由标签构造来的。此处没有论文的 Lrs,自监督是数据本身含有标签,如对话生成。
Fine-tuning(使用预训练好的模型继续训练):
训练:
使用multiwoz2.0数据集,multiwoz2.0 涉及多个领域(Attraction, Hospital, Police, Hotel, Restaurant, Taxi, Train, general)的对话,1个dial_id是1个完整对话,该对话中:
"goal": 该对话的信息,info,book是成功的信息,加上fail就是失败的信息
"log": 该对话的具体对话内容,log的1个元素是1个turn:user的话+sys的话,把话的槽位值用槽位名替换掉变为 user_delex 和 resp(delexicalized responses),turn_num 是该轮的轮编号,turn_domain 是该轮所属的领域,unified_act:该轮对话sys的动作 ,constraint:user的话中出现的slot,格式:[领域] slotname1 slotvalue1 slotvalue2 ... slotname2 slotvalue1 slotvalue2;pointer:预订状态,若后两位是: [0, 1],book_success,即预订成功;[1, 0]:book_fail,即预订失败;[0, 0]:book_nores,即还没有预订结果;unified_act:该轮的sys在20个动作中做了哪些动作,和unida 的 actlist 一样;sys_act:sys 的话中出现的 slot,[领域] [slotname1] slotvalue1 slotvalue2 [slotname2] slotvalue1
数据处理:
user:user 分词与 id 映射
resp:resp 分词与 id 映射
aspn:sys_act 分词与 id 映射
bspn(会话状态belief states):constraint 分词与 id 映射
db:根据constraint的所有slot(比如某个旅馆的所有slot是 pricerange:cheap,type:hotel)去对应的旅店数据库(保存了所有旅店的详细信息)做匹配查找,slot全部都满足的旅店筛出来,筛选了n个,则是 db_n,还有 pointer 预订状态,所以可能是:起始符 db_n book_nores 终止符,然后再分词与 id 映射
act:unified_act
1个对话的1轮:user作为 src,act作为act, bspn+db+aspn+resp 作为 tgt
src 作为 src_token;
src的每个单词是否不来自 pad 作为 src_mask;
src的每个词相对于自己所在的位置作为 src_pos;
src的每个单词是机器的回复还是人的回复,这里是user,所以是1,作为 src_type
src的每个单词所属的句子序号,这里只有1句,则是1,作为 src_turn
tgt 作为 tgt_token;
tgt 的每个单词是否不来自 pad:tgt_mask;
tgt 的每个单词的位置作为 tgt_pos;
tgt 的每个单词是机器的回复还是人的回复(这里 tgt 都是机器 0 说的话 )作为 tgt_type;
tgt 的每个单词所属的句子序号,此处 tgt 的句子序号为0:tgt_turn;
act(DA) 信息 作为act_index;
src作为模型的context,tgt作为模型的response,按照预训练的 DA Prediction任务,response generation任务进行训练
预测(多轮回复生成):
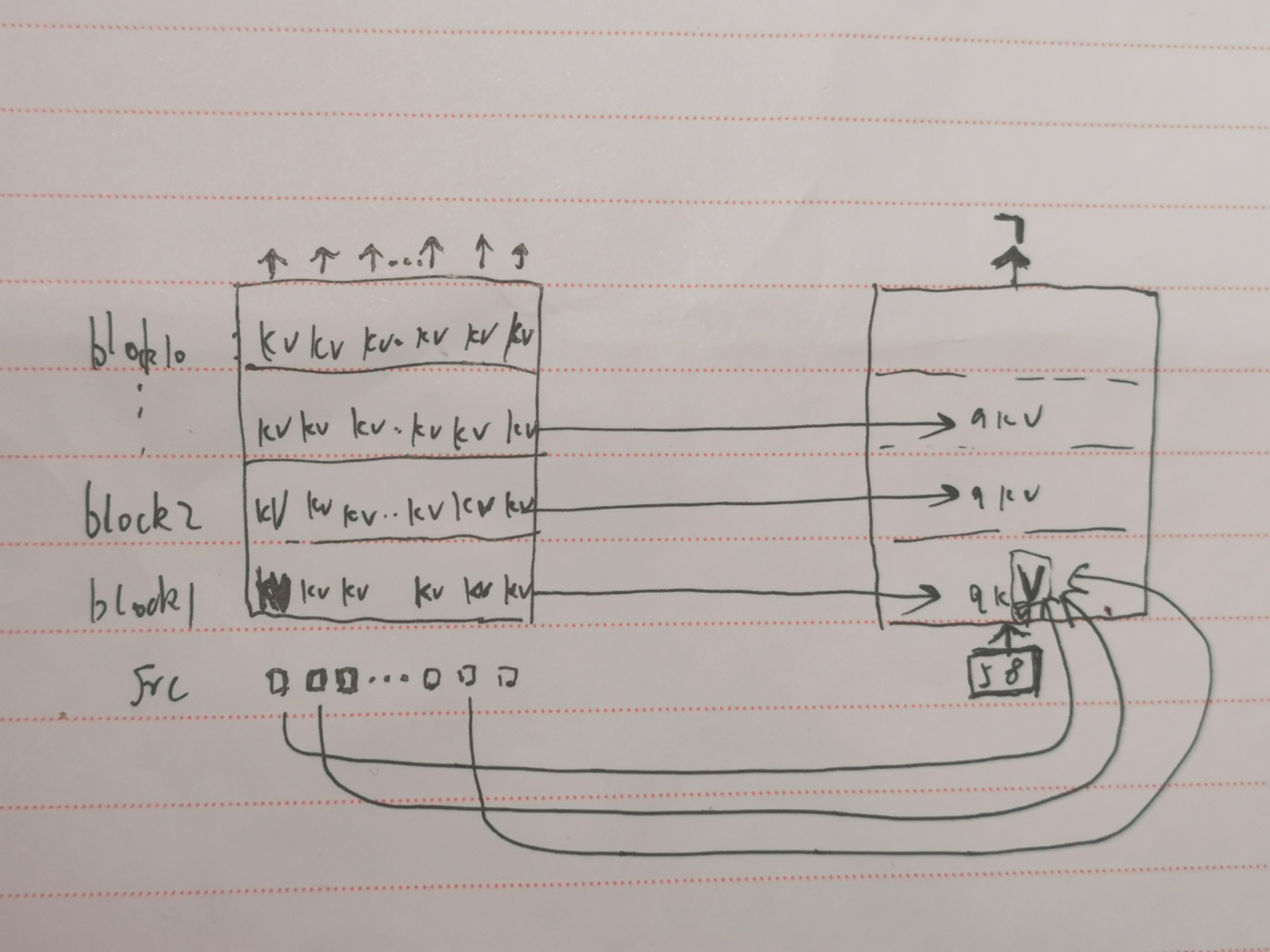
第1轮回复的第1个词 7 的生成:
src:1个对话的1轮的 src_token,src_mask,src_pos,src_type,src_turn,输入到模型中,此时全是蓝线,相当于Transformer encoder,得到 src 每个token的每层TransformerBlock的k向量和v向量,tgt 的起始符词 58 单独输入到模型中,只不过每层注意力机制都要前面计算好的k,v向量,和自己的v向量来加权产生自己的 v 向量,前面的k,v向量是已经算好的,然后模型最后的输出再映射到词典向量,推出词 7:
第1轮回复的第2个词 7688 的生成,将新预测的词 7 输入模型,注意力机制用到将前一个词 58 的k,v和前面src的k,v(静态的),和自己的v做加权求出自己的v向量,然后预测出新词 7688:
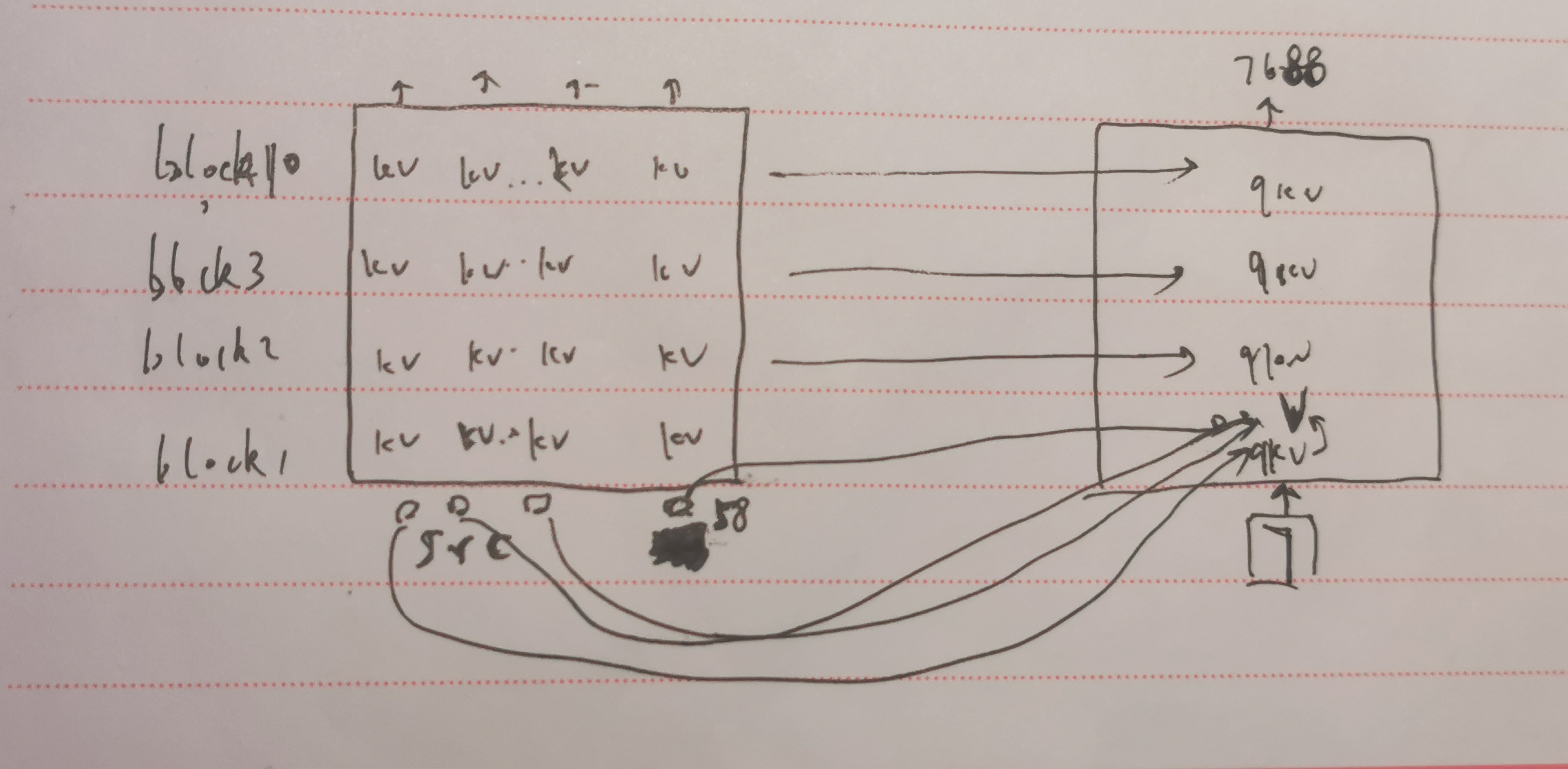
.......
由此预测出第一句回复:58 7 7688 ... 0 0 0,去掉0,得到 58 7 7688 ... 52,将其解码为bspn,即识别出user话中的所有 slot,根据 slot 取数据库中查找,将匹配的结果(比如查到了 n 条数据,则是 db_n),构成db(代码里面还结合了预订状态:正在预定?预订成功?预定失败?我感觉没必要),将 src bspn db 输入到模型(src先进去,然后 bspn 和 db 一个词一个词的进去,算v向量的时候依然还要用到前面的静态 kv),然后输入aspn的起始符 59 到模型中,用到前面 src bspn db 的k,v,逐词生成 aspn 和 resp,其中都要用到前面词的静态k,v,每次生成1个k,v就存起来以便后面的使用。所以第一句回复就是 bspn db aspn resp
第2句回复生成:把 第1轮的src1 + 第1轮的回复 bspn db aspn resp + 第2轮用户说的 src2,作为新的 src,同理生成第2轮回复的 bspn db aspn resp
直到用户不说话,则停止回复生成。
评测:根据系统生成的回复和原始回复进行对比,计算 bleu,success,match, 最后分数 = 0.5 * (success + match) + bleu
该模型的 few shot ability 不错:仅需要少量数据训练,就能学习的不错了
【DGMML,2022北大博士毕业论文】
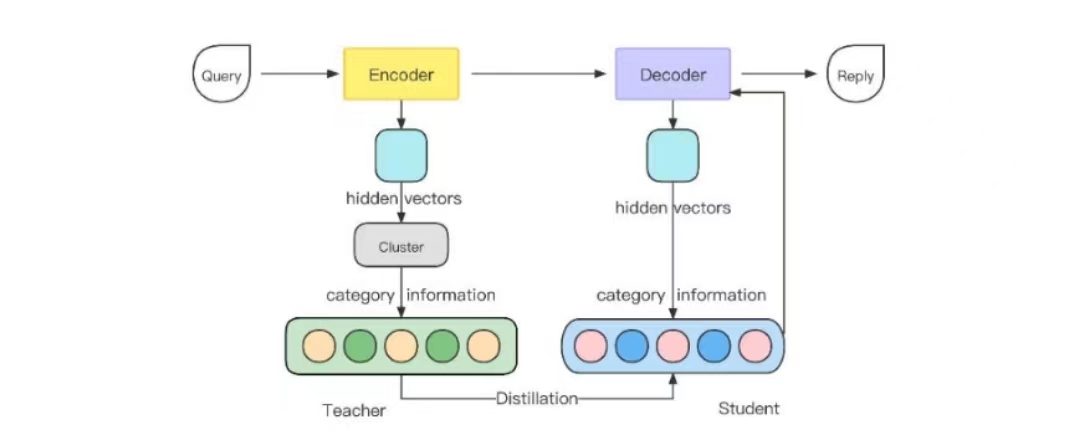
encoder-decoder架构(3选一):rnn seq2seq+attention,CVAE(条件变分自编码器),tensor2tensor,该损失记Lce
又通过蒸馏(将问题的聚类知识蒸馏给回复)来定义了2个损失Ldd,Ln-pair-center
损失Ldd:
假定问题可以划分为k类,将encoder输出的batch里面的每个问题隐向量h(对应一个问题)按照Kmeans分为k类,此时所有(问题,回复)对都被划分为k类了
类内的所有隐向量均值作为该类的问题中心向量,类内所有回复向量(对应问题的解码器输出)的均值作为该类的回复中心向量
2个类间的问题距离=两个类的问题中心向量的距离,2个类间的回复距离=两个类的回复中心向量的距离
目标是让所有可能的类间的问题距离分布(通过softmax)和所有可能的类间的回复距离分布(通过softmax)一致,比如a问题和b问题的意思差老远(向量距离很远),那么a的回复和b的回复的意思也差老远(向量距离很远),即KL散度要小,所以该损失是两个分布的KL散度

损失Ln-pair-center:
Ln-pair-center=所有(问题,回复)对的平均损失,其中vi:当前问题的回复向量,uri:第i类的回复中心向量

该损失越小,那么处于同一类的问题的回复向量越相似
总体的模型损失就是Lce+Ldd+Ln-pair-center,模型用的数据集是医学数据集,评测指标采用BLEU,生成回复向量和真实回复向量的相似度,entropy-based metrics(衡量回复的多样性)以及人工评测,该模型与3个baseline模型进行了对比:
S2SA-MMI:最大似然函数-log(p(生成的句子))做为新的似然函数,以此来尽可能减少产生“我不知道”这样高频的句子,P(生成的句子)表示这句话在训练集中的概率
Gmot-seq2seq:由于seq2seq模型只关注局部信息,能确保语句的流畅性,而主题模型只关注全局信息,能确保句子语义的一致性,所以作者将主题模型和seq2seq模型结合,将全局信息和局部信息融到一起来计算预测下一个目标词的概率,具体的:定义了k个主题T1,T2..Tk,1句话X的主题向量=这句话的主题概率分布*话题矩阵T

这句话的主题概率分布P(X)=每个词wi的主题概率分布之和再通过softmax层
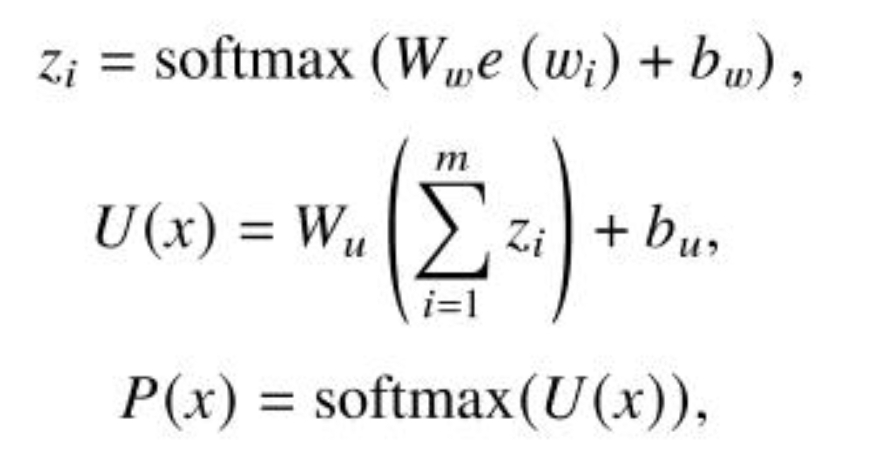
将主题信息和解码器在当前时刻 t 的预测输出加权结合并通过tanh函数,然后通过softmax层:
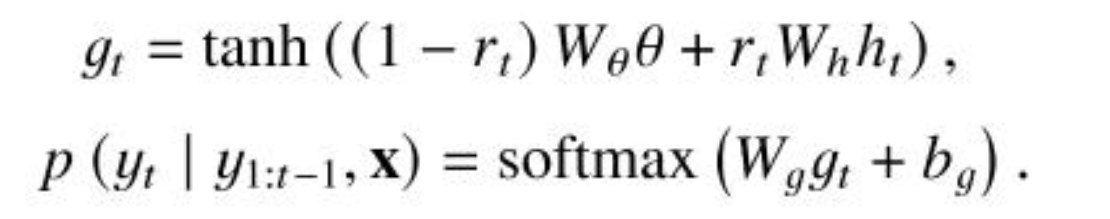
其中权重 rt 的计算是将主题向量和当前解码器输出结合然后映射:
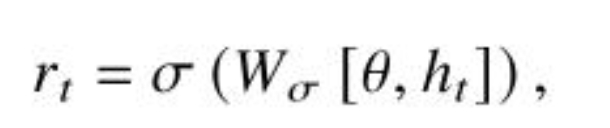
Negative training:在原来损失的基础上加入了生成不良句子的损失作为总损失
【FIFM,2022北大博士毕业论文】
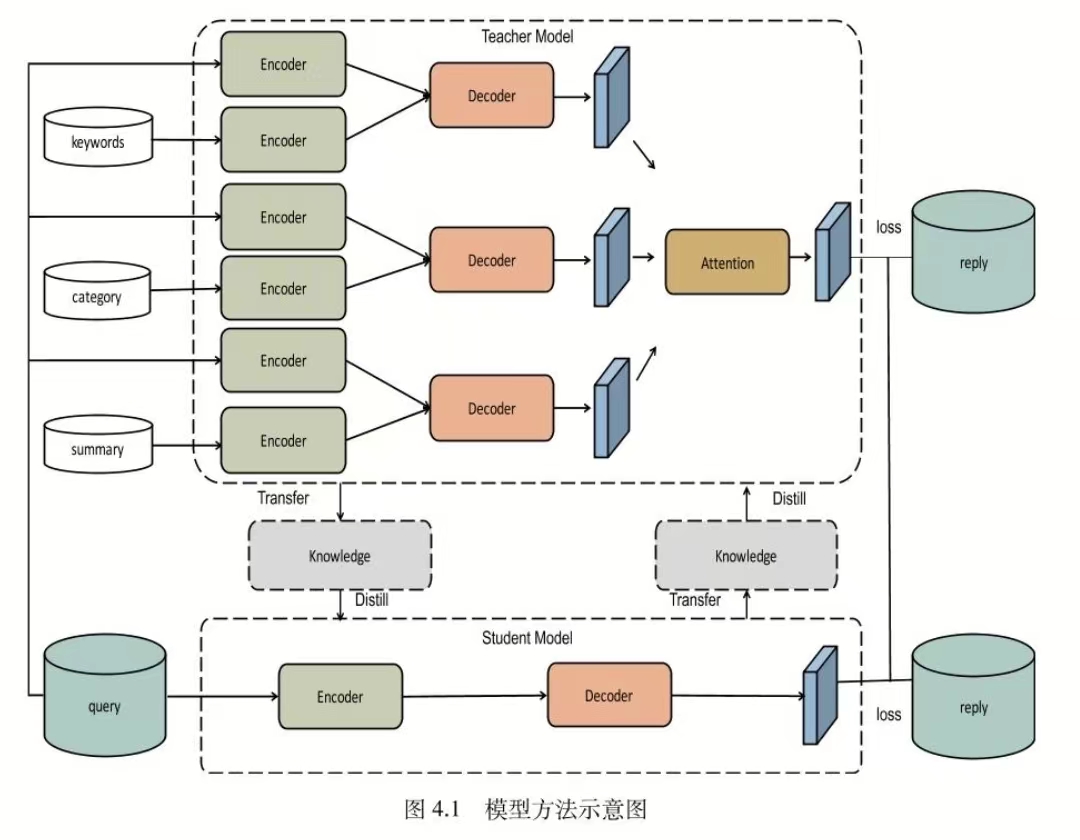
该模型注入3个外部知识:
关键词:选择与当前问题PMI分数最高的词wr作为关键词,PMI分数可以衡量相关性,句子和词wr的PMI分数约等于句子每个词和wr的PMI分数之和:
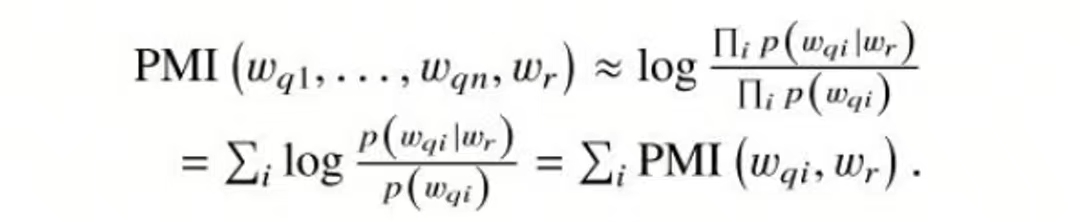
两个词的PMI分数:

类别:该问题所属科室,如精神内科
总结:该问题前的用户粗略描述
上面有三个教师网络,以第一个教师网络为例,分别编码问题和关键词,然后两者结合送给解码器,教师模型的损失函数是3个教师的编码损失加起来
下面是1个学生模型,输入问题输出回复,同时和老师交互信息,不仅要学到真实情况(硬标签),还要学到老师综合之后(对老师网络引入注意力)传来的信息(软标签),所以损失函数包括2部分:

其中权重计算方法,hTi是第i个教师编码器的问题输出,dTi是第i个教师解码器的输出:
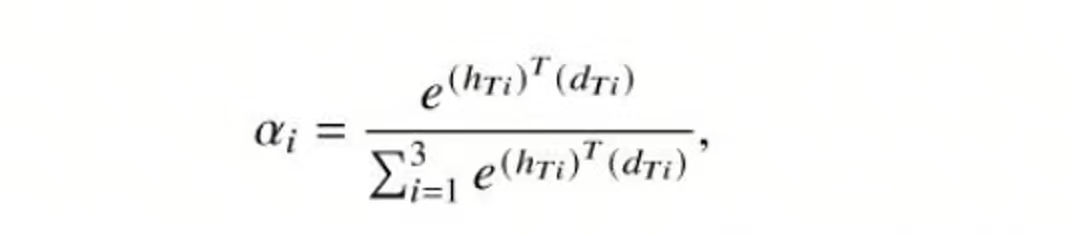
还有一个双向蒸馏损失,包含学生学老师的损失和老师学学生的损失:
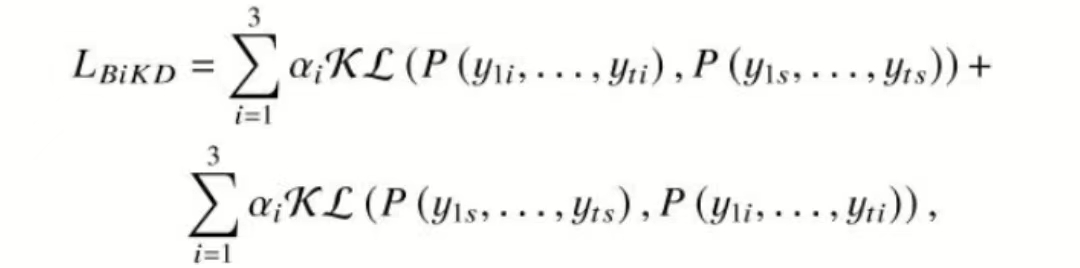
整体损失就是3者相加:

【CCLKD,博士论文】
(我做了改进)
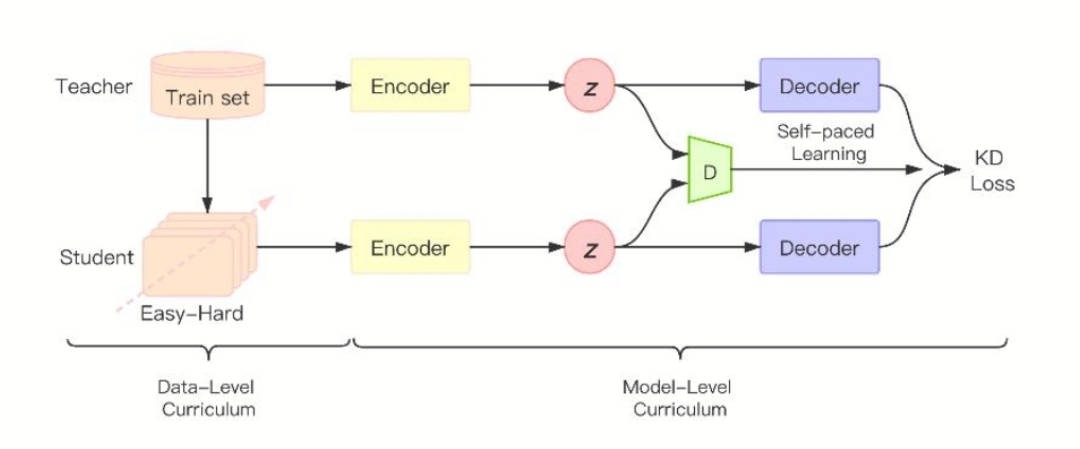
模型的encoder和decoder使用vae结构,教师模型先训练,然后冻住它的参数,再训练学生模型,传给学生模型的训练集按照对话(论文称之为课程)难度依次传入训练,难度从三个角度做定义:
回复长度:回复越长越难
熵:测量回复的多样性,越高越难,R是该回复,p(w)=该词在整个语料库中的频率
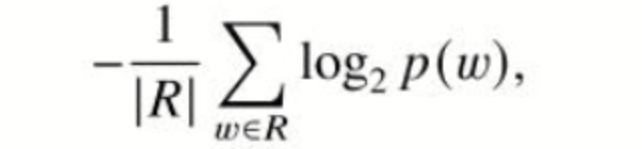
连贯性:这对问题向量和回复向量的相似度,句子向量可以简单表示为每个词向量的加权和
用三种方法分别计算句子的分数,3个分数归一化再相加作为句子的最终分数,然后按照分数给句子划分为多个难易集合。
接下来用GAN思想定义判别器D,它能区分教师模型和学生模型的分布,用wasserstein距离来定义D在第i个样本的损失是Ldi,如果该损失很大,说明对于该样本,教师掌握的信息比学生多得多,所以该样本比较难,因此该损失还能定义样本的难易程度,用 f(ldi)表示该样本的难易阈值,可见该阈值能动态改变。
学生模型不仅要学到真实信息,还要学到教授蒸馏过来的信息,所以对于第 i 个样本的学生模型损失:
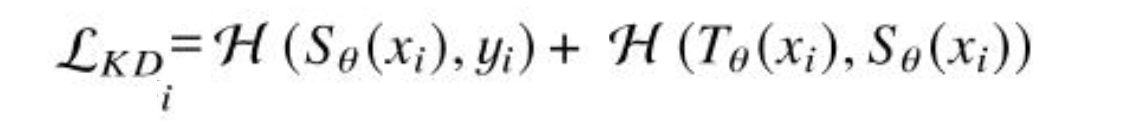
此时总损失 li 是学生损失,然后采用自学习方式定义新的损失函数来训练模型:

最小化该损失函数时,内部流程是:根据当前模型选择比较简单的样本(该样本的损失小于阈值 f(ldi)《=》vi=1),不要那些难的样本(vi=0),用简单样本训练模型,然后再选择样本再训练,这样模型训练的样本越来越多,样本的难度也越来越难
【MDMC,博士论文】
作者提出了2个架构一致的模型,架构采用GMVAE,GM:认为编码器的输出源于GMM,2个模型同时进行学习(协同训练),,模型要进行多任务学习,即它不仅要学习怎么回复,还要学习对问题的分类,其中分类的结果是两个模型集成后的结果,这个体现在损失函数上,两个任务损失通过调度器函数分配学习权重,作者一开始让模型专注于生成任务(权重大),后面开始专注于分类任务
模型预测:
有多种方案: 穷举搜索(exhaustive search)、greedy search(贪心搜索)、beam search(束搜索),Top-K采样,Top-p采样...,假定输入:我爱你,期望输出:i love u
穷举搜索(exhaustive search):穷举所有可能的输出结果:ilu,uil....,计算每个概率,取最大的概率作为预测结果,效果很好,但是慢,占空间
greedy search(贪心搜索):取当前每个词(i,l,u)的概率最大的作为第一个预测词,如u,然后结合前面的预测u,计算每个词的概率,取最大的概率作为第二个预测词,.....速度很快,但是效果不好,中间一步错则错误会传递到后面,类似于始终点击输入法的第一个词所形成的话,通常无意义,前后答案重复。
beam search(束搜索):假定超参数束宽=2,预测第一个词的时候,取概率最大的2个,如{i:0.5,u:0.3},预测第二个词时,把 i 输进去得到三个词的概率,再用 i 的概率0.5分别乘上它们,得到{ii,il,iu}的概率,然后独立的输入u用同样操作处理,得到{ui,ul,uu}的概率,这6个取最大的两个,{il: 0.5,ui: 0.4},预测第三个词时,输入il得到三个词的概率,再用0.5乘他们,得到{ili,ilu,lll}的概率,输入ui....,对这6个概率取最大的两个{ilu,uiu}交给业务层,业务进行结果筛选
结果筛选:
通过上面方案,生成了很多候选结果序列,需要过滤筛选,有RCE rank(对Bert 进行fine-tune,输入原句和候选序列,输出相关度(二分类的下游任务),取相关度最大的候选答案作为最终答案)、MMI rank算法
结果评估:
有人工评估和自动化评估。人工评估:比如facebook也有自己一套方案,都是通过人,一种是让一个人同时跟两个chatbot的去聊,判断哪个更好;第二种是让两个chatbot自己聊,人去判断哪个更好。在中文领域,百度也提了一种评估方案,包含四个方面评估,回答的内容是否跟上下文相关,是否包含一定的信息量,内容的新颖性,还有回复内容跟正常人说话是否相似。人工评估更接近真实体验。
详细:https://baijiahao.baidu.com/s?id=1723425131614659313&wfr=spider&for=pc
3、任务型:pipeline方式
目前最先进的是UBAR、PPTOD,百度UNIT的Task Flow,任务型对话系统的核心主要包括 Natural Language Understanding (NLU),Dialogue State Tracking (DST),Dialogue Policy Learning(DPL)、Natural language generation 4个部分。这四个模块串联起来,前一个输出是后一个输入,通常DPL的模型也包括了NLG,我这里就分3部分
概念:领域:意图的更上层是领域,如将 “询问天气” 意图和 “询问温度” 意图均归属于 “天气” 领域;
槽位:时间、地点算两个槽位,每个领域如Hotel、restaurant都有自己的name slot,如果再细化有了intent,则是domain下的每个intent都有自己的name slot,为了方便此处就不要意图了;
belief state:如果没有意图,则是用户话里面的(Domain、slot、slot value),否则是(Domain、intent、slot、slot value);
自监督学习:机器自动生成标签(如中心词的标签是它邻居),然后监督学习;
【NLU】
意图识别,比如识别购买意向,方法有规则匹配,模型匹配,TOD-BERT模型(2020)是最近提出的一个经典模型:TOD-BERT模型结构是Bert一致,不同点是采用MLM和RCL两个任务进行模型预训练,其中MLM与原生BERT保持一致,RCL:对一轮对话切一刀,前面的问答语句作为context,context后面的一句话作为response,这组成一个正例子,负例是a对话的context和b对话的response,将 context 和 response 分别输入到 bert 得到 cls 对应的句子向量,然后两个句子向量计算相似度,正例的标签是1,负例标签是0。意图识别任务(单个句子的分类问题)就作为TOD-BERT在下游任务的应用
【DST】
识别用户所说的槽位对,比如要识别出food:persian
方式一:槽值对预先定义好,DST模块遍历所有槽值对来找到最符合当前用户说话的槽值对,如NBT模型(2017)
NBT:
输入有3部分:系统输入(用户回复的上一句)、用户回复、候选槽值对,输出该用户的回复和候选槽值对的相似度,然后再输入下一个候选槽值对...最终选取最佳匹配该用户回复的槽值对,属于multi-hop classification,所有词向量的值采用预先训练好的值并固定
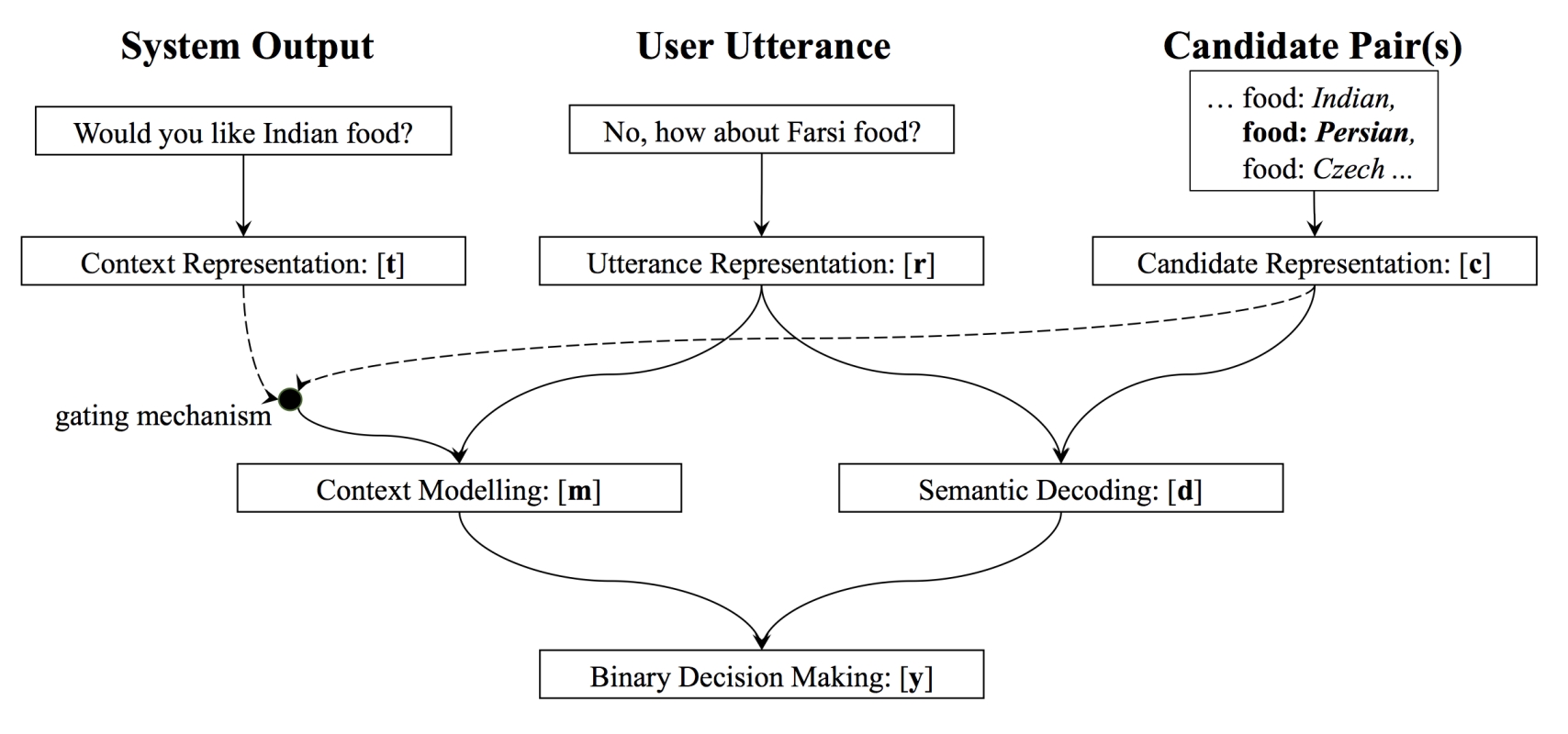
context representation:(tq,ts,tv)=(类型,槽位名,槽位值),如果系统输出是请求,比如上图,则是(请求符号,food的词向量,0),用以确定该slot food的值为多少;若系统输出确认,比如问:like AAA food?则(tq,ts,tv)=(确认符号,food的词向量,AAA的词向量)
Utterance representation:对用户回复做句子Embedding,作者提出2种方法NBT-DNN、NBT-CNN
NBT-DNN:
r1是句子的1-gram向量:所有词向量相加;r2是句子的2-gram向量,两两词向量先拼接,然后全部加起来;r3...然后分别通过神经网络映射到相同维度生成r1',r2',r3',最后三者相加

NBT-CNN:
就是textcnn,对于2-gram,假定有3个卷积核,每个卷积长度是2*词向量维度,每个卷积核生成1个列向量,3个做厚度拼接,然后加上一个全局的偏置,再通过relu,再max-pool,得到1*3的向量,其他1-gram、3-gram也得到自己的1*3向量,然后3个向量做相加 / 拼接作为最终的句子向量表示,该模型的效果比NBT-DNN效果好

candidate representation:槽位名向量cs+槽位值向量cv的结果再通过神经网络,使得维度和用户回复向量r一致
semantic decoding: r 和 c 做元素积,元素积的结果是一个向量,这样下游的网络实现特征交叉,如果2者直接拼接的话,就需要有更多的数据来支持特征交叉
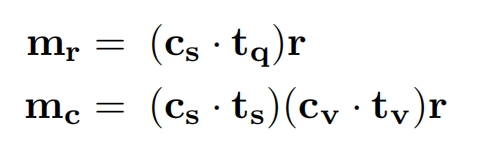
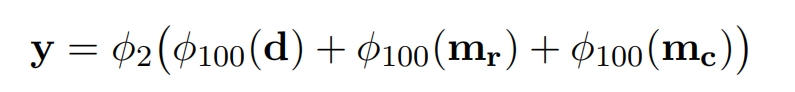
方式二:没有固定的槽值,因此DST模块直接根据对话上下文生成值,如TRADE模型
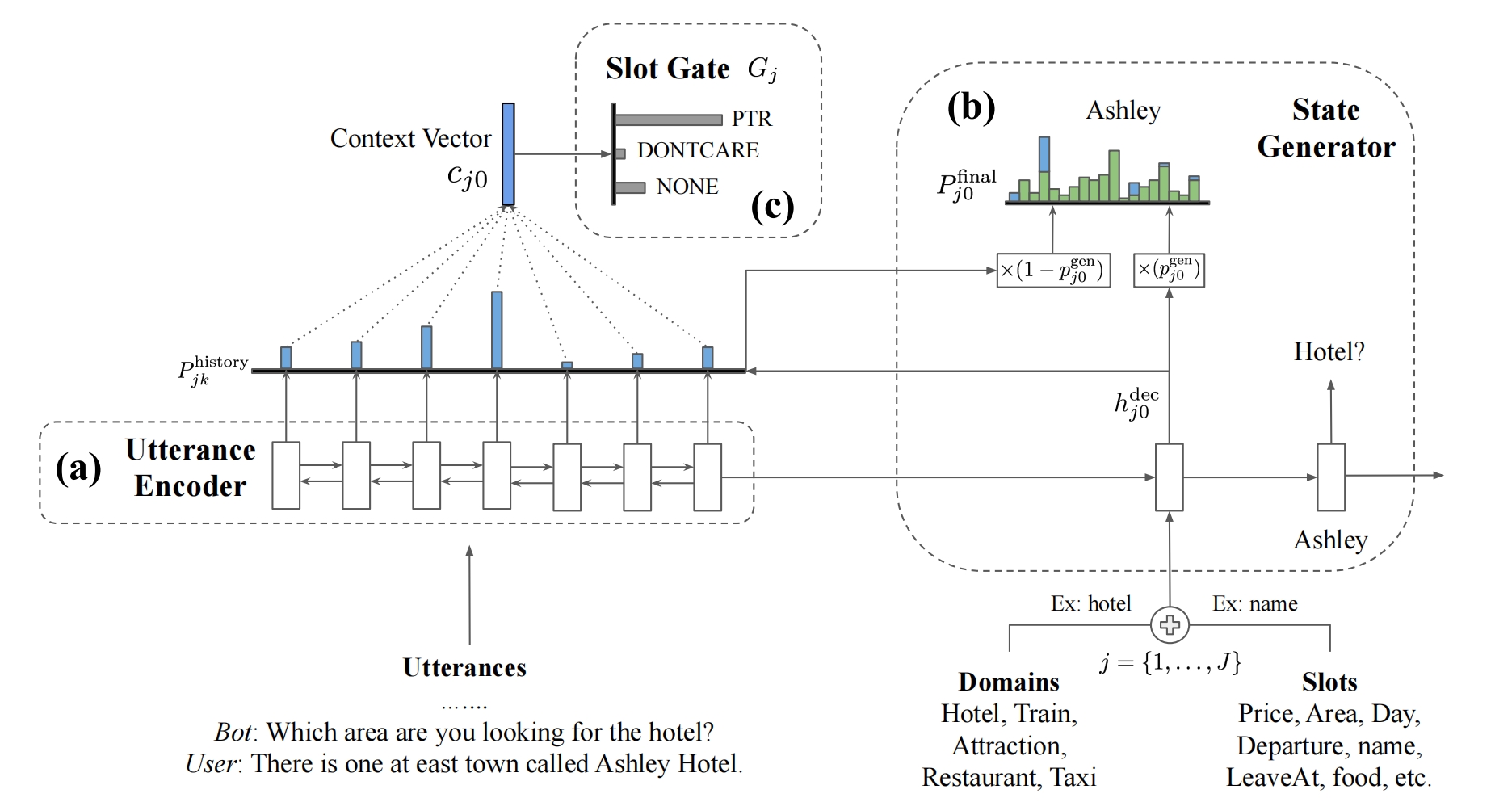
utterance encoder:双向GRU结构,输入 l 轮回合的历史对话,每轮回合=用户说话+系统回复:{Ut−l , Rt−l , . . . , Ut , Rt},每句话被映射到相同维度,输出 Ht={句子1向量,句子2向量...}
state Generator:用于生成槽位值,这个值是一个单词序列,如James Smith,遍历所有可能的(域,槽位名),总共有J对,对于第 j 个对,如(Hotel,name),将2者词向量相加输入GRU单元开始预测槽位值的第一个单词,当预测第二个单词的时候就把第一个单词的词向量作为GRU的输入,以此类推。假定要预测第k个词,此时GRU的隐状态输出为:
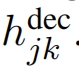
将它通过神经网络再通过softmax得到V维(词表大小)概率向量(一个元素是一个单词的概率),和Ht相乘再通过softmax得到一个概率向量(每个元素是该句话的概率),将这两个概率向量做加权和作为最终概率向量,这样不仅能考虑到和前一个预测单词的关系,还能结合历史对话的信息,从最终概率向量里挑出概率最大的单词作为预测输出


其中权重的计算是将隐状态向量,前一个预测的词向量,对话信息向量拼接起来然后通过神经网络映射为1个数(权重):
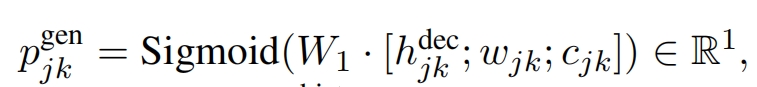
其中对话信息向量就是Ht的期望,即把对话语句Ht按照概率加权:
![]()
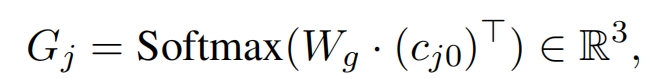
模型的损失是两部分(state Generator和Slot Gate)损失的加权和
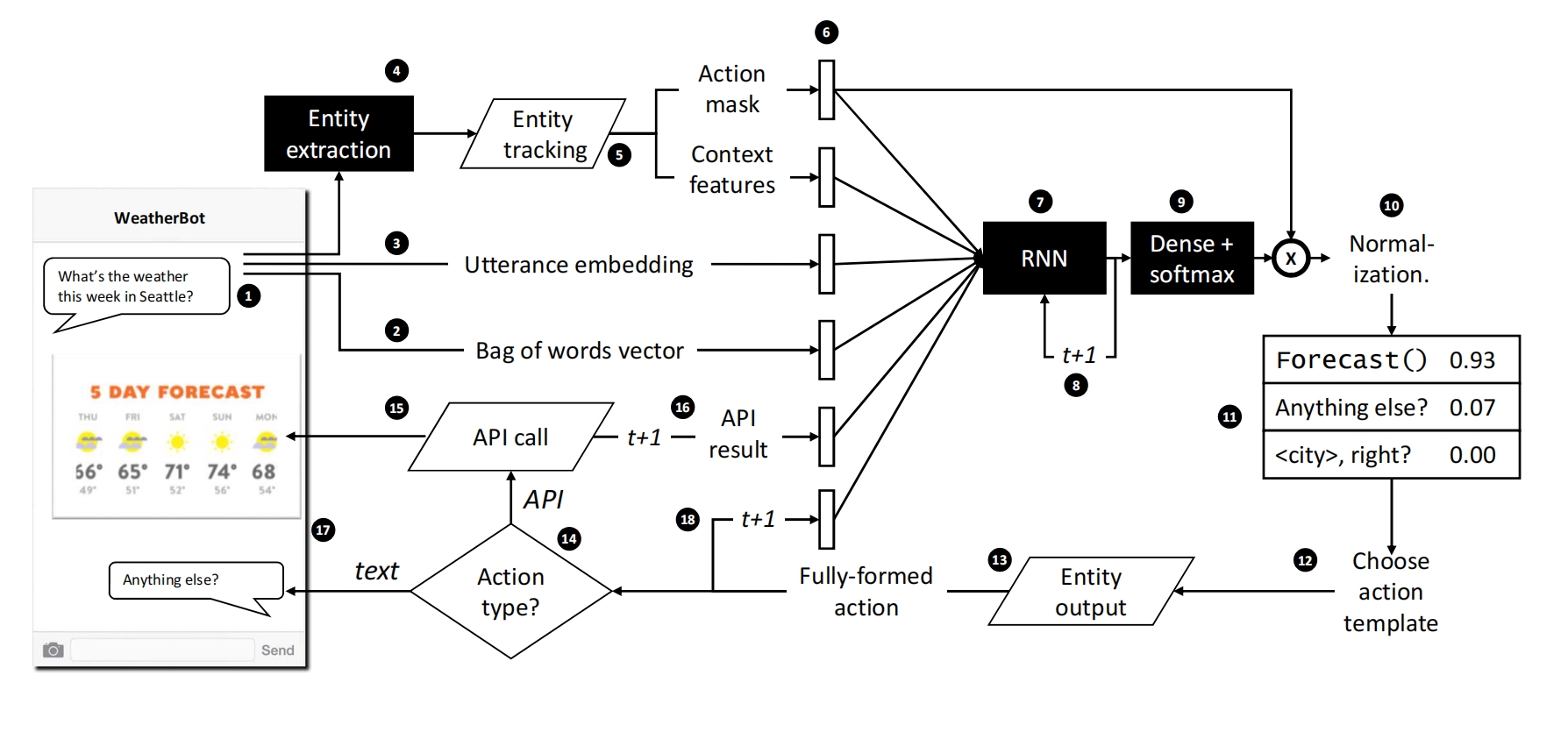
step 1:接受用户输入
step 2:将用户输入表示成一些词袋向量
step 3:将用户输入通过模型表示成句子向量
step 4:识别用户输入的实体,比如识别”Jennifer Jones” 为 <name> 实体
step 5:实体跟踪模块,根据传入的实体进行后台操作,返回Action mask,用于标识系统动作要不要采取(比如未识别到电话号码,则打电话api=0),以及context features,用于标识哪些实体出现了(1),哪些没出现(0)
step 6:将step1-step5的向量组成1个向量传入RNN
setp 8:将RNN的输出隐状态传入softmax层,生成一个概率向量,向量长度=系统该采取的所有动作数
step 10:将Action mask与概率向量做元素积,不能操作的动作概率=0,然后再归一化使得向量长度=1,这样每个元素还是概率
step 12:如果采用强化学习RL,则采样一个动作,如果是监督学习,则取最大的概率动作(核心点)
step 13:将动作里面的实体名替换成用户输入里面的具体值,如city right?变成了Seattle right?
step 14-18:判断动作类型,如果是api,则调用api并返回结果给用户;如果是文本,则直接返回给用户,同时将当前要执行的动作和api返回结果再传给RNN
方式二:人工设计有限状态自动机=规则匹配
比较常用的是,在自动机中,点表示操作=系统回复动作,如问用户时间ask_date,以边表示槽位状态,如某个槽位状态是0的话=该槽位值还没填充),比如从dst得到下面的表:
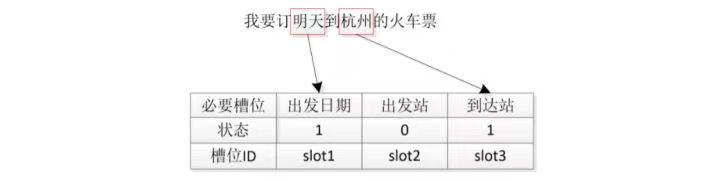
然后使用人工建立的自动机按照不同条件(槽位有没有填写),做相应的回复模式:

rasa:
https://zhuanlan.zhihu.com/p/75517803
https://zhuanlan.zhihu.com/p/78665885
https://zhuanlan.zhihu.com/p/81430436
4、统一对话系统
unified dialogue system = UniDS模型(UniDS: A Unified Dialogue System for Chit-Chat and Task-oriented Dialogues,2022年5月)第一个提出一个统一的对话系统,以端到端的生成式联合处理闲聊和面向任务的对话,对对话噪声的切换具有较好的鲁棒性和两种对话之间的切换能力,TOd数据集用 MultiWOZ,闲聊数据集用Reddit,Tod模型评价指标用Inform(实体正确率)、Success(问题回答程度)、BLEU(回复的流畅度)、Combined=(Inform + Success)× 0.5 + BLEU(综合回复的质量),闲聊模型评价指标用:BLEU、Dist-1(1-gram特征出现的比率)、Dist-2(2-gram特征出现的比率)、AvgLen(回复的平均长度)

假定当前处于第 t 轮的对话,把 chit-chat和 tod 数据格式统一为:用户输入 Ut , belief state Bt ,(域,槽位名,槽位值) 数据库返回结果 Dt(根据Belief state所找到的数量) , 系统行为 At (<domain> <act> [slot]),这个slot是可选的), 回复 Rt (具体的语句)
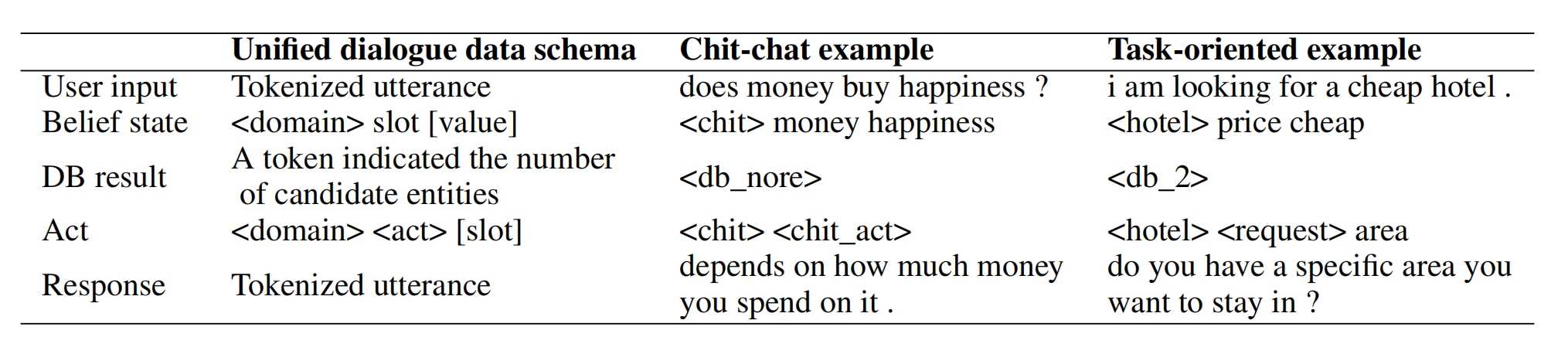
模型处理流程:
上下文向量Ct由之前的对话+当前用户输入:Ct = [U0, B0, D0, A0, R0,· · · , Rt−1, Ut]
输入到UNIDS得到当前Bt:Bt = UniDS(Ct),然后到数据库查询得到返回结果Dt,再输入到UNIDS得到At:At = UniDS([Ct , Bt , Dt ])
最后把前面的结果输入到UniDS得到Rt:Rt = UniDS([Ct , Bt , Dt , At ]).
t 轮的全部对话信息可以表示为:Xt = [Ct , Bt , Dt , At , Rt].
每个单词相对 tgt 的位置
 浙公网安备 33010602011771号
浙公网安备 33010602011771号