spark1
环境:jdk1.8,spark3.0,Scala2.12.11,maven3.6.3,hadoop3.2.3(要2.8.5以上版本)
【scala】
基于JAVA,可以直接调用java类库,编译成字节码文件(.class文件和$.class文件,$.class文件是辅助.class文件的)然后jvm做解释执行,所以能够实现跨平台
Unit:函数没有返回值
Array[String]:后面的String是泛型
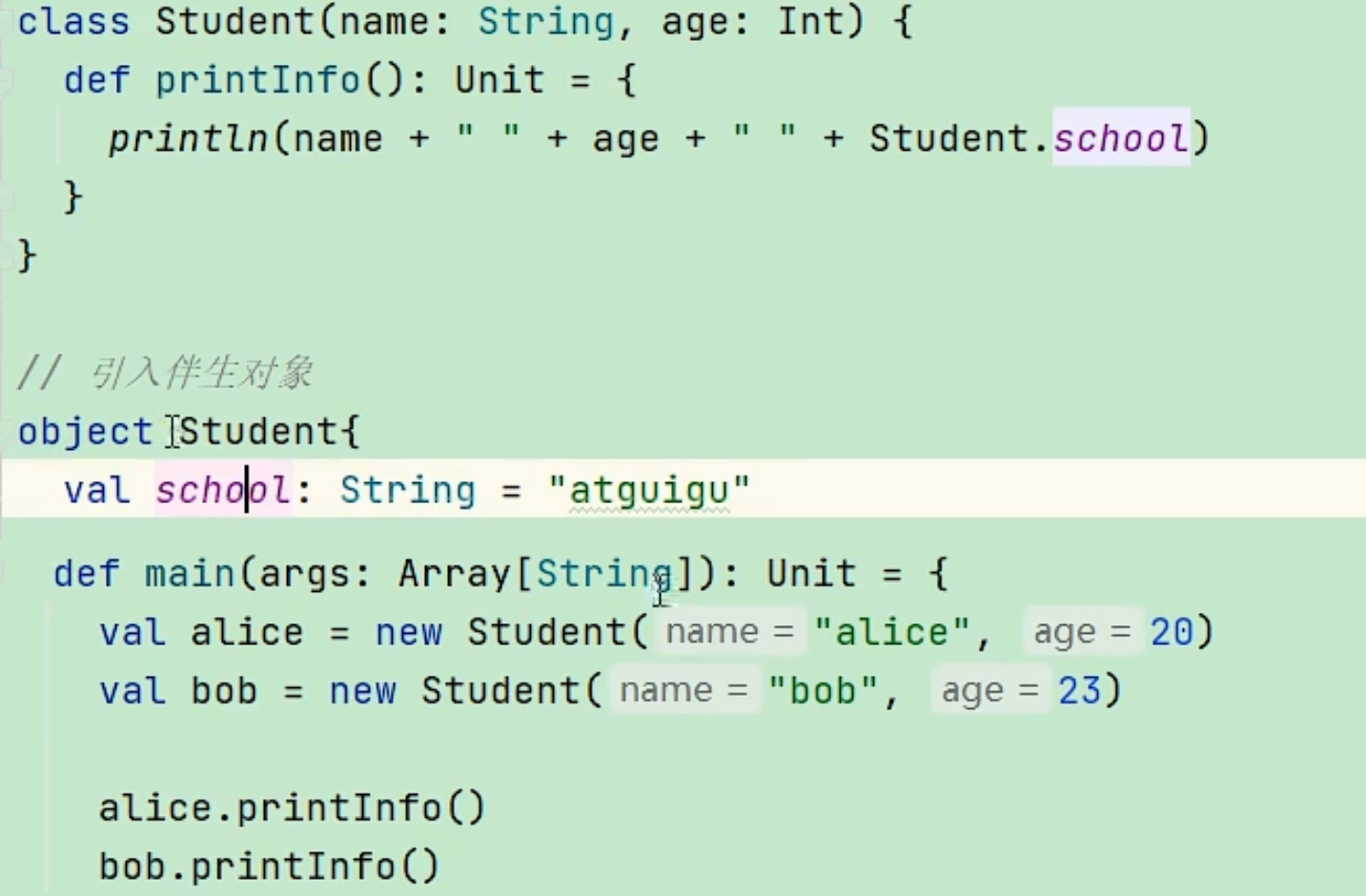
Object:声明一个单例对象(伴生对象)
如下图,伴生对象有自己的伴生类,反之,它俩名字一样,能够互相访问对方的属性,半生类用于定义对象的私有属性,如name,age,伴生对象用于定义全局属性,如school,伴生对象可以run,伴生类不行
常量val,变量var,变量类型可以省略,类型确定后不能换别的类型,变量要有初始值
字符串模板,s是原封不动替换,f能实现格式化:

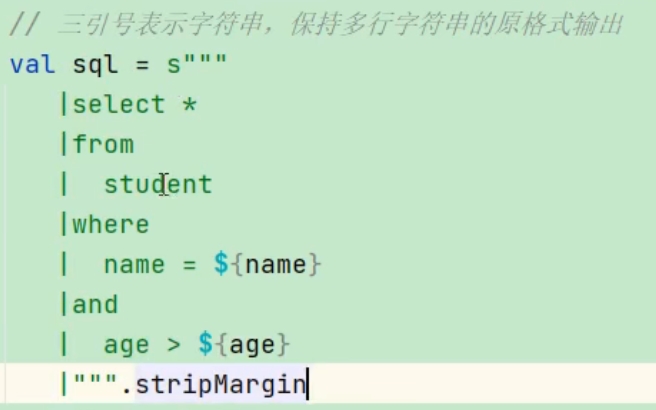
三引号能覆盖换行:
控制台读取输入:

文件的读取与写入:

数据类型转换:
函数返回空也是返回了类型是空的对象
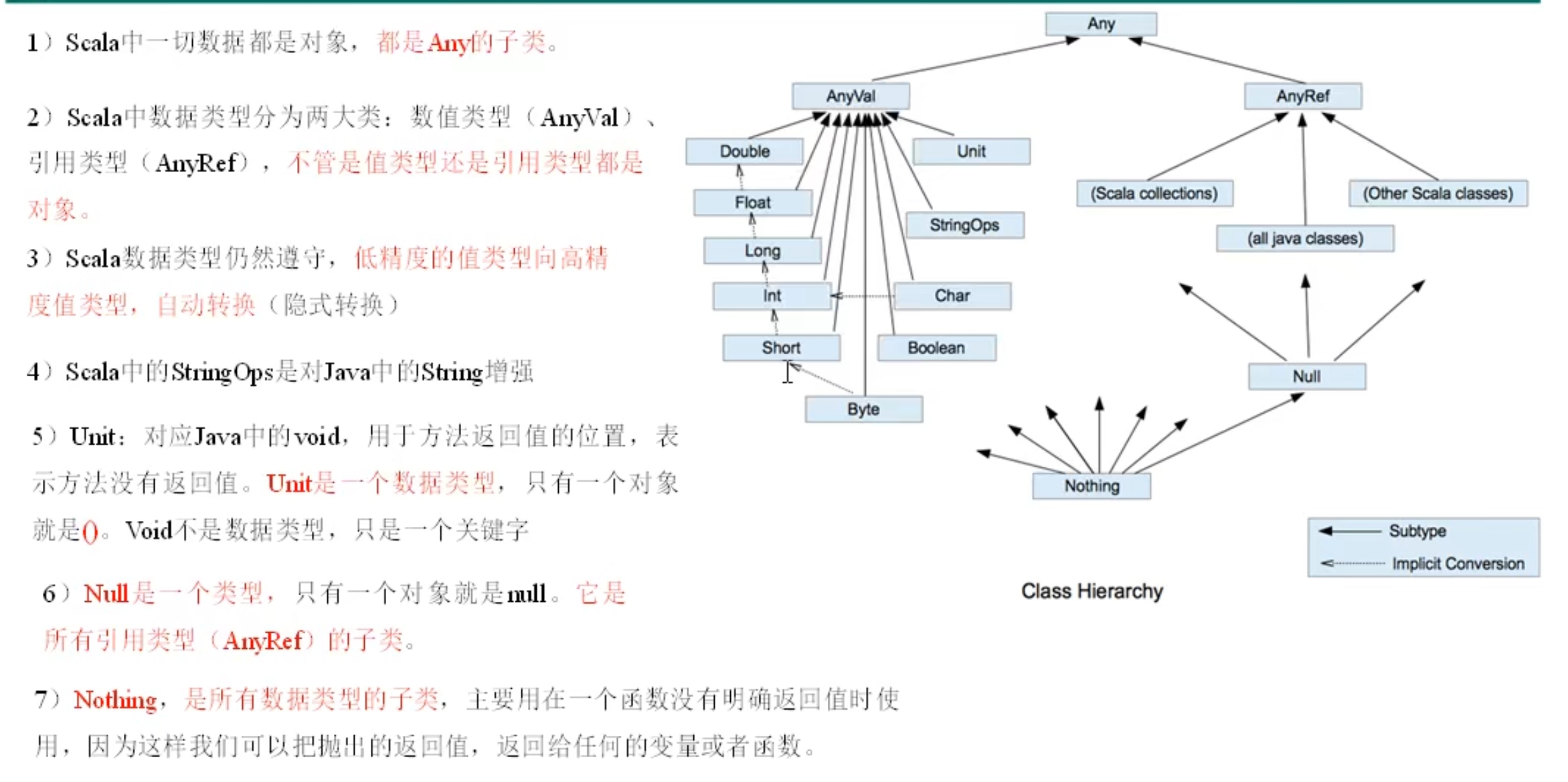
整数类型有Byte、short、Int、Long,能表示的范围越来越大,默认INT,低精度可以赋值给高精度,高不能赋值给低,除非先强转再赋值
附点类型默认double,需要float需要后面加f
Unit类型的唯一实例:(),单例模式;NULL类型的实例:null,用于赋给对象;nothing作为抛异常的返回
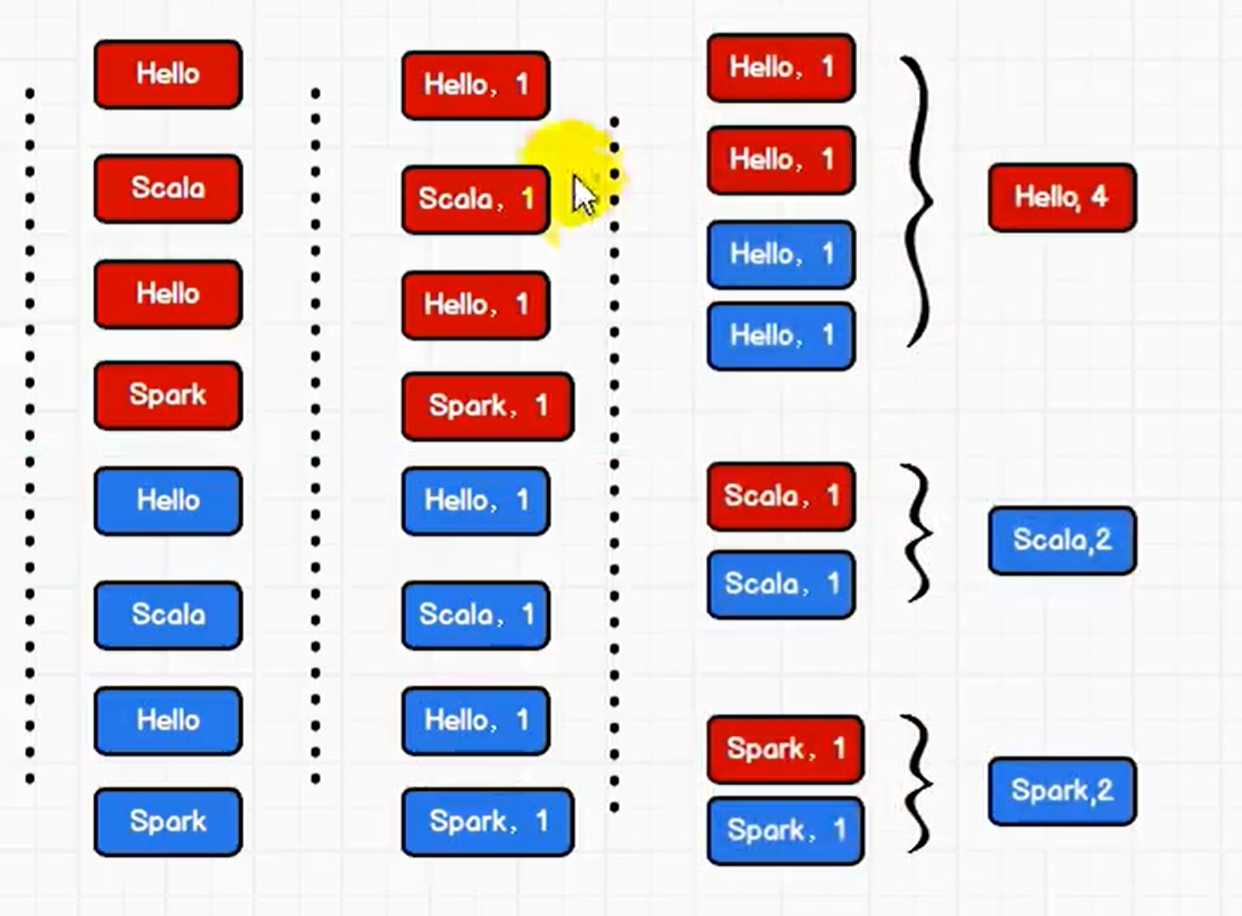
wordcount
方法1:
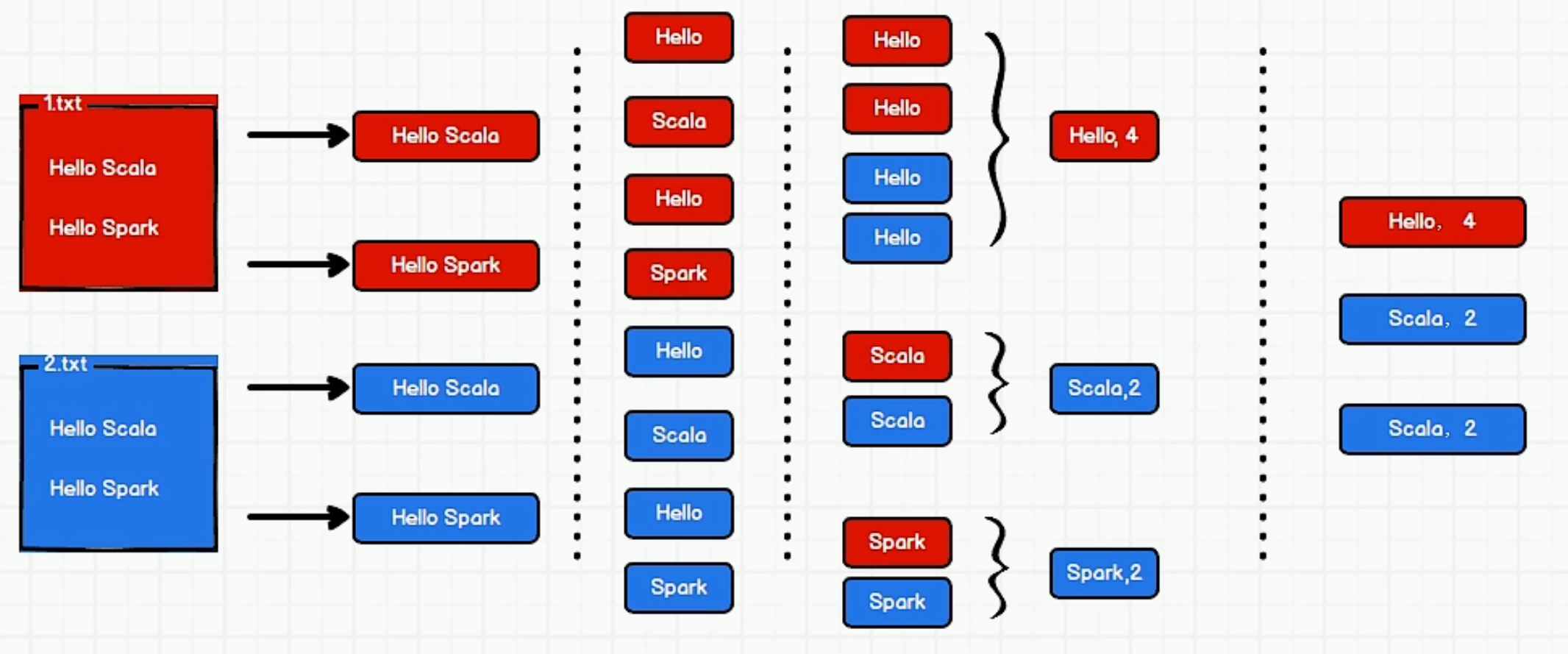
方法2,聚合功能: