es
es是Lucene上做的改进
解决跨域问题:在D:\aaa2222339\elasticsearch-7.8.0-windows-x86_64\elasticsearch-7.8.0\config的elasticsearch.yml底部加:
http.cors.enabled: true
http.cors.allow-origin: "*"
运行es:双击bat,浏览器输入http://localhost:9200/
客户端head运行:在D:\aaa2222339\elasticsearch-7.8.0-windows-x86_64\elasticsearch-head-master下,进入cmd,输入npm run start,浏览器输入:http://localhost:9100/
Kibana运行:打开bat,然后地址栏是http://localhost:5601
es看做数据库,索引看做库,文档看做数据
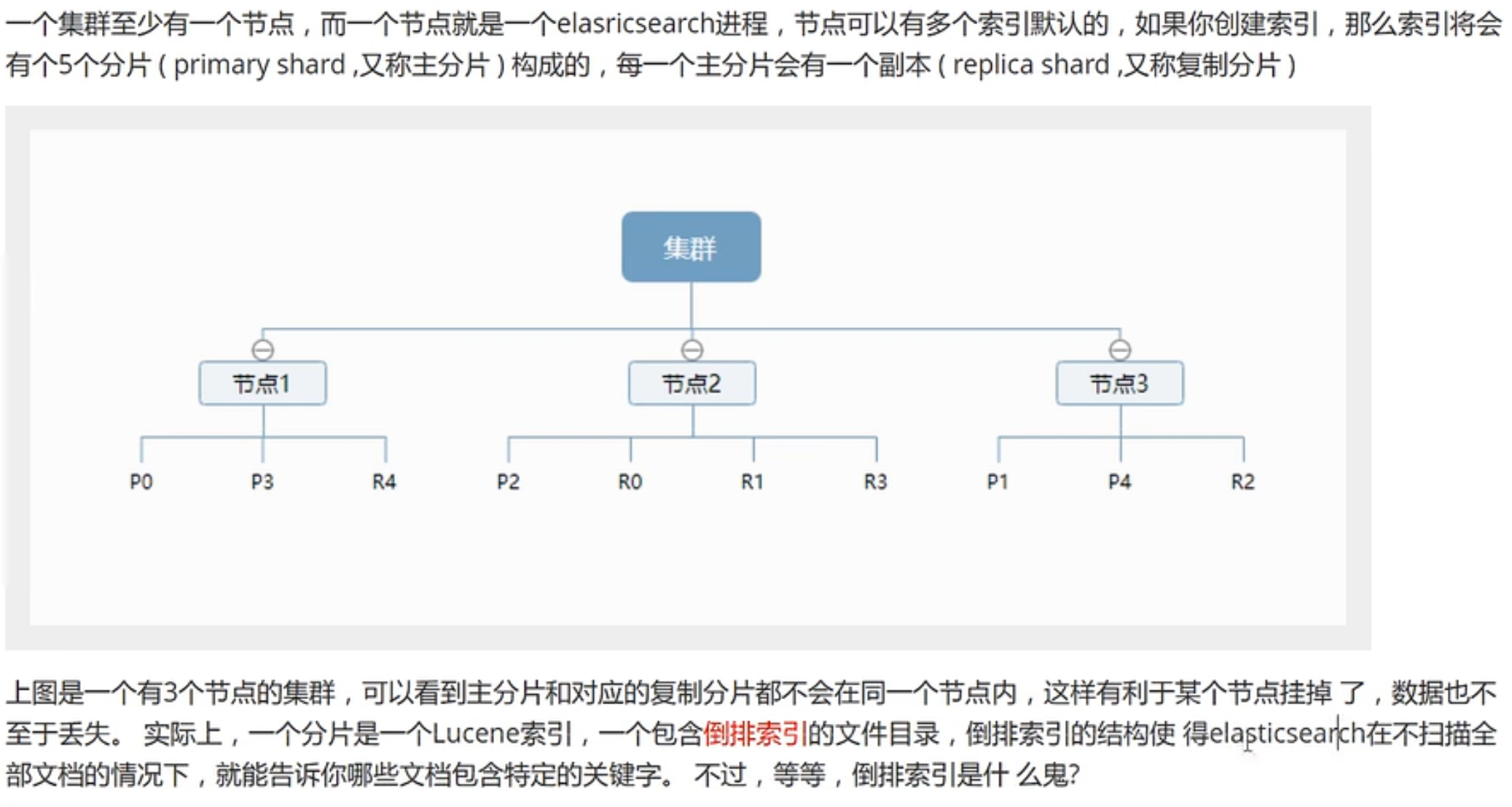
下图是一个索引的5个分片p0...p4,以及他们的副本r0....r4
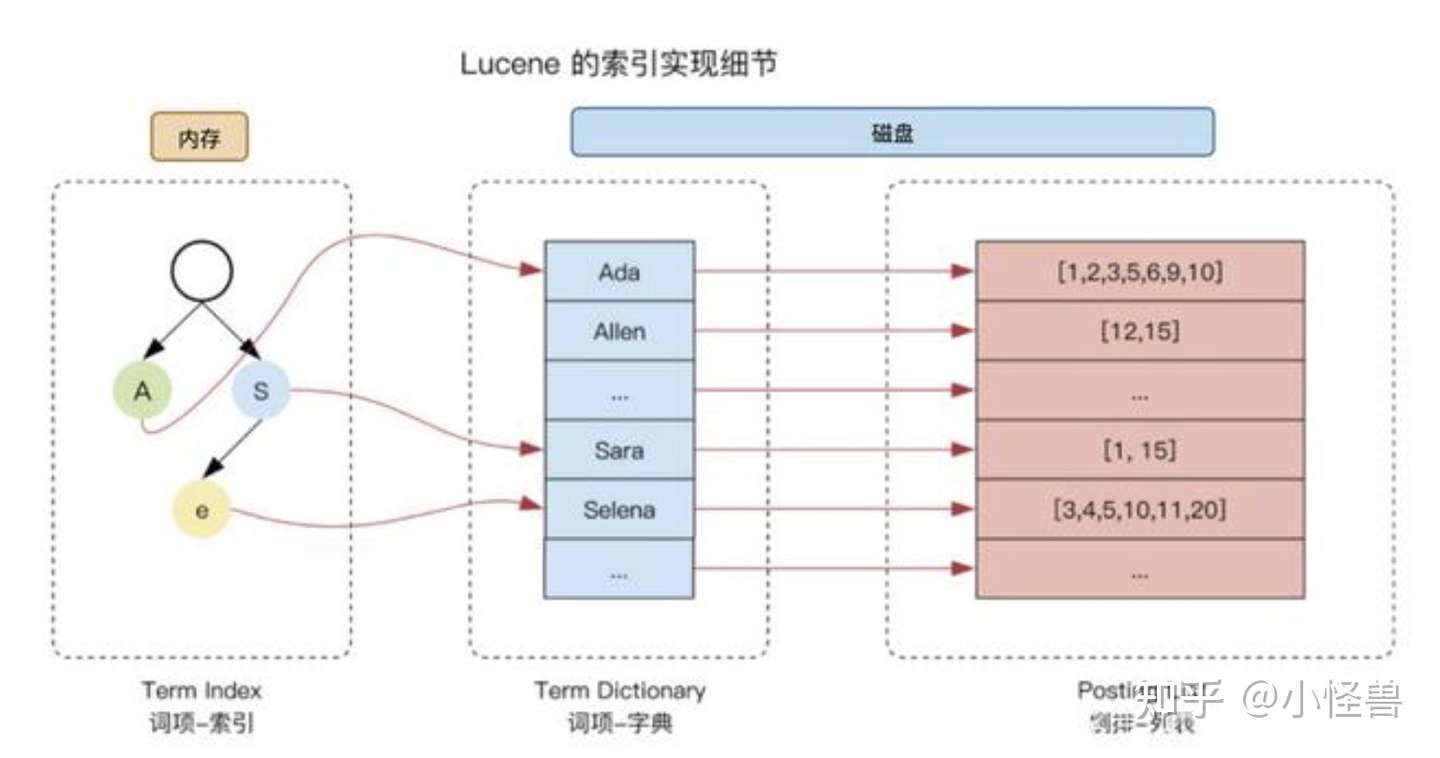
【倒排索引】
内存里是Trie 树,找到term index后,去term dic里面找term,注意term dic是有顺序的,再找到包含该 term 的所有 文档 id,若是查多个term,则得到了多个文档list,出现次数最多的(权重最大)文档id就是要先找的文档
命令都采用restful风格
ik分词器:
ik_smart会根据字典拆分成断句,在kibana输入:
GET _analyze
{
"analyzer": "ik_smart",
"text":"今天天气不错啊"
}

ik_max_word:拆成所有可能的短句,可能重合:
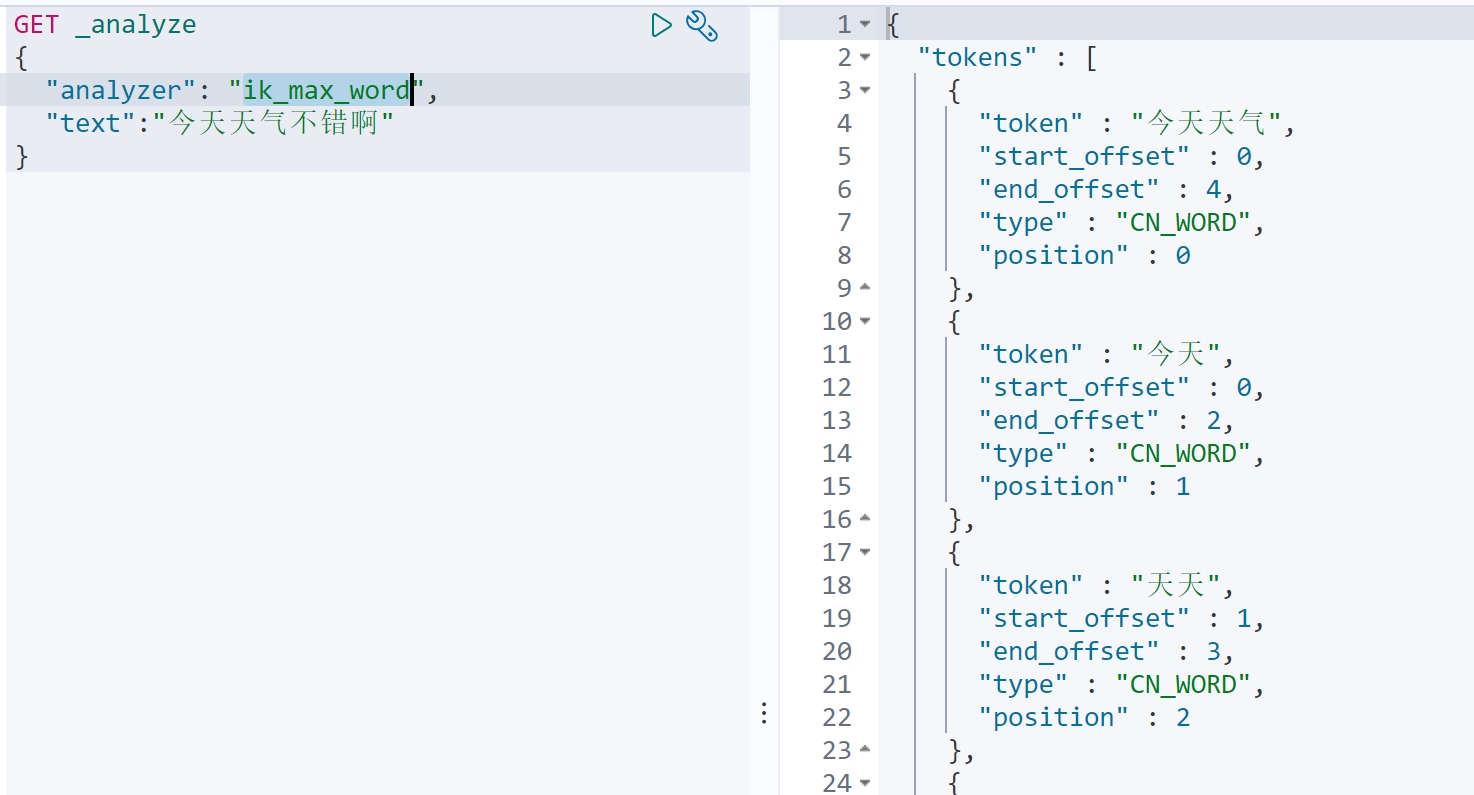
扩展词典让他认识更多的分词:在D:\aaa2222339\elasticsearch-7.6.1-windows-x86_64\elasticsearch-7.6.1\plugins\elasticsearch-analysis-ik-7.6.1\config新建ldp.dic,然后在IKAnalyzer.cfg.xml里面注册
analyzer如果是keyword,就没动,standard会拆分:


创建索引并插入数据:/索引/类型/文档
PUT /test1/type1/1
{
"name":"asd",
"age":22
}

只创建库和规则:

得到索引信息:GET 索引
获得其他信息:GET _cat/其他信息
修改数据(多加个_doc):

删除索引:DELETE 库
简单查询:


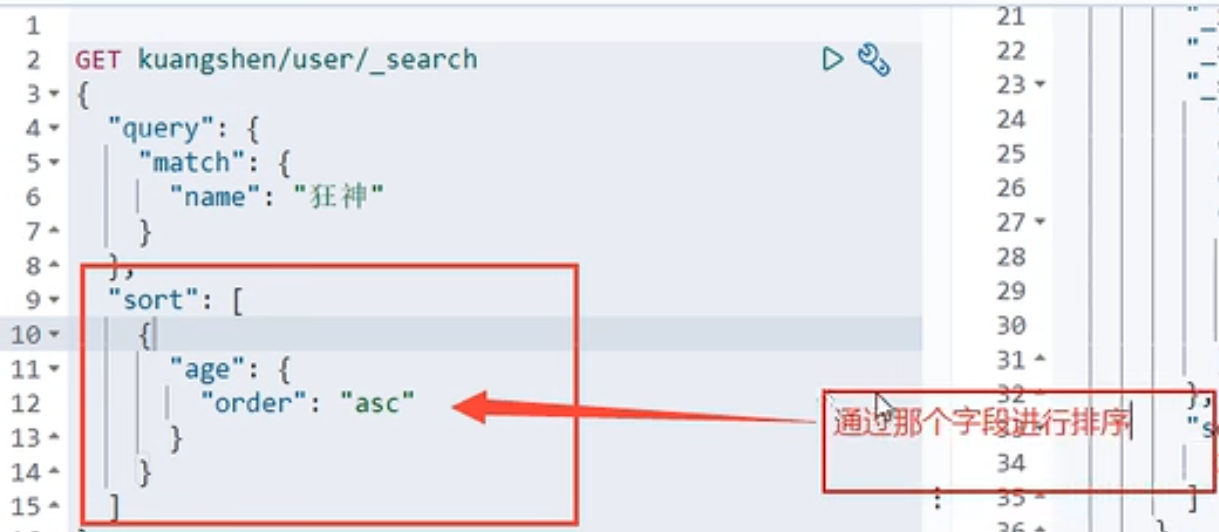
复杂查询:
使用match:先分词,再用or去查分词的倒排索引,它的效果是模糊匹配(不要设置type=keyword)
去“name”字段里面找符合条件的行
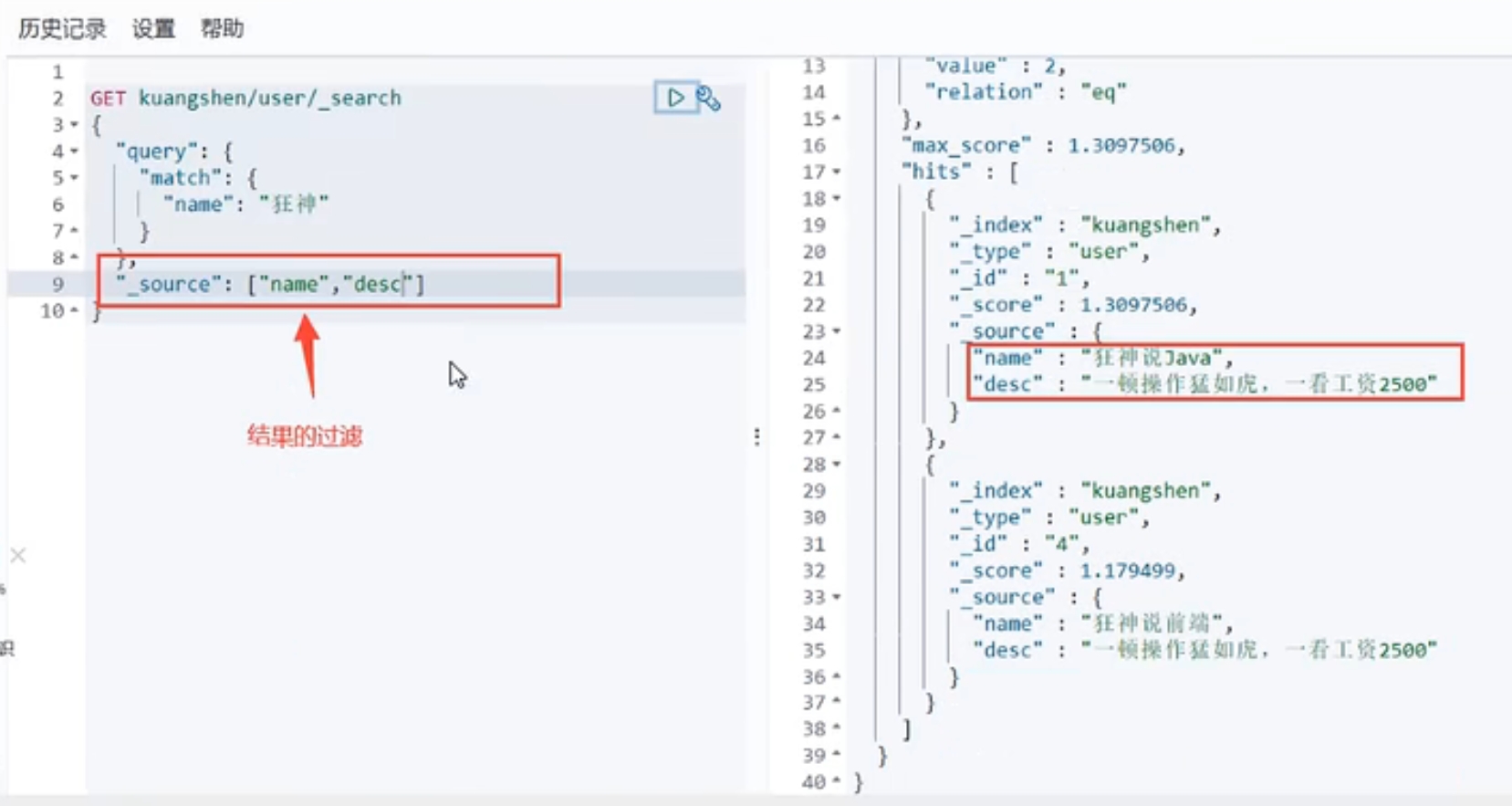
分页:

must:

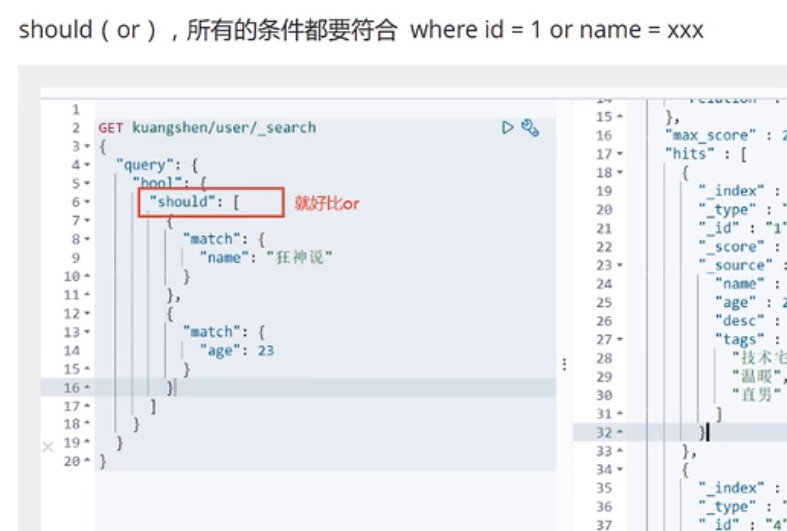
should:
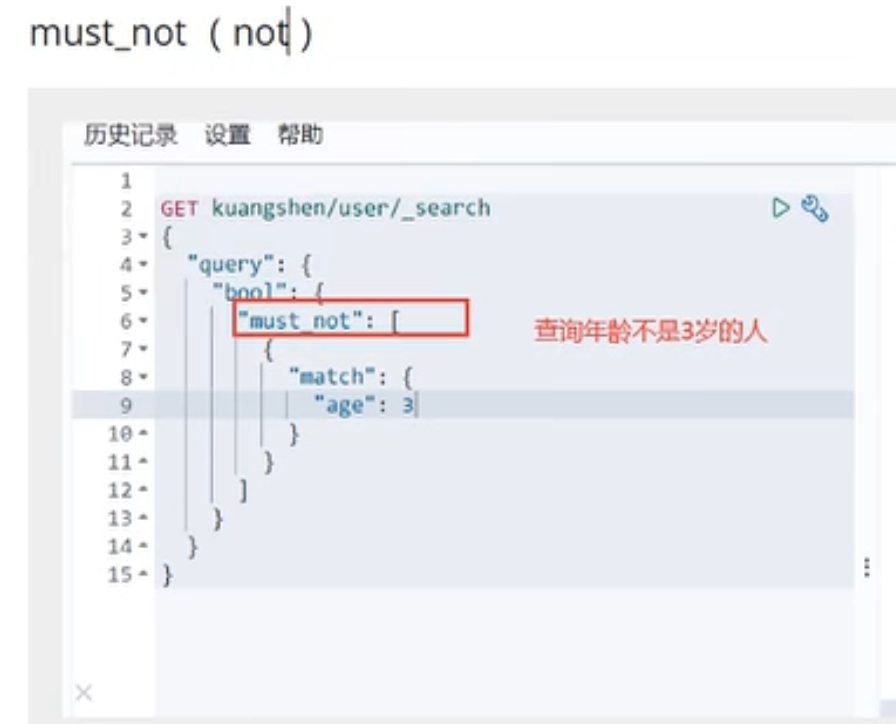
must_not:
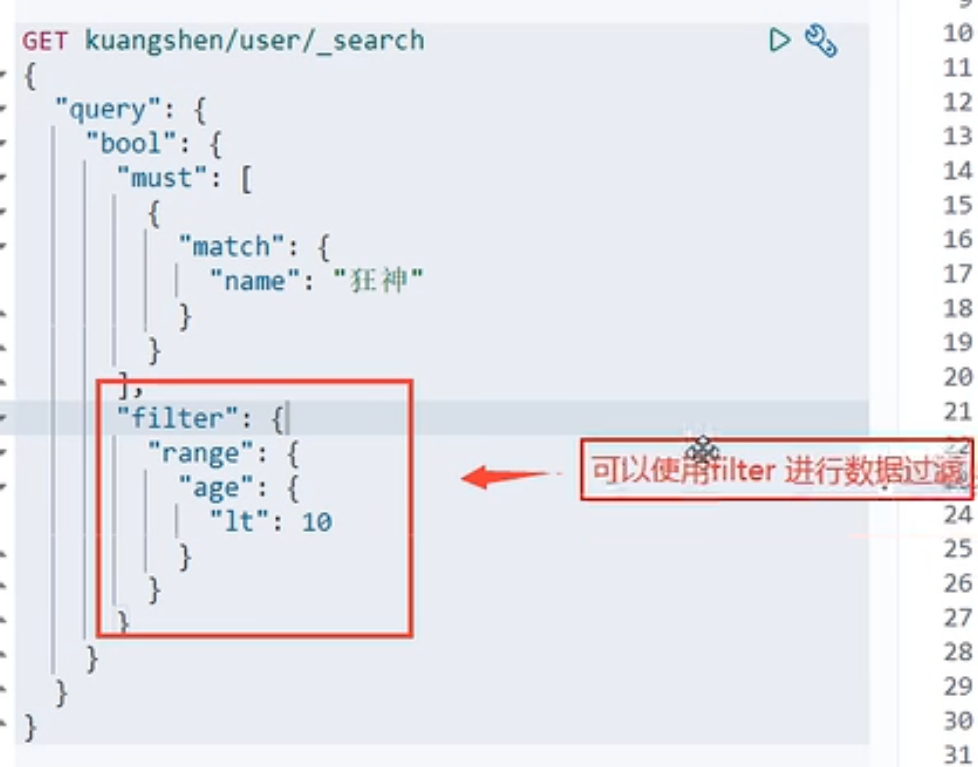
过滤满足条件的:

多条件模糊查询:

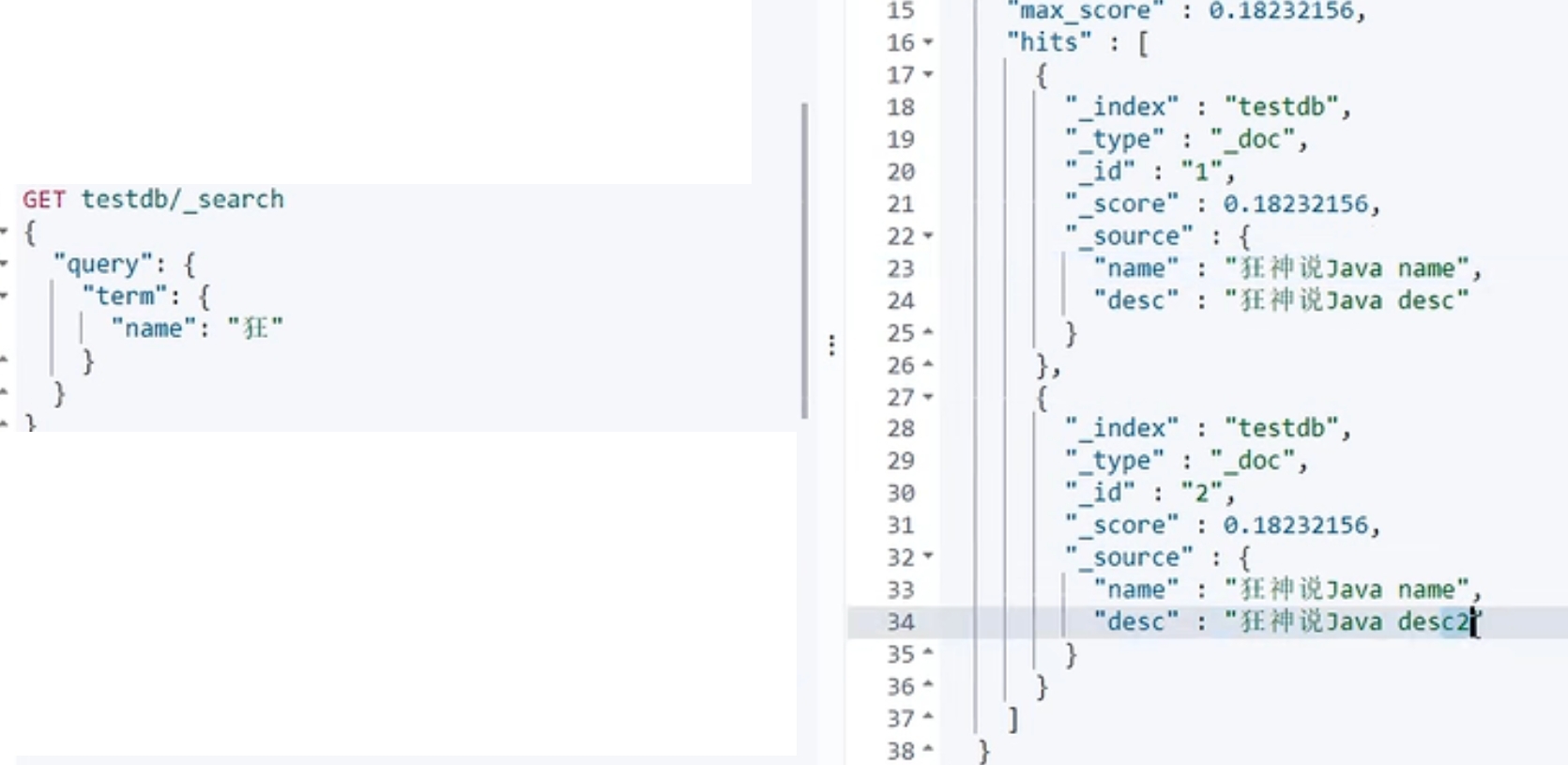
使用term精确匹配,需要设置对应的字段类型为keyword
原理:库中的字段name的type:text或者没有,则会先分词,再把存储分词的倒排索引;设置desc字段为keyword,整体存储为倒排索引,使用term会拿这个整体去倒排索引中去完全匹配,而使用match,会把query分词,再查询分词的倒排索引

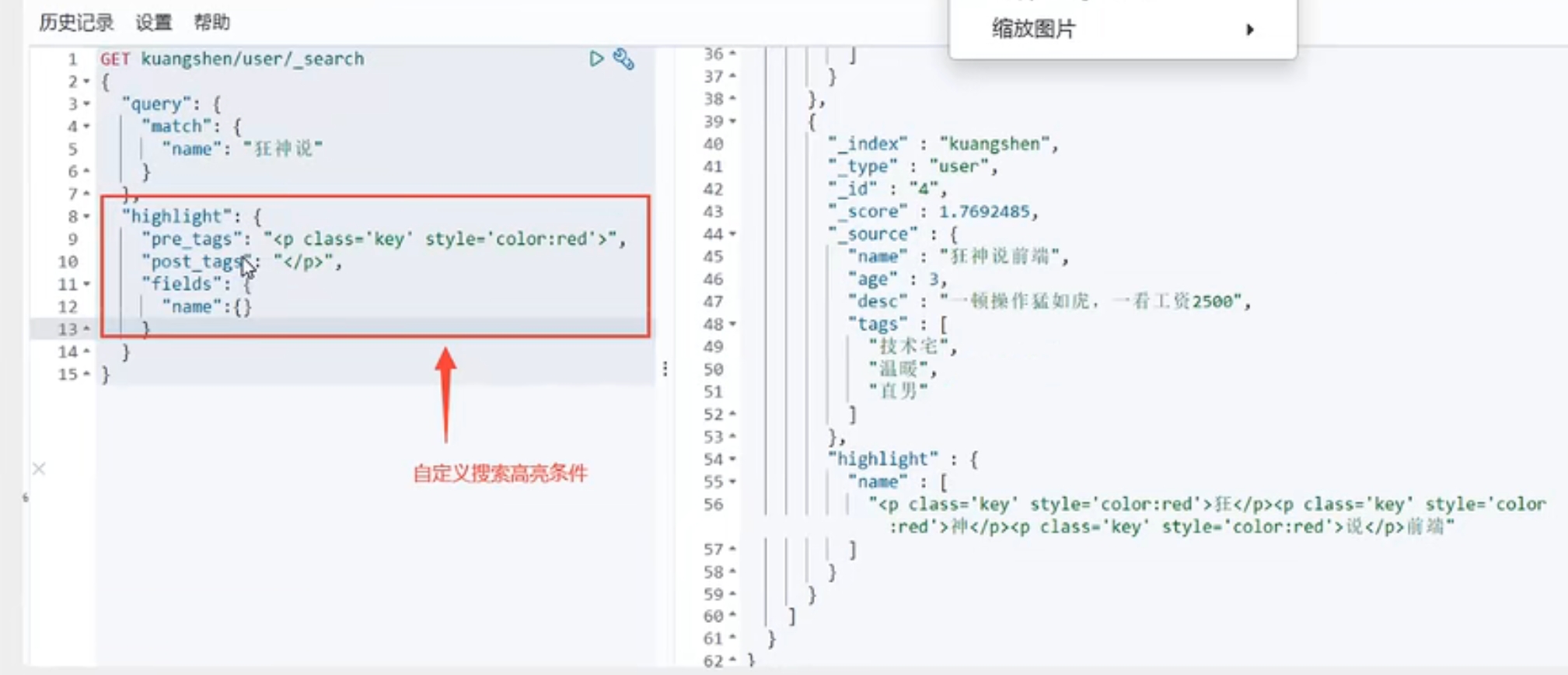
高亮查询: