
m5
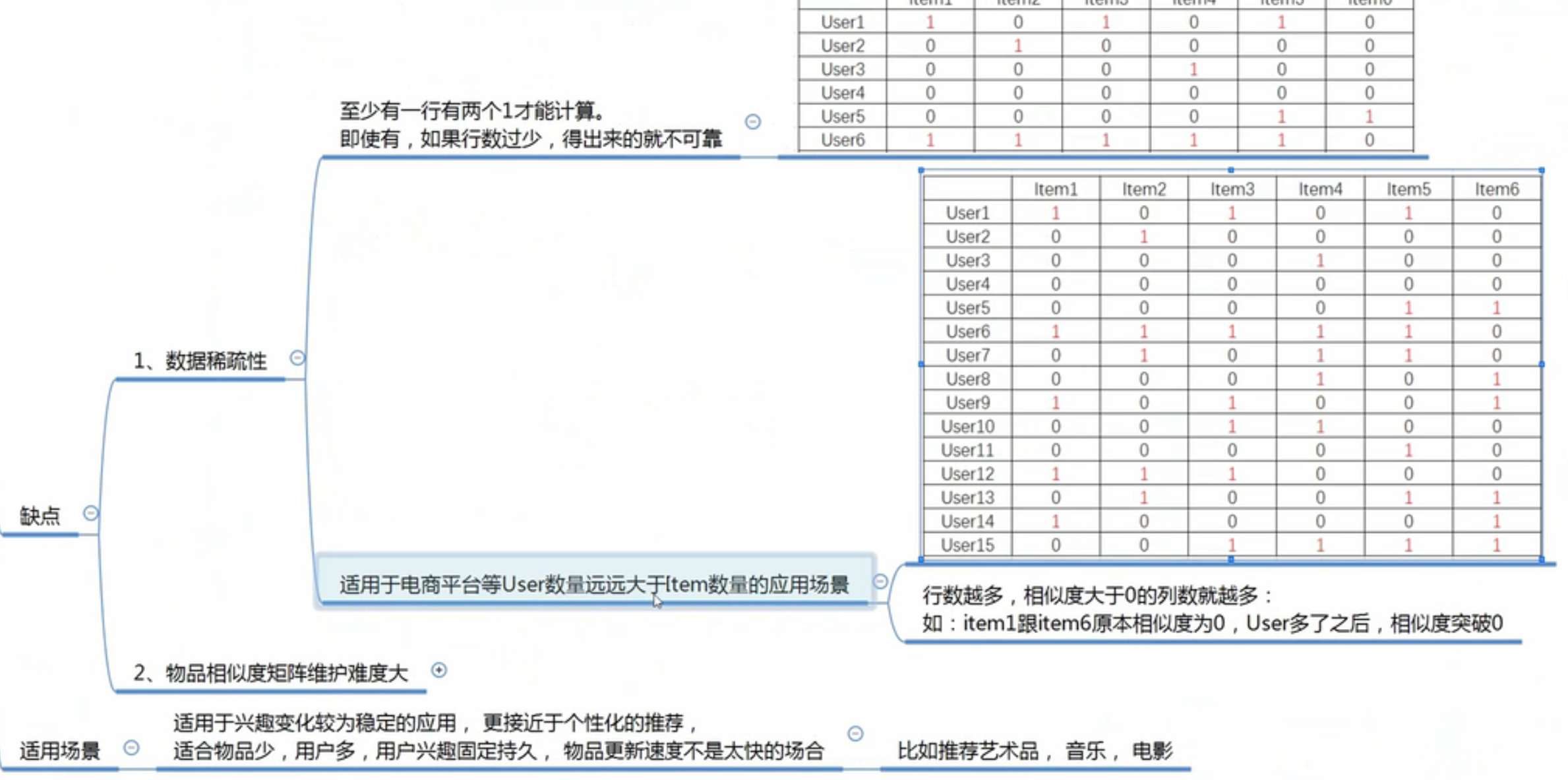
1、冷启动挑战:
1️⃣我们一般对新用户知之甚少, 所以基本不知道用户的真实兴趣,从而很难为用户推荐他喜欢的标的物;
2️⃣对于新的标的物,我们也不知道什么用户会喜欢它,很多时候标的物的信息不完善、包含的信息不好处理、数据杂乱,或者是新标的物产生的速度太快(如新闻类,一般通过爬虫可以短时间爬取大量的新闻),短时间类来不及处理或者处理成本太高,或者是完全新的品类或者领域,无法很好的建立与库中已有标的物的联系,所有这些情况都会增加将标的物分发给喜欢该标的物的用户的难度。
3️⃣系统冷启动:对于新开发的产品,由于是从零开始发展用户,冷启动问题就更加凸显,这时每个用户都是冷启动用户
详细:https://zhuanlan.zhihu.com/p/383215315
2、协同过滤
就是协同大家一起来对海量的信息进行处理过滤,从中筛选出目标用户可能感兴趣的信息的推荐过程,具体来说给定共现矩阵(用户和物品的打分矩阵),进行点击率预估,评分预测等,可以划分为:
【基于用户的协同过滤(UserCF)】
找最相似的用户去预测目标用户的分数,具体步骤:
1️⃣计算目标用户与其他用户的相似度(相似度矩阵),用下图的每个行向量
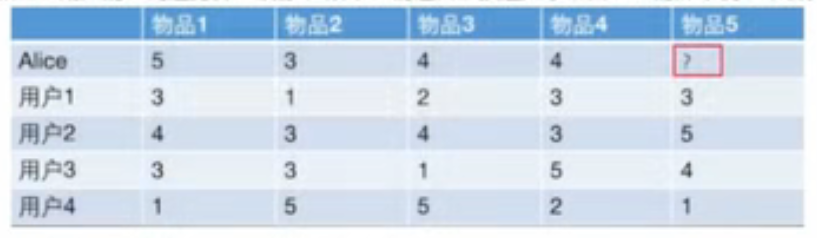
2️⃣根据相似度计算目标用户对物体的评分
评分方法1:

评分方法2,此处的平均分是行向量的平均:

3️⃣定一个阈值,超过这个阈值,推荐给目标用户
缺点和适用场景:时效性强代表很多用户都会看

【基于物品的协同过滤(ItemCF)】
找最相似的物品去预测目标物品的分数,具体步骤:
1️⃣计算目标物品与每个物品的相似度(相似度矩阵),此时用列向量
2️⃣假定物品1和物品2与物品5最相似,计算得分,此处的平均分是列向量的平均分:

3️⃣推荐
优点:

userCF和itemCF共同的缺点:

3、相似度计算方法:
1️⃣欧氏距离,欧式距离度量的是空间中两个点的绝对差异,适用于分析用户能力模型之间的差异,比如消费能力、贡献内容的能力等。欧式距离不适合布尔向量(向量值为0/1,不是实数)。

通常相似度计算度量结果希望是[-1,1]或者[0,1]之间,因此公式可以做改进:距离加一后取倒数。这个公式能够把范围为 0 到正无穷的欧式距离转换为 0 到 1 的相似度。

2️⃣余弦相似度
它的特点:它与向量的长度无关,度量的是两个向量之间的夹角,余弦相似度在度量文本相似度、用户相似度、物品相似度的时候都较为常用;
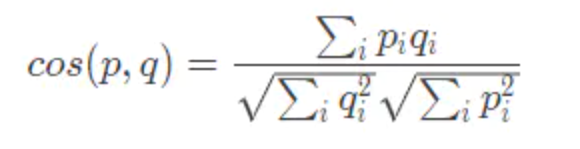
在协同过滤中,如果选择余弦相似度,某种程度上更加依赖两个物品的共同评价用户数,而不是用户给予的评分多少。这就是由于余弦相似度被向量长度归一化后的结果。比如,我用 140 字的微博摘要了一篇 5000 字的博客内容,两者得到的文本向量可以认为方向一致,词频等程度不同,但是余弦相似度仍然认为他们是相似的。余弦相似度对绝对值大小不敏感这件事,在某些应用上仍然有些问题。 举个小例子,用户 A 对两部电影评分分别是 1 分和 2 分,用户 B 对同样这两部电影评分是 4 分和 5 分。用余弦相似度计算出来,两个用户的相似度达到 0.98。这和实际直觉不符,用户 A 明显不喜欢这两部电影。 针对这个问题,对余弦相似度有个改进,改进的算法叫做调整的余弦相似度(Adjusted Cosine Similarity)。调整的方法很简单,就是先计算向量每个维度上的均值,然后每个向量在各个维度上都减去均值后,再计算余弦相似度。 前面这个小例子,用调整的余弦相似度计算得到的向量是(-1.5,-1.5),(1.5,1.5),改进相似度是 -0.1,呈现出两个用户口味相反,和直觉相符。
3️⃣皮尔逊相关度
实际上也是一种余弦相似度,不过先对向量做了中心化,向量 p 和 q 各自减去向量的均值后,再计算余弦相似度。皮尔逊相关度计算结果范围在 -1 到 1。-1 表示负相关,1 比表示正相关。皮尔逊相关度其实度量的是两个随机变量是不是在同增同减。 如果同时对两个随机变量采样,当其中一个得到较大的值另一也较大,其中一个较小时另一个也较小时,这就是正相关,计算出来的相关度就接近 1,这种情况属于沆瀣一气,反之就接近 -1。 由于皮尔逊相关度度量的时两个变量的变化趋势是否一致,所以不适合用作计算布尔值向量之间相关度,因为两个布尔向量也就是对应两个 0-1 分布的随机变量,这样的随机变量变化只有有限的两个取值,根本没有“变化趋势,高低起伏”这一说。
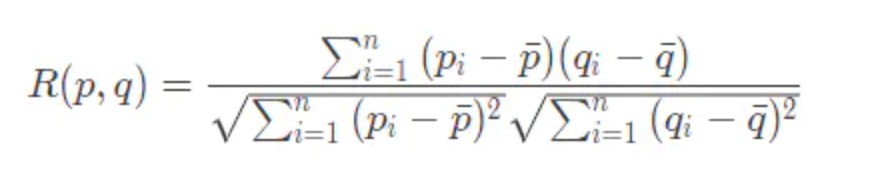
4️⃣杰卡德(Jaccard)相似度
杰卡德相似度,是两个集合的交集元素个数在并集中所占的比例。由于集合非常适用于布尔向量表示,所以杰卡德相似度简直就是为布尔值向量私人定做的。对应的计算方式是:
- 分子是两个布尔向量做点积计算,得到的就是交集元素个数;
- 分母是两个布尔向量做或运算,再求元素和。
余弦相似度适用于评分数据,杰卡德相似度适合用于隐式反馈数据。例如,使用用户的收藏行为,计算用户之间的相似度,杰卡德相似度就适合来承担这个任务。

【工具】
Faiss和annoy工具都能根据现成的向量,按照定义好的相似度方法,如欧式距离,去向量库找与它最相似的TopK个向量
annoy底层是根据相似度进行多次递归地划分空间,然后构建二叉树,样本点分散在二叉树的叶子中,越相似的样本点所在叶子越接近,查找某样本点的TopK时,就从根开始走到叶子,build函数指定的树的个数只影响精度,个数越大,精度越高
定义:余弦距离:1-cos(A,B)
当向量的模长是经过归一化的,此时欧氏距离与余弦距离的关系:
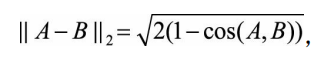
0.5*cos+0.5能对consin做进一步处理,映射到[0,1]也能表示相似度;
from annoy import AnnoyIndex import random f = 40 # 向量的维度 t = AnnoyIndex(f, 'angular') # f:向量的维度,angular:以归一化(两个向量的模长都=1)的欧式距离为根据 for i in range(1000): v = [random.gauss(0, 1) for z in range(f)] # 随机构造一个长度为 f 的向量 t.add_item(i, v) # 添加向量,每个向量开头是这个向量的编号 t.build(10) # 树的个数,越大精度越高 print(t.get_nns_by_item(0, 1000,include_distances=True)) # 找到离0号向量最近的1000个邻居,并返回与它之间的归一化的欧式距离
3、MF
矩阵分解针对的问题是:协同过滤处理的稀疏矩阵能力比较弱,相似度矩阵维护难度大
下图的缺乏历史行为指的是对于刚来的新用户,不好找他的隐向量
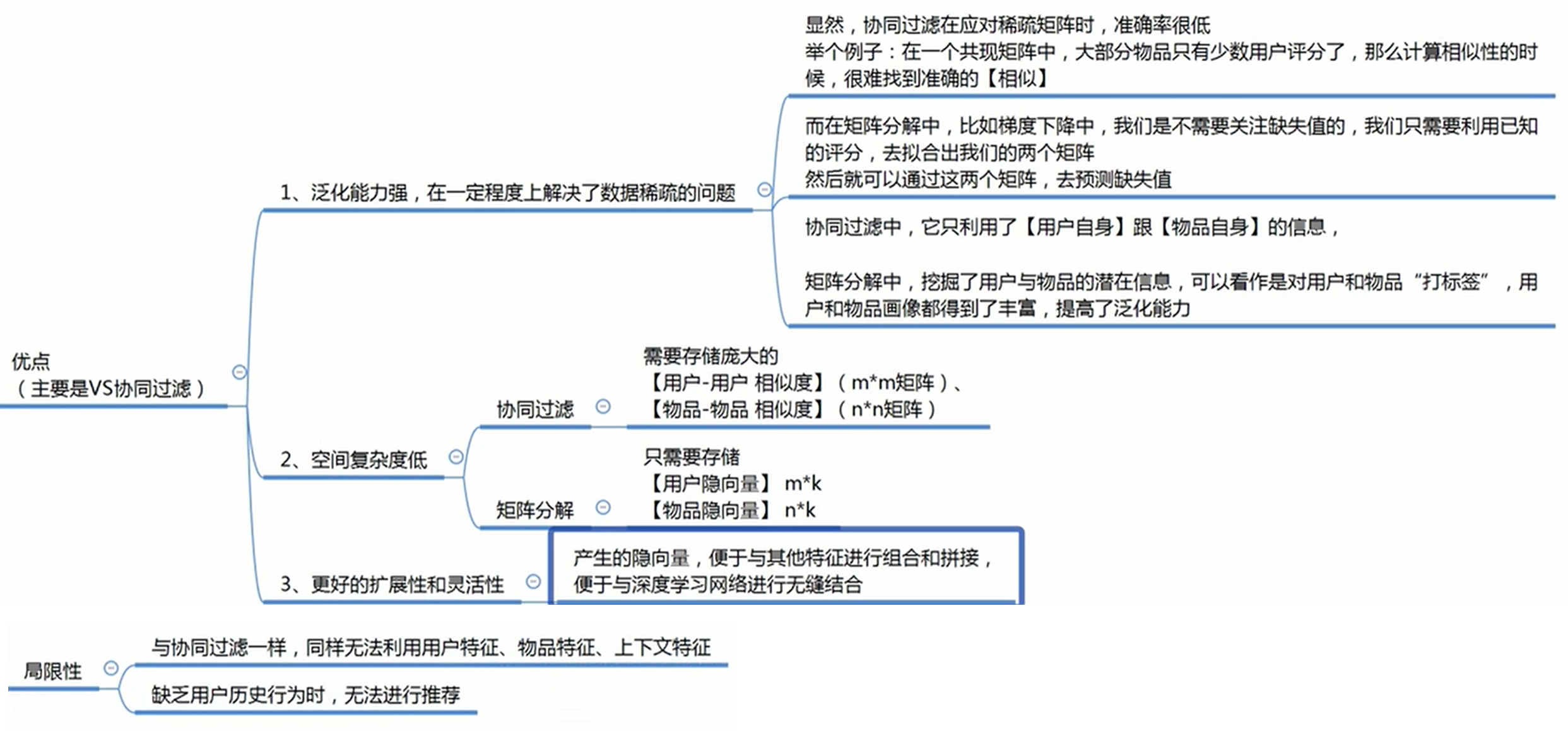
【basic SVD=LFM=funk svd】
根据已有的分数不断训练U、V,使得 A = U*V,这样就把A的里面缺失值算出来了

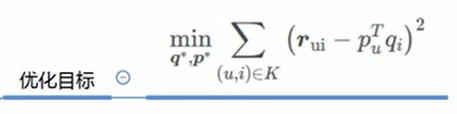
【RSVD】

对预测值公式更新,其中用户评分偏差和物品得分偏差是需要训练的参数:

损失函数加上了对U、V、2个偏差参数 的 l2 正则项,其他的和basic svd一样,训练之后分U、V相乘就不=A了,还需要加偏差和平均数
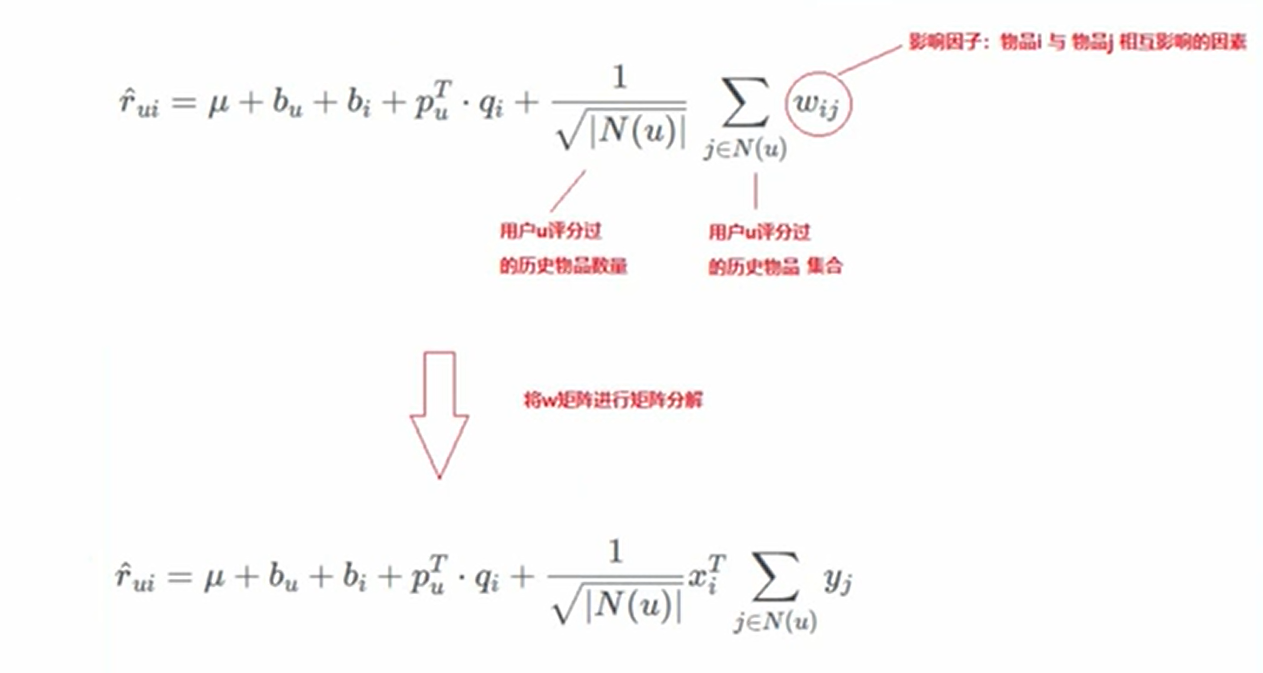
【SVD++】

在RSVD的基础上,对预测值公式更新,加上了其他物品对要预测物品的关系,由于又出现了物品与物品之间的大关联度矩阵,对该矩阵分解为2个矩阵的乘积:

4、POLY2模型
如果是二分类问题,如用户是否点击,将原来的单个属性值如性别,按照属性的离散取值生成多个特征,如男作为x1特征,女作为x2特征,其他的属性列同理,由此可以按照用户的属性和商品的属性全部生成一个个单独的特征:x1,x2,x3,x4...xn,同时再做特征交叉:特征之间两两组合形成新特征,如x1*x2做为新特征,x1*x3作为新特征...按照逻辑回归的方法,假设现在所有的特征为X,定义参数W,sigmoid(w*x)作为样本的预测值,计算交叉熵损失,梯度下降法更新参数W,如果是回归问题,就不用通过sigmoid了,损失函数改为 MSE:
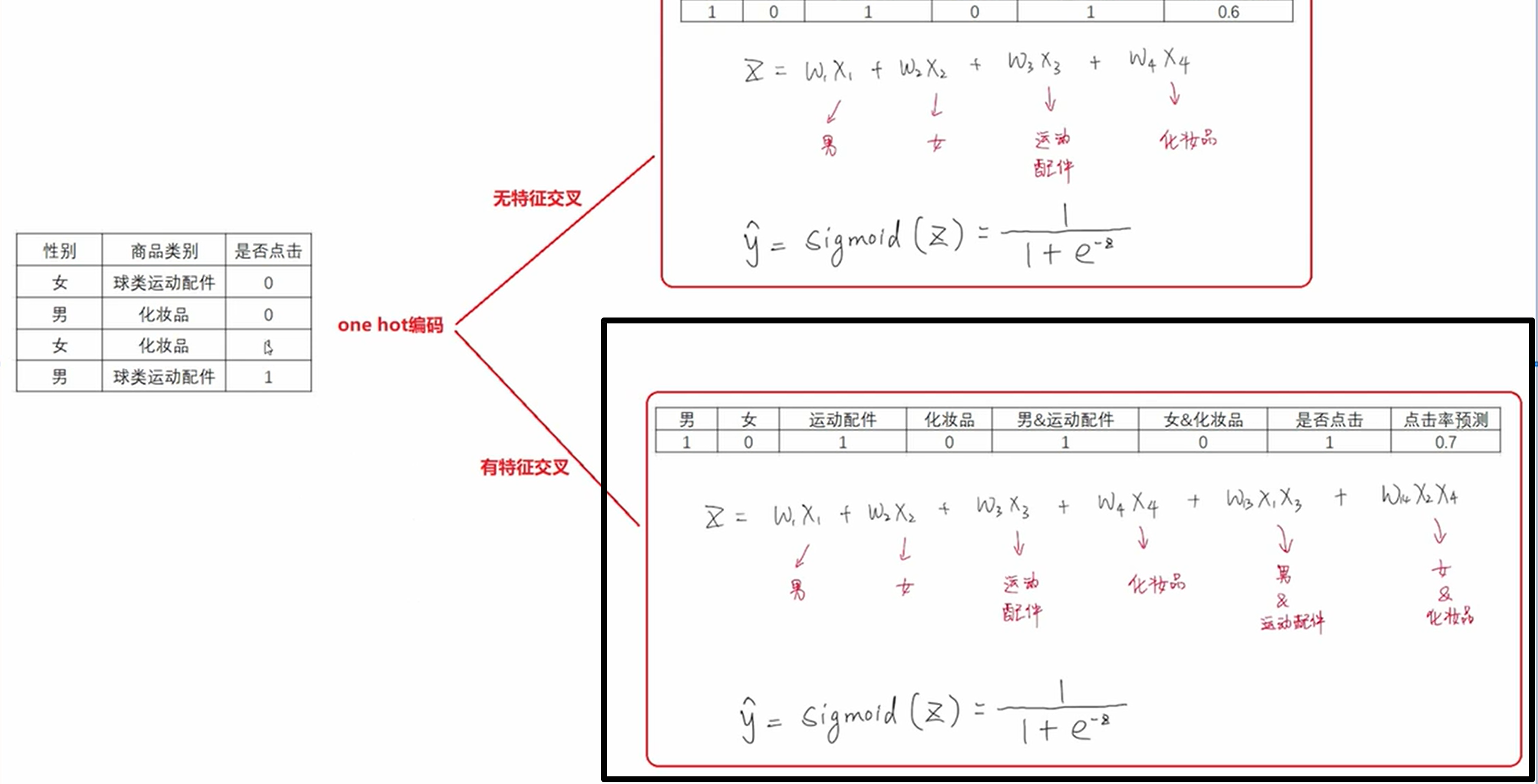

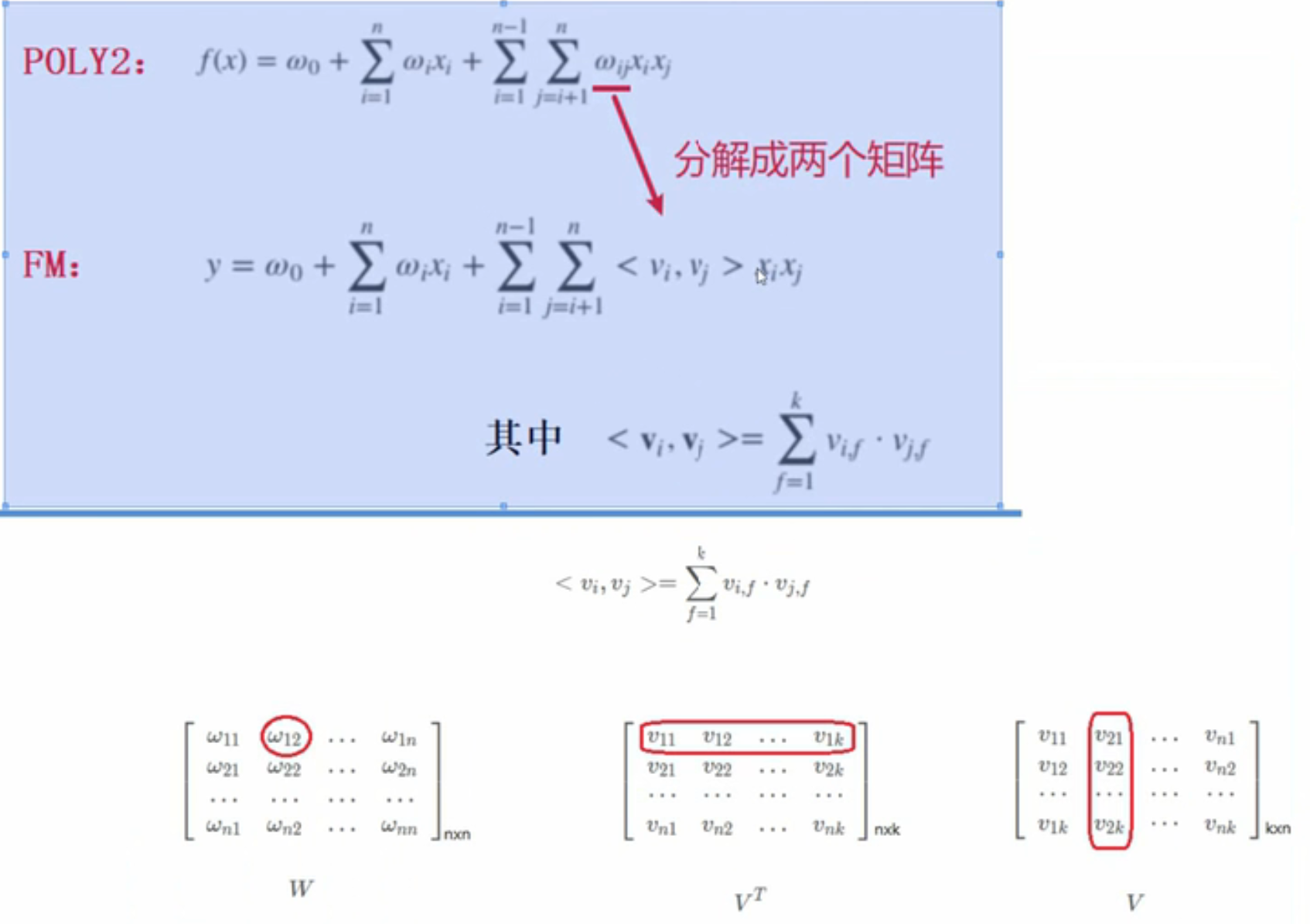
5、FM模型
针对问题:计算poly2复杂度高;得维护一个二阶特征的权重系数矩阵,很占内存
理论依据:
![]()
改进就是,每个单特征(非组合特征)给一个 k 维的特征隐向量向量,把2个特征交叉前面的权重系数分解为这两个特征隐向量乘积:

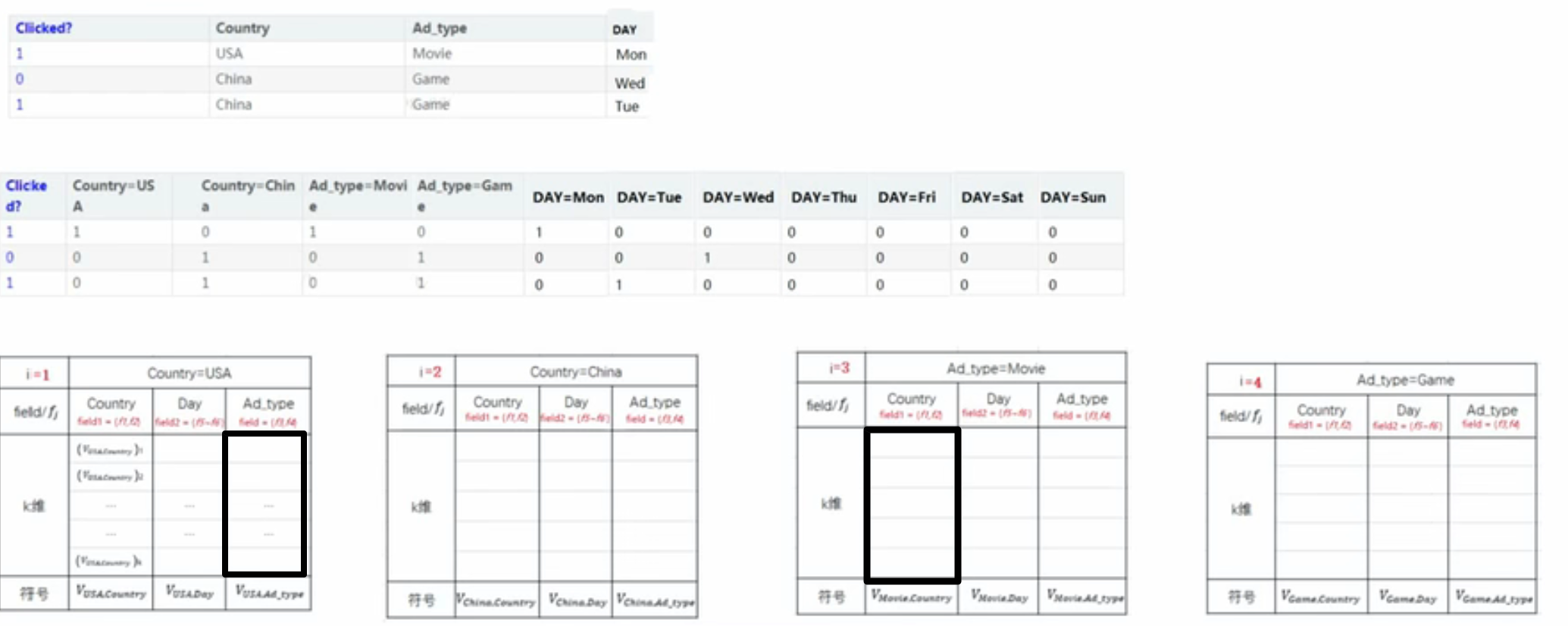
6、FFM
引入特征域的概念,比如男和女都属于性别特征域,星期一、二、三都属于星期的特征域。此时每个单特征下有x个特征隐向量,x是特征域的个数
若x1*x3,则找到x1下的x3所属的特征域的隐向量*x3下的x1所属的特征域的隐向量作为权重
公式中是在特征交叉的前面的权重有变化:
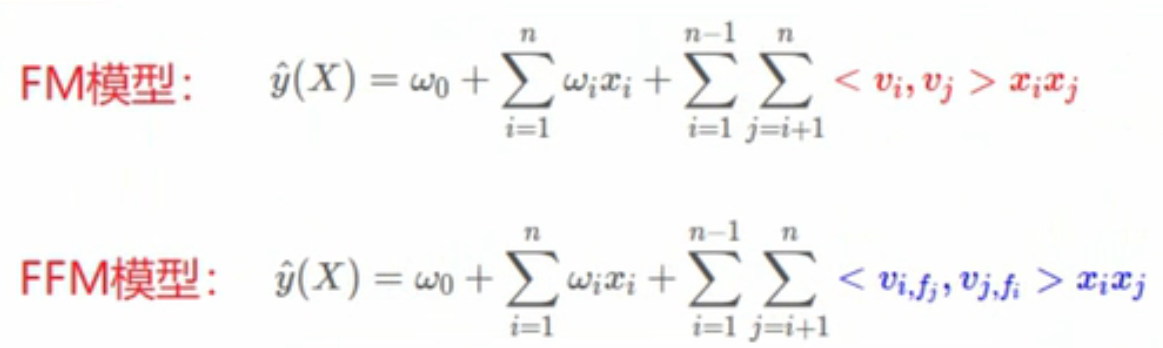
举例:x1*x3(country=USA,adtype=movie)前面的权重:

7、GBTD+LR
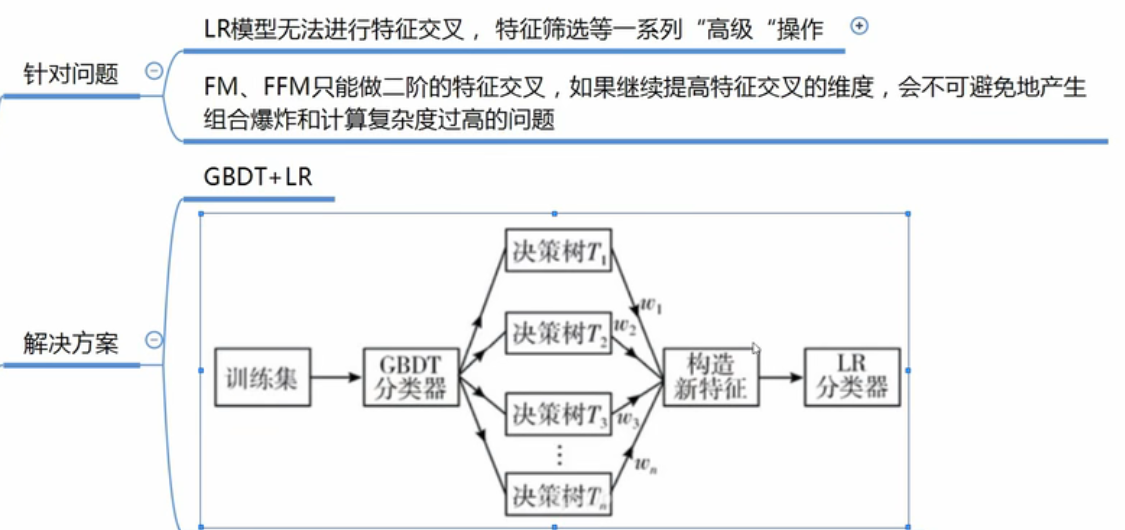
先根据二分类问题训练好GBTD,GBTD的作用就是进行多特征的组合和筛选,不同的样本能有不同的特征选择和组合,一个样本输入到GBTD后,会输出这个样本的特征筛选和组合后的结果:
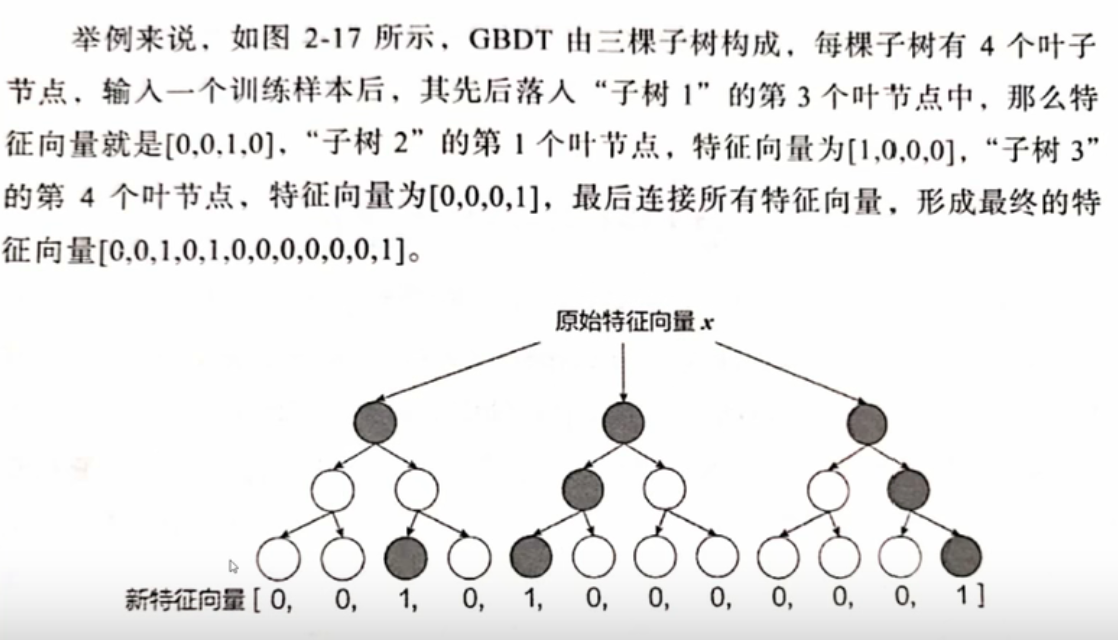
再初始化一个对应长度的参数向量与它相乘,这一项作为公式中特征组合的那一项,其他一致

8、MLR=LS-PLM
使用于二分类模型,MLR用分片线性模式来拟合高维空间的非线性模式。把所有特征分成m个组,每个组有参数向量wi,ui,对于第一组而言,用 lr 算出该组概率后再乘以 用softmax求出来的该组的权重,其他组类似,然后所有组的结果相加,即把多个LR模型进行加权。m越大拟合的越好,但是容易过拟合,计算量也更大
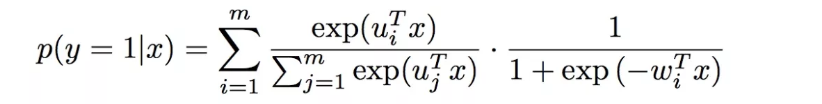
假定有参数向量是d维,每个特征对应2m个参数,参数矩阵为:
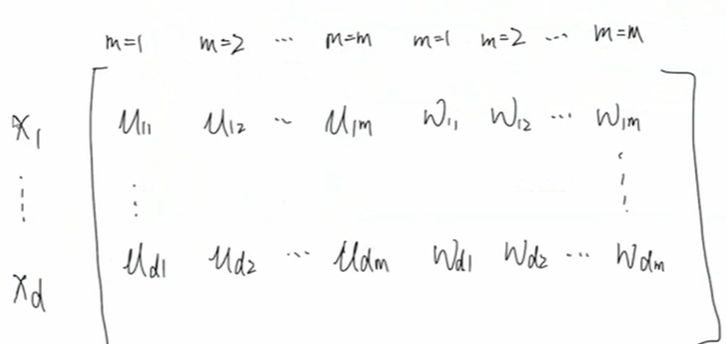
目标函数:

9、NeuralCF
Neural CF模型是从传统的 MF 的基础上进行的改进, 把MF里面隐向量的点积操作换成了多层的神经网络, 使得两个向量可以做更充分的交叉, 得到更多有价值的特征组合信息, 另外一个就是神经网络的激活函数可以引入更多的非线性, 让模型的表达能力更强。
原始模型:
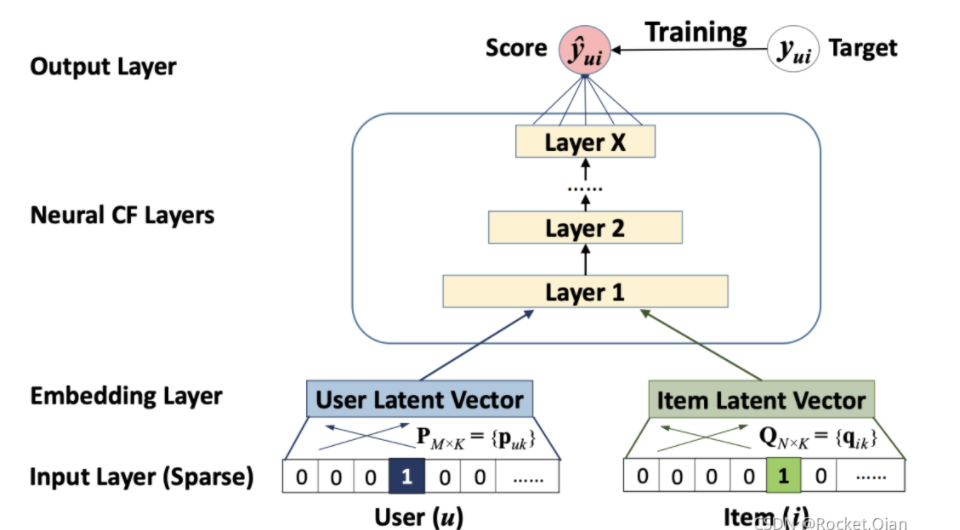
输入为user和item的id,把他们进行onehot编码,然后使用单层神经网络进行降维即Embedding化。2个向量拼接然输入到多层神经网络,用来捕获用户-物品的交互非线性关系,增强模型的表达能力。每层的非线性通过ReLu来激活,可以防止sigmoid带来的梯度消失问题。如果是二分类问题,结尾再通过一个sigmoid函数。
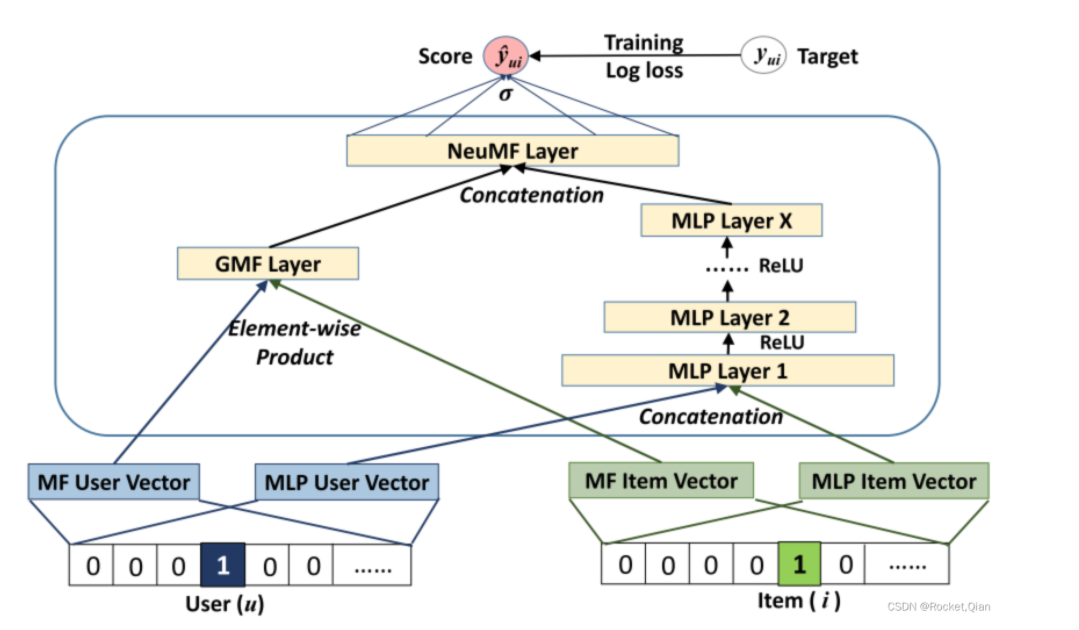
原始模型可以和广义矩阵分解GMF进行结合。GMF就是在两个隐向量元素积后接了一个只有1个神经元的输出层,当权重向量为1且没有激活函数时,GMF退化成MF,GMF公式:

举例:(1,2,3) * (4,5,6) =>(4,10,18), sigmoid ( W*(4,10,18) )
和神经网络的结合后,模型允许GMF和神经网络学习独立的嵌入,左边的一个GMF层, 接收用户和物品的embedding向量, 然后做一个元素积element-wise运算生成一个向量就可以了。 右边是一个多层的神经网络, 接收的是用户和物品的另一种embedding向量, 然后经过了多个全连接层,最后2个层的输出向量拼接起来再经过一个全连接层得到最后的输出,如果是2分类问题再通过sigmoid。
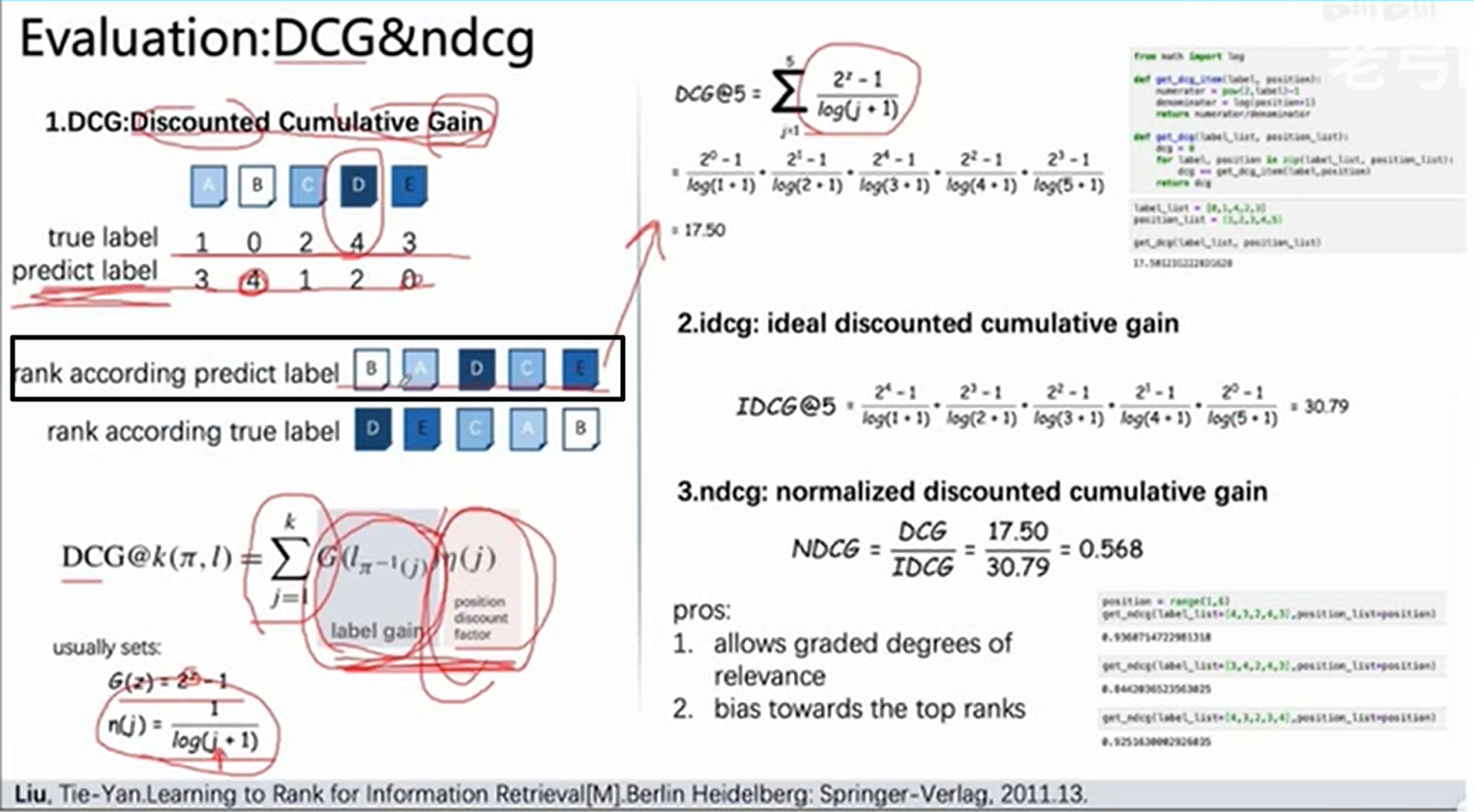
由于推荐模型还包括排序,因此模型的评估指标可以引入NDCG,范围在[0,1],越大说明模型越好,假定用户对A,B,C,D,E电影的评分分别为1,0,2,4,3,模型的预测评分为....,按照模型的预测进行排序,然后从头开始带入用户的真实评分,作为DCG的分子,分母的 j 都是从1开始,IDCG的分子都是从最高分到最低分,代表模型理想的情况(预测值与真实值完全一致),最后NDCG = DCG / IDCG

10、PNN

模型:
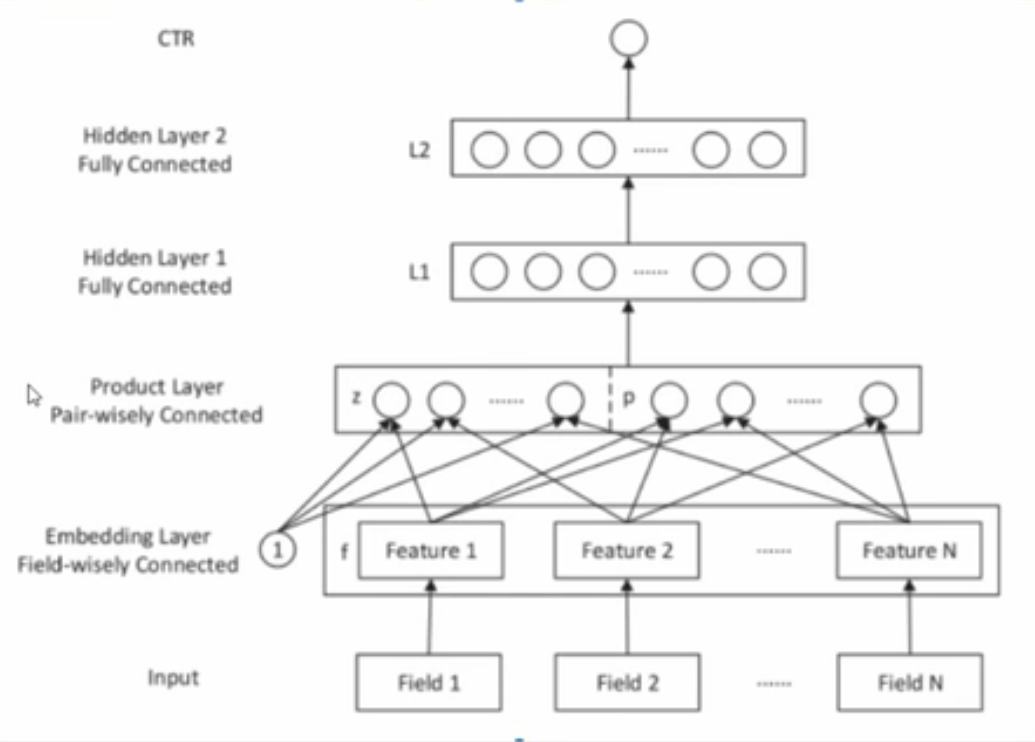
假定一个样本既包含数值特征也包含离散特征,标签是二个类别,C20=2可以理解为星期这个属性取值为星期2:

先处理所有离散特征,将各个离散列处处理成one-hot形式作为输入层,比如c18的one-hot是field1,c19是field2,然后每个field通过embedding层降维成小向量,向量长度都一样,接下来就是product层
product层分为2部分z和p
z的计算:将所有feature拼成1个整体的大向量,然后通过乘以一个参数矩阵(通过一个全连接层)生成一个新向量作为z
p的计算,p有两个模式可选,inner模式和outer模式
inner模式:所有的 feature 两两内积(2个向量内积结果是一个数),生成f1*f1,f1*f2,....fn*fn,将这些数拼成一个大向量,通过一个全连接层生成新向量作为p
outte模式:所有的 feature 两两外积(2个向量外积结果是一个矩阵,列向量*行向量),生成f1。f1,f1。f2,....fn。fn,将这些矩阵全部相加形成新矩阵(该步可能会忽略原始有价值的特征),再把矩阵展成一个大向量,通过一个全连接层生成新向量作为p
所以product层的输出=relu ( a, z+p+b ),b是一个偏置向量,a 是样本中的数值特征l1,l2,l3...l10,l 和后面的向量和拼接,再通过relu,作为 l1层的输入
随后就是多层网络的堆叠

11、Wide&Deep模型

【wide】
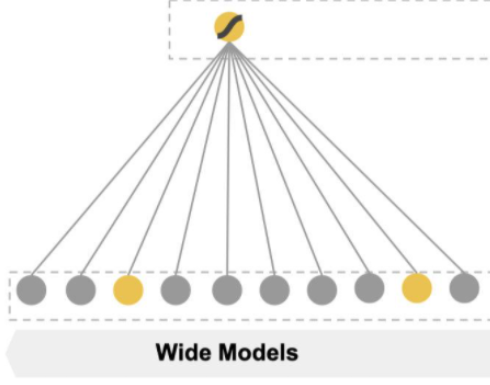
整体上是一个线性模型:w*x+b。特征x包含两个部分,一种是原始数据直接拿过来的特征,另外一种是我们经过特征转化之后得到的特征,一般组合二值稀疏特征,如(性别,喜好),这类组合特征值是里面的特征列的值直接相乘,只有各个特征列同时为1结果才是1,所以等价于(性别=A & 喜好=b )。通过这种方式我们可以捕捉到特征之间的交互,以及该组合特征与标签的关系。因为模型采用在线学习方式:

所以优化器采用FTRL算法,L1正则化,而不是梯度下降,它兼顾了模型稀疏性(更错参数=0)和精度:

【deep】
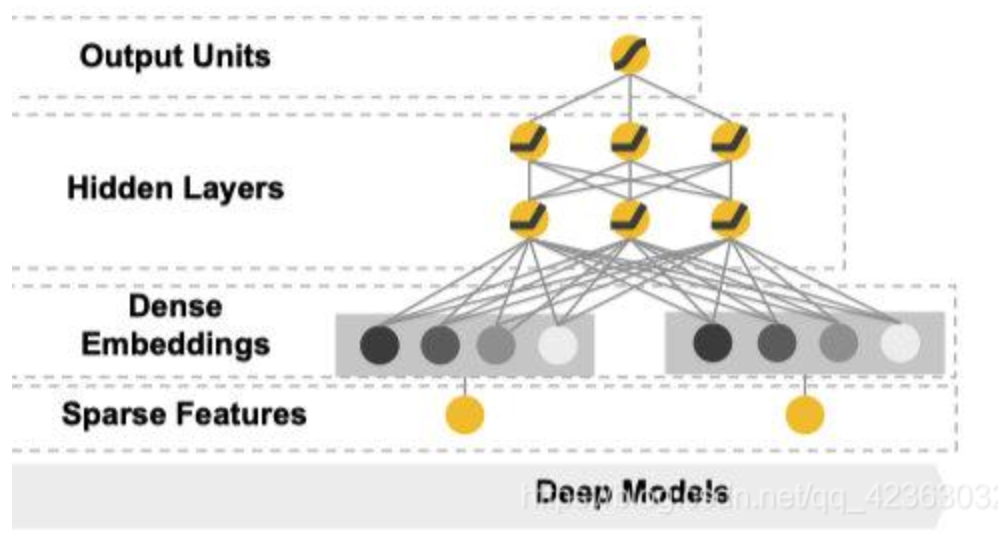
将离散的特征分别通过embedding层映射成1个个词向量,所有词向量和特征中的数值列特征进行拼接,然后通过多层神经网络,最后得到一个输出。优化器采用AdaGrad:

12、Deep&Cross模型
2阶就是2个特征的交互,3阶是3个

模型:
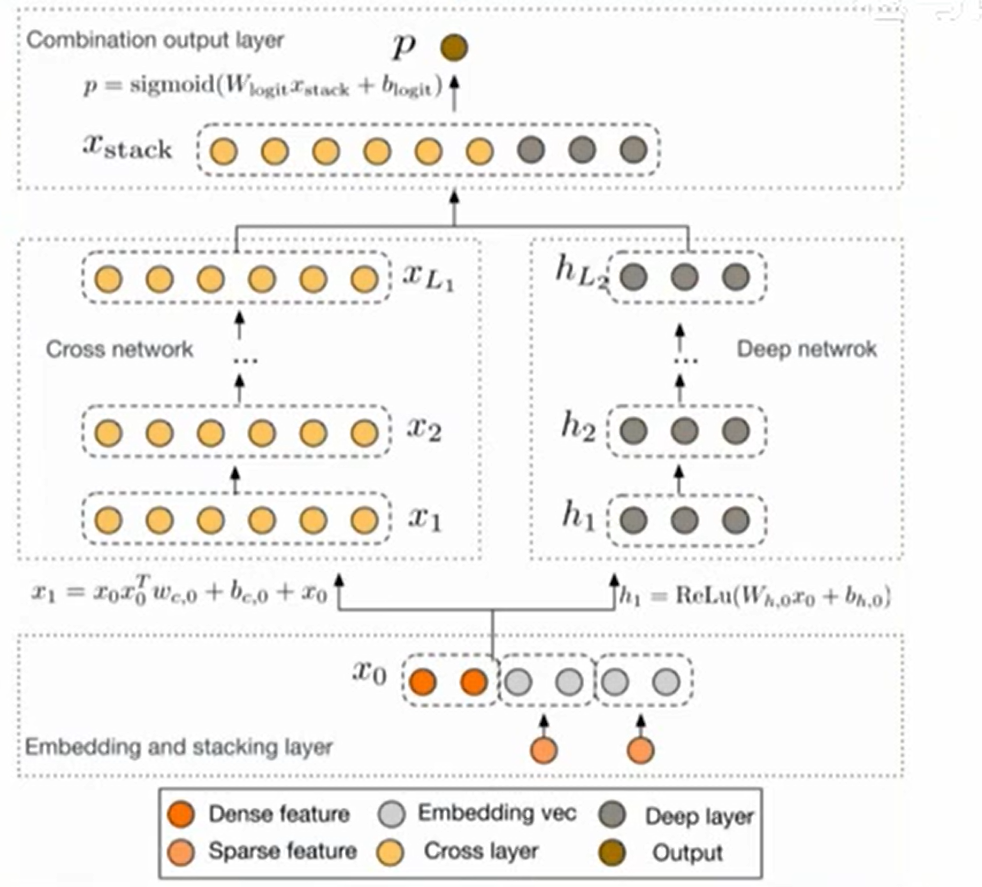
输入的时候,将每个离散(稀疏)特征通过embedding映射为向量,所有向量和数值(dense)特征拼接成1个大向量作为x0,右边输入到deep网络,左边输入到cross net,xl表述第 l 层的输出,每层的维度都和x0保持一致,从x1开始算,计算公式:

最后cross的输出和deep输出进行拼接,然后通过全连接输出1个结果。
分析:
当cross layer叠加层时,交叉最高阶可以达到
阶,并且包含了所有的交叉组合,并不需要人为设计的特征工程,可以获得随网络层数增加而增加的多项式阶(polynomial degree)交叉特征,这是DCN的精妙之处。
复杂度分析:假设表示cross layers的数目,
表示输入
的维度。那么,在该cross network中涉及的参数数目为:
。
一个cross network的时间和空间复杂度对于输入维度是线性关系。因而,比起它的deep部分,一个cross network引入的复杂度微不足道
13、FNN

模型:
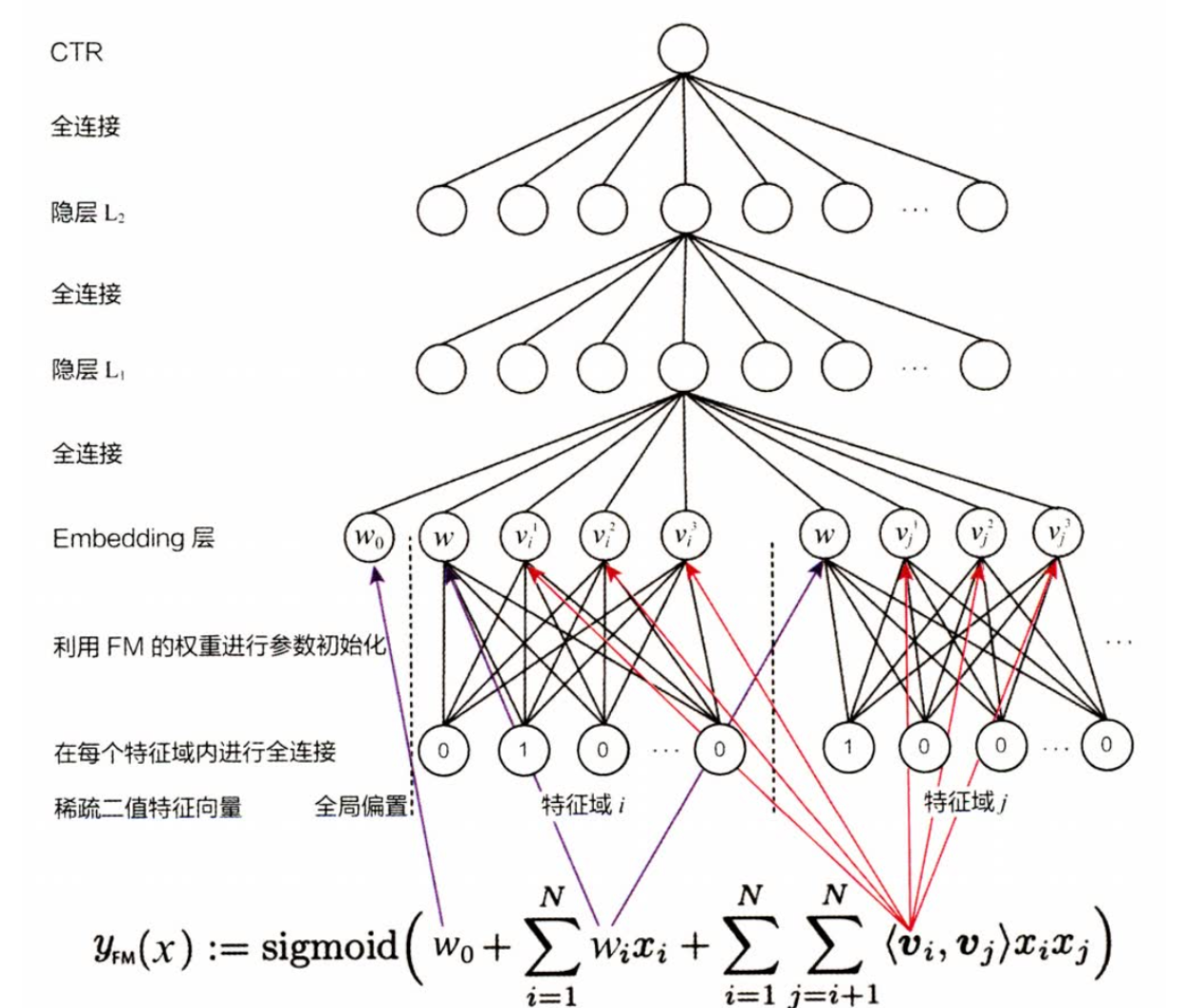
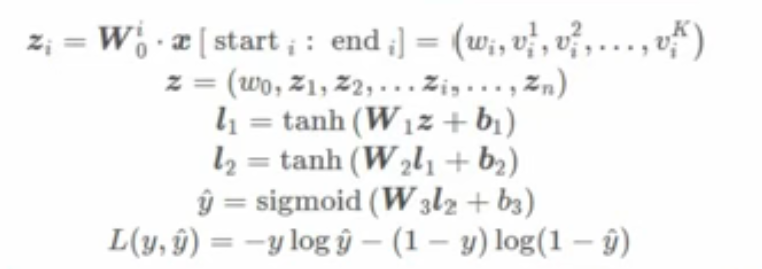 、
、
第一阶段:先通过FM模型训练出来每个特征的隐向量vi和权重参数,第二阶段:隐向量vi和参数wi作为特征xi的初始化embedding向量(相当于在初始化DNN(神经网络)的embedding向量时引入了先验知识,因此能够更好更快的收敛DNN)然后把所有隐向量和参数(所有embedding向量)全部拼接起来,输入到多层神经网络再训练

14、DeepFM
DeepFM 是 Deep 与 FM 结合的产物,也是 Wide&Deep 的改进版,只是将其中的 LR 替换成了 FM,提升了模型 wide 侧提取信息的能力,综合考虑了前面所有模型的缺点。
优点:
1 两部分联合训练,无需加入人工特征,更易部署;
2 结构简单,复杂度低,两部分共享输入,共享信息,可更精确的训练学习。
缺点: 将类别特征对应的稠密向量拼接作为输入,然后对元素进行两两交叉。这样导致模型无法意识到域的概念
那FM 本来就可以在稀疏输入的场景中进行学习,为什么要跟 Deep 共享稠密输入呢?虽然 FM 具有线性复杂度 O(nk),其中 n 为特征数,k 为隐向量维度,可以随着输入的特征数线性增长。但是经过 onehot 处理的类别特征维度往往要比稠密向量高上一两个数量级,这样还是会给 FM 侧引入大量多于的计算,不可取。
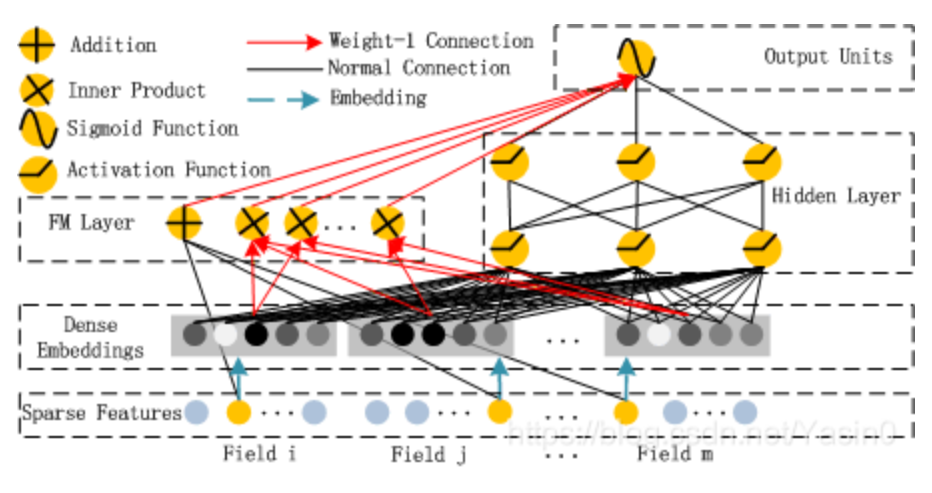
先将离散的特征通过embedding映射为一个个向量,然后与数值特征一起拼成一个长向量作为 Deep 与 FM 的输入。对于FM:

FM 有两部分,线性部分和交叉部分。线性部分 (黑色线段) 是给与每个特征一个权重,然后进行加权和;交叉部分 (红色线段) 是对特征进行两两相乘,然后赋予权重加权求和。然后将两部分结果累加在一起即为 FM Layer 的输出。
Deep 部分就是多层的神经网络,一般会映射到1维,因为需要与 FM 的结果进行相加,即高阶与低阶特征交互的融合,然后相加和经过 Sigmoid 非线性转换,得到预测的概率输出。
15、NFM
NFM模型也结合了FM二阶交叉的线性和神经网络的非线性,能够进一步提升模型的表达能力。NFM网络架构的特点非常明显,就是在Embedding层和神经网络层之间加入特征交叉池化层。模型:
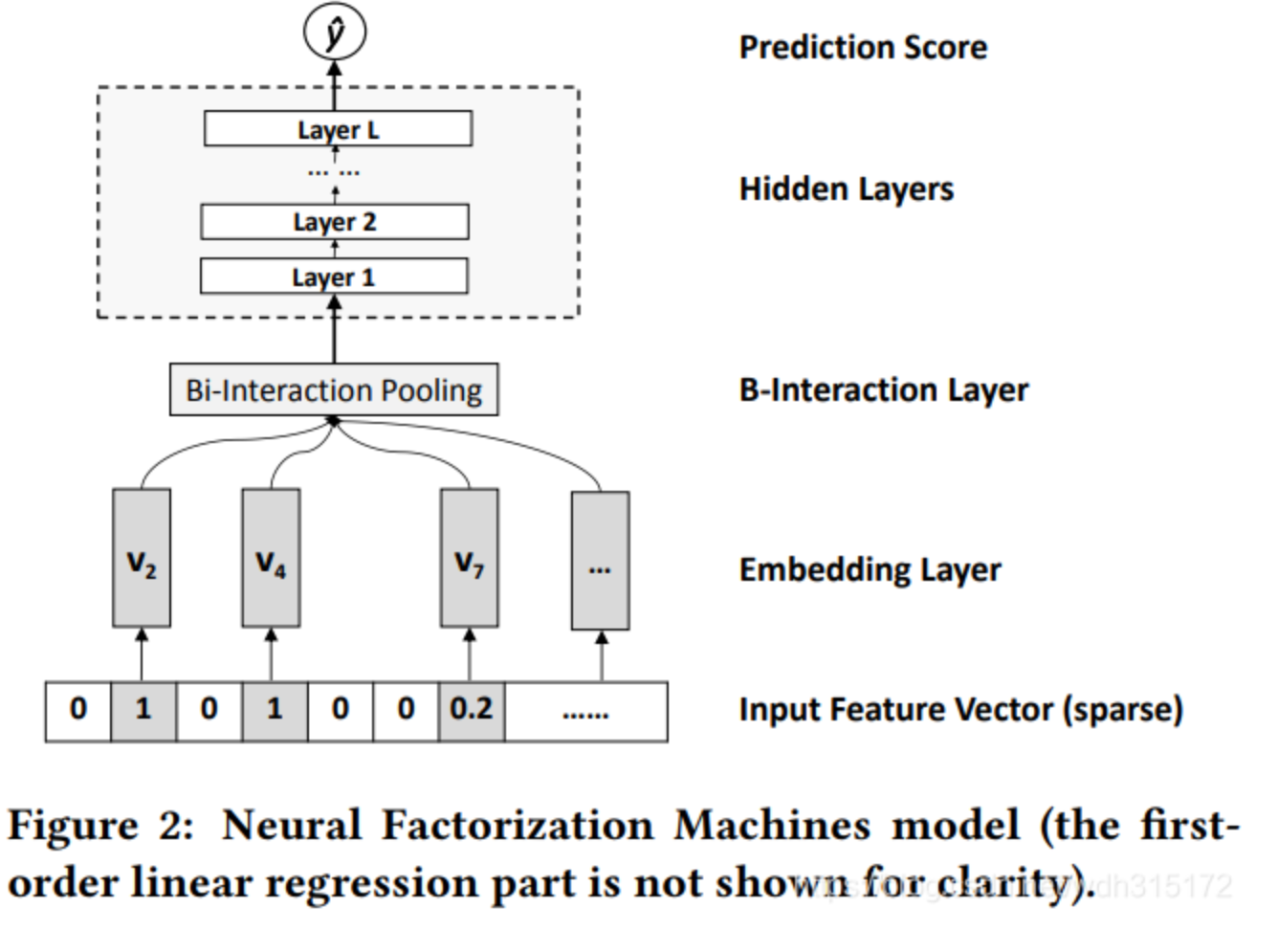
输入层是对每个离散特征进行embedding,得到每个特征的K维的v向量,然后通过特征交叉池化层,先将各个特征值和自己的向量相乘,然后这些向量互相做element-wise元素积,元素积的结果还是K维向量,然后所有向量相加,结果还是K维。用公式表示:

然后向上输入到 神经网络 部分
16、AFM模型 —— 引入注意力机制的FM


模型:
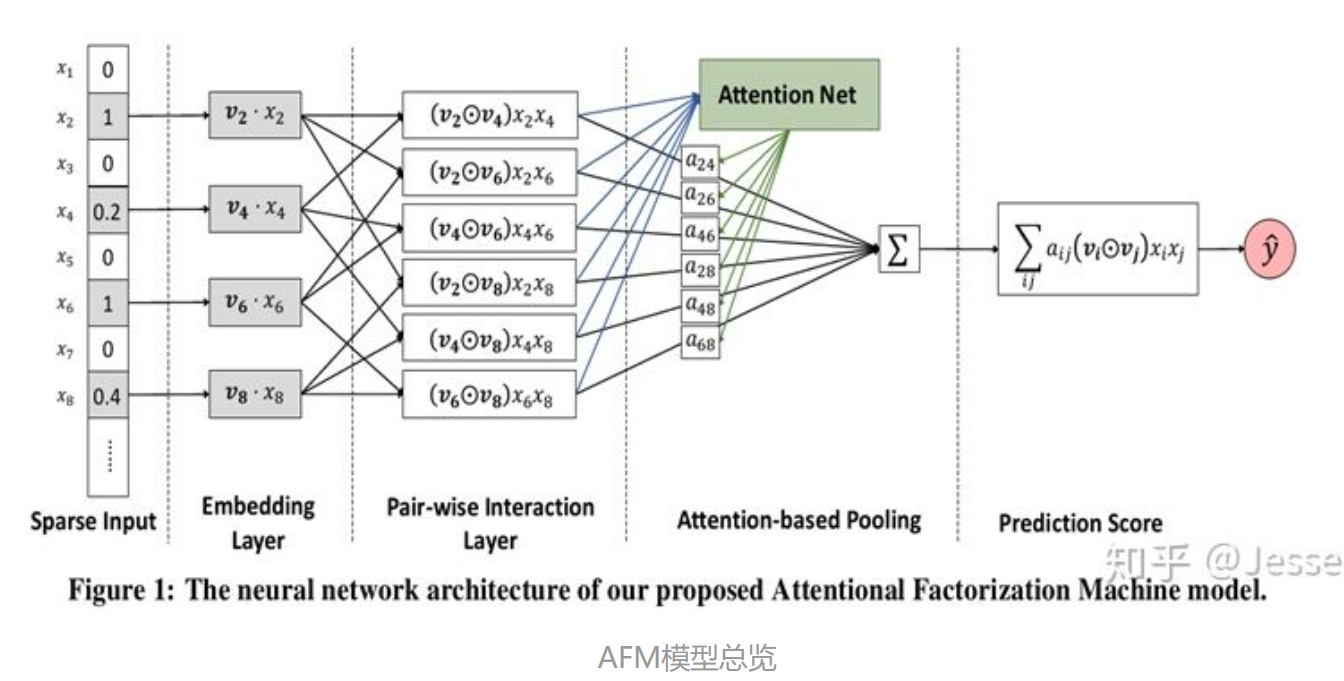
改进就是对向量加和的改进(上面的黑体),分为3层,在Pair-wise Interaction Layer中,这一层主要是对组合特征进行建模,原来的m个嵌入向量,通过element-wise product(哈达玛积)操作得到了m(m-1)/2个组合向量Interacted vector,这些向量的维度和嵌入向量的维度相同均为k。形式化如下:
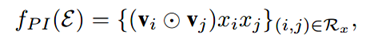
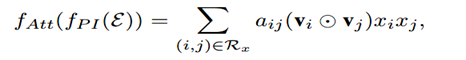
但Attention score的学习是一个问题。一个常规的想法就是随着最小化loss来学习,但是存在一个问题是:对于训练集中从来没有一起出现过的特征组合的Attention score无法学习。
为了解决泛化问题,引入含有t个神经元的Attention network,每个Interacted vector通过Attention net后先映射为 t 维向量然后与向量 h 相乘得到一个数a'ij,然后通过一个softmax得到aij:

最终Attention-based Pooling输出一个加权的向量和,然后和数值特征拼接成大向量,输出层将其再映射成一个数值
17、DIN
Base模型考虑到了用户的历史购买商品(行为)goods1,goods2,...goodsn,然后直接对多个历史购买商品Embedding向量进行等权的sum-pooling,这种方法肯定会带来信息的丢失,而且相对重要的物品Embedding向量无法完全突出自己所包含信息的重要性。
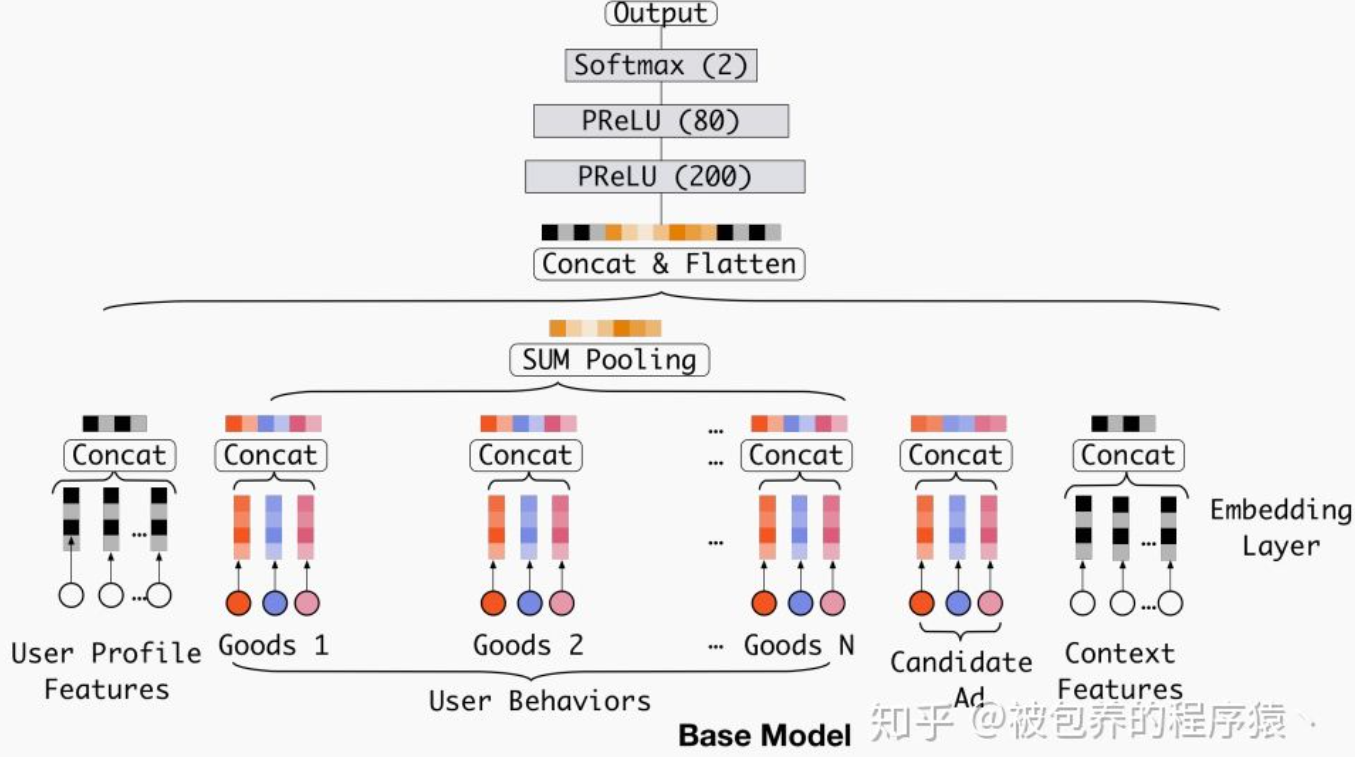
DIN模型在基准模型的基础上,增加了注意力机制Activation unit,将多个历史物品与候选商品进行关联,对每个历史物品分配权重(关联度),如果和历史商品都关联大,用户就很可能点击/购买(是否点击为标签)这个候选商品,反之:
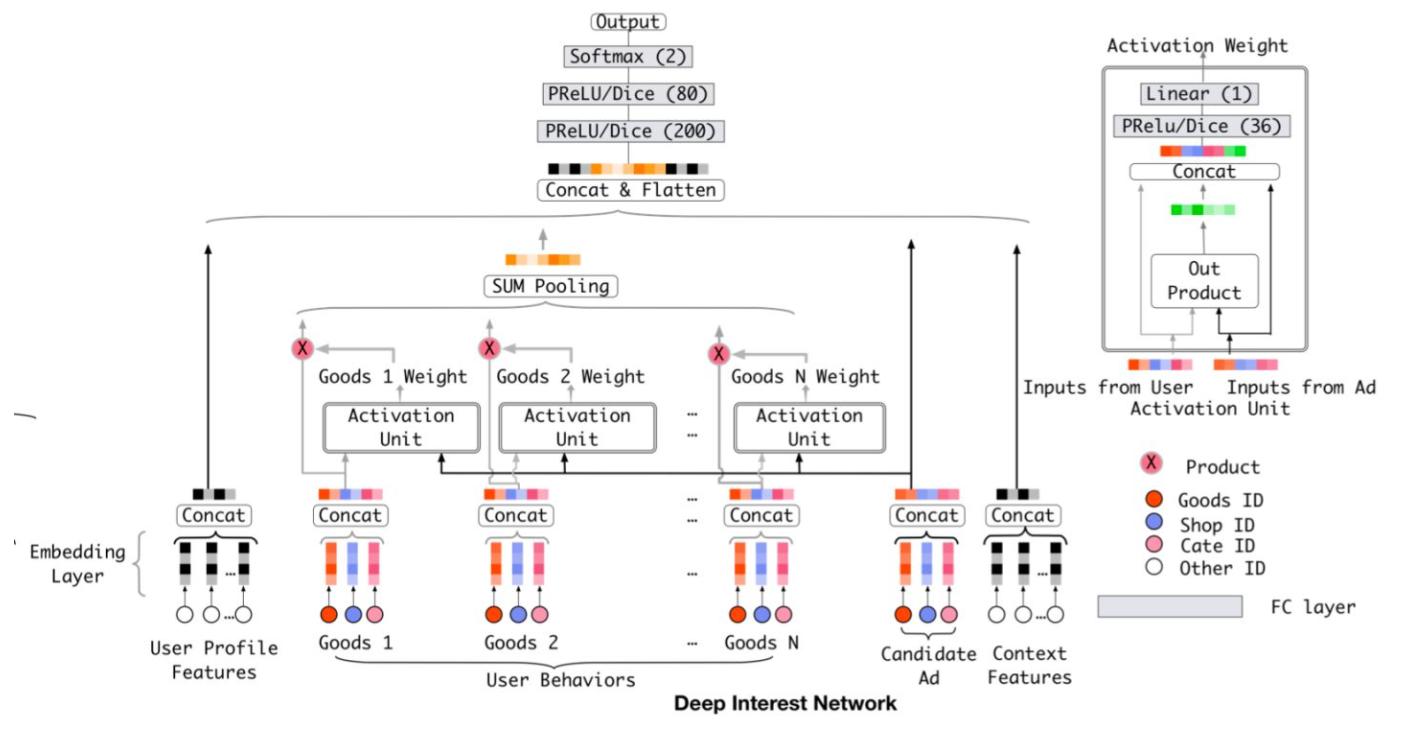
当来了一个样本后,分别提取它的各类特征,包括用户的画像特征,例如性别、年龄、学历等,用户的历史(商品)行为序列数据,例如点击商品的行为序列、购买商品的行为序列,候选商品的画像特征,例如品类、品牌等,下文特征,例如设备终端、时间、地点等,然后每个特征通过embedding层生成向量,以good1为例,good1的3个词向量进行拼接成一个向量代表good1,通过activation unit求出它和候选商品embedding向量的关联度(goods1的权重),这里activation unit的out product是element-wise积,加权到good1身上,其他历史goods同理,对于关联度小的goods,权重就小,这样就可以把它视为噪声并过滤掉,文章中放宽了对于权重加和等于一的限制,这样更有利于体现不同用户行为特征之间的差异化程度。如果改用softmax可能会由于goods太多,导致权重很小,不容易体现差异化。所有加权后的goods通过sum pooling得到一个求和向量代表历史所有goods,然后将用户画像向量,历史godds向量,候选商品向量,上下文向量拼接,通过多层神经网络输出。
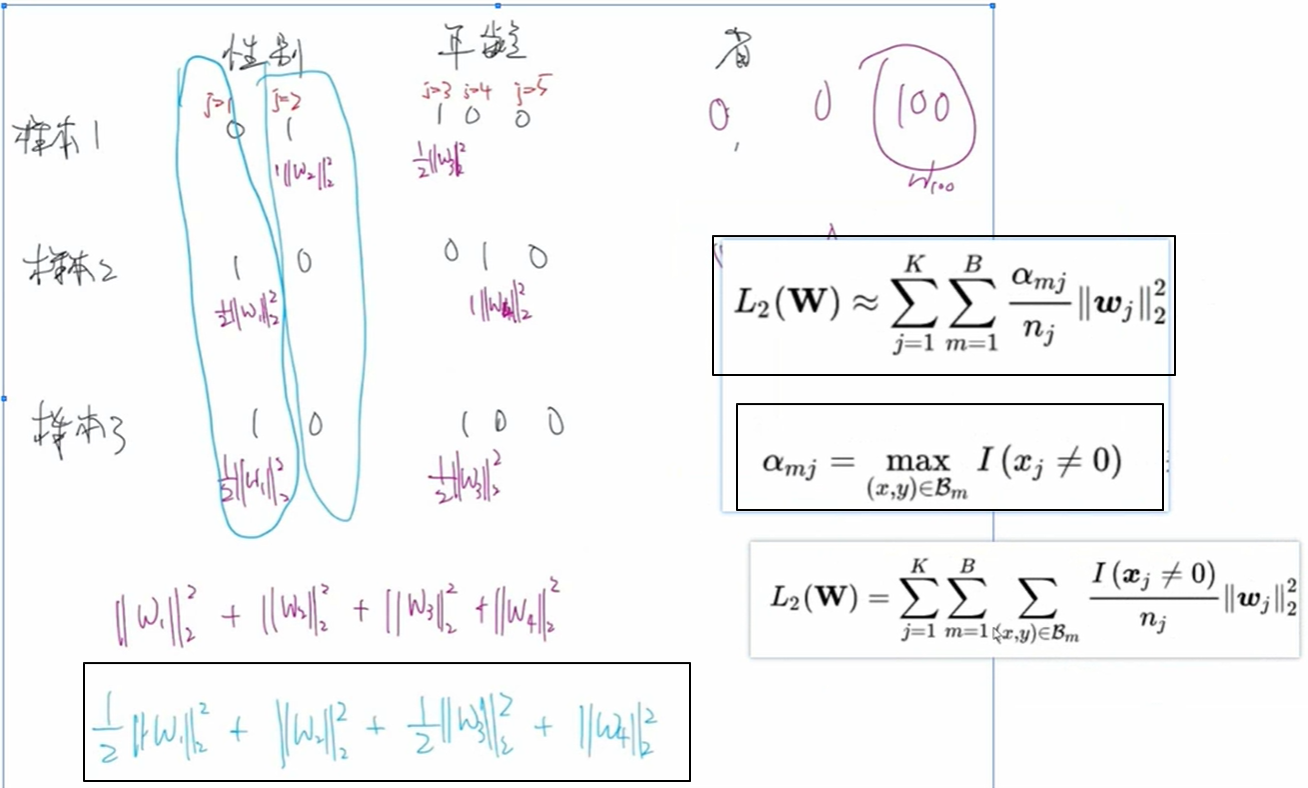
模型的正则化采用基于mini batch的自适应正则化:

步骤:先将样本的每一列原始特征值按照 one-hot 展开,形成新的特征,每个特征对应一个权重,然后把所有样本切分为一个个的 batch,将所有batch的结果相加,针对单个batch而言,若某列的特征值全=0,则不考虑该权重,若某列特征有 n 个1,则权重前面的系数就是 1/n,用公式和例子表示就是:
激活函数:
为了使得数据分布一致,论文通过改变激活函数来实现,而不是像bn一样改动数据本身,激活函数用Dice激活函数:
之前用的激活函数是PReLU,形式为:
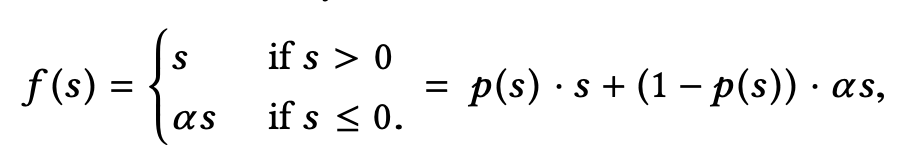
其中, 。作者认为这种突变型的激活函数不是很合适,因此将其修改为以下形式(称为Dice函数):
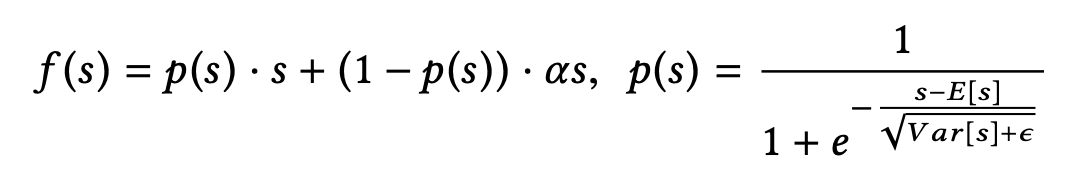
其中, 和
分别表示每个mini-batch中激活函数输入的均值和方差,这样Dice激活函数就会根据每层输入数据的分布来自适应调整校正点的位置。
评估指标GAUC:
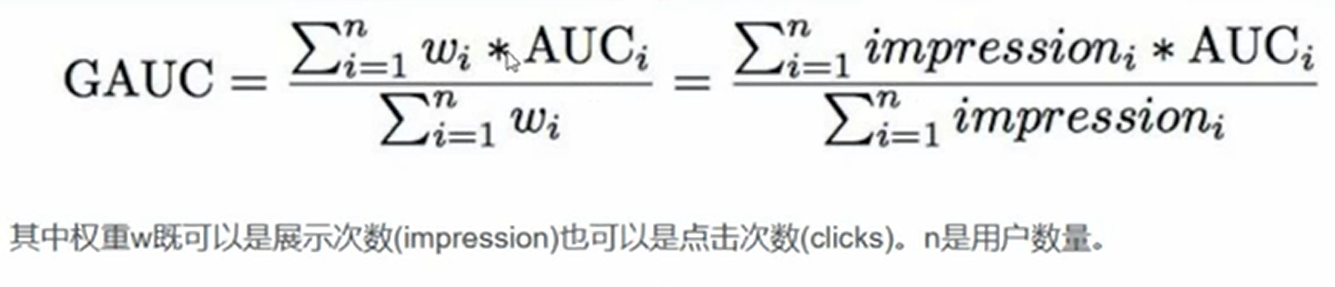
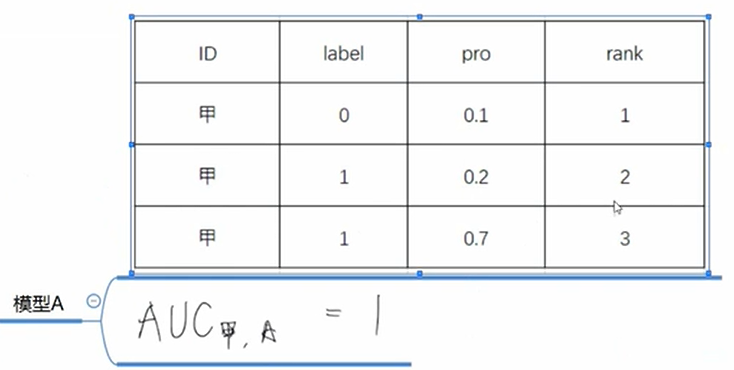
计算单个用户的AUC就是先把该用户的样本全部提取出来再算,比如计算模型A的甲用户的AUC:
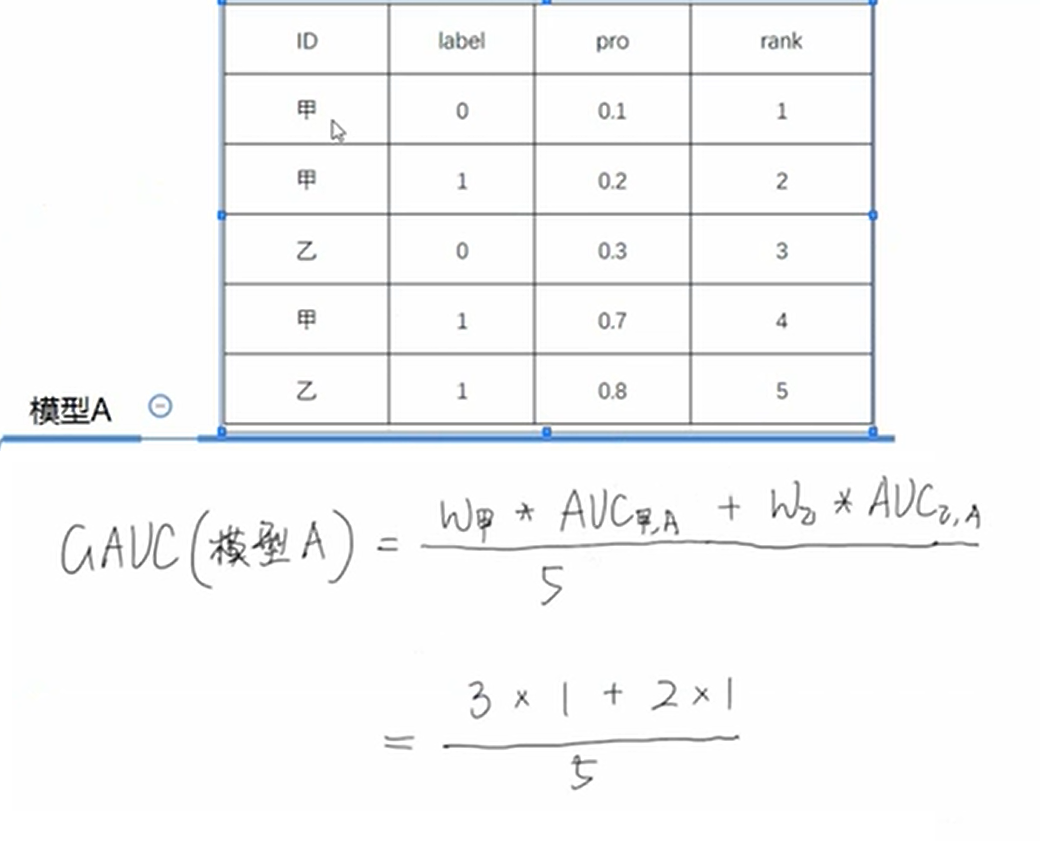
模型A的GAUC:
与base模型比的时候,用如下指标(AUC可以换成GAUC):

18、DIEN模型
提出动机:DIN会基于用户所有购买行为综合推荐,而不是下一次推荐
模型在DIN的user behavior层做了改进,将生成后的每个goods向量ei先后通过兴趣提取层和兴趣进化层
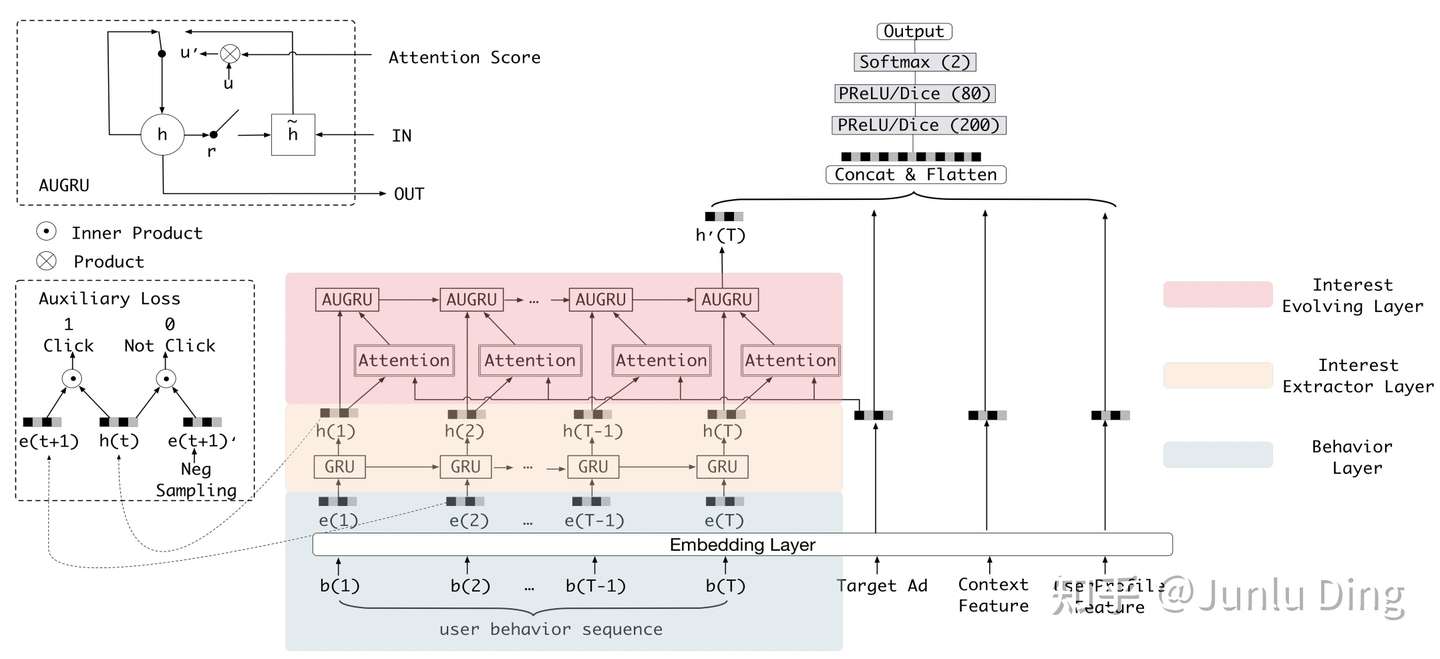
淡黄色的部分就是兴趣抽取层,选用了时序模型GRU对用户兴趣变化趋势进行建模,由于单个整体的损失函数只能做到对最后时间步的兴趣点的学习,无法对之前的不同时刻的兴趣点进行充分的学习,所以引入了辅助损失Auxiliary Loss,Auxiliary Loss会对每个时间步输出的隐藏状态进行监督学习,该损失函数是基于负采样的:
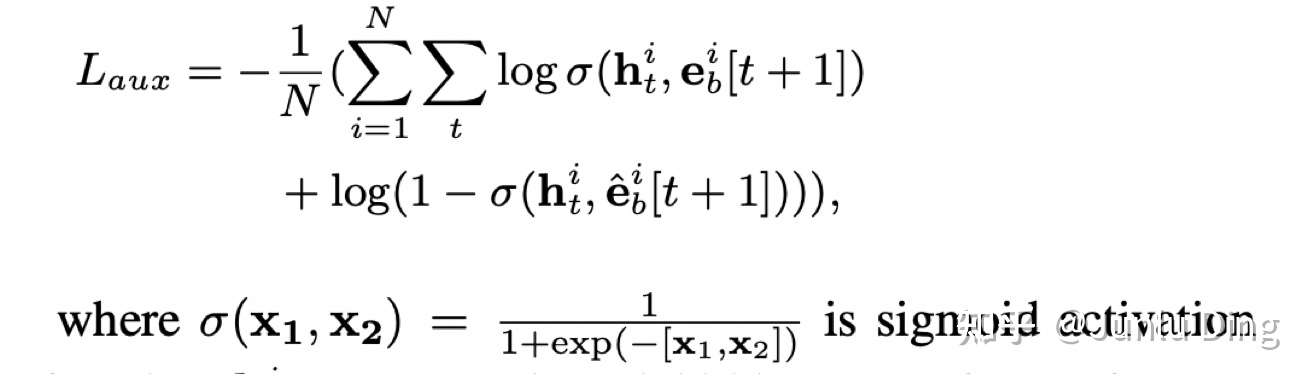
表示
时刻的隐藏状态,
表示正样本即用户点击或购买过的商品embedding,
表示负样本即用没有购买过的商品embedding

最后是兴趣进化层,现在每个hi代表各个历史商品,候选商品分别与商品向量做attention,通过Attention机制提高那些影响力大的历史行为的权重,降低那些影响力小的历史行为的权重,最终进化出一个历史行为向量代表“下一个推荐”,所以此处采用串行结构。此处权重(注意力得分)a和h的结合不再是直接相乘,而是通过AUGRU结构,将权重a直接乘到了GRU的更新门z上,这样不仅保留的各个维度的信息,而且当行为不重要(与候选商品关联度小)时,即权重=0,得到的结果还是上一个行为信息,能把当前不相关的行为去掉。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号