



ml2
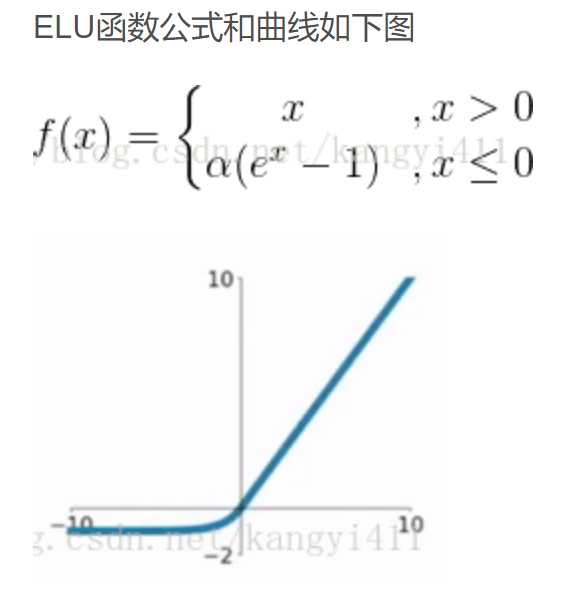
1、elu
ELU函数是针对ReLU函数的一个改进型,相比于ReLU函数,在输入为负数的情况下,是有一定的输出的
1、bert
NLP中有各种各样的任务,比如分类(Classification),问答(QA),实体命名识别(NER)等。对于这些不同的任务,最早的做法是根据每类任务定制不同的模型,输入预训练好的embedding,然后利用特定任务的数据集对模型进行训练,这里存在的问题就是,不是每个特定任务都有大量的标签数据可供训练,对于那些数据集非常小的任务,恐怕就难以得到一个理想的模型。NLP领域也引入了一个通用模型,在非常大的语料库上进行预训练,然后在特定任务上进行微调,BERT就是其一。BERT不是第一个,但是效果最好的方案之一。BERT用了一个已有的模型结构,提出了一整套的预训练方法和微调方法。BERT完全放弃了以往经常采用的RNN和CNN,提出了一种新的网络结构,采用Transformer中的encoder。Transformer改进了RNN最被人诟病的训练慢的缺点,利用self-attention机制实现快速并行。并且Transformer可以增加到非常深的深度,提升模型准确率。另外输入引入BPE算法优化
使用BERT模型解决NLP任务需要分为两个阶段:
- pre-train:用大量的无监督文本通过自监督训练的方式进行训练。预训练模型学习到的是文本的通用知识,不依托于某一项NLP任务;使用MLM任务和NSP任务来做训练
- fine-tune阶段:使用预训练的模型,在特定的任务中进行微调,得到用于解决该任务的定制模型,下游任务有很多种,取决于应用场景。Bert外面的结构,如Linear Classifier的参数是需要从头开始学习的(Trained from scratch),而BERT中的参数微调就可以了;
【pre-train】
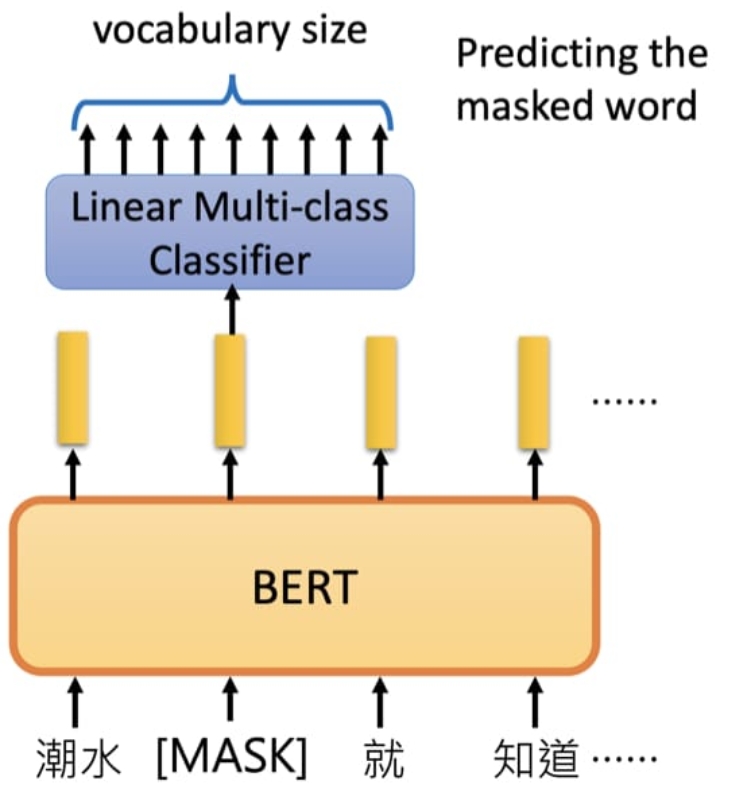
MLM(Masked Language Model)任务
在训练时随机mask部分token,然后只预测那些被屏蔽的token。 MLM 学习的是单词与单词之间的关系。
具体做法:
- 随机选择15%的token;
- 选中的token并不总是被[mask] 取代,其中的80%的单词被[mask]取代;
- 其余10%的单词被其他随机单词取代;
- 剩余的10%的单词保持不变;
结构:
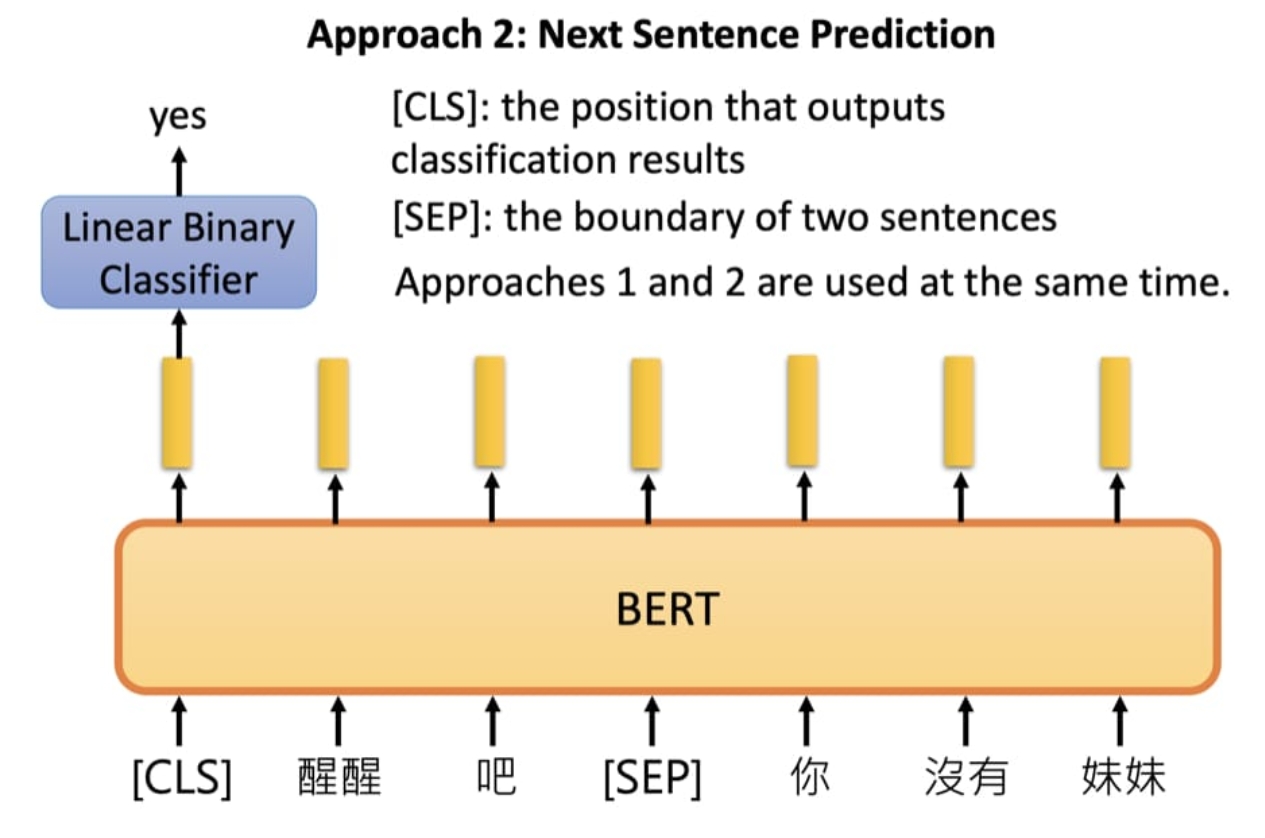
NSP任务
下句预测(Next Sentence Prediction),该任务是一个二分类任务,预测第二句sentence是不是第一句sentence的下一句。 NSP 学习的是句子与句子之间的关系。
具体做法:
- 训练数据中的50%,第二句是真实的下句;
- 另外50%,第二句是语料库中的随机句子;
- 前50%的标签是 isNext ,后50%的标签是 notNext ;
结构:
预训练阶段是将上述两个任务结合起来,然后将2者的Loss相加,如:
Input: [CLS] calculus is a branch of math [SEP] panda is native to [MASK] central china [SEP] Targets: false, south ---------------------------------- Input: [CLS] calculus is a [MASK] of math [SEP] it [MASK] developed by newton and leibniz [SEP] Targets: true, branch, was
【fine-tune】
单句分类任务,如情感分类:
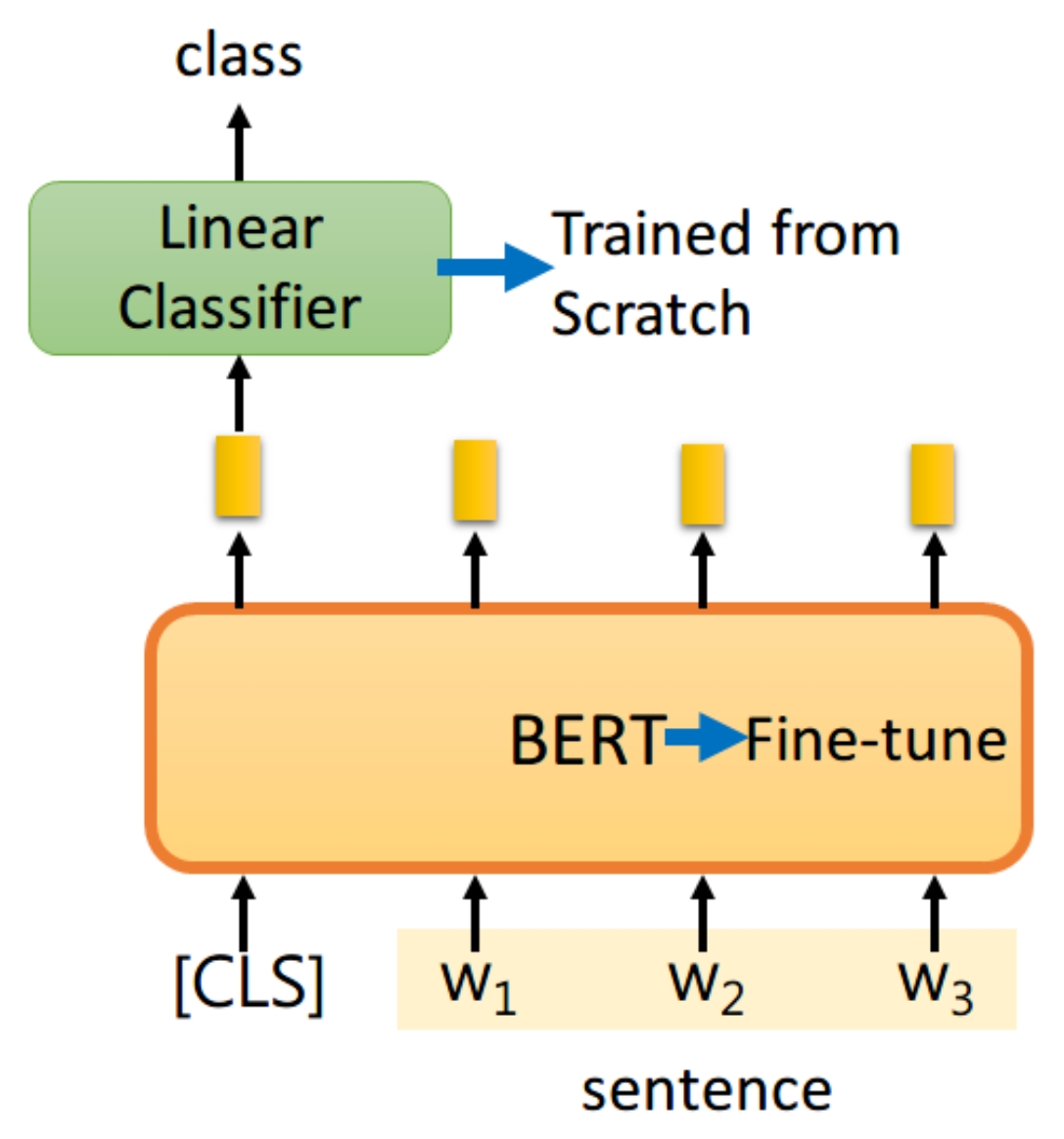
识别单句中的每个词的标签:
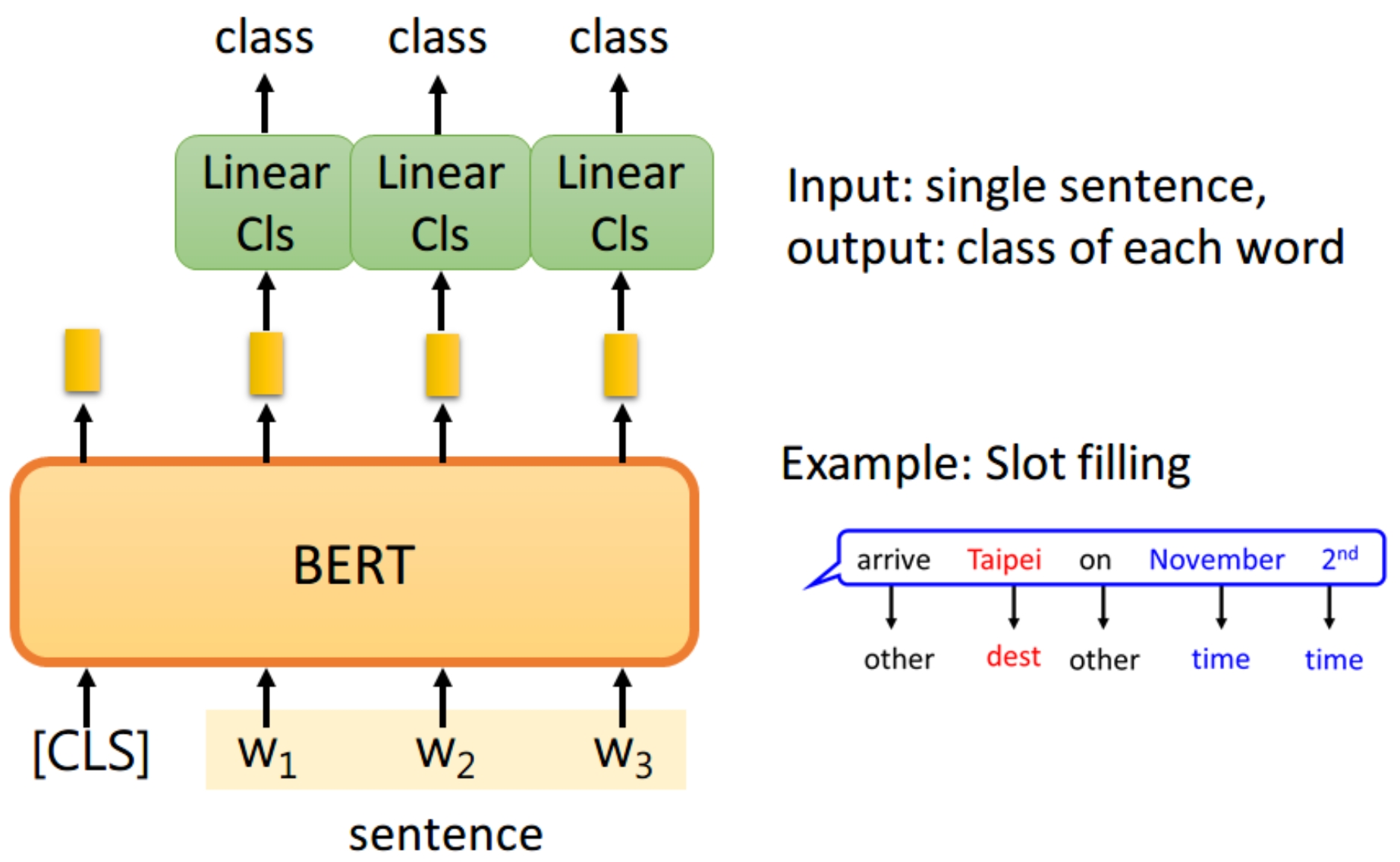
两个句子做分类,如MRPC、NLI(自然语言推理)。即给定一个前提,然后给出一个假设,模型要判断出这个假设是 正确、错误还是不知道。
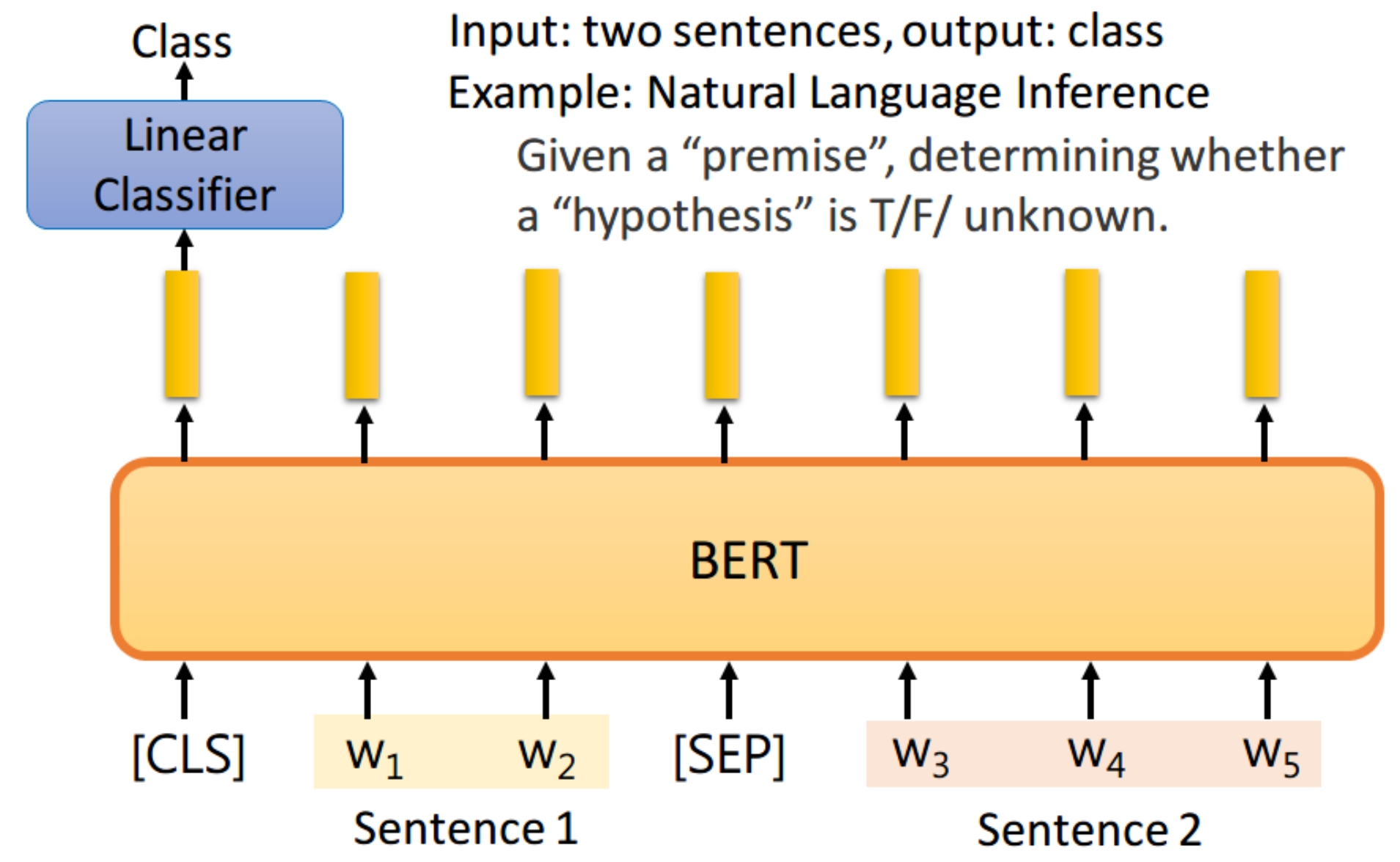
QA,将一篇文章,和一个问题(这里的例子比较简单,答案一定会出现在文章中)送入模型中,模型会输出两个数s,e,这两个数表示,这个问题的答案,落在文章的第s个词到第e个词。

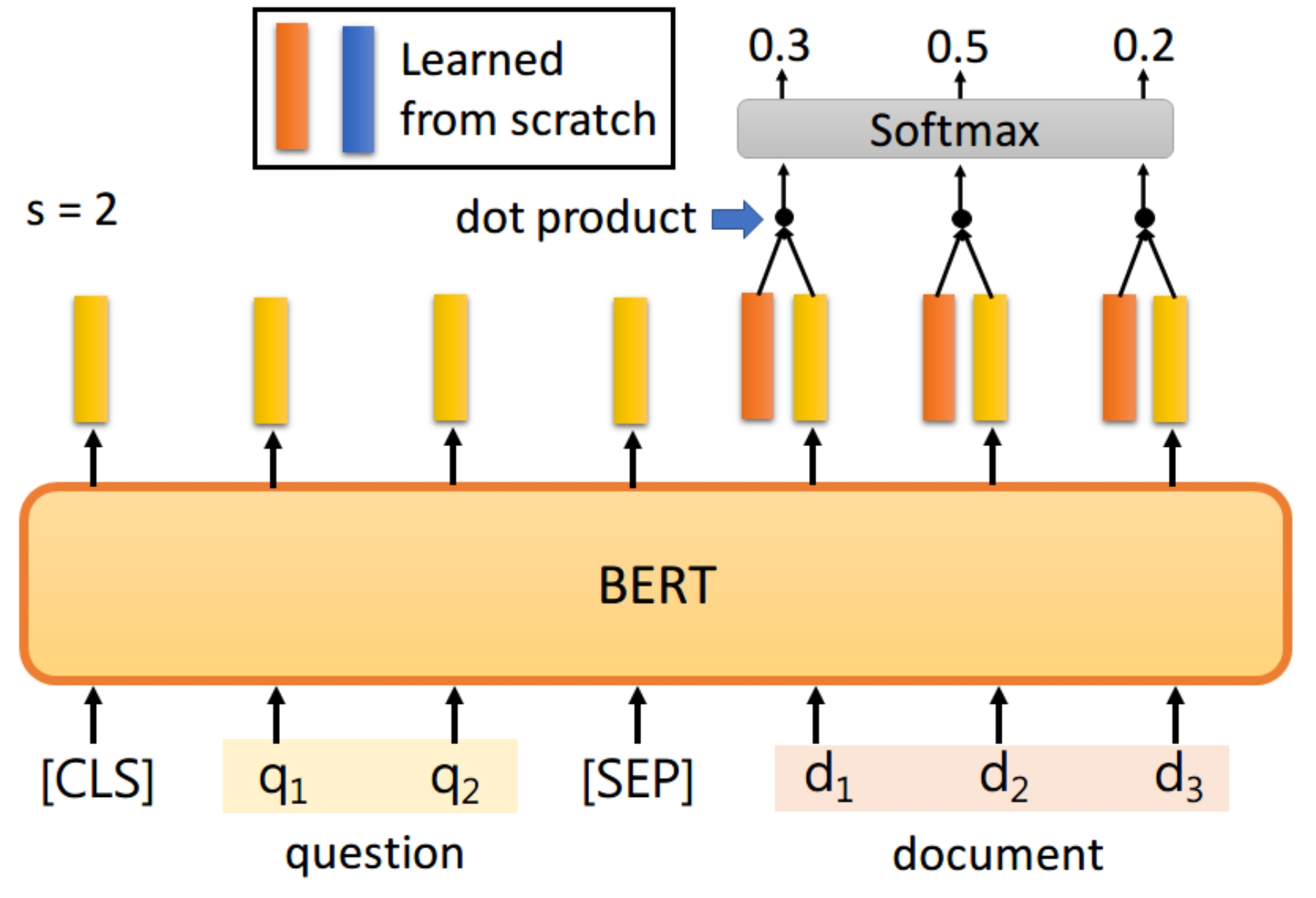
首先将问题和文章通过[SEP]分隔,送入BERT之后,只看document的每个输出。此时我们还要训练两个vector,即上图中橙色(代表答案的起始位置)和黄色(表答案的终止位置)的向量。首先将橙色和document的每个输出进行dot product,然后通过softmax,看哪一个输出的值最大,例如上图中d 2的概率最大,那我们就认为s=2;
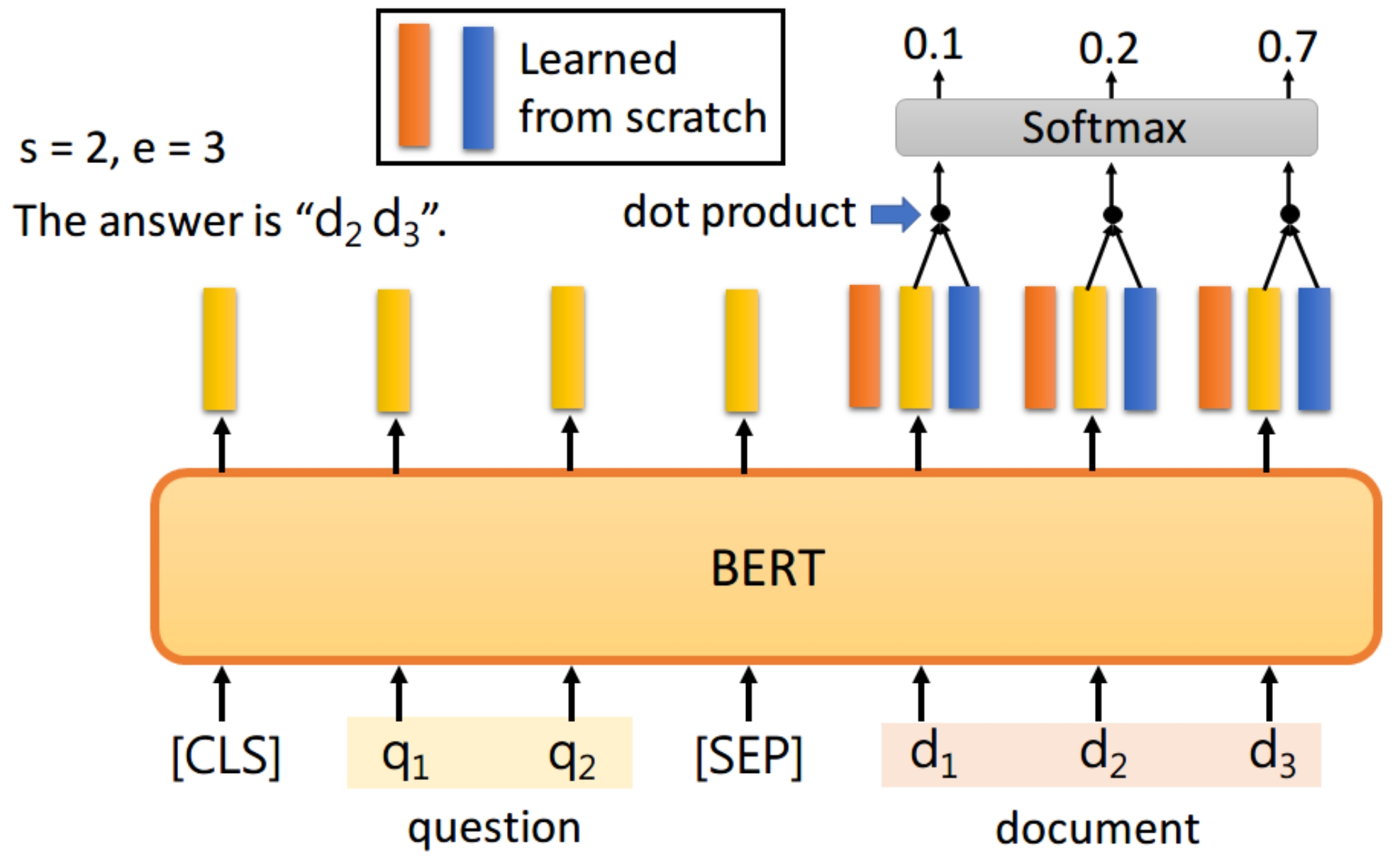
同样地,我们用蓝色的向量和所有document的输出进行dot product,最终预测得d3的概率最大,因此e=3。最终,答案就是s=2,e=3,假设最终的输出s>e怎么办,就认为该问题没有答案
- word2vec缺乏对于位置的建模
- word2vec的vocab一般巨大,动辄100w的词汇,BERT系列模型因为mlm任务的限制和bpe tokenizer的流行,单个语言一般也就3w-5w的vocab。
- BERT可以让句子的表示变得简单,只需要使用[CLS]和[seq]这样的特殊token就可以了,相比之下,传统的word2vec模型则没有特别好的直接获取句子级别的表示的方法,一般做法是平均所有的词向量,然而这和句子的表示并不等价。
bert与其他方案的对比:
BERT并不是第一个提出预训练加微调的方案,此前还有方案叫GPT、ELMo
【ELMO】
一个预训练加微调的方案,预训练阶段采用无监督方式训练,以便提供给下游任务词向量。由于Word2Vec模型如skipgram,训练出的词向量是固定的,所以没有办法解决一词多义的问题,ELMo是对word2vec的第一次改进,它是根据上下文信息输出词向量的,所以,相同的词汇在不同语境下有不同的Embedding。训练的时候,初始embedding采用在大规模语料库上训练好的Word Embedding,所以能够实现一词多义。elmo采用LSTM进行提取,但是Transformer特征提取能力强于LSTM。elmo采用双向语言模型,实际上是两个单向语言模型(方向相反)的拼接,这种融合特征的能力比Transform一体化融合特征方式弱。当数据量大时,效果不好。
预训练模型结构:
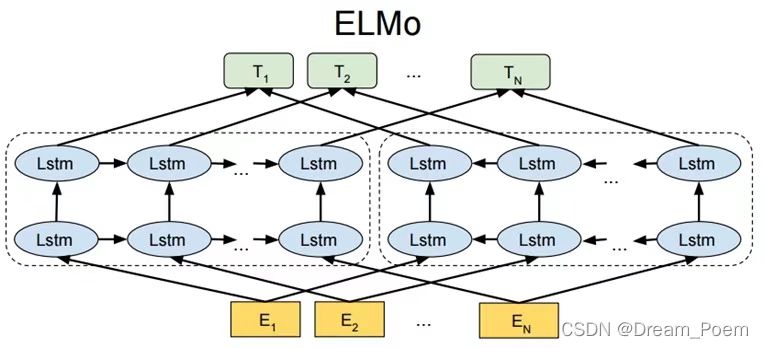
输入是一句话,如go to school,每个词的标签是后一个词,输出的标签是to school 结束符,所以是无监督训练。单词在输入之前也要通过embedding,左边和右边的LSTM都是L层的,每一层代表单词的不同维度的信息,所以一个单词能有2L+1个词向量,单个lstm的输出就看做一个词向量。给每层一个用于训练的权重参数,对2L+1个单词进行加权求和来作为单词的最终的词向量,然后给下游任务。
【GPT-1】
GPT和bert则采用Transformer进行提取,GPT是在一个8亿单词的语料库上做训练,给出前文,不断地预测下一个单词。因此只能用到上文的信息,无法利用到下文的信息。输入(以及后续的版本)采用BPE优化。BERT与GPT的具体差异表现在:
- 语言模型:Bert和GPT虽然都采用transformer,但是Bert使用的是transformer的encoder,是双向的语言模型;而GPT用的是transformer中的decoder,是单向语言模型。单向语言模型不能利用后面的信息。
- 输入向量:GPT是token embedding + position embedding;Bert是 token embedding + position embedding + segment embedding。
- 参数量:Bert是3亿参数量;而GPT3有1750 亿参数了。
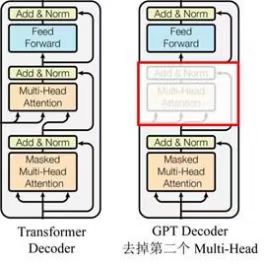
预训练阶段:
无监督训练,由当前词预测后面的词,模型由12层Transformer的decoder组成,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention,如下图所示。
【GPT-2】
以无监督、多任务为目标,放弃微调阶段,仅通过大规模多领域的数据预训练,让模型在Zero-shot Learning(
few-shot:在inference time(预测阶段),只给模型某个特定任务的说明和少量示例,不进行权重更新,完成任务;
one-shot:在inference time,只给模型某个特定任务的说明和一个示例,不进行权重更新;
zero-shot:在inference time,只给模型某个特定任务的说明,不给示例,不进行权重更新;
)
的设置下自己学会解决多任务的问题。该方法证明了自然语言处理领域通用模型的可能性。模型有微小改动:
(1)LN层移动到了子模块的输入端。
(2)在最后一层Tansfomer Block后增加了LN层。
(3)残差层权重做了修改,与残差层的数量有关。
(4)特征向量维数扩大,词表扩大,batchsize扩大。
(5)Transformer Block的层数从12扩大到48。
模型细节:
当输入1个长句子,模型在训练阶段的样子如下,输入层的 token 是 id (经过字典和分词器的处理),输入层往上是 1个GPT2Block,共10个GPT2Block串联,下图只列了1个GPT2Block:

10个GPT2Block后,通过 ln,再通过 ffnn 将词向量映射为字典长度的向量,字典每个值对应1个logit,再通过sotfmax,最大的概率的词就是 token1 对应的预测词 id,label 就是 token1后面的token2 的 id,由此算出token1的交叉熵损失,token2 处的label 是 token3 的id...,最后的tokenn 不用计算损失,因为它没标签了,然后所有词的平均损失就是该句子的损失。如果 token 是 0或者是pad前句子的末尾单词,则该 token 的 label 是结束符id -100。再统计准确率:一个pad之前的原始句子有百分之多少token预测对了
预测阶段:用户输入第1句话(如果是Prompt-Based Learning,则最前面再加入系统的个人画像的信息),结合字典并将其分词以及id映射,开头加入起始符id,结尾加上分隔符id,然后输入到模型中,只要最后分隔符的字典预测概率,除去unk,取出8个概率最大的单词,然后从这8个里面抽取1个单词,哪个词的概率大抽取的概率大,如果预测的词是SEP,则回复就到这儿了,否则,把该预测词作为回复的第1个词,方式1:该预测词加入到之前输入的句子的最后,作为新的输入,再次输入到模型,来预测第2个回复词,等回复词预测的是SEP的时候停止,此时该回复就作为机器人的回复,并加入到对话历史;方式2:第一部分是将该预测词加入到之前输入的句子的最后,并保存它们的k,v,第二部分是单独的该预测词作为模型的输入,只是每层都要用到第一部分的k,v,模型输出再映射到字典概率,从而输出第2个预测词,第2个预测词再加入到第一部分,同时再作为第二部分,直到预测的词是SEP,就得到1句完整的回复。
用户输入第2 句话,分词id映射后,拼接对话历史的最近3句话(如果是Prompt-Based Learning,则最前面再加入系统的个人画像的信息)作为模型输入:起始符id 用户第1句的id映射 sep 机器人的第1句回复 sep 用户第2句话 seq,模型输出新的第2句回复,并加入到对话历史
用户输入第3句话,拼接对话历史的最近3句话(如果是Prompt-Based Learning,则最前面再加入系统的个人画像的信息)作为模型输入:起始符id 用户第2句的id映射 sep 机器人的第2句回复 sep 用户第3句话 seq...
【GPT-3】
训练过程与 GPT-2 类似,但对模型大小、数据集大小与多样性、训练长度都进行了相对直接的扩充。使用了和 GPT-2 相同的模型和架构。但是参数量过于巨大,如果你想自己训练一个GPT-3模型,需要花费1200万美元,不具备真正的推理,存在不安全的内容出现。
【Roberta】
模型和bert一致,只是训练方式有变化:1、dynamic masking:同一个句子复制10份,每个句子采用MLM机制,此时就相当于同一个句子有10种不同的mask机制;2、去掉了NSP任务;3、采用更大的batchsize、训练步长、更多的数据
【Albert】
Albert是谷歌在Bert基础上设计的一个精简模型,主要为了解决Bert参数过大、训练过慢的问题。ALBERT架构的主干与BERT相似,因为它也使用非线性的transformer encoder。
Albert的改造:
1️⃣BERT的loss由两部分组成(MLM+NSP)。MLM在各种研究中得到了越来越多的认可,但是NSP自问世以来一直受到各种诟病和质疑。NSP(Next Sentence Prediction)给定一个句子对,判断在原文中第二个句子是否紧接第一个句子。正例来自于原文中相邻的句子;负例来自于不同文章的句子。ALBERT的作者认为,NSP作为一项任务,和MLM相比,没有什么难度。它把主题预测和一致性预测混淆在了一起,而主题预测比一致性预测要容易。具体而言,由于正例来自于同样一篇文章,而负例来自于不同的文章,很可能判别正负例仅仅需要判别两个句子的主题是否一致,而这些信息已经在MLM中学习过了。
Albert提出一种的句间连贯性预测任务,称之为sentence-order prediction(SOP),正负样本表示如下:
正样本:与bert一样,两个连贯的语句
负样本:在原文中也是两个连贯的语句,但是顺序交换一下。
SOP因为正负样本都是在同一个文档中选的,只关注句子的顺序而不考虑主题方面的影响,所以这将迫使模型在话语层面学习更细粒度的区分。并且通过实验发现,SOP能解决NSP的问题,但是只学习NSP的模型却不能解决SOP的任务
2️⃣去掉dropout后能够提升MLM的精度,同时在其它任务上也基本都有所提升
3️⃣Albert采用矩阵分解的做法:把原来的嵌入层矩阵(大小为V× H)分解成2个矩阵,大小分别为V*E,E*H,这样一个one-hot向量先投影到一个低维的空间(维度为E),然后再从这个空间投影到隐藏层的空间(维度H)。经过矩阵分解,当H远大于E时,参数量大大减少了。
4️⃣传统 Transformer 的每一层参数都是独立的,包括各层的 self-attention、全连接。这样就导致层数增加时,参数量也会明显上升。之前有工作试过单独将 self-attention 或者全连接层进行共享,都取得了一些效果。ALBERT 作者尝试将所有层的参数进行共享,相当于只学习第一层的参数,并在剩下的所有层中重用该层的参数,而不是每个层都学习不同的参数
【ERNIE1.0 from Baidu】
百度提出的ERNIE模型主要是针对BERT在中文NLP任务中表现不够好提出的改进。ERNIE 同样采用多层的双向Transoformer 来作为特征提取的基本单元。ERNIE模型在BERT的基础上,加入了海量语料中的实体、短语等先验语义知识,建模真实世界的语义关系。主要提出两点:
1️⃣采用三种masking策略,经过这三种策略的mask训练后,短语信息就会融入到word embedding中了:
Basic-Level Masking: 跟bert一样对单字进行mask,很难学习到高层次的语义信息;
Phrase-Level Masking: 首先使用语法分析工具得到一个句子中的短语,然后随机掩码掉一部分,预测被mask掉的这些短语。
Entity-Level Masking: 首先进行实体识别,然后将识别出的实体进行mask。
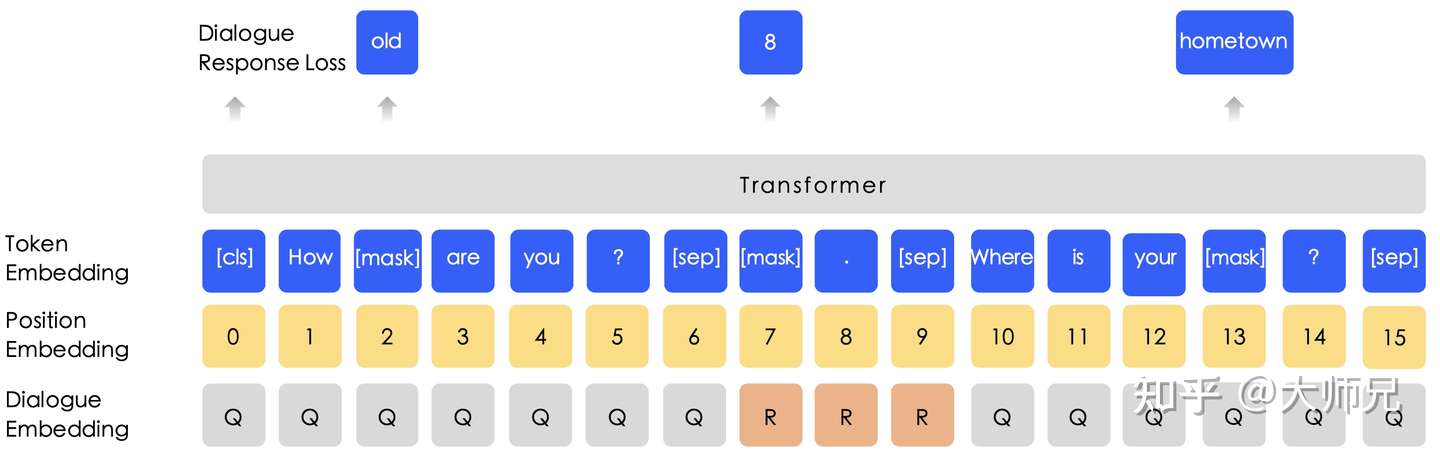
2️⃣引入对话语言模型(DLM)无监督任务
得益于百度贴吧强大的数据量,ERNIE-B使用了海量的对话内容,对对话中的词语随机mask,并做预测。而且作者认为一组对话可能有多种形式,例如QRQ,QRR,QQR等(Q:Query,R:Response),为了处理这种多样性,ERNIE-B给输入嵌入中加入了对话嵌入(Dialogue Embedding)特征。
【ERNIE2.0 from Baidu】
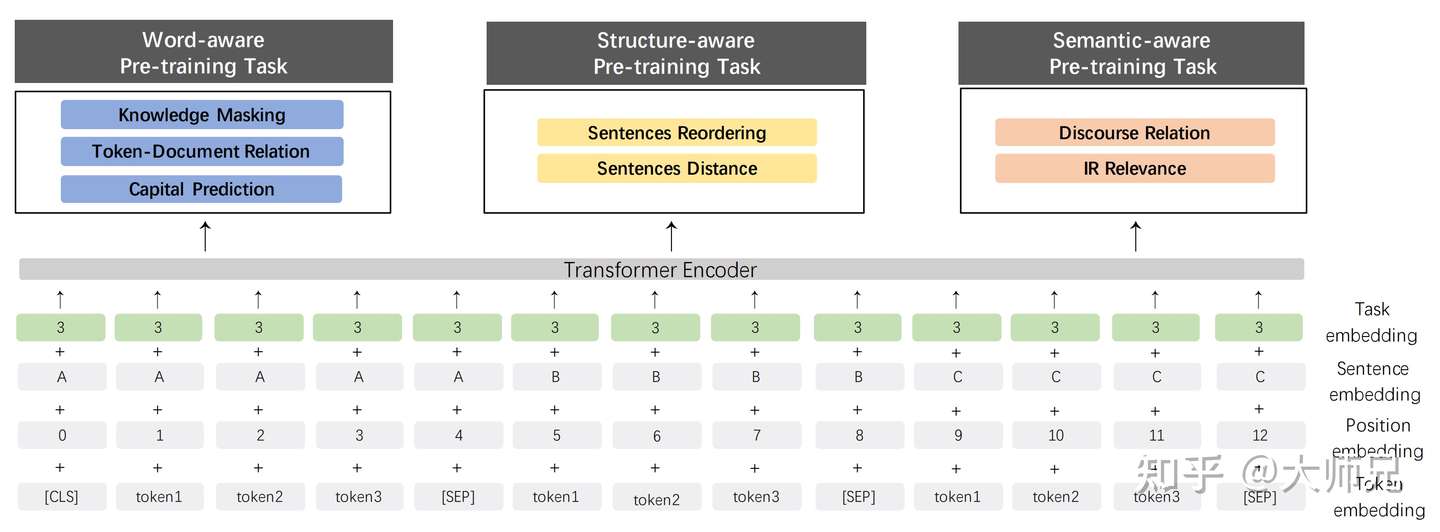
1️⃣ 提出了更多的学习任务,并由简到难将它们划分为三个感知级别的预训练任务,共3类7个任务,这样能使得模型能够学习到更丰富的知识:
单词感知预训练任务(Word-aware Pre-training Tasks):学习单词级别的知识,包括1.0提出的掩码任务、大写预测任务(因为大写的单词往往表示这个词在句子中拥有特殊的含义,例如是一个实体类别等,该任务就是预测这个单词是否需要大写,以察觉它的特殊性)、Token-文档关系预测任务(预测在一篇文章中一个片段出现的token是否也在这篇文章的其他片段中出现了,从而就知道了这个词是不是文章的关键词);
结构感知预训练任务(Structure-aware Pre-training Tasks):学习句子级别的知识,包括句子重排序任务(将一个段落的所有句子打乱,再预测原来的正确顺序),句子距离预测任务(预测两个句子的距离,可能两个句子在一篇文章中的距离很近,或者两个句子在一篇文章中但是距离比较远,或者两个句子不在一篇文章中。);
语义感知预训练任务(Semantic-aware Pre-training Tasks):学习语义级别的知识,包括篇章句子关系任务(这是一个无监督任务,它根据文章中的一些关键词来提取两个句子之间的语义或者修辞关系。例如“but”切开的两个句子可以表示转折关系。),查询关系任务(这个任务的数据集是根据百度搜索引擎得到的,它用来判断一条查询和一篇文章的题目的相关性程度。它共有3类:强相关,即当用户输入查询后会点开这篇文章的题目、弱相关,即会查询到这篇文章,但是用户不会点开、不相关,即使用的是一条随机采样的样本。)。
所以在输入阶段还添加了一个任务嵌入(Task Embedding),用于识别输进来的任务,从而通过共享网络再进入对应的独立网络进行训练,3个独立网络分别用于处理对应感知级别的任务,且共享encoder网络结构。
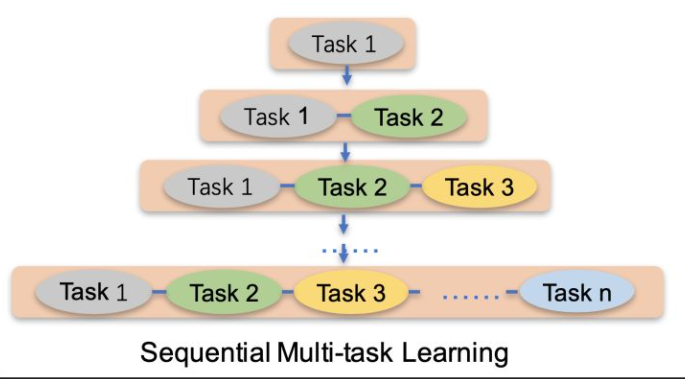
由于串行训练任务可能会导致灾难性遗忘,即训练新任务后导致老任务的效果不好,其次是训练的速度慢,因此提出持续多任务学习,每次训练新任务的时候带上老任务一起训练,而且指定迭代步数,兼得泛化能力和效率。
【ERNIE3.0 from Baidu】
引入了知识图谱改进了MLM任务,能够对实体和实体之间的关系mask,如根据知识图谱知道:安徒生--作品-->《夜莺》,然后在mlm中,把“作品”关系做mask来预测关系
【ERNIE from THU】
ERNIE-T的核心在于引入了知识图谱中的命名实体,并根据命名实体进行了下面三点优化:
1️⃣设计了可以融合BERT和知识图谱两个异构信息的网络架构;
整个模型主要由两个子模块组成:
底层的textual encoder (T-Encoder),用于提取输入的基础词法和句法信息,有N个,T-Encoder 依然是对原来的文本进行编码,这部分和 BERT 是一样的;
高层的knowledgeable encoder (K-Encoder), 用于将外部的知识图谱的信息融入到模型中,有M个,在 K-Encoder 中,可以看到输入输出都变成了两个,多了 entity 的信息。
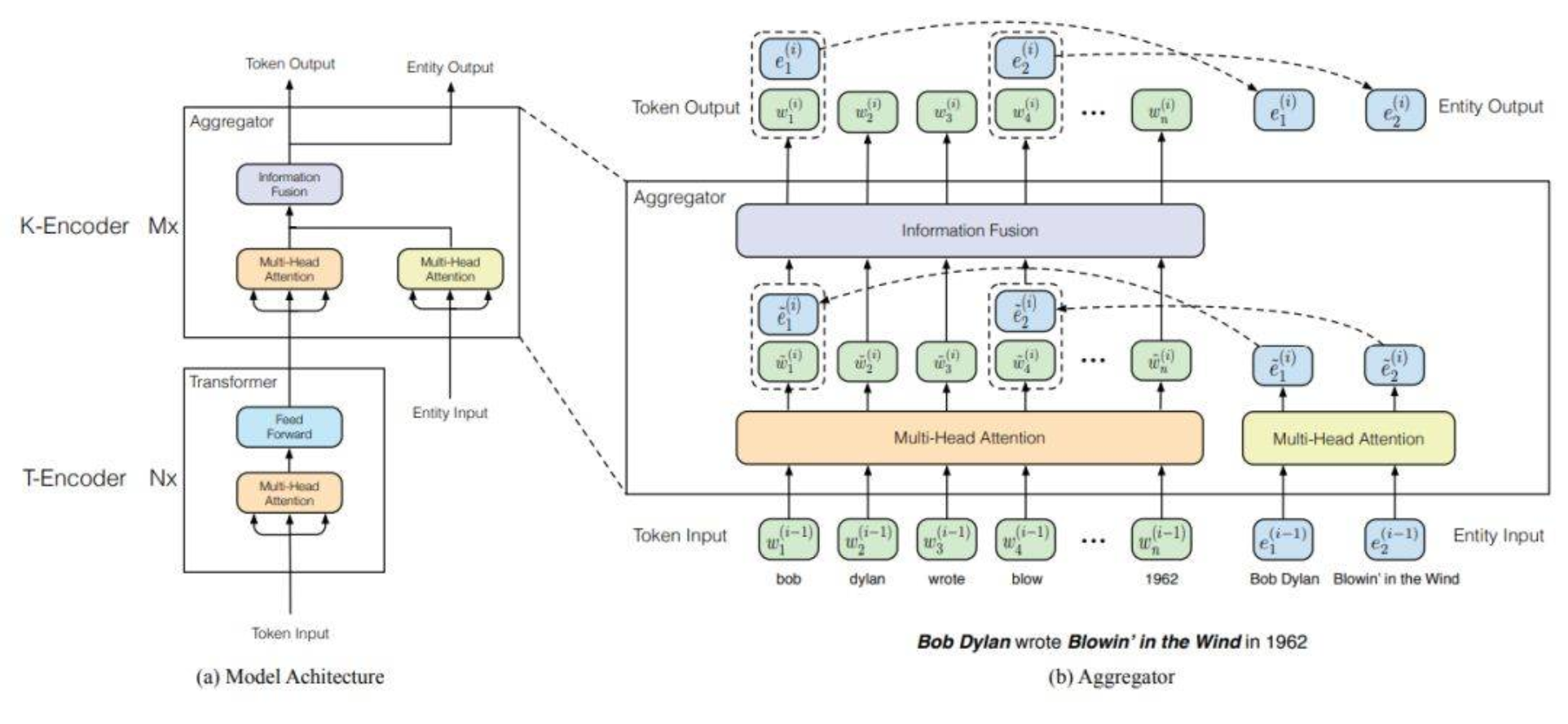
输入的实体序列 是从前面的 token 序列
当中提取出来的,每个实体需要经过TransE将其转换为实体嵌入向量,在transe中,首先需要初始化实体和关系所对应的向量,假定在知识图谱中,三元组
表示实体head和实体tail之间的关系是 l ,基于负采样和距离公式定义 transe 的损失函数,其中正样本就是已有的三元组,负样本是把头部或者尾部替换成其它的实体:
其中 表示
的正数部分,并且
然后采用sgd可以求出实体向量来。
然后将token向量和实体向量分别通过参数不共享的multi-head attention得到2组特征向量,然后将2组特征向量做针对性信息融合,得到关于token的输出和实体的输出,接着再传入到下一个K-encoder当中
2️⃣dEA:随机mask掉一些实体,让模型预测,最终的损失函数包括mlm,nsp,和实体损失
总结:多方向跨界融合一直是AI界非常重要的领域,本文提出的ERNIE-T便是一个将NLP和知识图谱进行融合的经典范例。通过提取知识图谱中的实体以及实体之间的关系信息,给予了模型更强的表达语义信息的能力。但是它依赖于NER提取的准确度,模型复杂度过高
详细:https://zhuanlan.zhihu.com/p/359379784
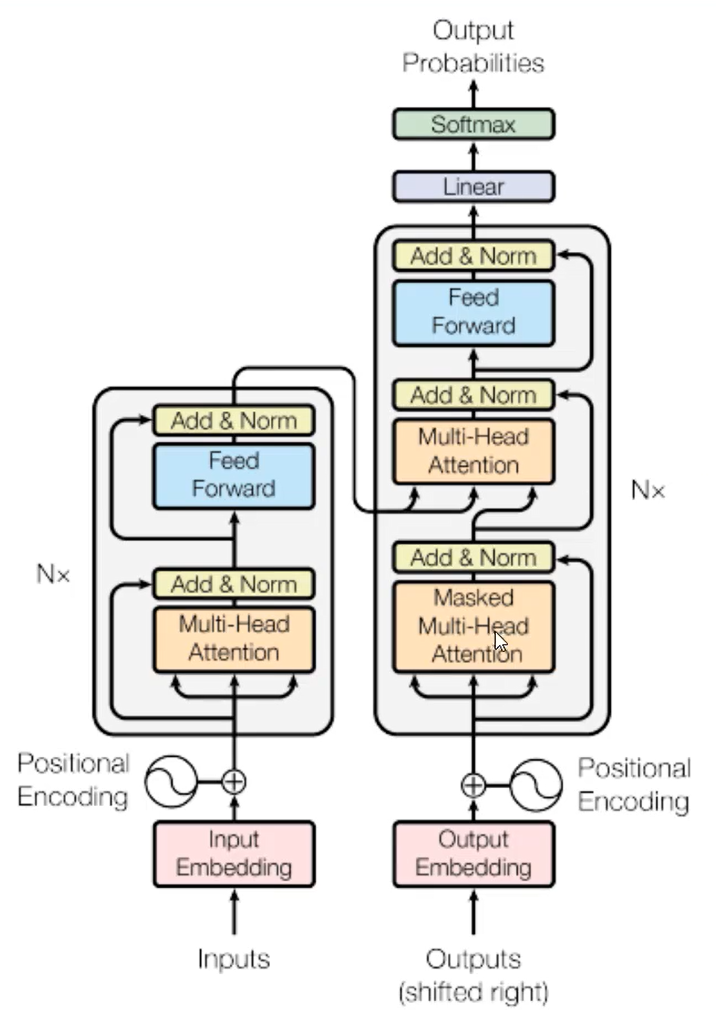
2、Transformer结构(论文)
Transformer本身是一个典型的encoder-decoder模型,Encoder端一般有6个encoder,Decoder端也是6个decoder
3、encoder内部机制:(从输入开始)
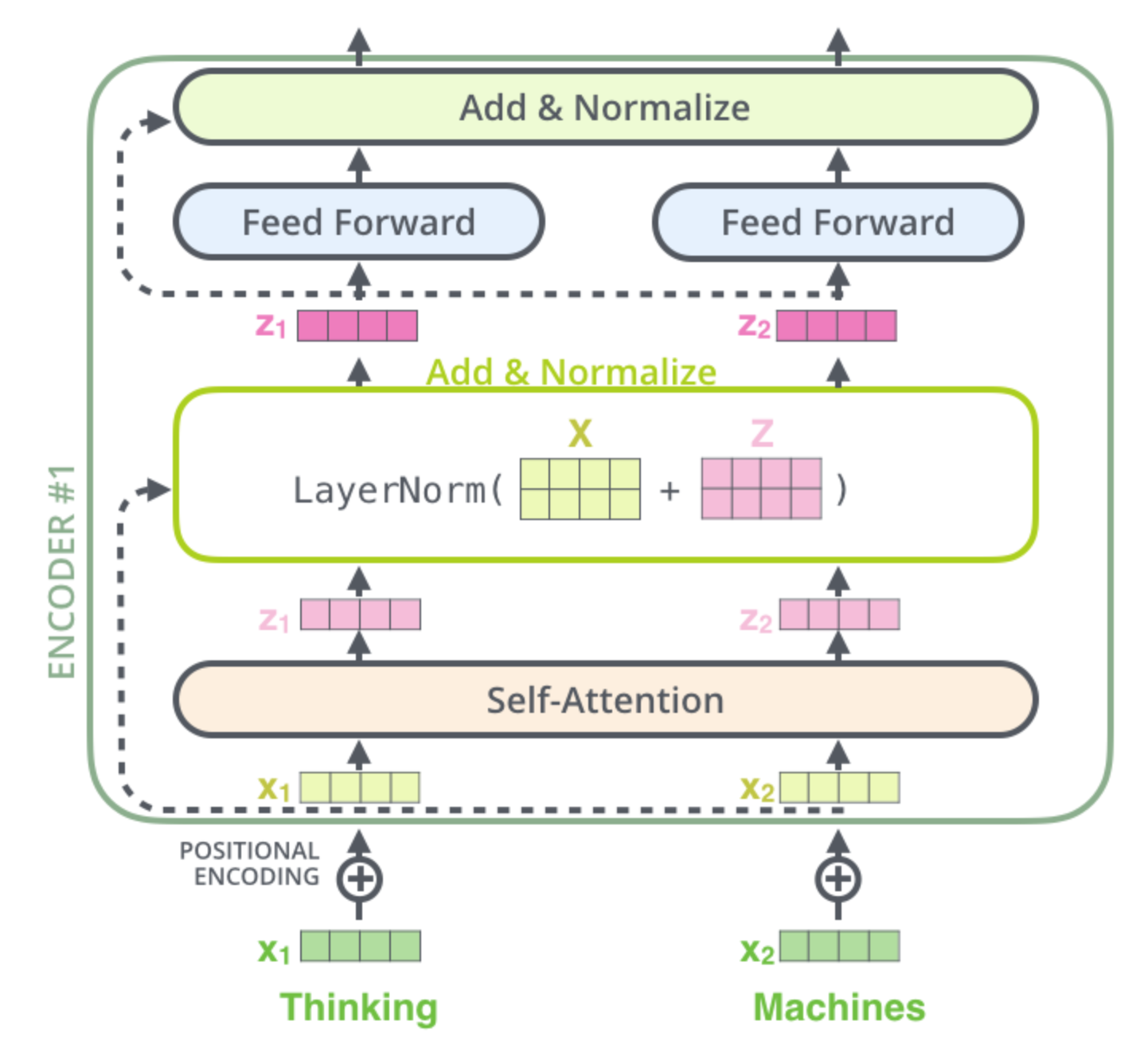
输入的每个单词分别转成词向量
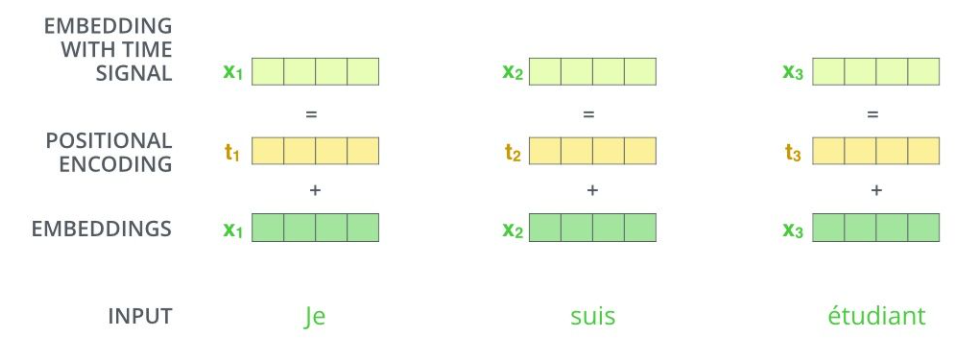
【位置编码POSITIONAL ENCODING】
在论文当中,根据单词位置,得到对应的位置向量pe,然后相加
PE矩阵计算公式:
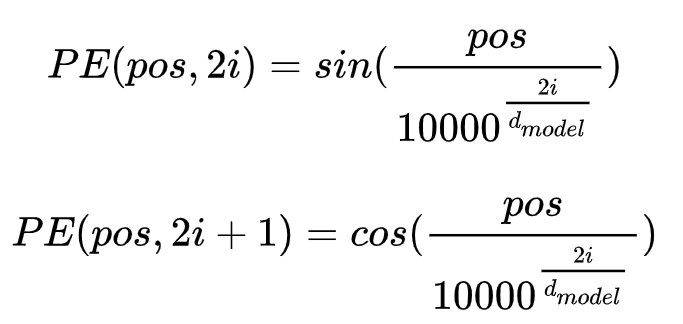
pos是单词在句子的位置,i 是词向量里面元素的索引,dmodel是词向量维度
比如the在句子的第1个位置,词向量是(0.1,0.2,0.3),则the的pos是1,计算
i=0:
pe(1,0) = sin( 1/10000^(0/3) )
pe(1,1) = cos( 1/10000^(0/3) )
i=1:
pe(1, 2) = sin( 1/10000^(2/3) )
pe=
( pe(1,0) , pe(1,1) , pe(1,2) )
( sin(1/10000^(0/3)) ,cos(1/10000^(0/3)) , sin(1/10000^(2/3)) )
如果是用索引来位置编码,则由于计数的值过大,以至于盖住词向量,而且最后的位置比第一个位置的编码大太多,和词向量合并以后难免会出现特征在数值上的倾斜
如果是用归一化的索引来编码,则对于短文本而言,相邻的词序关系显著,而对于超长文本,分母过大使得相邻的词语关系几乎看不出来
实际在 bert 中,没有采用论文里面的公式,使用的是token embedding(通过embedding后的词向量) + segment embedding(用于区分该词属于哪个句子,若该词属于第一个句子,则为0,若属于第二个句子则为1) + position embedding(保存词语的位置信息,先随机初始化,然后通过网络训练得到) 作为作为编码后的向量
然后进入到第一个encoder的self-attention
【self-attention】
先考虑单个head的单个词x1 - > z1的过程:
每个词都有自己的q,k,v,用q1和这一排所有单词的k做点乘(相似度计算),再分别除以根号下dk(标准化),dk是k向量的维度,默认64
padding mask : (14,12, ... 无意义词,无意义词) 加上padding mask向量 [ 0 0 0 0 .... 负无穷 负无穷 ] = (14,12,....负无穷 负无穷)
这样对于需要屏蔽的词,通过padding mask映射为负无穷
然后经过softmax层,作为各个单词的权重,此时屏蔽词的权重为0,最后和每个单词的v向量做加权求和

考虑这一排所有单词,用矩阵的等价写法:
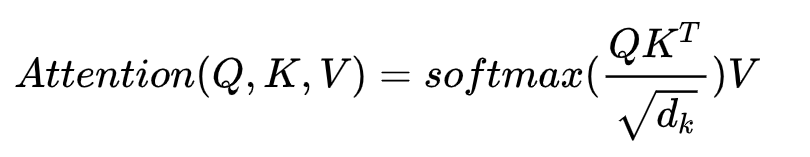
等价于:
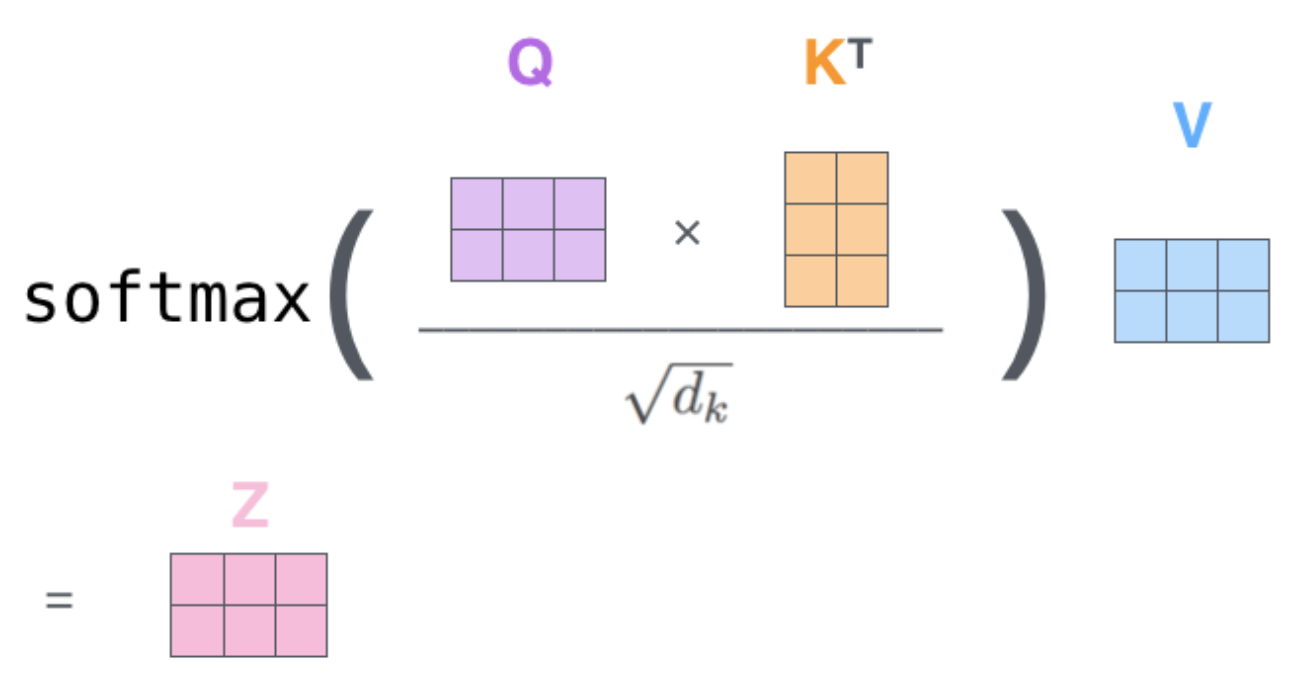
Z的每行对应输入的一个单词,从上往下
这里的Q、K、V是这么来的:X乘以用于训练的矩阵,Q、K、V的 第 i 行对应第 i 个单词
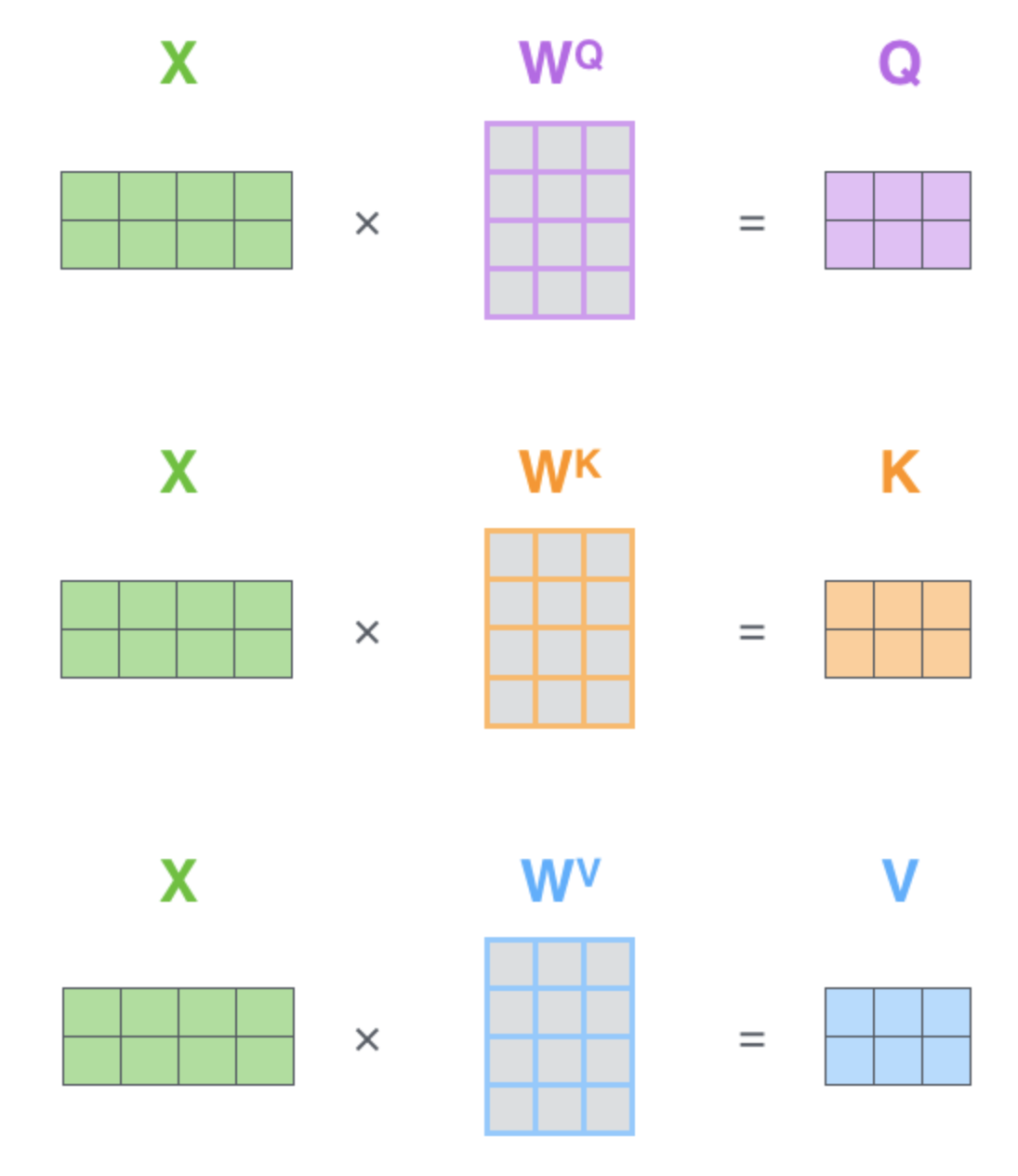
现在是多个head:
词向量做切割,一个head负责提取一部分信息,而且能并行计算,一般是12个head,每个head有自己的QKV矩阵,X每行是一个单词的词向量(含有位置编码),一个单词在每个head里面各有1组q,k,v,head1只和head1的做计算,方法就和1个头一样,head2只和head2的做计算...该单词算出12个head的12个z之后,拼起来就代表该单词了,然后通过一层神经网络做个降维:
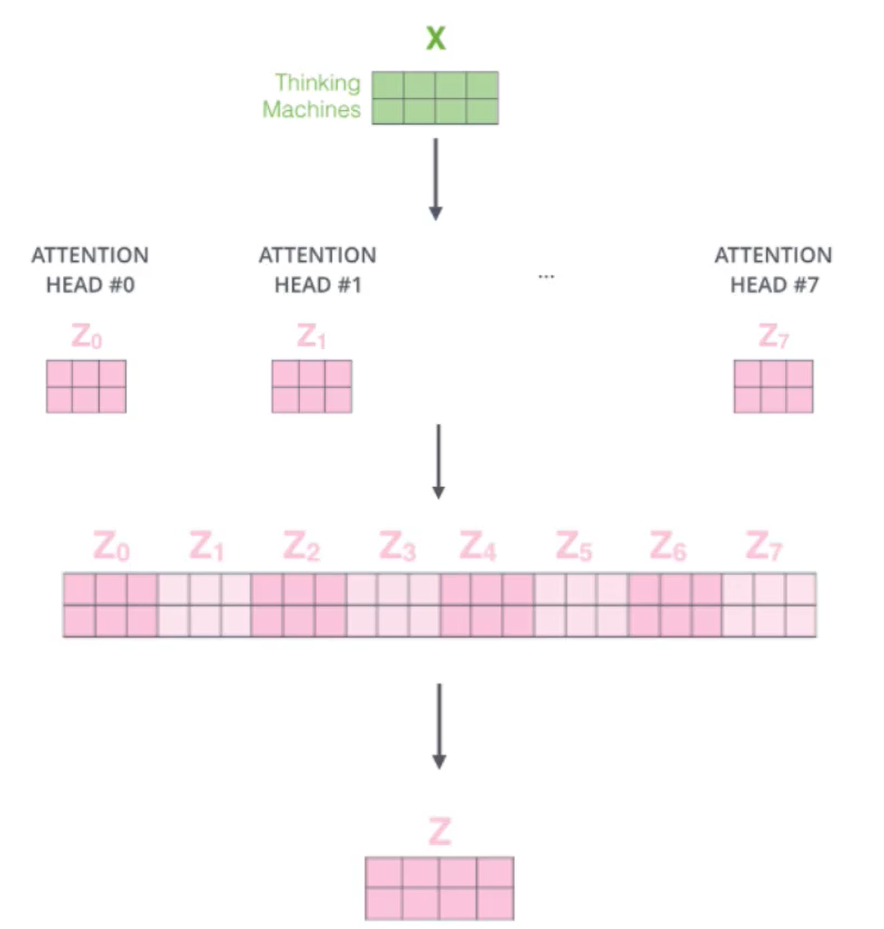
总结:
该层综合所有词的相关性并为每个词分配与当前词有关的注意力(权重),加权求和得到当前词语的综合结果向量,举例,比如得到了the的结果向量,这个向量更不仅关注the,还关注其他单词,但是更能体现the,采用了多头机制是为了从多个角度提取更多信息同时实现并行运算,提升速度
self-attention的优点
需要学习的参数只有3个矩阵Wq,Wk,Wv,所以它的参数量少但每个参数所涵盖的信息多,这是它的第一个优点。
每个单词的计算都是独立的,所以可以并行处理每个单词,这一点相比之前的RNN来说很不一样,RNN是需要串行计算,所以速度快,这是它的的第二个优点。
对于RNN,前面的变量在经过多次RNN计算后,已经失去了原有的特征。越到后面,最前面的变量占比就越小。self-attention在每次计算中都能保证每个输入的词变量(带位置信息的)是平等的,这样才能保证经过self-attention layer计算后他的注意力权重系数是可信的。
【add & normalalize】
输入向量x1+结果向量z1,然后通过layer norm,即内部归一化,维度没有发送变化,用矩阵考虑所有单词:layer norm(X+Z),即对X+Z的每一行的向量,分别减去自己的均值再除以标准差,一个单词就是一个样本
总结:
采用残差网络思想,通过将前一层的信息无差的传递到下一层,过滤掉学得不好的信息
用ln的原因:
BatchNorm是对一个batch-size样本内的每个特征做归一化,LayerNorm是对每个样本的所有特征做归一化。假设有一个二维矩阵。行为batch-size,列为样本特征。那么BN就是竖着归一化,LN就是横着归一化。区别在于:BN抹杀了不同特征之间的原来的大小关系,但是保留了不同样本间的大小关系,所以适合cv。LN抹杀了不同样本(单词)间的大小关系,但是保留了一个样本(单词)内不同特征之间的大小关系。
【 feed forward neural network】
有两层,第一层的激活函数是ReLU,第二层没有激活函数,公式为:
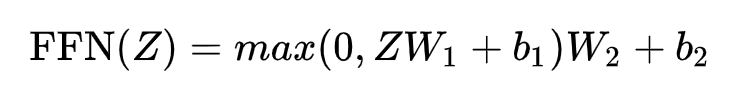
总结:
由于经过Multi-head attention 层都是没有经过非线性变换,此处是为了增加模型的非线性能力来提高模型的表现
最后再通过一个add & normalize,第一个encoder就结束了
接下来进入下一个encoder:多个encoder堆叠起来,前一层输出给后一层输入,就像神经网络的多层一样
decoder 的原理见上面的 gpt-2
4、transformer整体流程
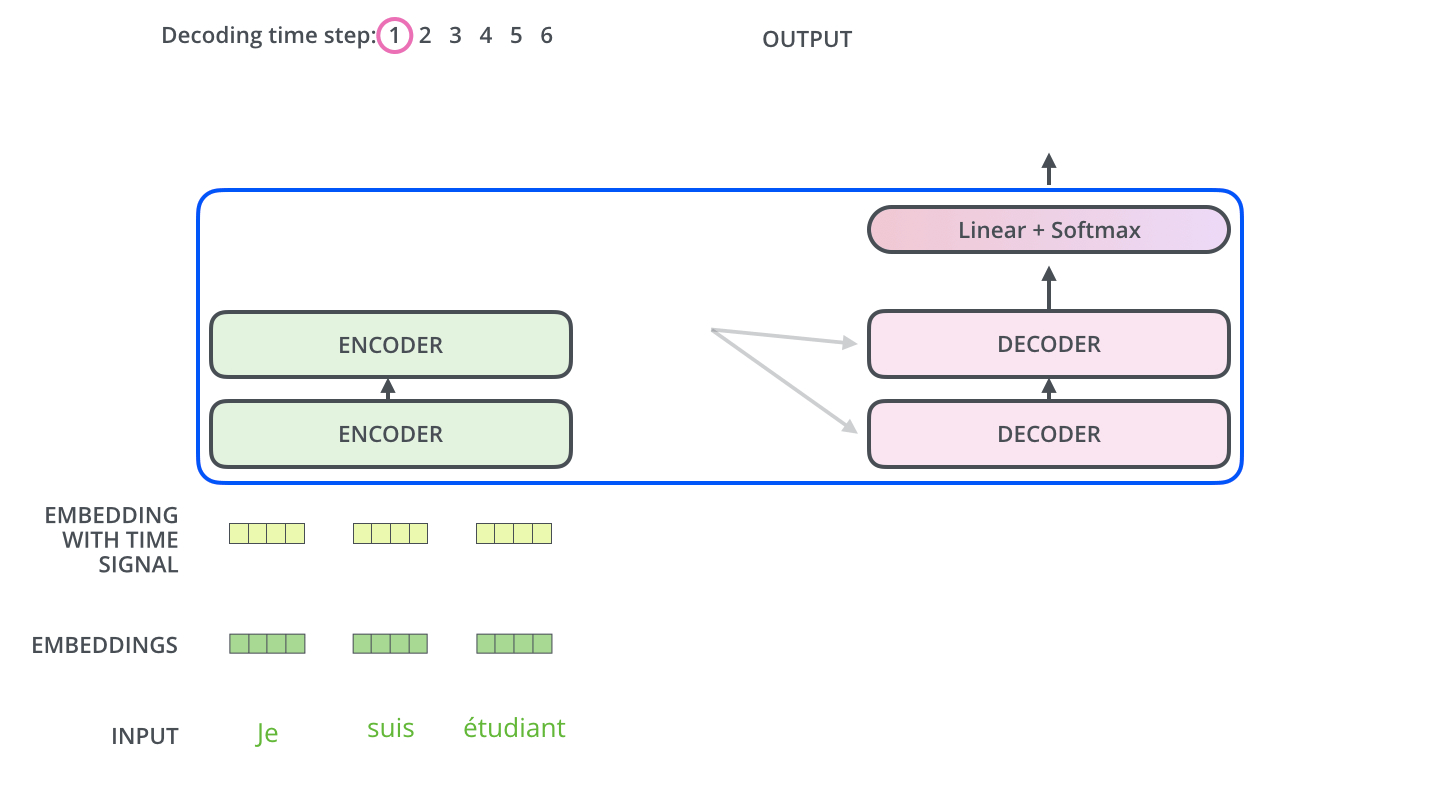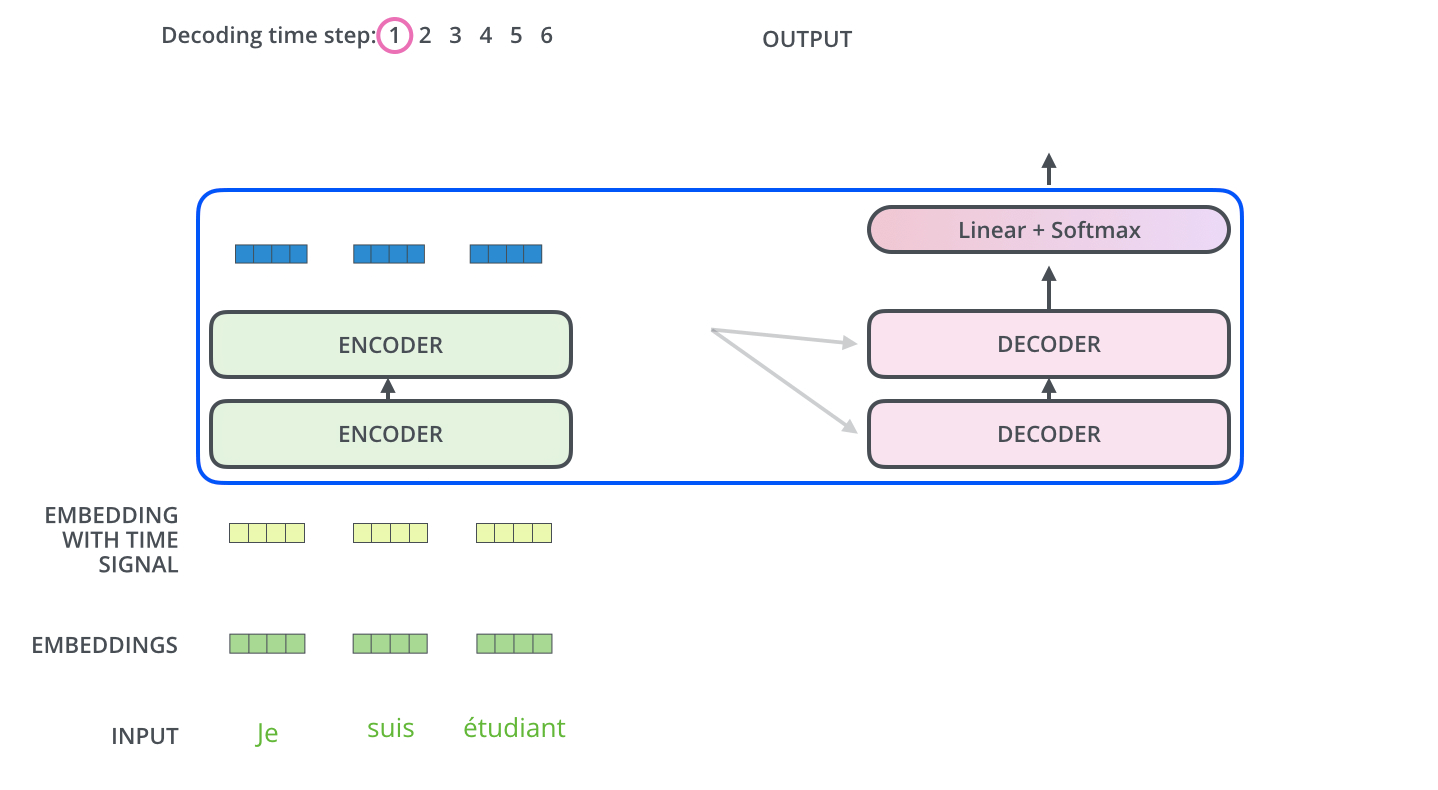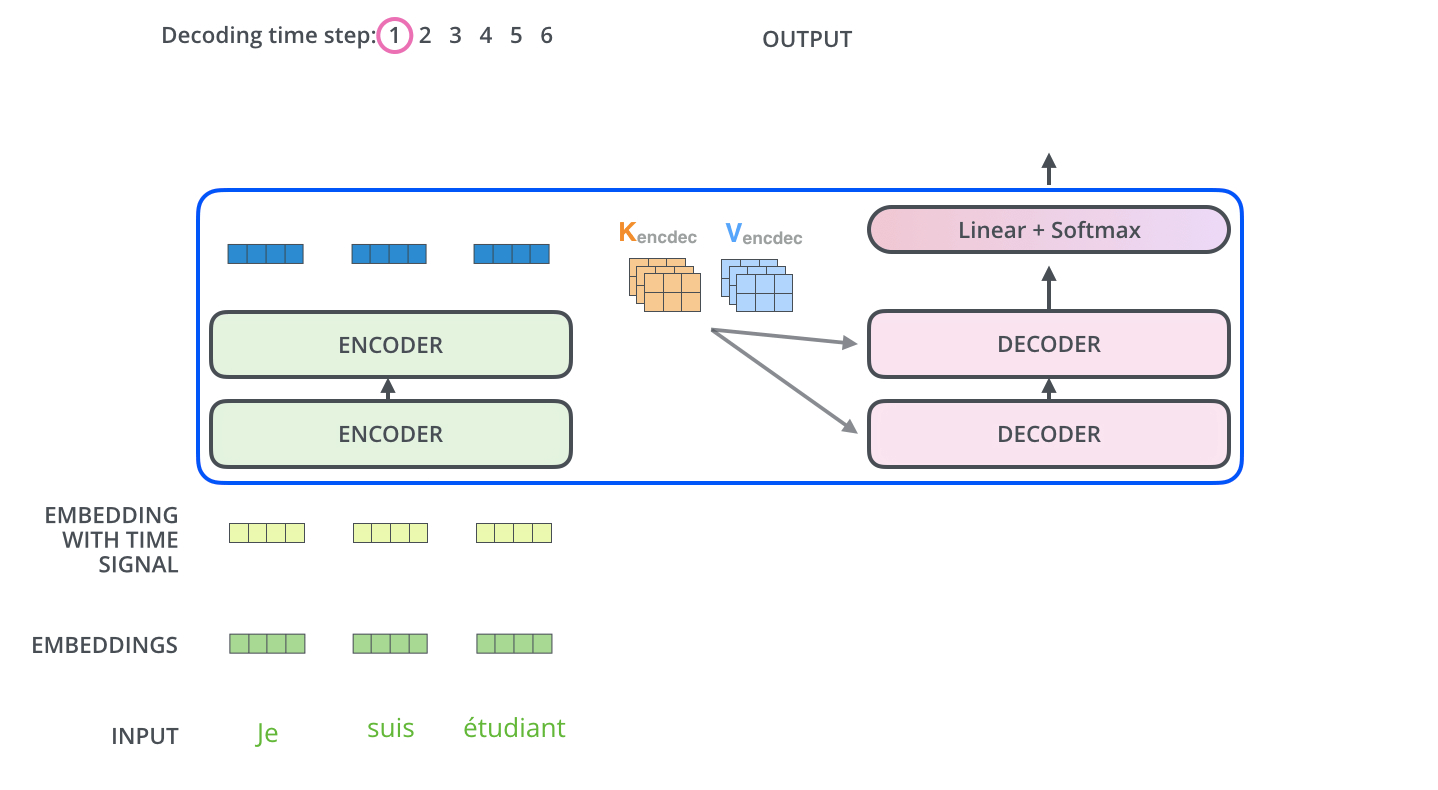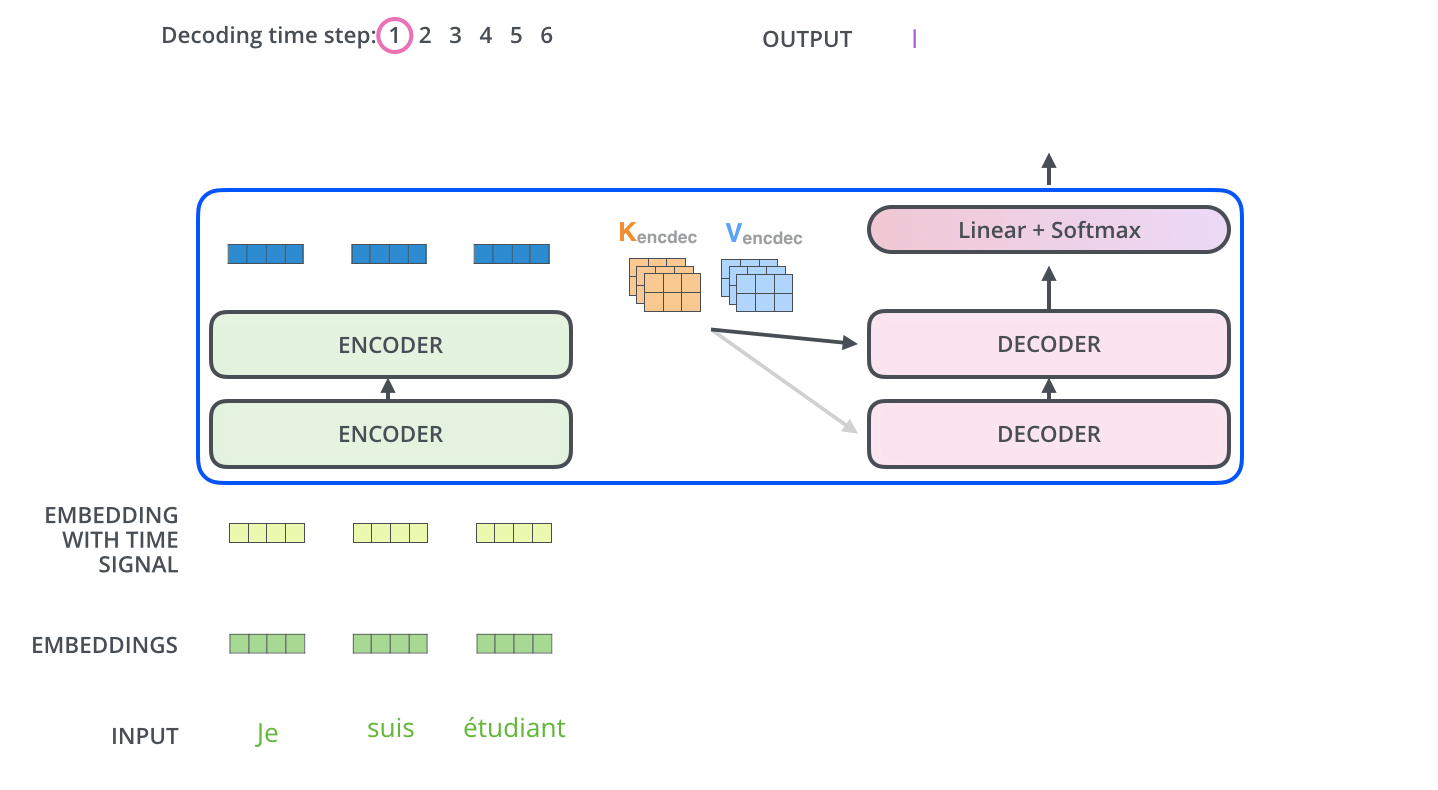
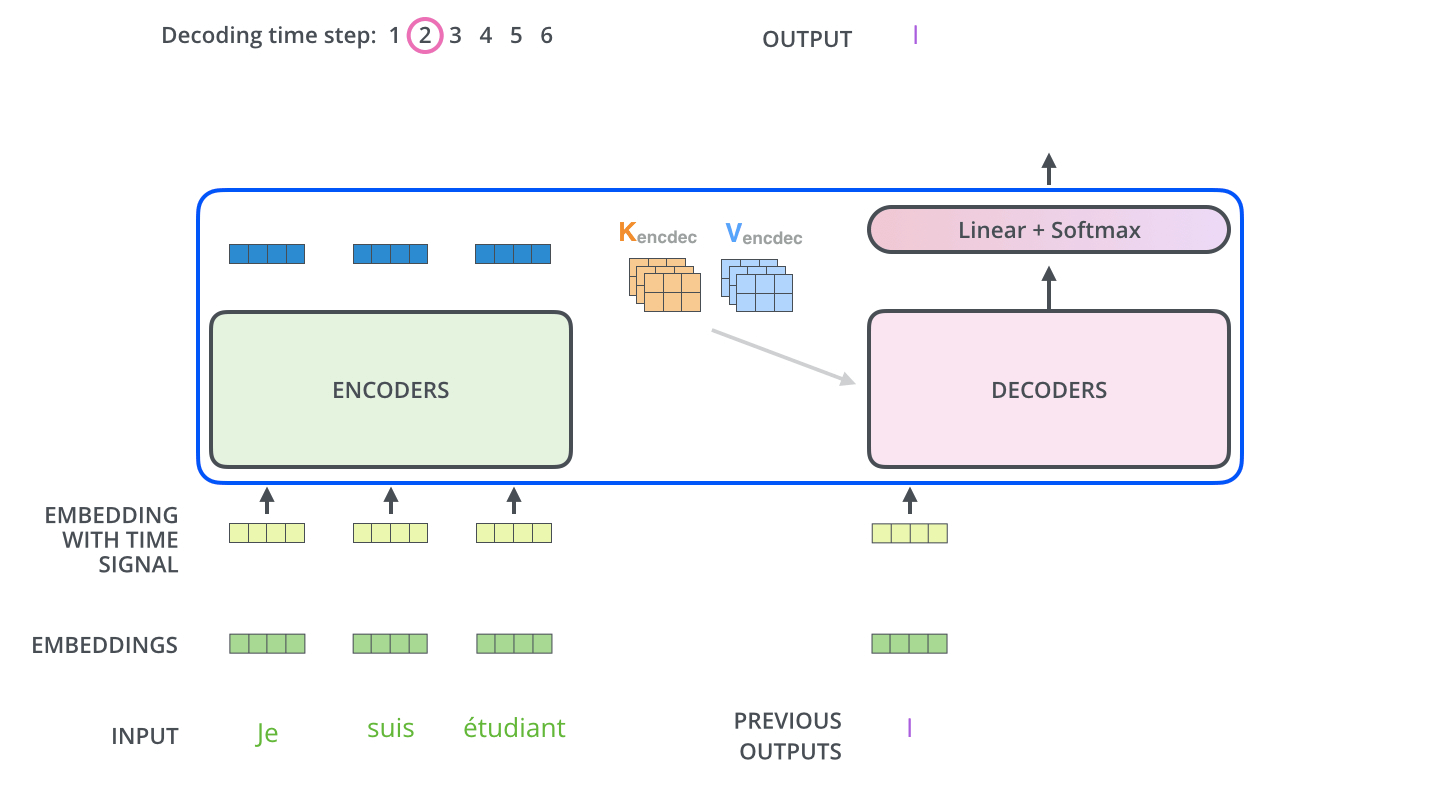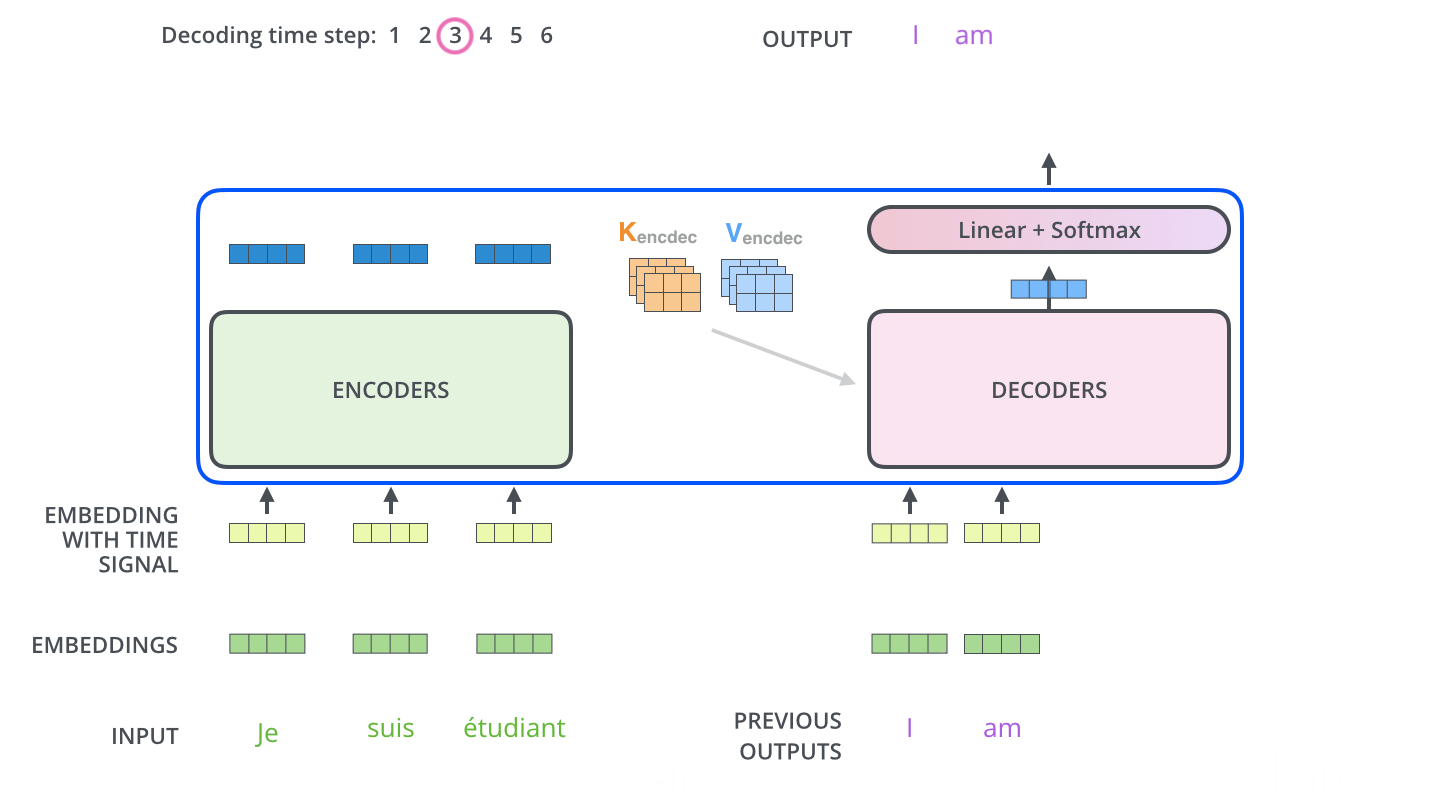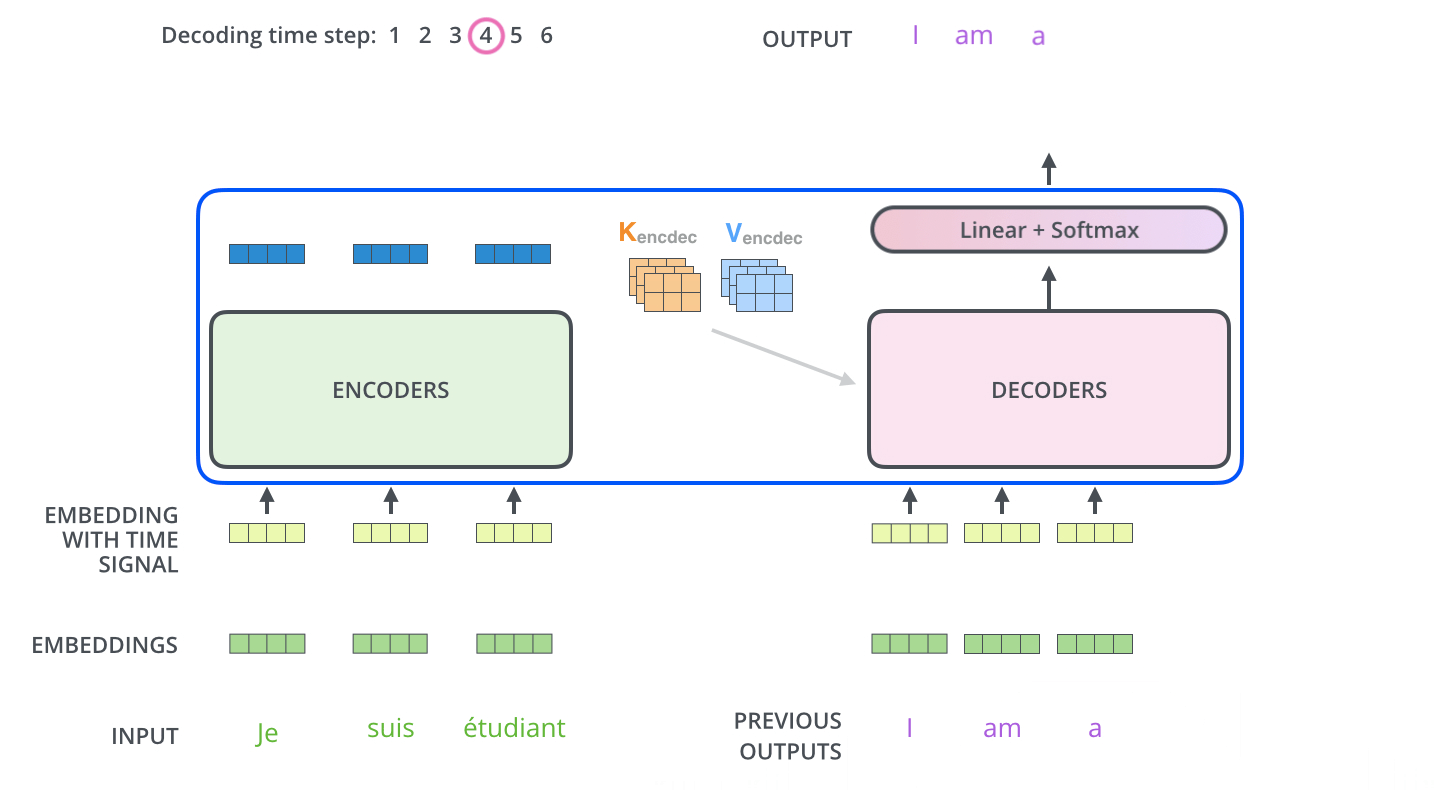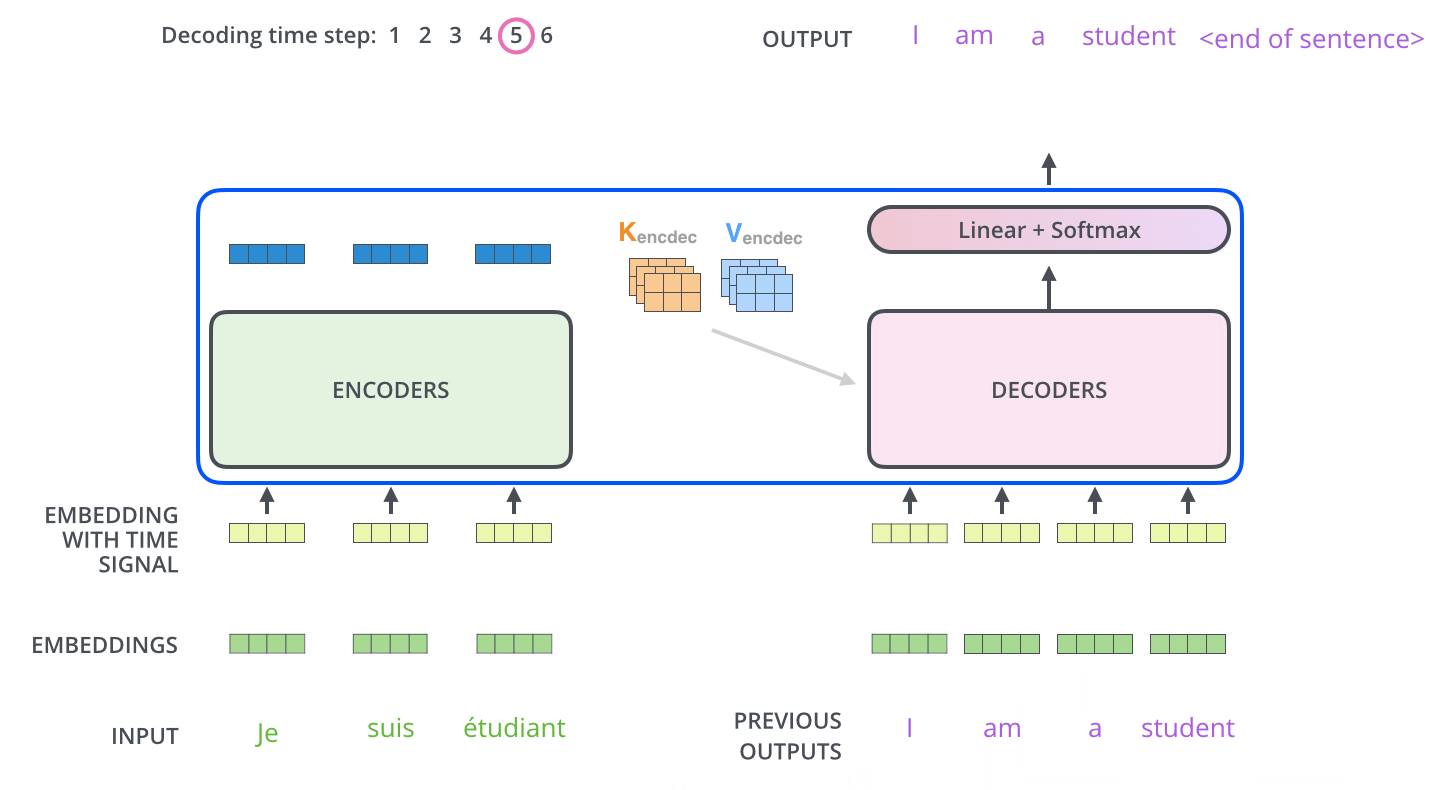
详细:http://jalammar.github.io/illustrated-transformer/
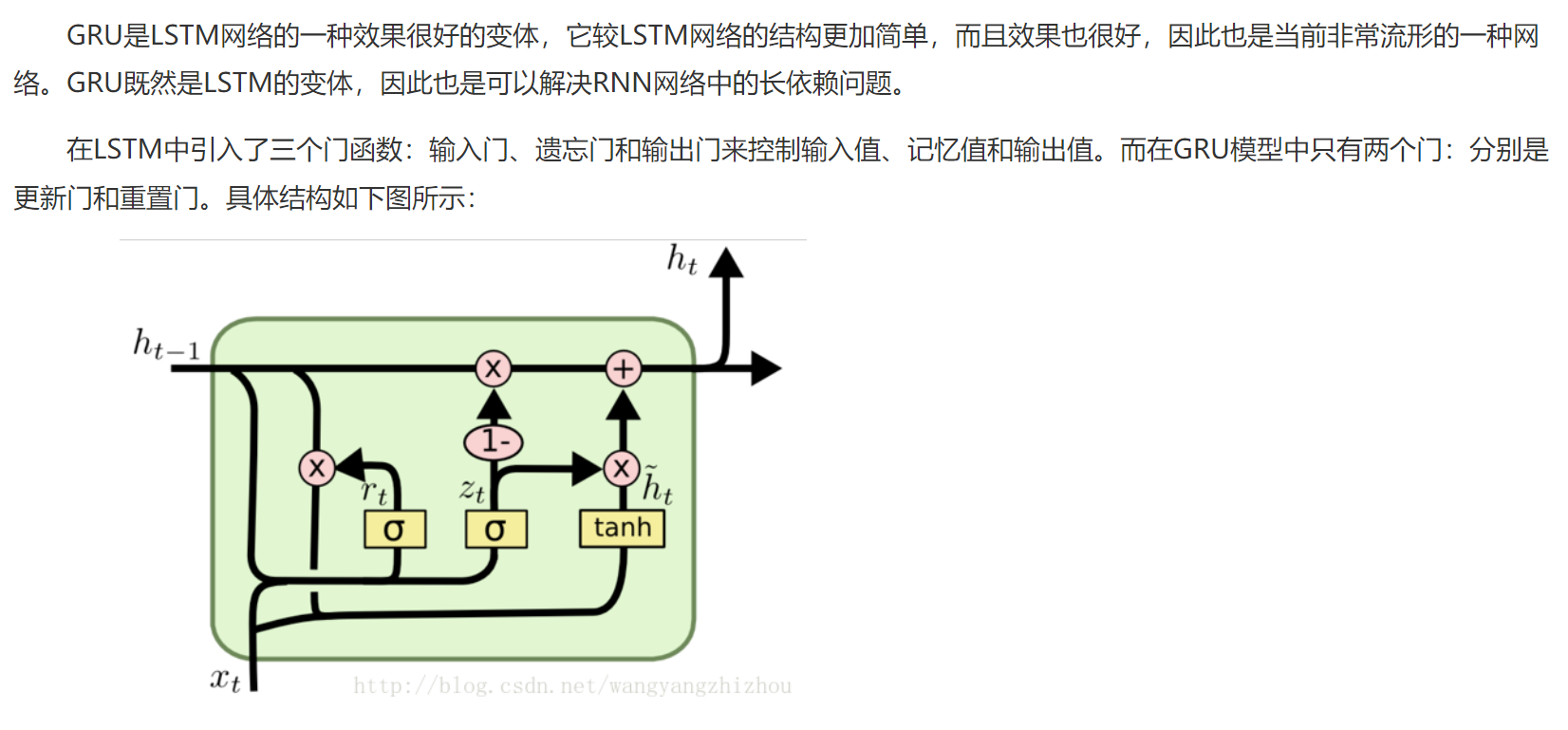
3、GRU
4、梯度下降
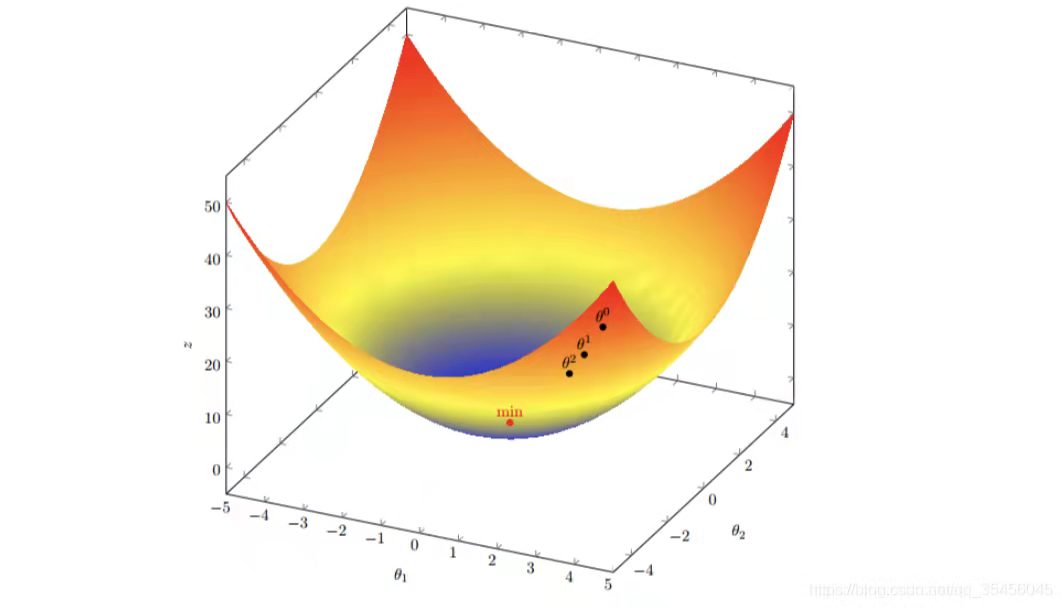
梯度下降法简单来说就是用数值法去一种寻找目标函数最小化的方法。由于梯度方向就是损失函数值上升最快的方向,所以参数=自变量更新时要取梯度相反的方向,所以要有负号,学习率=步长 决定了参数变化的跨度,每次参数的更新都向着局部最小值靠近。
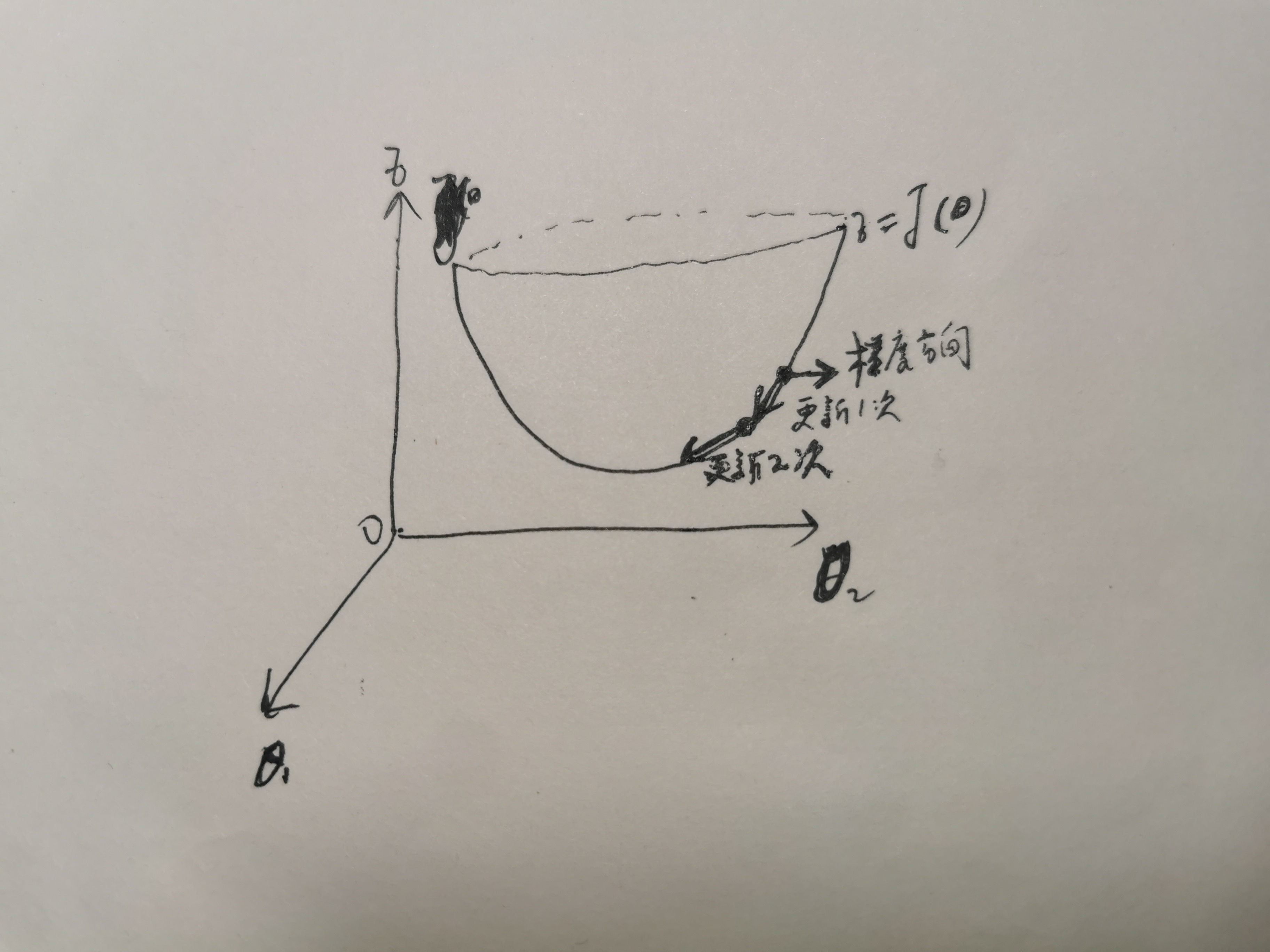
举例:
目标函数 :J(θ) = θ12 + θ22
通过观察就能发现最小值其实就是 (0,0)点
初始的起点为: θ0 = (1, 3)
初始的学习率为:α = 0.1
函数的梯度为:
▽:J(θ) =< 2θ1 ,2θ2>

注意正规方程是解析法,即令代价函数偏导为0求出的:
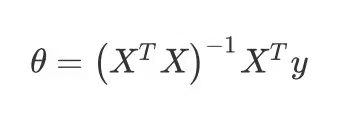
正规方程需要X’X可逆,如果自特征之间可能存在自相关性,此时需要引入正则项,即在X’X的基础上加上一个较小的lambda扰动 ,从而使得可逆。
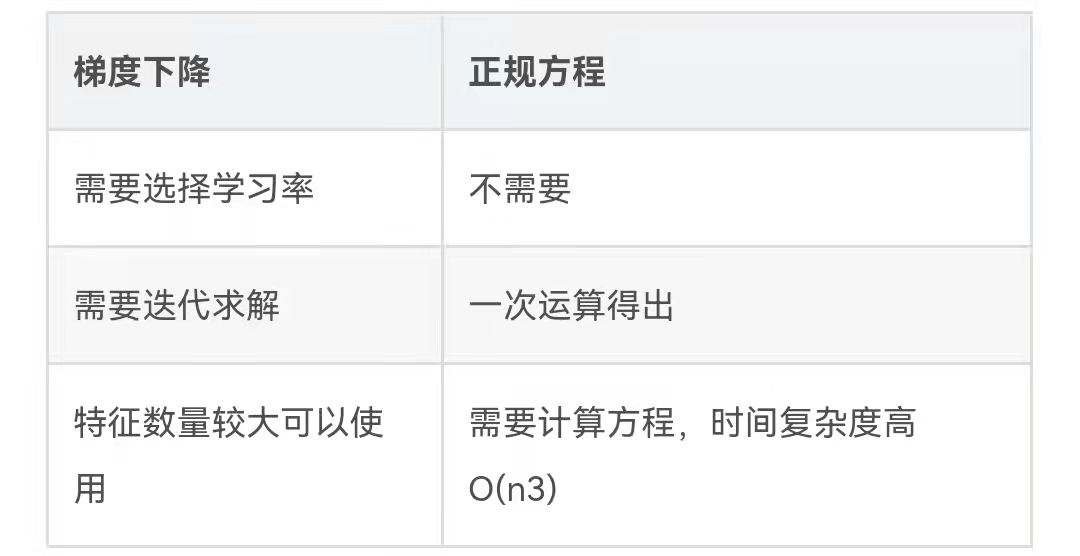
梯度下降和正规方程的对比:
梯度下降算法有:
全梯度下降算法(Full gradient descent)
随机梯度下降算法(Stochastic gradient descent)
随机平均梯度下降算法(Stochastic average gradient descent)
小批量梯度下降算法(Mini-batch gradient descent)
其差别在于样本的使用方式不同。
全梯度下降算法(FG)
计算训练集所有样本误差,对其求和再取平均值作为损失函数。所以全梯度下降法的速度会很慢,同时无法处理超出内存容量限制的数据集。在运行的过程中,不能增加新的样本,收敛效果好
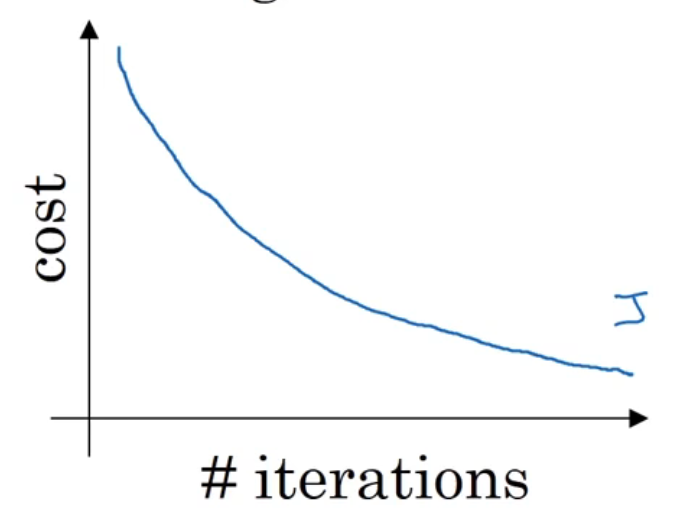
随机梯度下降算法(SGD)
每次迭代用1个样本,因此每次损失函数都不同(以参数为自变量),简单高效,能在训练初期快速摆脱初始梯度值,快速将平均损失函数降到很低。受噪声影响大
小批量梯度下降算法(mini-bantch)
每次取一个batch训练,batch_size通常设置为2的幂次方,更有利于GPU加速处理。若batch_size=1,则变成了SGD;若batch_size=n,则变成了FG。每个batch对应一个损失函数。综合了FG和SGD的优点,目前使用的最多了
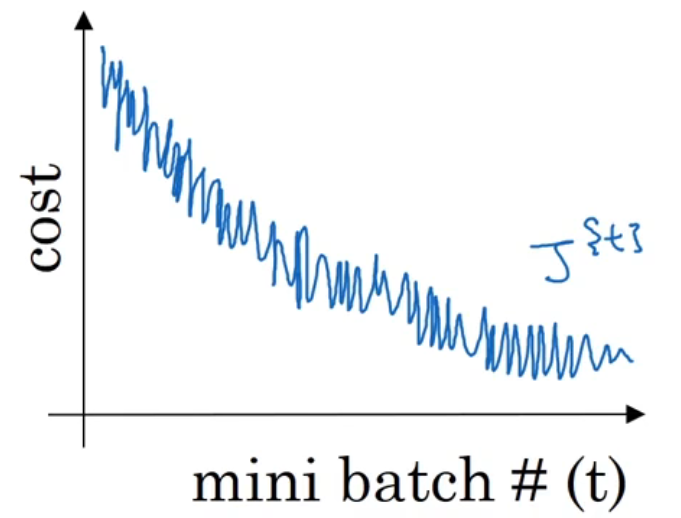
随机平均梯度下降算法(SAG)
内存中维护一个平均梯度,每次迭代时,随机选择一个样本求梯度后更新平均梯度,然后用平均梯度更新参数。这样每一轮梯度更新都与之前的梯度有关,每一轮仅需计算一个样本的梯度,计算成本小,收敛速度快得多
梯度下降优化算法包括:动量法,Nesterov,Adagrad,Adadelta,RMSProp,Adam
【动量法】
梯度更新公式有变化:使用指数加权平均之后梯度代替原梯度进行参数更新,每个指数加权平均后的梯度含有之前梯度的信息,指数加权平均的优点在于无需保存之前的梯度数据,大大节省了内存,而以前每次更新仅与当前梯度值相关,并不涉及之前的梯度
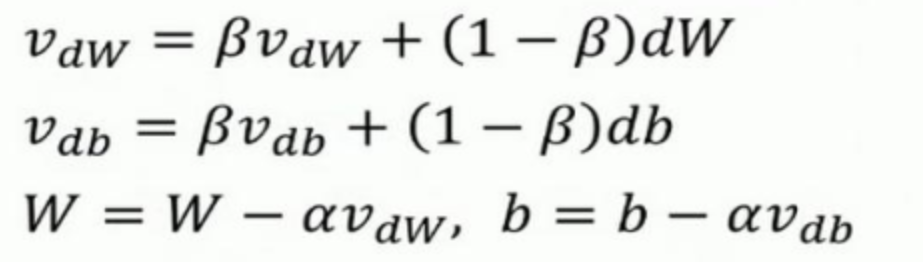
【RMSProp】
能够降低摆动幅度,减轻震荡,加快梯度下降速度
梯度更新公式有变化:
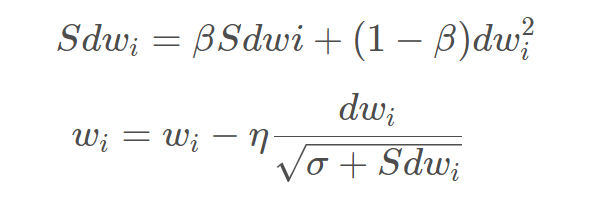
此处极小的值放到根号里面来防止分母为零的情况出现
【adam】
结合了动量法和RMSProp,同时获得了二者的优点,也是梯度更新公式发生变化,倒数第三行是修正项,能够修正初始迭代的参数,但是随着迭代次数的增大,修正项就不起作用了:

详细:https://blog.csdn.net/qq_35456045/article/details/104508217
5、反卷积
输入输出尺寸关系:



实现1:
假设有4x4大小的输入D,有3x3大小的卷积核C
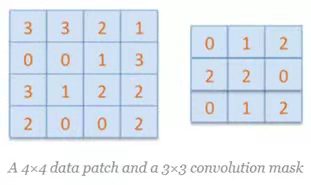
卷积后:
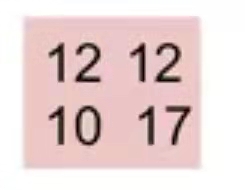
开始反卷积:
先由卷积核得到4个列向量,然后向量堆起来
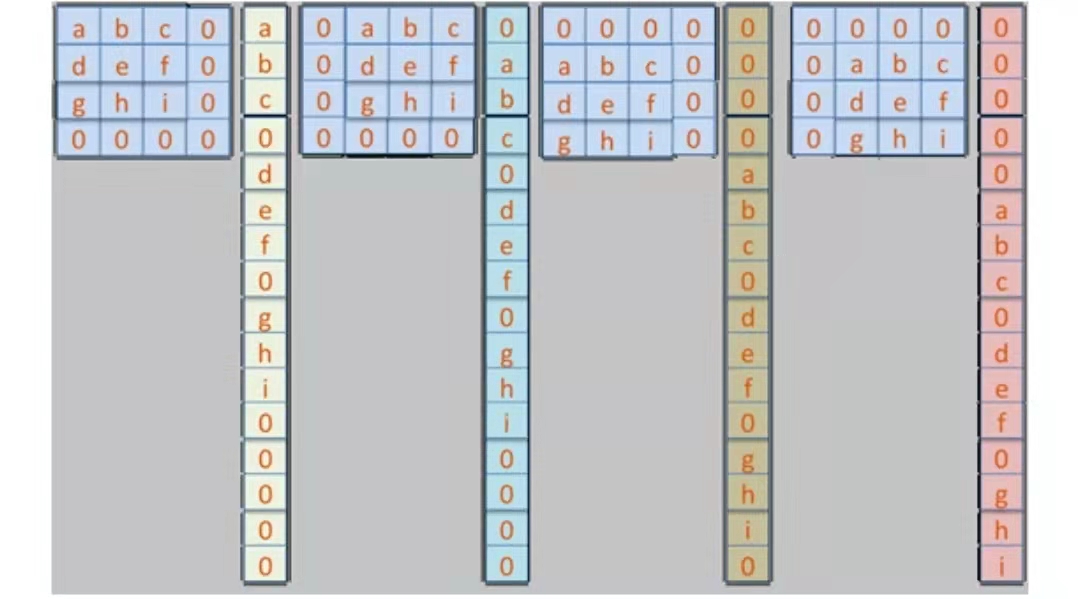
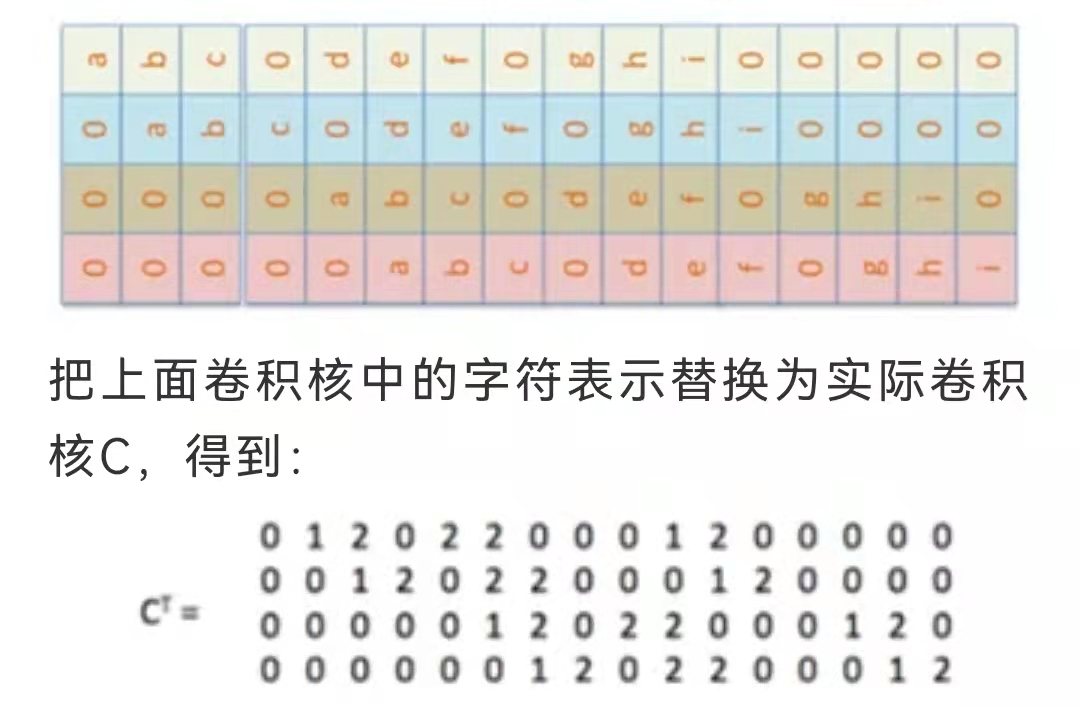
把2x2的输入矩阵转换为1x4的向量E,再乘上面的稀疏矩阵得到16维度向量,重排以后就得到了4x4的输出
实现2:先通过补0来扩大输入图像的尺寸,再进行正向卷积

