



code1
1、三个单引号能实现换行定义字符串:

1、__call__:类中定义该函数,对象()就会调用它
2、
冒号后面是建议传入的参数类型
箭头后面是建议函数返回的类型
如:
def greeting(name: str) -> str:
return 'Hello ' + name
输入参数 name 为 str 类型;输出结果也为 str 类型
3、list做函数参数时,是公用内存地址的,和直接=一样,改变里面外面也会变(浅拷贝)
4、条件且:and
5、 7//2:商取整(截整数)
6、is 比较的是两个对象的地址值(完全一样);而==比较的是对象的值是否相等,其调用了对象的__eq__()方法,=可以使得两者地址直接相等
6、np.array_equal 可判断两个ndarray值(整体)是否相等
7、np.argmax 取出集合中的最大元素的索引
a = np.array([3, 1, 2, 4, 6, 1])
b=np.argmax(a)
print(b) #4
8、哈希表查找,插入,删除的复杂度O(1),键值唯一,在python里面是dict,通过get(key)/[key]方法得到value,get 还能直接看元素在不在,不在则返回 None
9、sorted
lambda : g = lambda x : x**2 lambda定义匿名函数,g(4)返回16
sorted 函数的 key 是排序的依据,第一个参数是要排序对象,里面的每个元素要放到 key 里面
# 利用key [('a', 1), ('b', 2), ('c', 3), ('d', 4)]
L=[('b',2),('a',1),('c',3),('d',4)]
sorted(L, key=lambda x:x[1])
d = {'lilee':25, 'wangyan':21, 'liqun':32, 'age':19}
sorted(d.items(), key=lambda item:item[1])
输出:
[('age',19),('wangyan',21),('lilee',25),('liqun',32)]
10、 查看Python 版本
import sys
print(sys.version)
11、 查看 tf 版本
import tensorflow as tf
tf.__version__
12、yield=return+迭代
带yield的函数是一个生成器,而不是一个函数了,这个生成器有一个函数就是next函数,这一次的next开始的地方是接着上一次的next停止的地方执行的,上一次的变量值依然保留
所以调用next的时候,生成器并不会从函数的开始执行,只是接着上一步停止的地方开始,然后遇到yield后,return出要生成的数,此步就结束。
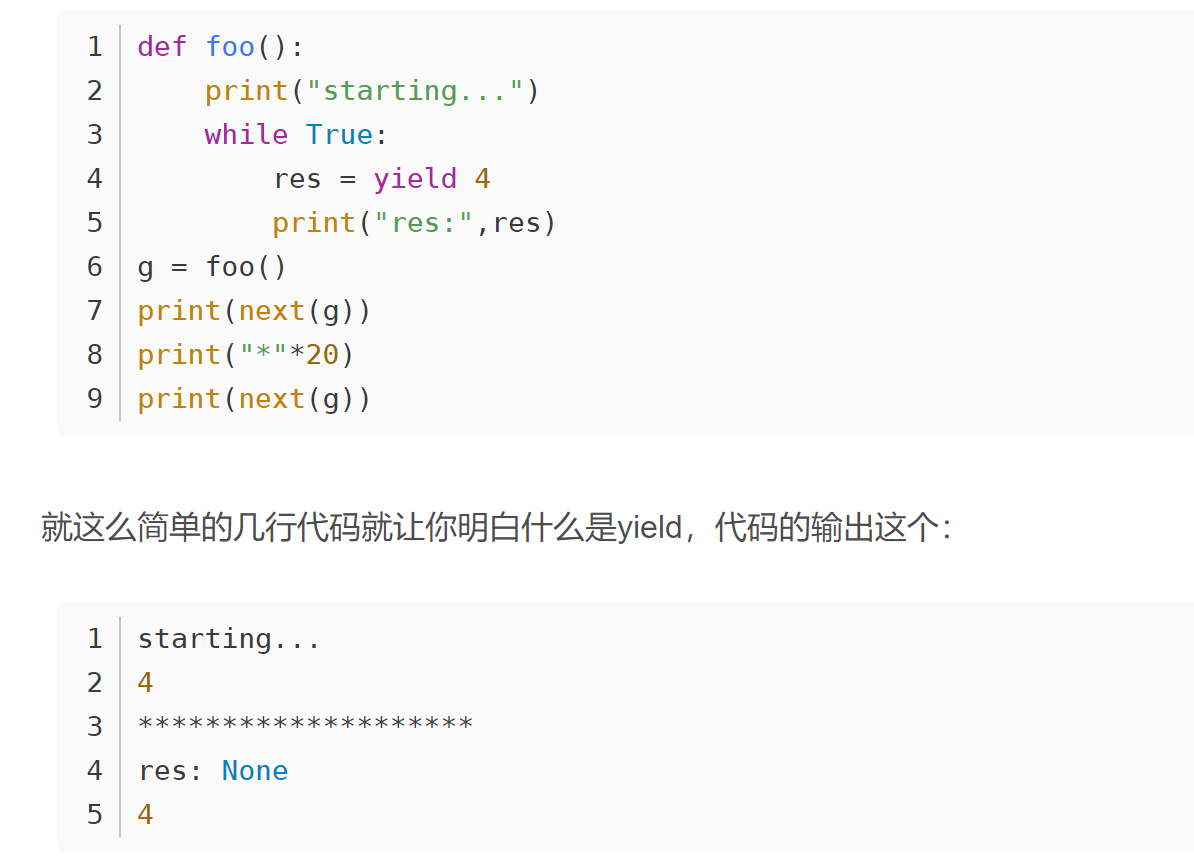
执行顺序:
因为发现 foo函数中有yield关键字,所以foo函数并不会真的执行,而是先得到一个生成器g
调用next方法,foo函数正式开始执行,先执行foo函数中的print方法,然后进入while循环
程序遇到yield关键字,然后把yield想想成return,return了一个4之后,程序停止,并没有执行赋值给res操作,此时next(g)语句执行完成
程序执行print("*"*20),输出20个*
又开始执行下面的print(next(g)),这个时候是从刚才那个next程序停止的地方开始执行的,也就是要执行res的赋值操作,这时候要注意,这个时候赋值操作的右边是没有值的(因为刚才那个是return出去了,并没有给赋值操作的左边传参数),所以这个时候res赋值是None,所以接着下面的输出就是res:None
程序会继续在while里执行,又一次碰到yield,这个时候同样return 出4,然后程序停止,print函数输出的4就是这次return出的4
与for结合,for会自动调用它的next:

优点:生成器是只能遍历一次的,生成器在不使用的时候几乎不占内存,随用随生成,用完即刻释放,非常高效!
13、列表(list)和元组(tuple)的联系
相同点:
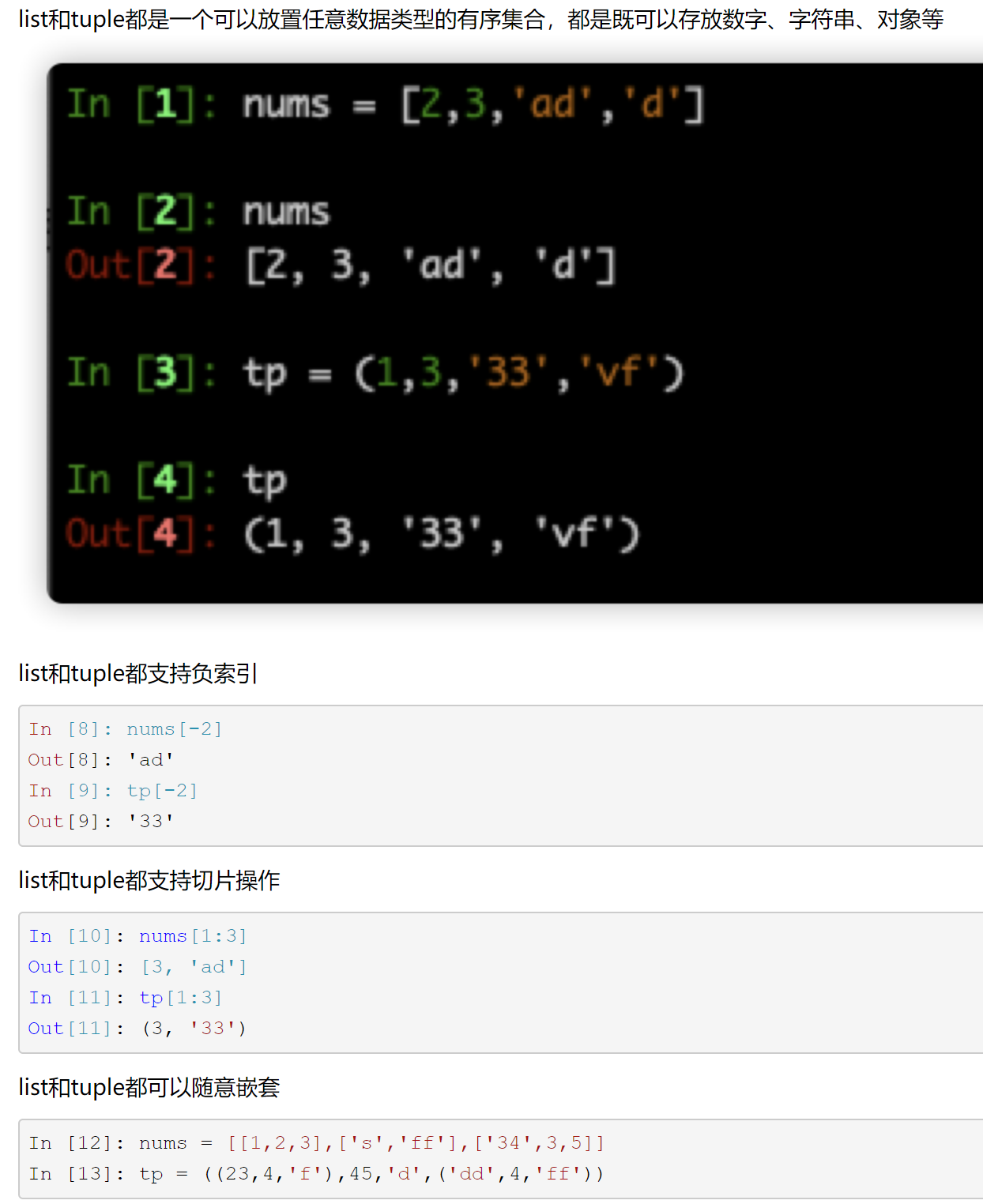
区别:
列表是动态的,长度大小不固定,可以随意的增加、删除、修改元素;元组是静态的,长度在初始化的时候就已经确定不能更改,更无法增加、删除、修改元素
元组长度大小固定,元素不可变,所以存储空间固定;列表的存储空间会根据元素的多少动态分配存储空间
14、python是否区分大小写?
是。Python是一种区分大小写的语言。
15、Python特点?
Python是一种解释型语言,读一行然后解释成机器码,接着立即执行,不需要在运行之前进行编译。
而C语言是编译型语言,需要先全部编译成一个可执行文件,然后运行这个文件。
Python是动态语言,当声明变量时,不需要声明变量的类型。
Python适合面向对象的编程,因为它允许类的定义以及组合(在一个类中以另外一个类的对象作为数据属性)和继承。
Python中没有显式访问修饰符:Public,Protected,Private,但也可以为类定义私有属性. 只需将属性命名变为以__开头,例如 __field,但是,这只能防止无意间的调用, 不能防止恶意调用,因为可以通过obj._className__field在外部访问obj的私有__field
dir(对象)获得该对象的所有属性名和方法名
函数可以像对象那样,函数名可以当作值赋值给一个变量,可以当做函数的参数,可以当做函数的返回值,函数名可以当作元素放在容器中(这叫做第一类对象);类也是第一类对象
编写Python代码很快,但运行比较慢。
Python允许基于C的扩展,它能够调用 C 定义的函数和库,例如numpy函数库就是用C语言处理好数据然后返回给python 。
16、安装环境
ide:pycharm
之前使用anaconda管理了2个版本的python环境,一个是base,python版本是3.6.5,TensorFlow版本是2.6.2,用于日常编程
一个是tensorFlow_1.11.0,python 版本是3.6.5,tensorFlow_1.11.0版本是1.11.0,用于跑bert项目
在prompt里面切换版本:conda activate tensorflow_1.11.0;conda deactivate
指定源下载TensorFlow:pip install tensorflow==1.11.0 -i https://pypi.douban.com/simple
17、if __name__ == ‘__main__‘
只有当本文件运行时,本文件的 if __name__ == ‘__main__‘ 才会执行
理由:每个python文件都包含内置的变量 __name__,在A文件中执行的话,A的if __name__==‘__main__’,该句会被执行
在B文件中import A,执行B,则A文件的__name__是A,则不执行A的if __name__==‘__main__’。
18、debug
PyCharm开始运行,并在断点处暂停,但尚未执行断点所标记的代码
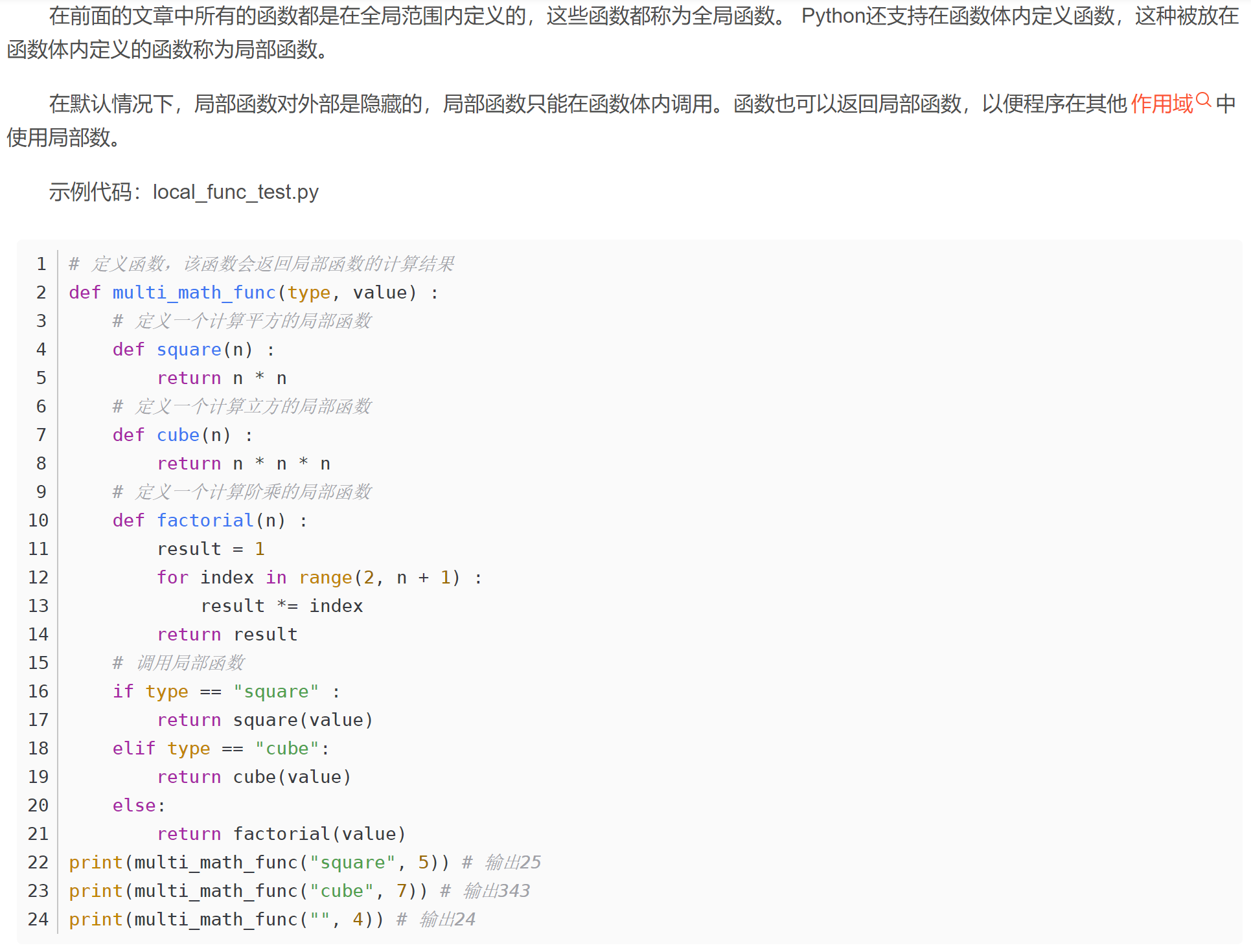
19、局部函数
不能直接访问,得通过全局函数访问:
20、随机
np.random.choice(5, 4) # 从[0,5)中随机抽取4个数
np.random.choice([1,2,3], 4) # 从[1,2,3]中随机抽取4个数
np.random.randint(0, 5, n) # 在[0,5)中随机抽取 size=n 个数
np.random.randn(n) # 返回 size=n 个具有标准正态分布的数
np.random.permutation():随机排列序列

np.random.normal(-1., 1., [a, b]) # 均值-1,标准差为1的正态分布的随机数,标准差越小数据越接近
np.random.randint(1,10,[4,2]) # 生成size=4*2的二维数组,每个元素范围是 [1,10)
21、neo4j
开始菜单:neo4j.bat console,浏览器:http://localhost:7474/
第一次启动有默认用户名和密码:neo4j neo4j 改:qweewq
Neo4j增删改查:
增:
增加一个节点,返回指代它的n,用于后续操作
create (n:Person {name:'我',age:31})
带有关系属性,注意前面是p,后面是n,不能一样
create (p:Person{name:"我",age:"31"})-[:包工程{金额:10000}]->(n:Person{name:"好大哥",age:"35"})
删除节点,match后面要跟上一个动作
在Person标签里面找到name是TYD的节点再返回n,然后删掉它:
match (n:Person{name:"TYD"}) delete n
删除关系
match (p:Person{name:"我",age:"31"})-[f:包工程]->(n:Person{name:"好大哥",age:"35"}) delete f
改:
加上个“好人”标签(在Person标签里面找id=789的)
match (t:Person) where id(t)=789 set t:好人 return t
加上属性
match (a:好人) where id(a)=789 set a.战斗力=200 return a
修改属性
match (a:好人) where id(a)=789 set a.战斗力=500 return a
查:
match (p:Person) - [:包工程] -> (n:Person) return p,n
delete 语句用于删除图元素(节点、关系、或路径)。 不能只删除节点而不删除与之相连的关系,要么使用 detach delete
DETACH DELETE n
22、正则表达式
网站:https://tool.oschina.net/regex
元字符

量词:

.*?尽可能少的匹配: 比如1.*?3就是找到1....3就停了
.* 尽可能多的匹配:比如1.*3就是找到:1...3...3....3
[\u4e00-\u9fa50-9A-Za-z]+:匹配连续的汉字或者字母或者数字,如:阿萨德asd123,=>阿萨德asd123
[^a]+:匹配连续的且没有a的,如abc->bc
(你们){2,}:()把里面的看一个整体,匹配连续的至少2个以上的“你们”
23、for i in range(len(a))=>从0开始全遍历、循环len(a)次
24、dict.get('key', 1):返回val,找不到key则返回默认值1,比dict['key']多个默认值
25、 哈希表存储的是键值对,字典就是哈希表,在字典中找某个key的时间复杂度是O(1)
26、给链表添加新节点的时候就要tail指向它,然后tail移过来
28、三目运算符:

29、list.remove(元素):从 list 中移除某个元素;list.pop(index):不要第 index 的 元素,没有index的话不要最右的元素
29、[2,4]+[1,3,'a']=>[2, 4, 1, 3, 'a']
l=[2,4]
l.append([1,3]) # [2, 4, [1, 3]]
l=[2,4]
l.extend([1,3]) # [2, 4, 1, 3]
30、快速排序

快排不稳定,因为它可能打乱原来相同元素的顺序
31、动态规划
动态规划与分治方法类似,都是通过组合子问题的解来来求解原问题的。分治方法将问题划分为互不相交的子问题,递归的求解子问题,再将它们的解组合起来,求出原问题的解。而动态规划与之相反,动态规划应用于子问题重叠的情况,即不同的子问题具有公共的子子问题,在这种情况下,分治方法会做许多不必要的工作,他会反复求解那些公共子子问题。而动态规划对于每一个子子问题只求解一次,将其解保存在一个表格里面,从而无需每次求解一个子子问题时都重新计算,避免了不必要的计算工作。
特点:函数值变成数组值;可通过递推公式(类似递归)将大问题分解成小问题,然后从小问题往期推着求;开始(类似递归的出口)也要给表做个赋值
例如斐波那契:
def fab(n):
if n<=1:
return n
res=[]
res.append(0)
res.append(1)
i=2
while i<=n:
res.append(res[i-1]+res[i-2])
i+=1
return res[n]
32、 定位一个字符串可以用 i,j 2个变量;
33、[1]*3 => [1,1,1]
34、a[ i:i+L]:返回 i 是起始,长度为L的串
35、函数内部要使用外部定义的变量时,如果直接修改,则会新定义一个局部变量,如果直接使用,则使用的是外部变量,但不能先使用后修改值,否则会报错。
36、要取第 i 行第 j 列,ndarray:用[i,j],纯list的话,用[ i ][ j ]
37、range(n,n),range(n,n-1)...都是[],所以可以直接用到for里面,不用判断
38、想记录一个长度为n的字符串的所有连续子串的状态,可以用一个n*n的矩阵记录
40、想用全局变量的时候可以考虑使用对象属性,对象方法来访问,这样封闭性好
9、重定向

12、字符串、list 倒序输出 ::-1,list本身逆序:list.reverse()
6、reduce(函数f,[a,b,c,d])
from functools import reduce
对a,b通过f,结果再和c通过f,结果再和d通过f
适用于对序列做同一个单向运算:a+b+c+d/a*b*c*d/a-b-c-d...
18、读取输入:
import sys
sys.stdin.readline().strip()
18、数字字符串=》数值:int('00431')
19、统计频数
c = collections.Counter(list) # 频数降序排练
c = collections.Counter('字符串') # 频数降序排练
c.most_common(5) #取频数最高的前5的结果,不传则返回所有结果,形式是元组列表,不是字典
取value:c.get(key)
所有key:c.keys()
所有values:c.values()
c.update(list/字符串):在原有基础上(可以是空),加入新的参数再做统计
转成dict:dict(c)
d = Counter(),d['a']+=2 # 比字典好,不用考虑 key 存不在的问题了
"aaabb".count("a"):统计“a”出现的个数
利用后面的函数排序,max([1,2,3],key = lambda x:-x),返回 1
24、print(1,2,3):1 2 3
25、函数参数
传入实参中,f (a,b=2):b就是默认参数,得在位置参数后面
不定长参数:*a:组成元组;**b,组成字典,可以不传值
函数在定义和调用时应遵循依次是位置参数,默认参数,*args,**kwargs的顺序(定义和调用都应遵循)

27、是 a 的倍数 《=》% a ==0
28、filter(函数,序列):对序列里面的元素过滤,需要符合定义的函数
filter(lambda x:x>1 and x<111,[0,1,222,-1,3])
30、继承
默认集成Object 类,支持多继承,先访问对象属性,再访问父类的类属性,若用super(),则指明调用父类的:
class Foo():
def f1(self):
print('Foo.f1')
def f2(self):
print('Foo.f2')
self.f1()
class Bar(Foo):
def f1(self):
print('Bar.f1')
obj = Bar()
obj.f2()
# 结果
Foo.f2
Bar.f1

31、print(对象):调用对象的__str__方法,得到 return 值
31、len(对象):调用对象的__len__方法,得到 return 值
32、第一列升序,第二列降序:
t = [
[1, 3],
[2, 1],
[1, 2],
[1, 4],
[2, 5],
[3, 1]
]
t.sort(key=lambda x: (x[0], -x[1])) # t=sorted(...) 也可以
print(t)
# [[1, 4], [1, 3], [1, 2], [2, 5], [2, 1], [3, 1]]
33、维度
【:1维,【【:2维
[1,2,3]: 3 (1维)
[ [ 1,2,3 ] , [ 3,4,5 ] ] : 2*3,外面有2个大元素,大元素里面有3个小元素 (2维)
[[1],[1],[1]] : 3*1 (2维)
[[[1., 1.,2], [2., 2.,2]], [[3., 3.,2], [4,1., 4.]]]:2*2*3(3维)
reduce_mean:计算均值,并能降低一维
举例x:
[[[ 1. 1.]
[ 2. 2.]]
[[ 3. 3.]
[ 4. 4.]]]
reduce_mean(x,axis=3-1=2),axis指的是维度,只对最里面(第2维)的做,axis=1,和外面的做;axis=0,和最外面的做,不写axis的就是对所有元素计算,数字越大越往里凑


初始化二维list,然后再修改会出错的,s=[[0]*2]*2,s[1][0]=333,其他元素也会变,它某些元素公用内存了,改用numpy初始化吧
递归的本质:先给递归函数1个定义,然后在递归里面,把这种复杂的定义留给他的后一代去处理,只用添加定义在出口时的情况
一个树根就能代表一棵树了

