
jvm
jvm跑在操作系统上,java程序都跑在jvm上,jre包含了jvm
.java文件编译后是.class文件,类加载器加载class文件
类装载子系统classloader把字节码(.class)文件加载到运行时数据区,字节码执行引擎负责执行内存里面的代码
每个线程有自己的栈,存储自己运行的局部变量...,一开始执行main方法时,先把main方法的局部变量压入栈,直到执行main里面的另外一个run方法,把该run方法继续压进去,直到run执行完,弹走run,每一个方法对应一个线帧。jvm用c写的
执行引擎负责修改程序计数器
JVM中提供了三层的ClassLoader:
Bootstrap classLoader:主要负责加载核心的类库(java.lang.*等),构造ExtClassLoader和APPClassLoader。
ExtClassLoader:主要负责加载jre/lib/ext目录下的一些扩展的jar。
AppClassLoader:主要负责加载应用程序的主函数类
全盘负责委托机制:当一个classloader加载一个类时,除非显示的使用另一个classloader,不然该类所依赖和引用的类也有这个classloader所加载
双亲委派机制:首先会在AppClassLoader中调用loadClass方法检查是否加载过,如果有那就无需再加载了。如果没有,那么会拿到父加载器,然后调用父加载器的loadClass方法。父类中同理也会先检查自己是否已经加载过,如果没有再往上。注意这个类似递归的过程,直到到达Bootstrap classLoader之前,都是在检查是否加载过,并不会选择自己去加载。直到BootstrapClassLoader,已经没有父加载器了,这时候开始考虑自己是否能加载了,如果自己无法加载,会下沉到子加载器去加载,一直到最底层,如果没有任何加载器能加载,就会抛出ClassNotFoundException。(简单点:Bootstrap classLoader调用loadClass方法检查自己是否有该类,有的话加载,没有的话,向下ExtClassLoader,还没有的话,向下AppClassLoader)
每个线程都有自己的程序计数器,就是一个指针
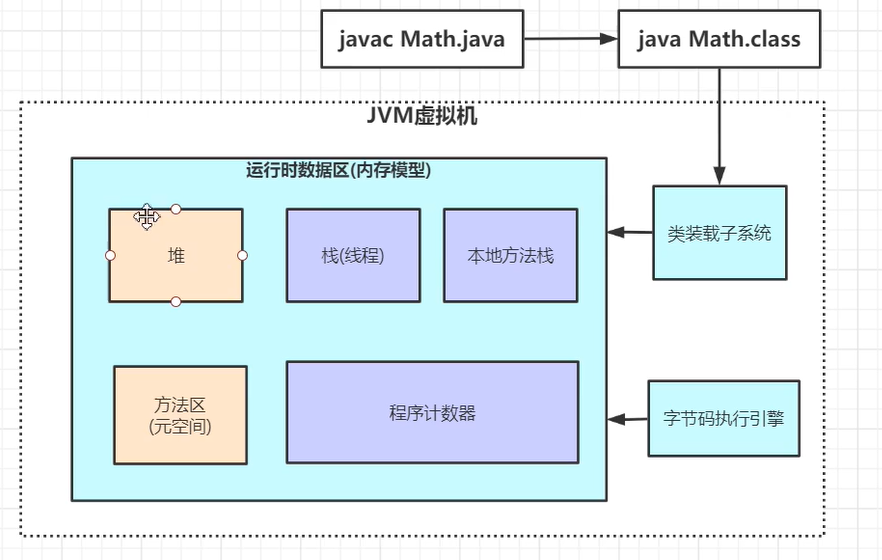
方法区(元空间)(jdk之前版本叫永久区):
方法区是共享的,保存:静态变量、常量、类信息(构造方法、接口定义)、运行时的常量池

线栈有局部变量表(变量值为操作数栈的运算结果),操作数栈(中间用到数的运算就使用它了),动态链接(存储方法的物理地址)、方法出口(保存方法调用完后,要返回的地址,即返回方法调用者)
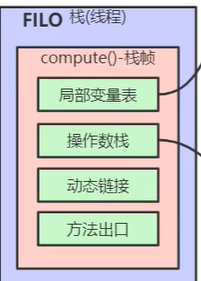
如果方法里面new了一个对象,则该对象实例存在堆里面,线帧里面的局部变量(引用)指向该对象(保存对象在堆里面的地址)
方法区保存常量、静态变量、类信息,如果静态变量是个对象,则保存对象的物理地址
native:本地方法库都由C++编写
有3个jvm,我们学的是hotspot版的
一个jvm只有1个堆,堆内存的大小可以调节
当发生OOM:
![]()
使用JPofiler工具分析OOM原因:
先设置VM:
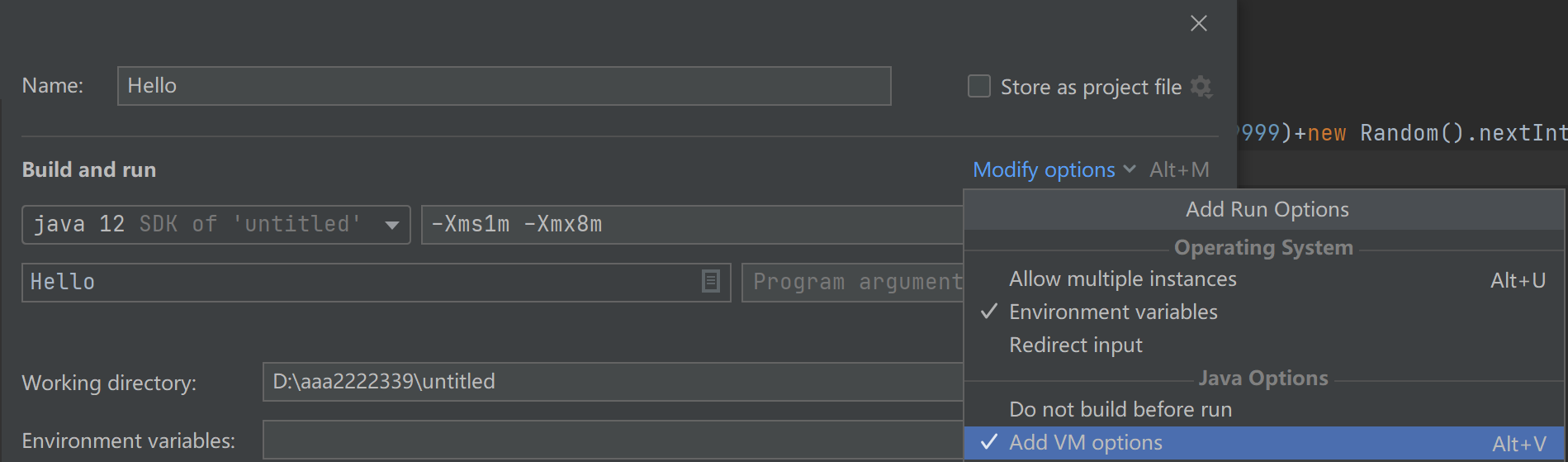
-Xms1m -Xmx2m -XX:+PrintGCDetails:设置JVM初始堆内存为1m,设置JVM最大堆内存为2m,打印GC(Garbage Collection,垃圾回收)信息,当堆内存超过最大值2m时就堆溢出了
设置:-Xms1m -Xmx2m -XX:+HeapDumpOnOutOfMemoryError:当发生堆溢出时,会生成一个.hprof文件,里面记录了堆错误信息
写入代码:
import java.util.ArrayList; public class Hello { public static void main(String[] args) { String s = "asd"; ArrayList<Hello> l = new ArrayList<>(); while(true){ l.add(new Hello()); } } }
使用jprofile打开它,发现错误所在行数:
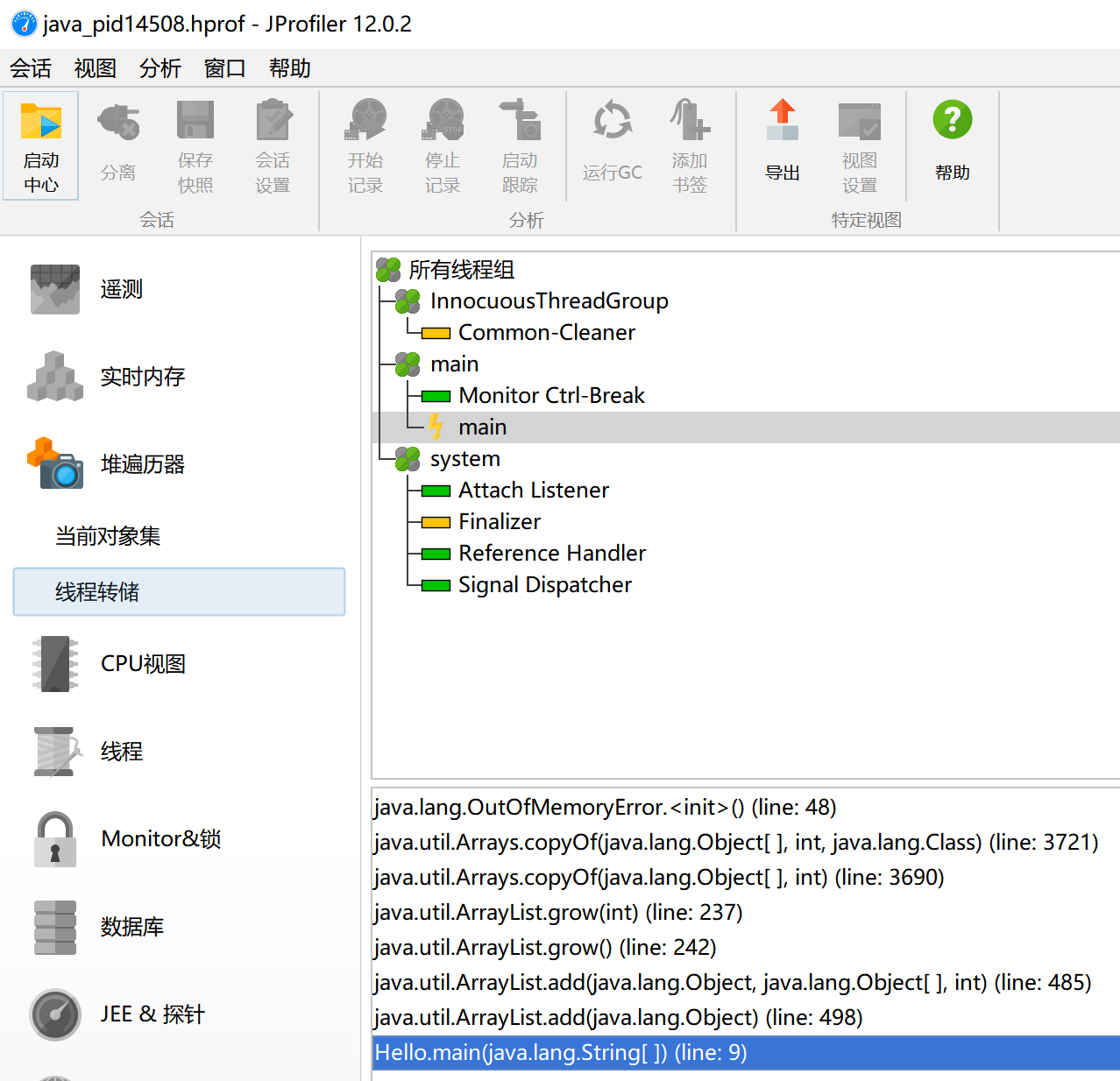
如果要捕获其他异常,则换个名字就好了如OutOfMemoryError
GC的作用区包括:方法区和堆,大部分回收的都是新生代
TLAB:在开启TLAB的情况下,虚拟机会为每个Java线程分配一块TLAB空间,对象分配前首先看看能不能在TLAB上分配。JVM使用TLAB来避免多线程冲突,在给对象分配内存时,每个线程使用自己的TLAB。TLAB本身占用eEden区空间。TLAB空间一般不会很大,因此大对象无法在TLAB上进行分配,总是会直接分配在堆上。
类加载过程:
1.加载:通过全限定名获取字节流;将字节流的类描述信息存到方法区;生成java.lang.Class对象放到堆中,作为方法区数据的入口
2.验证:确保class文件的字节流中包含的信息符合虚拟机的规范,包括:文件格式验证、元数据验证、字节码验证、符号引用验证
3.准备:在方法区为静态变量分配内存并初始化为默认值
4.解析:将符号引用(就一个符号)转换为直接引用
5.初始化:对类变量初始化
gc垃圾回收:新建的对象到伊甸园区,直到满了, 触发轻gc,将里面没有被引用的对象清理掉,其余的放到幸存区0或1区,直到幸存区满了,触发重gc,处理掉伊甸园和幸存区的对象,剩下的放到养老区
当新生区和养老区都满了,堆内存溢出,oom

识别垃圾对象的方法:引用计数(给每个对象一个计数器记录引用的次数,计数器本身也占空间,清除的时候把次数为0的清除掉)、可达性分析(从GC root到达不了的对象都是垃圾对象)
GC算法分为:标记清除法、标记压缩法、复制算法、
复制算法:
1、当Eden区满的时候,会触发第一次young gc,把还活着的对象拷贝到Survivor From区;当Eden区再次触发young gc的时候,会扫描Eden区和From区域,对两个区域进行垃圾回收,经过这次回收后还存活的对象,则直接复制到To区域,并将Eden和From区域清空。 2、当后续Eden又发生young gc的时候,会对Eden和To区域进行垃圾回收,存活的对象复制到From区域,并将Eden和To区域清空。 3、可见部分对象会在From和To区域中复制来复制去,如此交换15次(由JVM参数MaxTenuringThreshold决定,这个参数默认是15),最终如果还是存活,就存入到老年代
标记清除法:
gc开始运行的时候会停止应用程序的运行并且开启gc线程,然后开始标记工作,从根节点开始标记引用的对象,每个对象中都有一个mark 标记位,标记之后mark由0变成1,接下来开始清除垃圾对象,也就是mark=0的对象,那么清除完以后存活下来的对象mark标记由1还原成0,清除工作完成之后就开始唤醒应用的线程。
优缺点:因为标记和清除两个动作都需要遍历所有的对象,并且在gc时要停止应用运行,对于交互性要求比较高的应用来说就不能满足;通过标记清除算法整理的内存碎片化比较严重
标记压缩算法:只是清除不同,在清除垃圾对象的时候将存活的对象压缩到内存的一端,然后清理边界以外的垃圾对象,从而解决碎片化严重的问题,但是移动对象需要消耗时间
总结:

分配担保机制:大对象在eden,from,to区放不下,就干脆放到养老区
垃圾收集器分为古典垃圾回收器,中古时代的垃圾回收器,现代的垃圾回收器:
顺序:先开发了serial 和serial old串行垃圾收集器,然后开发parallel scavenge和parallel old并行垃圾收集器,接着开发了用于老年代的CMS,但是他和parallel scavenge不搭配,于是开发parnew 收集器,parnew收集器和CMS重在缩短垃圾回收的时间,而parallel scavenger重在控制系统运行的吞吐量。
串行的gc垃圾回收器(垃圾回收线程开启时,其他所有线程都停止,开始stw):
serial收集器:串行收集器,一个线程进行年轻代的垃圾收集工作
serial old收集器:一个线程进行老年代的垃圾收集工作
parallel scavenge收集器:开启多个线程进行年轻代的垃圾回收
parallel old收集器:开启多个线程进行老年代的垃圾回收
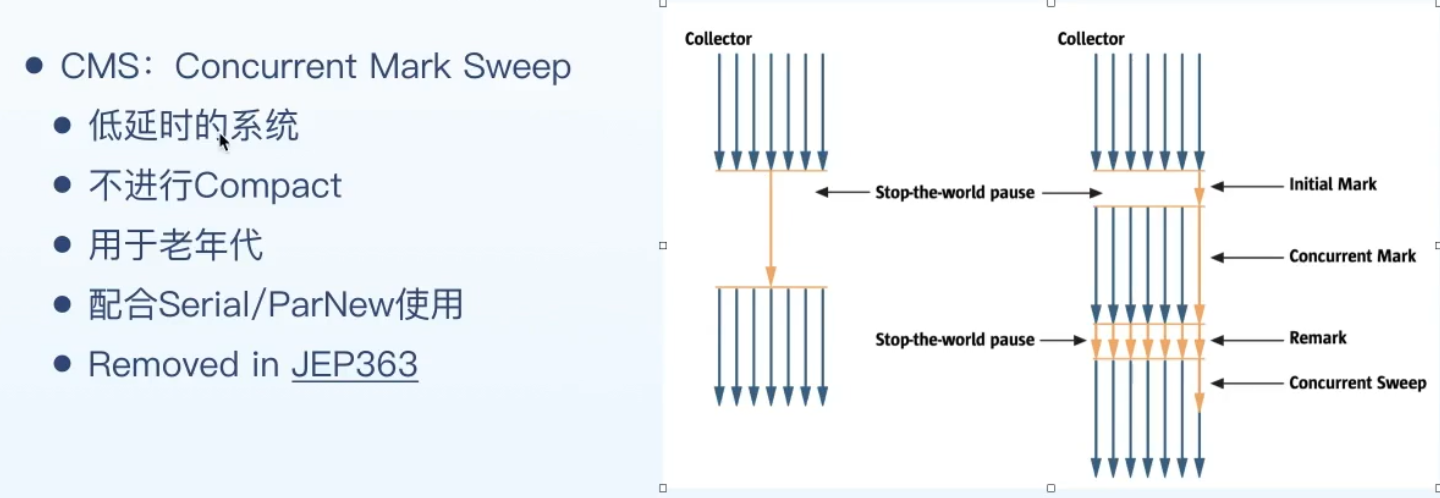
中古时代是CMS=concurrent mark sweep收集器:
要收集垃圾时,先让所有用户线程做个短暂的停顿,开启一个线程初始化对象的标记,然后放开所有用户线程,一个线程同步进行标记(并发工作),然后再停顿一下,多个线程开始重新标记,然后用一个和用户进程并发进行的sweep进程清除垃圾(并发)
缺点是内存碎片,对cpu资源敏感,无法处理浮动垃圾(程序在运过程中产生的垃圾)
parnew 收集器:多个线程进行年轻代的垃圾回收
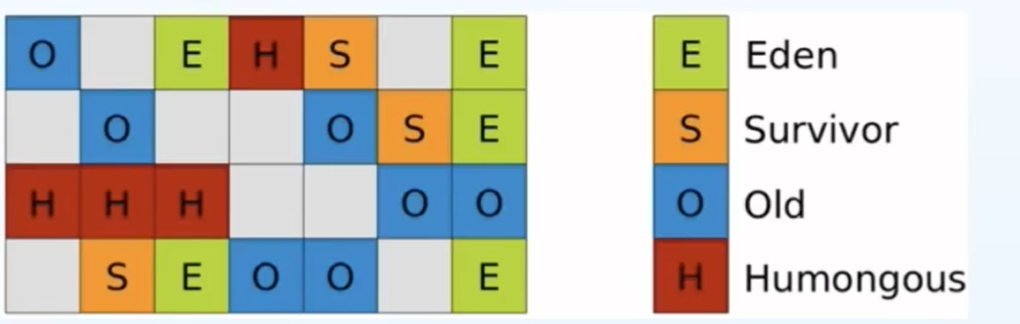
现代的回收器:G1
把堆分成多个等大的区域:
humongous属于老年代,大对象能放到这儿
g1解决跨代引用的机制:每个区域被划分为若干个卡片,该区域就对应一个card table,当a卡片里的对象引用了另一个区域b,则把a卡地址记录到b中的remember set里面,同时把card table里面的a卡标记为dirty,那么,当清理完b区域的对象后,在扫描一遍b的rs做对应的清除。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号