
词向量
分词:把中文的汉字序列切分成有意义的词,就是中文分词,有些人也称为切词。我是一个学生,分词的结果是:我 是 一个 学生。
停用词:搜索引擎在索引页面或处理搜索请求时会自动忽略某些字或词,这些字或词即被称为Stop Words(停用词)。 如常见的“的”、“在”、“和”、“接着”之类
词嵌入(word embedding):把文本转换成数值形式,或者说——嵌入到一个数学空间里,而 Word2vec,就是词嵌入( word embedding) 的一种
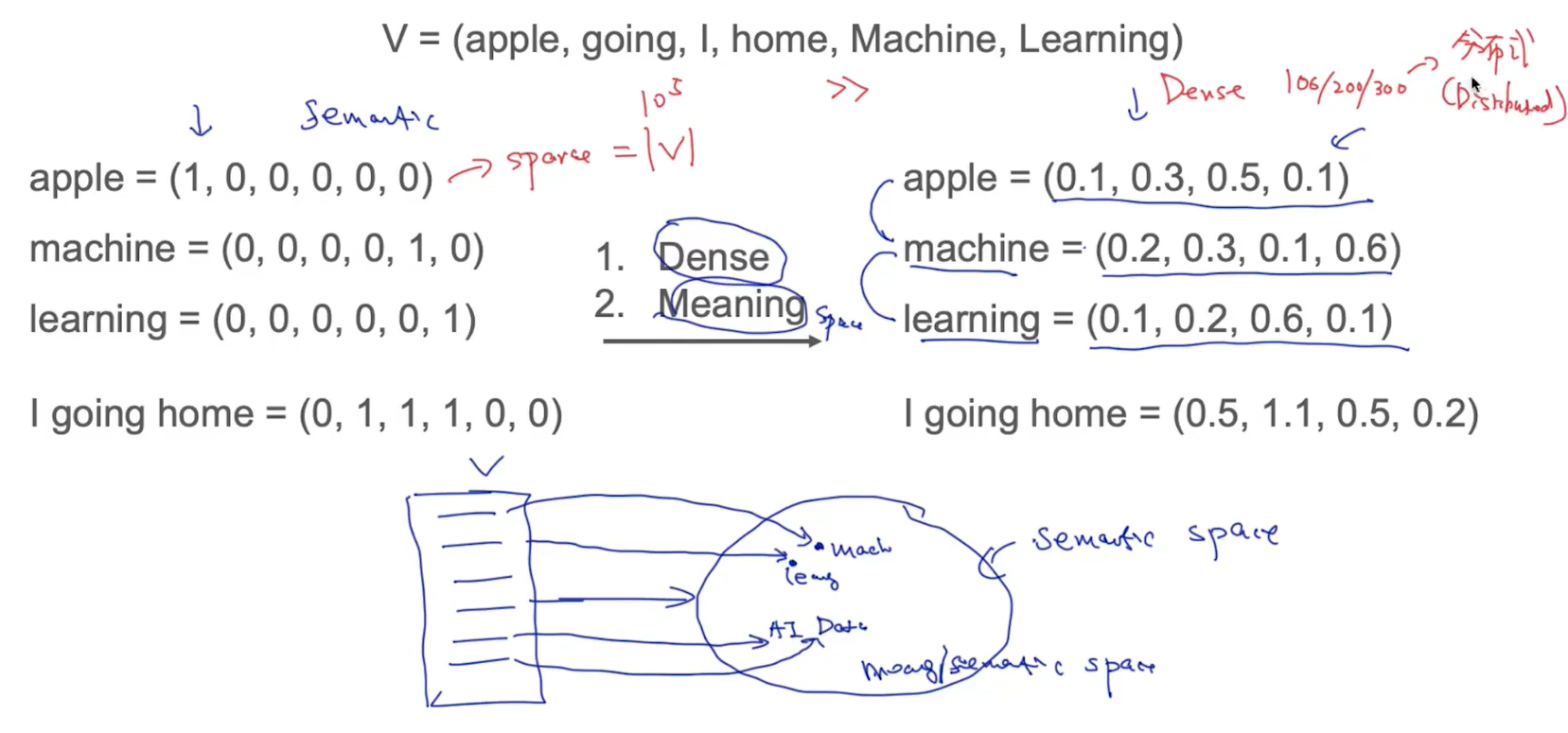
词向量:一个单词所对应的向量,向量之间的数学关系可以表示单词之间的语义关系
单词表示法:

one-hot representation:

缺点:稀疏;不能表示单词之间的联系
分布式表示方法ii:将单词映射到semantic space中
泛化generalization:不仅模型在训练数据上表现好,测试数据上也好;局部泛化容易造成过拟合,全局泛化不会
下面2个模型都是基于:一句话中,单词离得越近则相似度越大的原理
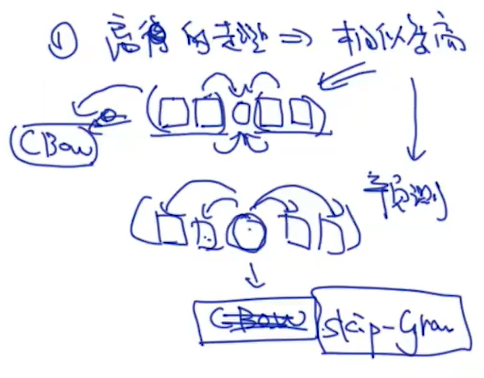
p(是 | 我):我是中心词,是是上下文,由于一个单词可能是中心词或上下文,因此一个单词对应2个词向量。
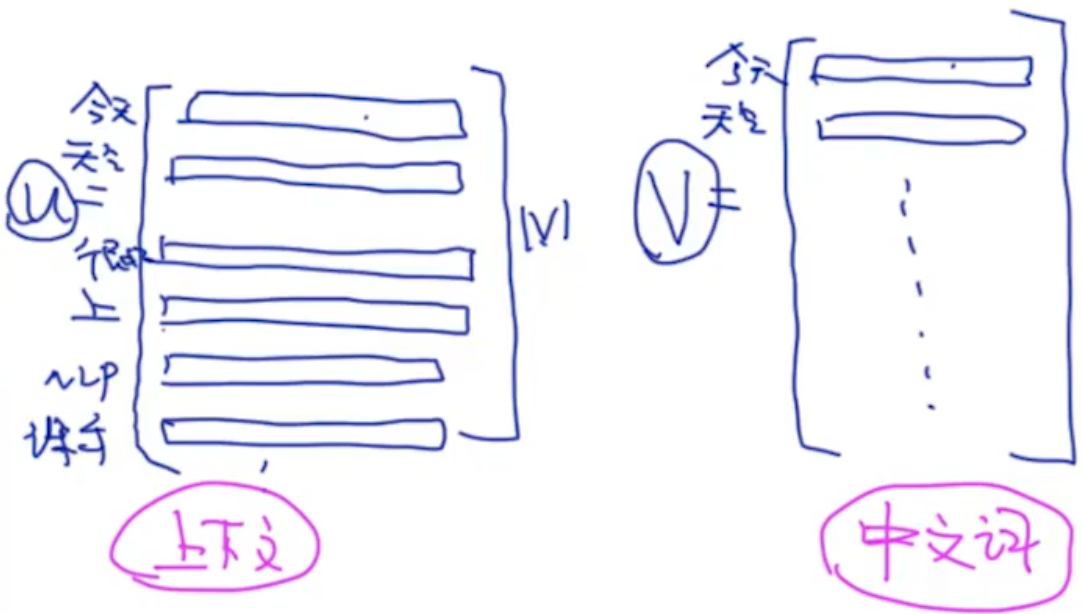
Uc:单词c在U中的词向量,C’是所有的单词

x0= argmax(f(x)):表示当函数f(x)取x=x0的时候,得到f(x)的最大值
sg目标函数:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号