



sql3
索引:

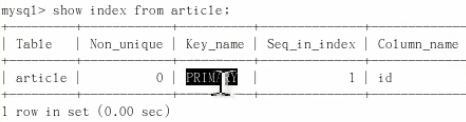
下图右边是索引
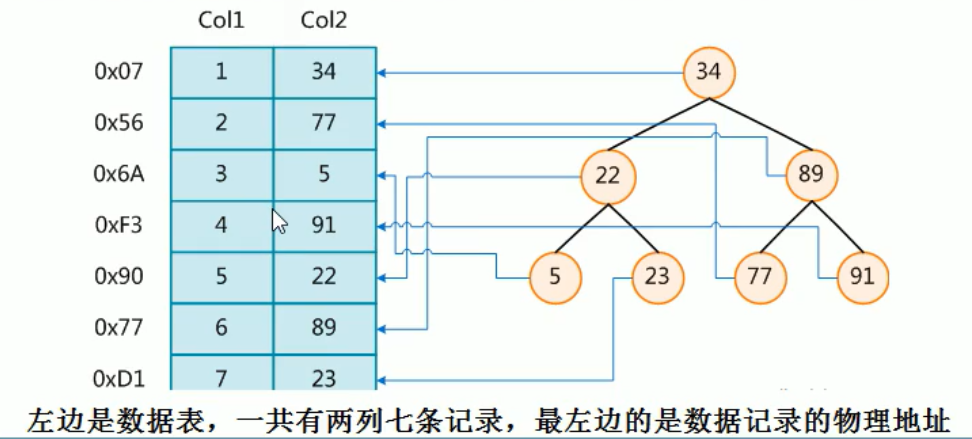
![]()

索引列:加了索引的列





复合索引优于单值索引

BTree索引就是B树查找。


索引公式:

添加索引:
主键也属于索引

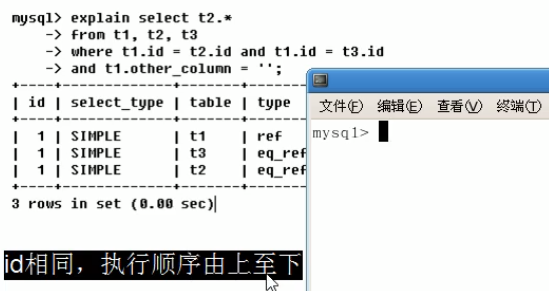
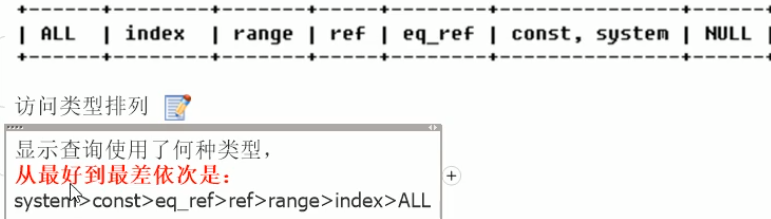
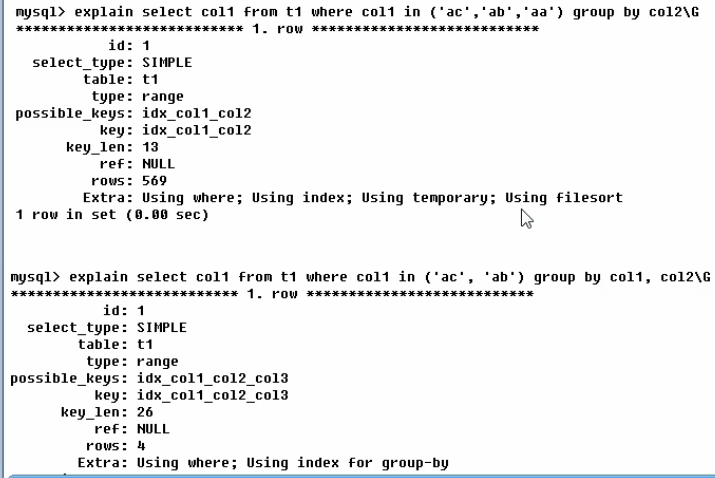
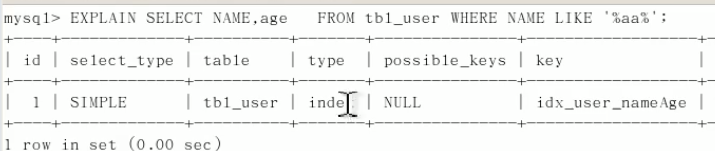
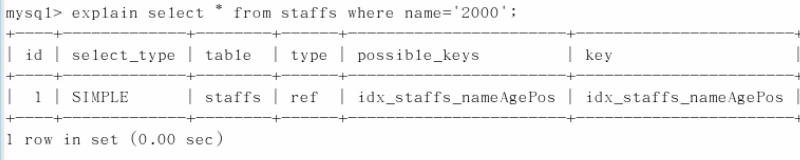
explain

![]()

结果:
![]()
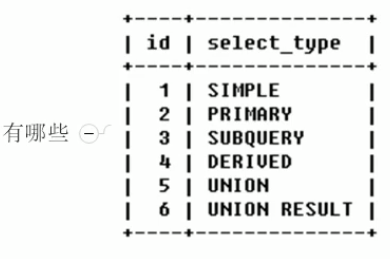
id:


select_type:查询的类型

type:
注意:
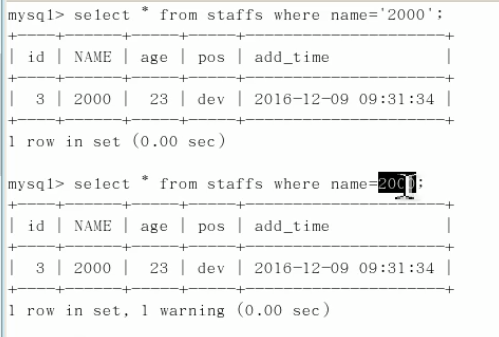
const情况,sql 如 ... where 主键/带有unique的 = 2
eq_ref:用到索引了,但是只查出1条记录
ref返回匹配某个值的所有行:... where name = "小明"
index:如select id from t。以上类型都用到了索引


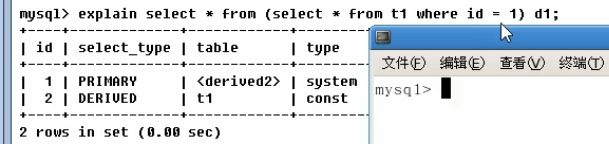
possible_keys:可能用到了哪些索引

key:是实际用到了哪些索引

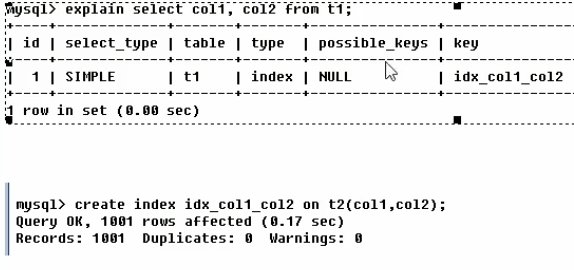
key_len:实际使用到的索引列的总长度,单位是字节,where用的索引条件越多,它越大,结果也越精确。但是希望它越短越好


ref:是一个=号后的东西

rows:


Extra:

using filesort表示mysql 没有按照我建立的索引排序,而是按照它自己排序,原因是sql的编写不是按我的索引顺序写的

比 filesort 更严重:需要中间建立临时表做个数据存储中介,最后再删掉临时表,所以使用group by时,要按照索引编写顺序来写 sql
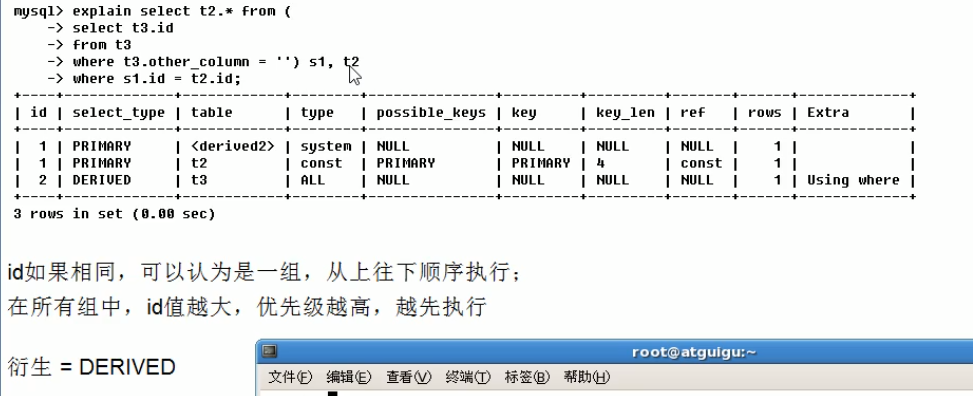
![]()
index好
索引覆盖就是建立的索引能够包含select的列
查找动作就是用了where条件,读取数据就是select而已







case:
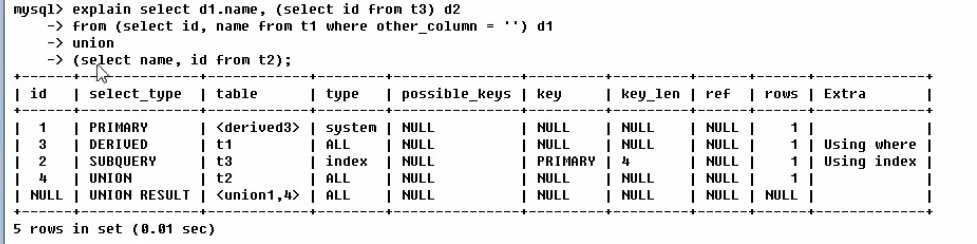
table表示查询的时候用的是哪个表,derived3的 3 是 id,union(1,4)的1,4是 id

索引分析:
单表:
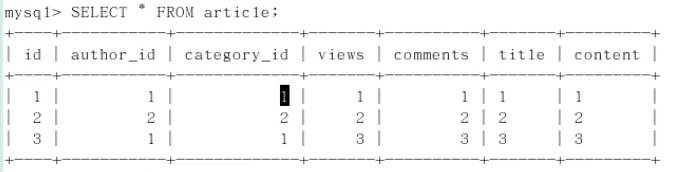

查看索引:

对where 后面的字段建立复合索引:

由于category_id使用了索引,但是到了comment>1停止了,此时mysq采用内排序,不合理,删除索引:


此时跳过范围字段建立索引,效果就很好了:

2表:

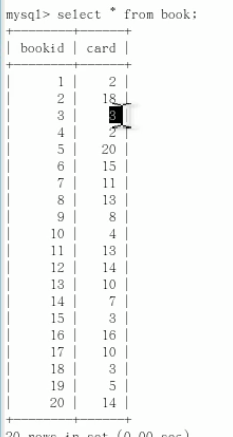



所以左连接的索引加到右表,右连接建左表。

三表:

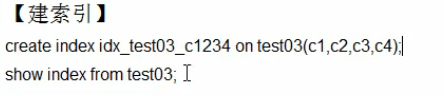
建索引:

索引优化:
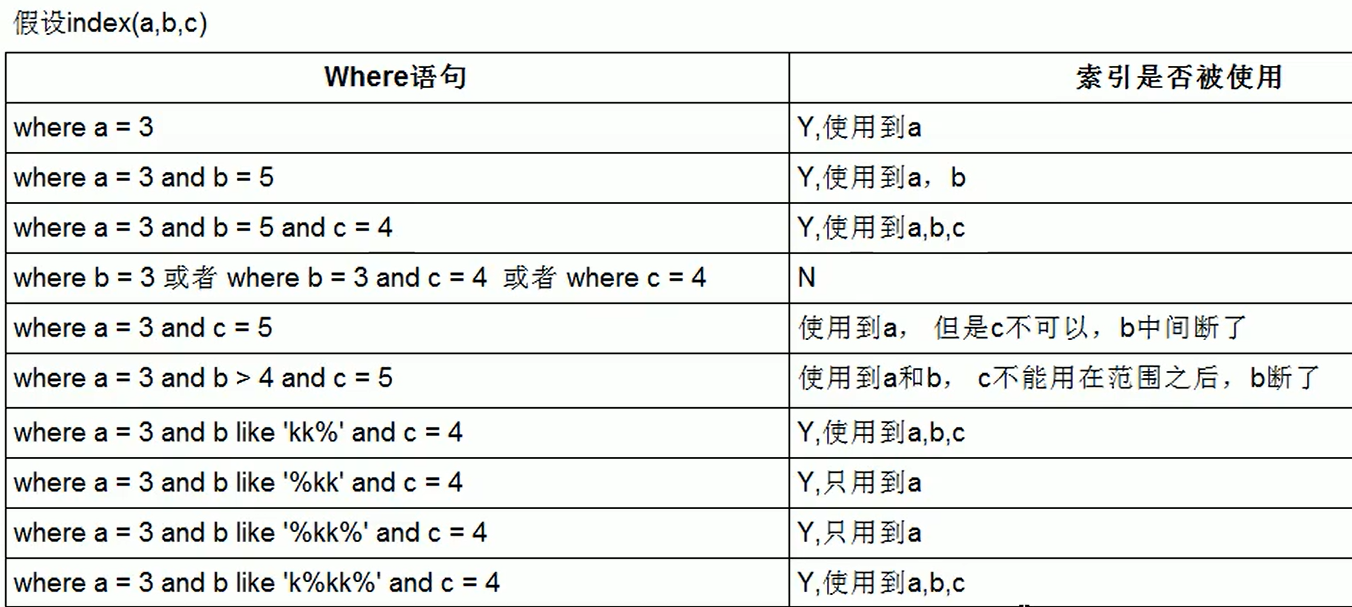
1、索引是啥,where就是啥,顺序也一致

假设建立复合索引(name,age,pos),where没有name就用不到它;where 有name但是后面跳过age直接pos,则用到了但是只对name有效

3、索引列上少计算
left("asd",2):返回asd左边开始的2个字符as,加上该函数后索引失效了,转成全表扫描了


此处name用于检索而age用于排序,age之后的pos不再用了,所以用了索引,但是只包括name和age


尽量select 索引包含的列 from





like ...%就可以了,%放左边效果索引失效


如果非要%在前面,则可以建立覆盖索引,然后select 索引的子集就可以了:




总结:
面试题:
mysql优化器会调整顺序,and顺序无所谓:


order by 和group by 写的字段的顺序最好和索引顺序一样,否则可能产生filesort
分析流程:

exist只返回0,1,且执行顺序是从外到exist内部。而in是先in里面,再到外面



小表驱动大表:

order by索引:

group by优化:

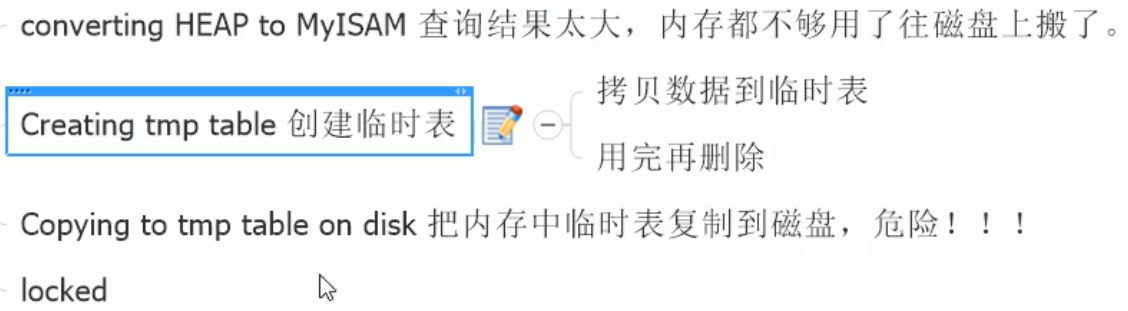
慢查询日志:运行时间超过long_query_time的sql会被记录到慢查询日志中




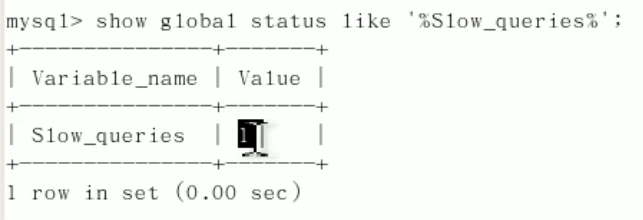
mysqldumpslow:


函数有返回值,存储过程没有返回值
show profile:

使用步骤:


然后运行几条sql
![]()

若status列出现一下,则说明不好了:
全局查询日志(不要在生产环境中开):

存储引擎:
注意系统表都用的是myisam

其他引擎等:
其中blackhole引擎就是把操作记录到日志,不会作用到表上

锁:
读锁:若session1加对A表加了读锁,则session1能读A,不能写A,不能读表B,session2能读A,B,写A的话就会阻塞,除非session1释放了A表。session1释放A表后,就能干别的事了
写锁:若session1加对A表加了写锁,可读写A,但不能操作其他表,session2要读写A时,会被阻塞(如果能查到,可能是从缓存查到的,此时可以加个where id)

表锁:锁住表,别的session就不能访问
![]()
建表:

看看锁,第三列in_use为0是没有锁:
show open tables
给mylock表上读锁,book上写锁:
lock table mylock read,book write;
解锁:unlock tables
![]()
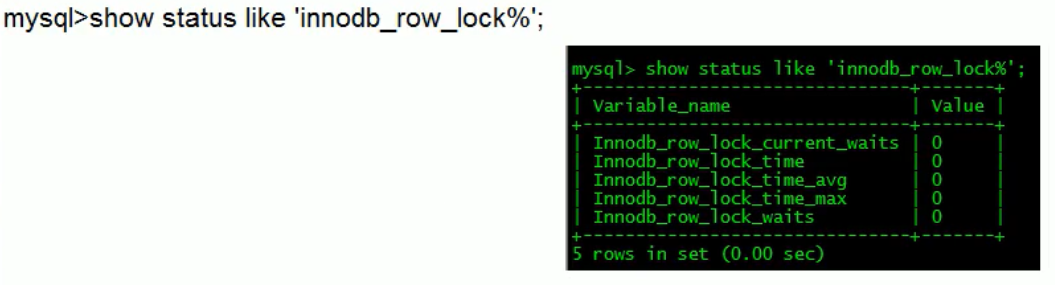
分析锁:
高可用:系统不瘫痪
行锁:锁住某一行
session1设置set autocommit=0后,如果改动了表,还手动需要commit,session2如果也set了,那么session2自己需要commit后才能看到session1改动的表,如果它没有set...,就能直接看得到
当sql写错导致索引失效时,行锁有可能变成表锁
间隙:在sql的检索范围内,但是并不存在的记录,比如下图 id=2,innodb会对该间隙加锁,即间隙锁,下图直接锁了id从(1,6)内的,=2的记录要插入必须先阻塞等待session1的commit

锁住一行:

分析行锁定:

优化建议:


