Hadoop入门
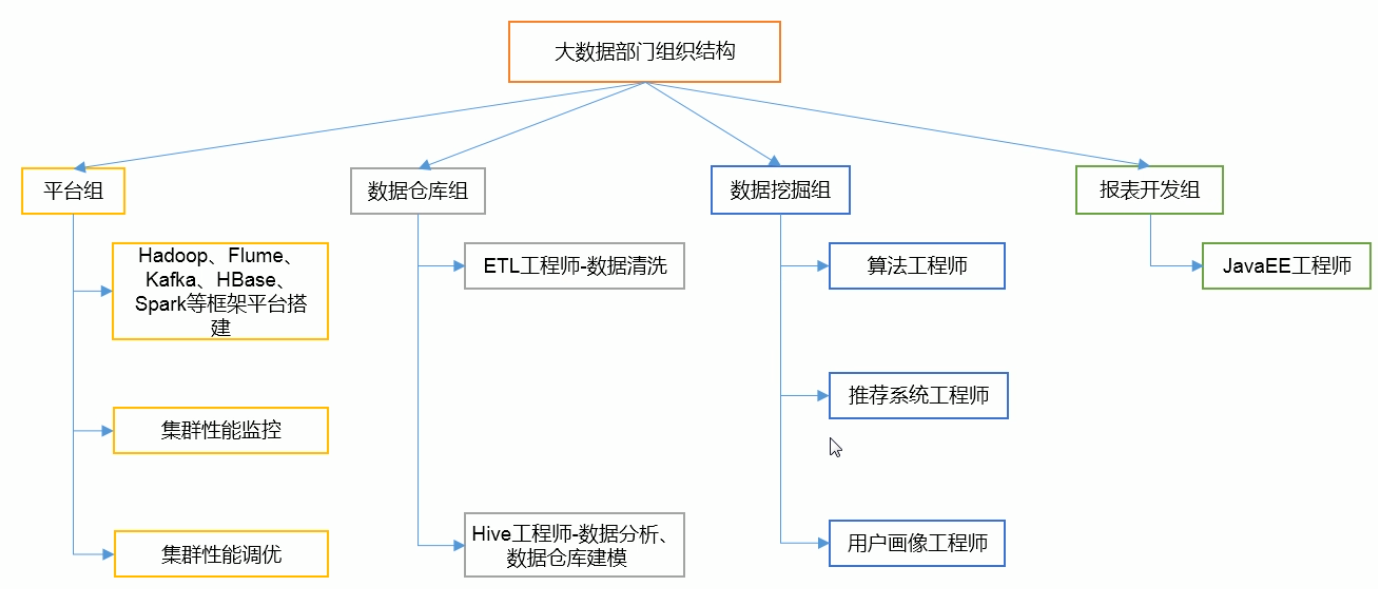
0.大数据组织
0.jdk,jvm,jre
jdk包括jre,jre=jvm+lib(类库)。运行Java时:去它的环境变量的path里面所列出的路径里面找到jre,然后运行java。因此安装了jdk后,要更改path,告诉电脑jre在这儿。
1.jps
显示java的进程。由jdk规定
1.大数据生态圈
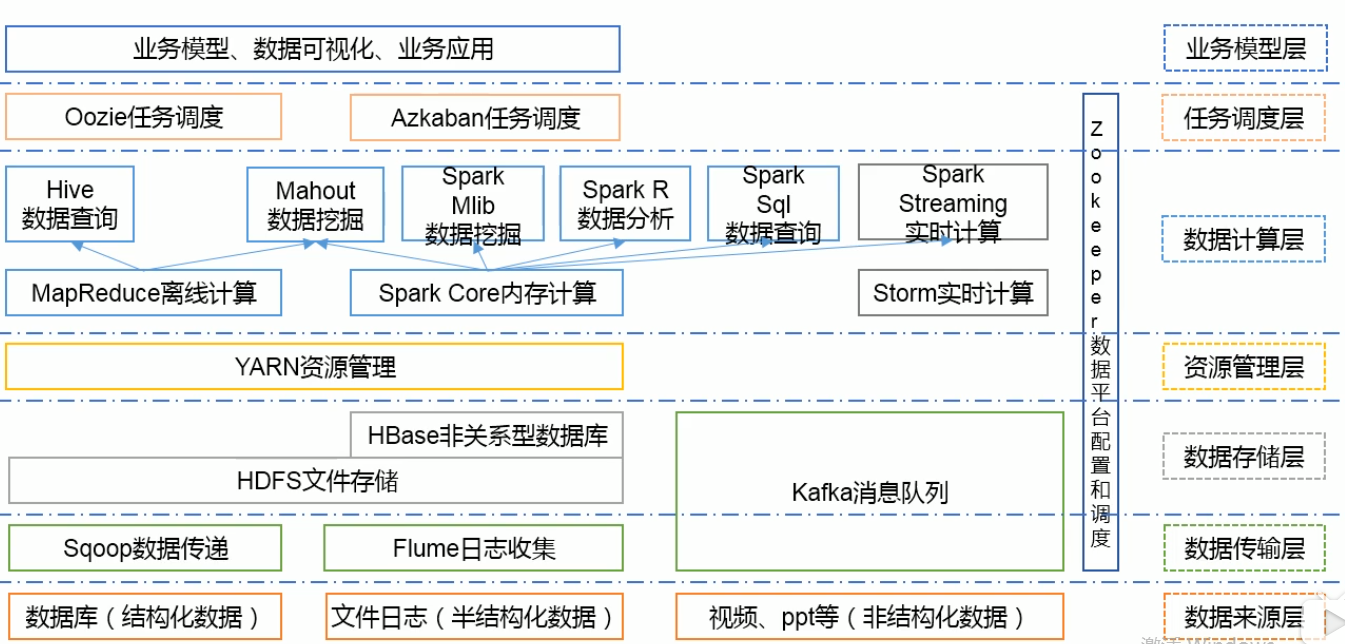
1.ssh
认证:
①基于口令的认证
只要知道对方的账号和口令就OK
②基于密钥的安全认证
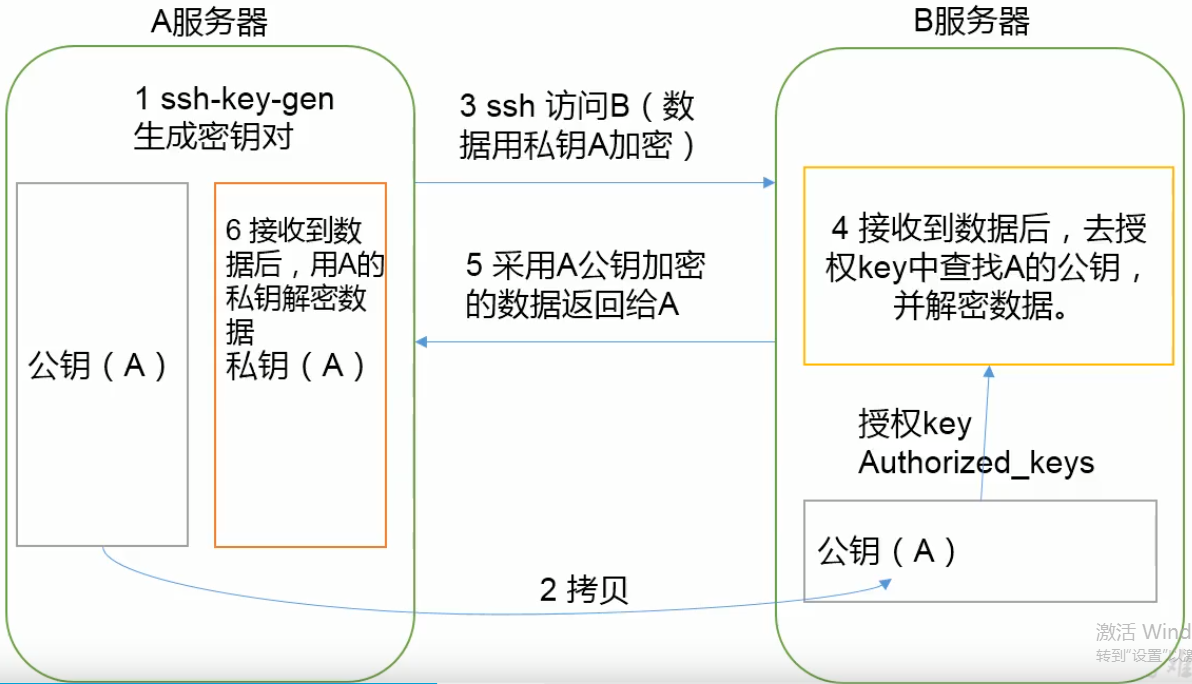
说明:authorized_key里面的内容就是id_rsa.pub
步骤:
在02上,cd ~/.ssh

之后就可以直接ssh了。
注意:私钥和公钥信息默认放到~/.ssh目录中。免密只是对单个用户而言例如qweewq,登录过去也是qweeqw,此处和对方都是同一个用户。而对于root还得单独配置。上图是atguigu配置了免密,则只对atguigu有效。
ssh root@node02:以root身份登录到node02上。如果不加root@,则默认当前发出ssh命令的用户。
zzz
2.rsync

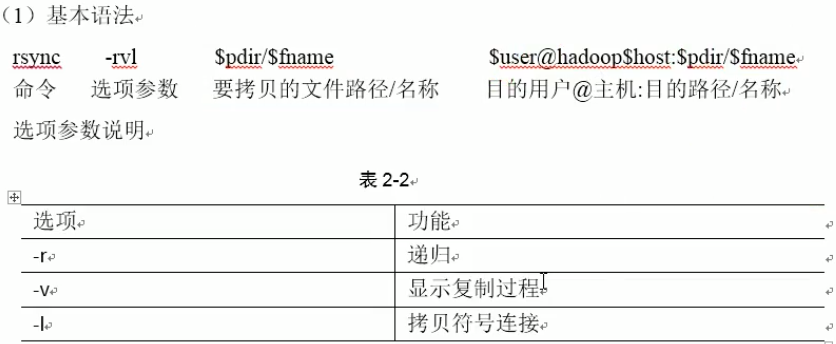

2.脚本xsync配置其他结点
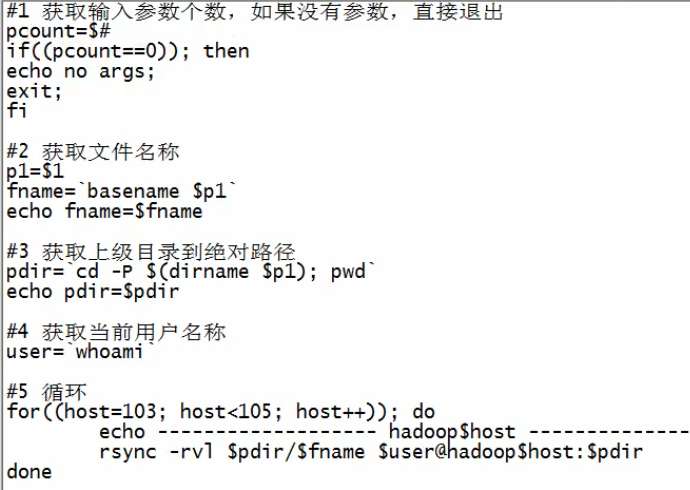
说明:注意是``不是‘’。第二段是只要文件名,不要文件前面的路径。basename只取文件名。dirname 绝对路径:返回上一级目录的绝对路径。本脚本的作用:将传入的文件名所指向的文件传到别的其他主机上的对应目录中。
2.小需求

注意:文件服务器上建立启动脚本(启动任务)和安装脚本(负责下载安装包并安装配置),启动脚本将安装脚本下发到各个节点中,然后各个节点执行安装脚本(服务器利用ssh命令一登录过去之后,执行安装脚本)
scp:


将hello.sh放到另一台机器(hadoop0002上的当前目录下),以root登录。
用expect来自动登录到另一台机器上:
先安装expect:
yum lis | grep expect
yum -y install expect.x86_64
再vi a.sh:
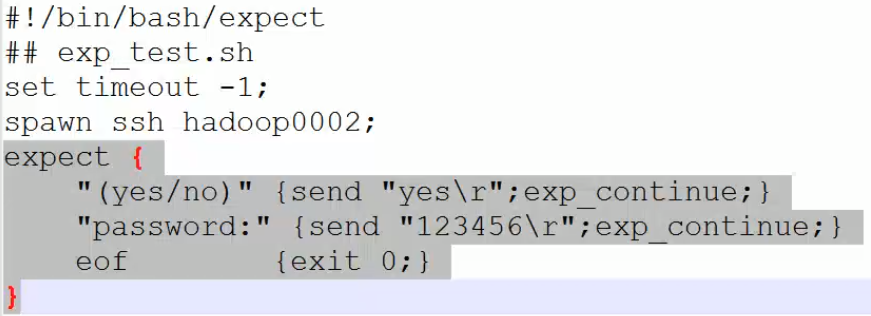
说明:timeout超时设置为-1表示不等待了,执行完上一条直接到下一条了。如果设置为10,表示等待10s,10s之后认为是超时,则执行下一条命令。spawn监控。expect里面第一行,如果监控到有yes/no的字样,则进行后面的动作,发送yes\r,并继续监控。第二次如果有password。如果没了,就退出。
再expect -f(文件) a.sh
内网放jdk:
在web主目录新建目录,并把jdk包放入:

最终解决:

说明:BASE_SERVERE是node01的IP,上面的函数是针对单个主机,下面的函数调用上面的函数对所有主机(node02,node03)进行


说明:大致步骤:首先实现免密登录(后期登录不用输入密码和不再显示提示),再对第一个对象:先拷贝install.sh脚本,再登过去执行,再对第二个对象。。。。

说明:BASE_SEVERE是node01的ip,wget从node01上搭建的web服务器上下载jdk。最后在/etc/profile中追加两行变量的设置。
接着:
chmod u+x install.h
sh boot.sh:不加权限,用sh直接执行boot.sh
注意:ssh客户端有scp。如果小鸡上没有安装scp,说明它也没有安装ssh客户端,需要给它安装上
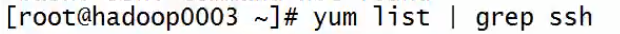
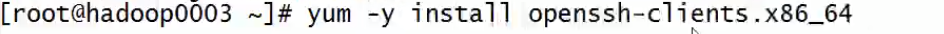
改进:

④、目标机器名要写死在脚本中
说明:
①.可将免密配置放到install里面;
②.重定向

其中1表示标准输出,2表示错误输出
④.

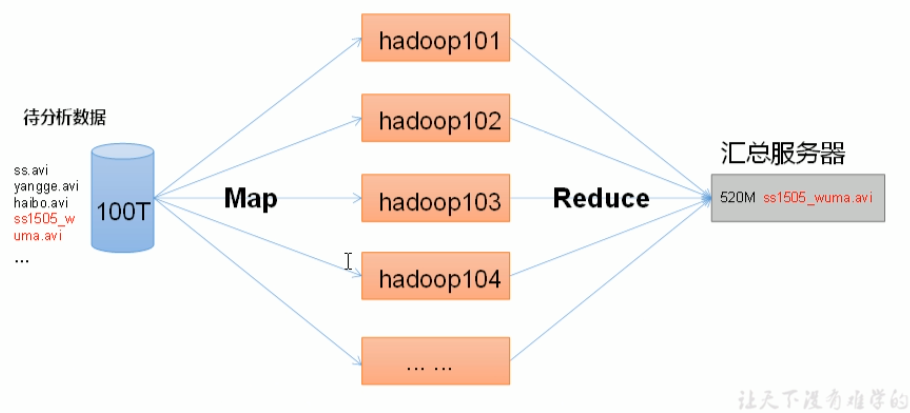
3.hadoop简介




YARN由ResourceManager(RM,管理整个资源),NodeManager(NM,管理单个结点),ApplicationMaster(AM),Container组成
3.删除
hdfs dfs -rm -r /a
4.hadoop安装

前2种是安装在单节点上,第三种安装在多个结点上
5.本地模式:
①传入hadoop压缩包并解压

进入/usr/local修改小错误:

②编辑配置文件
vi /etc/profile
追加:

说明:sbin是针对系统管理员的
source /etc/profile
③更改hadoop的运行环境
vi /usr/local/hadoop2.7.1/etc/hadoop/hadoop_env.sh

④查看安装
hadoop version
⑤实现grep案例(在hadoop-2.9.2目录下操作)

说明:第三行中,input表示从input目录中读取数据,output表示将结果显示到output目录,注意output应该是当下没有创建过的。总之,从一堆jar包中(2.7.2.jar)的名为grep的jar包拿过来,给它传入参数input,读入input里面的所有文件的内容,寻找包含按照正则表达式所指示的东西有几个。并将执行结果放到output目录中。结果中:3 hi表示包含hi的单词有3个。
⑥实现Wordcount案例
统计每个单词出现的次数
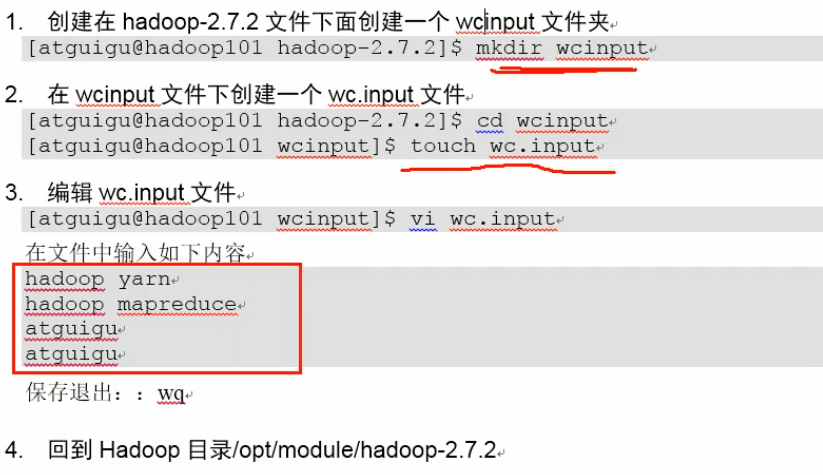

6. 伪分布式模式:
在上面的基础上修改一下配置文件:
①
hadoop-2.9.2/etc/hadoop/:这里都是配置文件
vi core-site.xml
在<configuration></configuration>中间写入:

说明:hadoop101是一个主机名。/
②

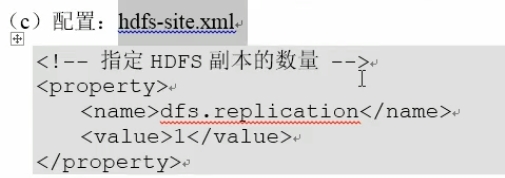
说明:还是写入<configuration>里面。始终保证有n个副本,每个副本有备份。

③检测访问
此时开辟了一个类似于Linux根目录的本地文件目录,它称为hdfs的根目录,浏览器输入:http://192.168.10.11:50070可访问
或者试着创建目录和查看:
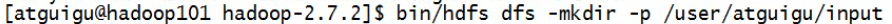
说明:这里创建目录用绝对路径才行。命令中的前面2个是固定写法

注意:namenode和datanode的log信息在hadoop-2.9.2/logs下,通过这个分析错误。info是对的,主要看里面的warn。格式化之前要删掉hadoop-2.9.2下的data和logs。在/opt/module/hadoop-2.9.2中,namenode和datanode的clusterID必须一致:

说明:每次格式化namenode后,会生成新的/opt/mode/.....name/..../VERSION,它会和..../data/..../VERSION不一致。此时重新安装,使用初始的。
上传:

说明:将本地的wcinput/wc.input文件上传到hdfs的/user/atguigu/input
对hdfs上的文件执行wordcount:
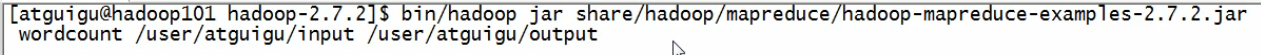
浏览器查看或者:
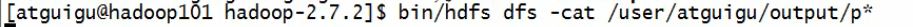
③再次开机时,需要启动namenode和datanode:
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
4.启动yarn,运行MapReduce

说明:在hadoop-2.9.2/etc/hadoop下。要把该行的#去掉。
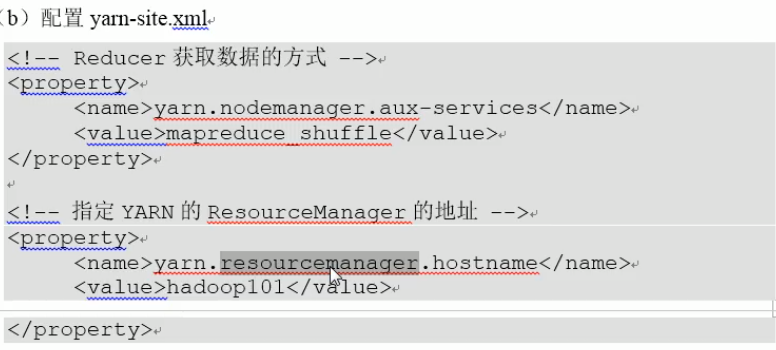
说明:写到configuration中。第二段的意思是将RM放到hadoop101这个服务器上。


说明:MR是MapReduce

sbin/yarn-daemon start nodemanager
测试:
浏览器访问:http://node01:8088,这是查看mapreduce进程的端口。
运行一个MR程序:

显示:
说明:ID是作业的ID,程序名称:wordcount
6.配置历史服务器
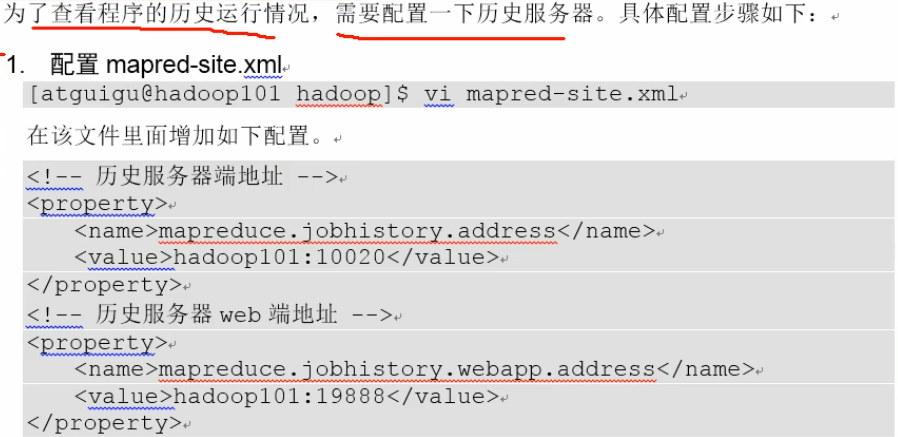
启动历史服务器:

说明:启动命令都在sbin下

可以点了:
说明:上面是内部的地址,下面是对外的地址。
7.日志聚集
将hadoop-2.9.2/logs下的logs显示到yarn上

步骤:
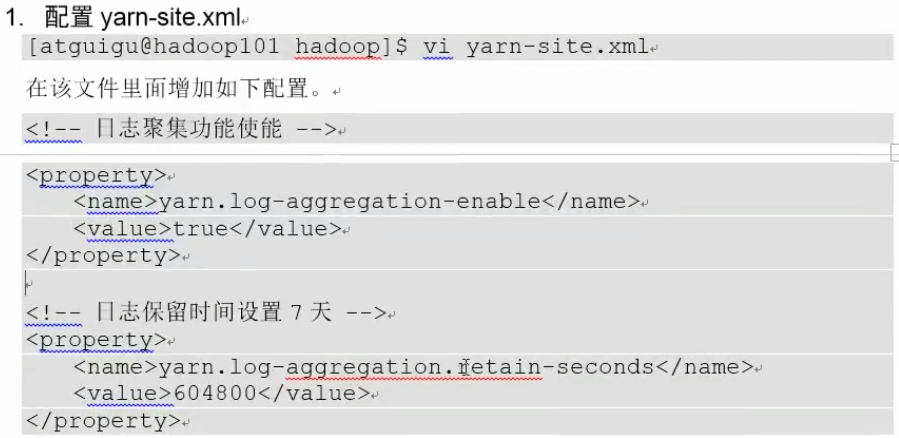
说明:604800是以秒为单位的
测试:

说明:此时2个参数所针对的目录都是hfds上的。
点击logs:
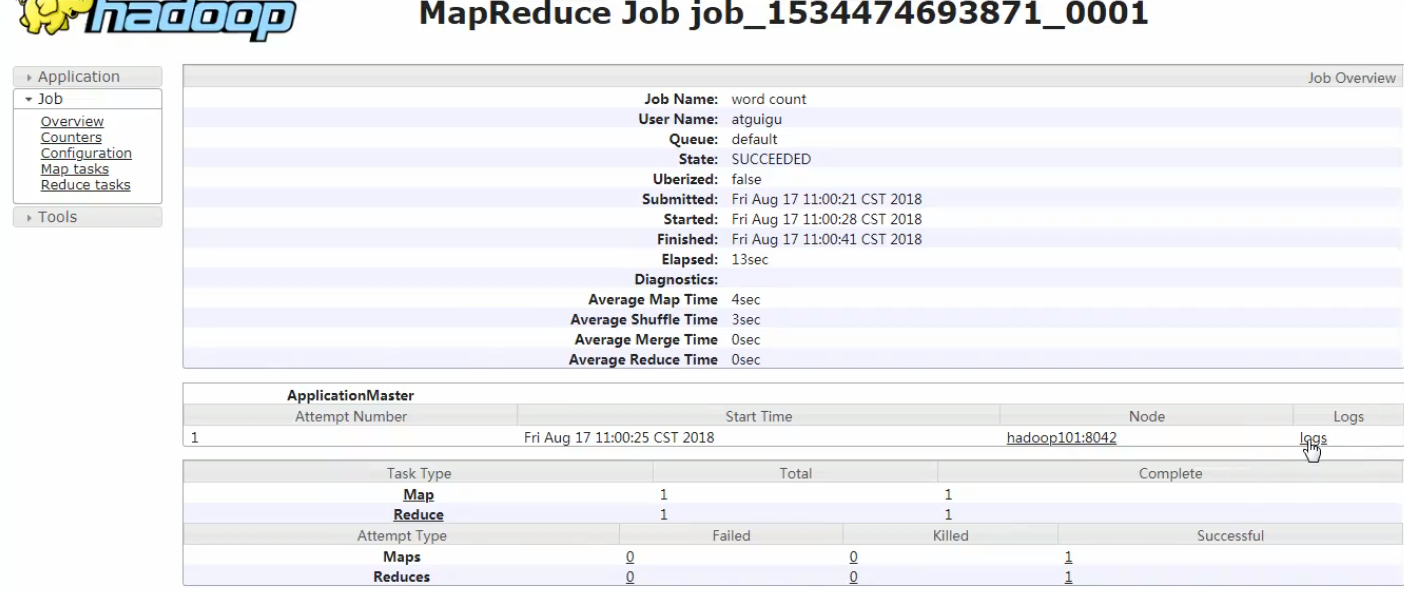
7.完全分布式模式(从零搭建):
思路:

步骤:
在node02上按博客Linux安装好jdk,再进行本地模式的①②③④步骤来安装好Hadoop。
(
建立node03,node04
利用scp -r(-r:递归)将hadoop-2.9.2和jdk1.8.0_144从node01拷贝到其他机器,再将/etc/profile拷贝到别的机器上:
示例(在B机器上把A的东西拷贝到C上):

再在每台机器上上source /etc/profile
,我的做法是先把node02配置好,然后node03,node04用链接克隆方式,如果没有实现免密,则实现以下免密即可
)
集群配置目标:

在node02上配置:
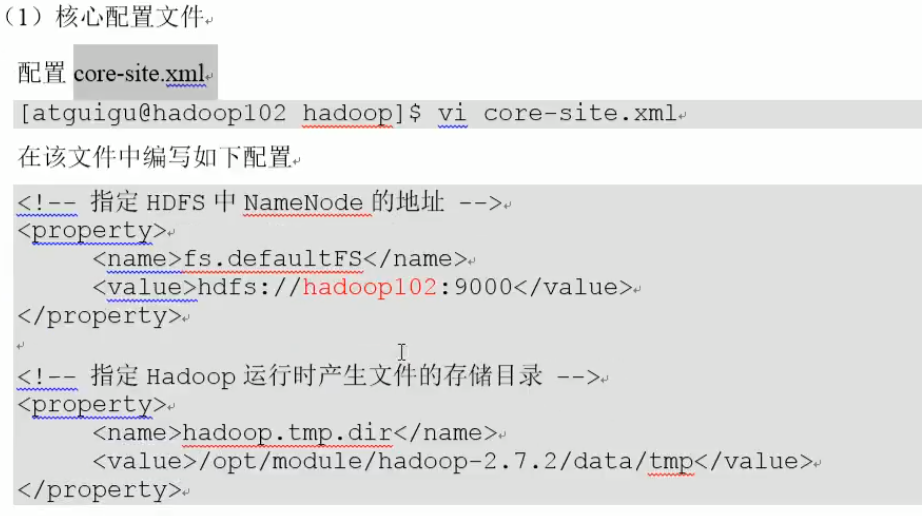
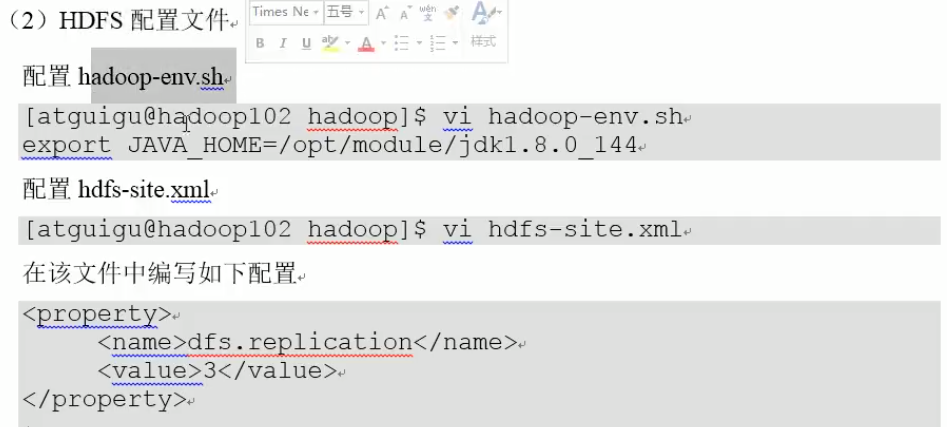

说明: 默认是3,就可以不写了
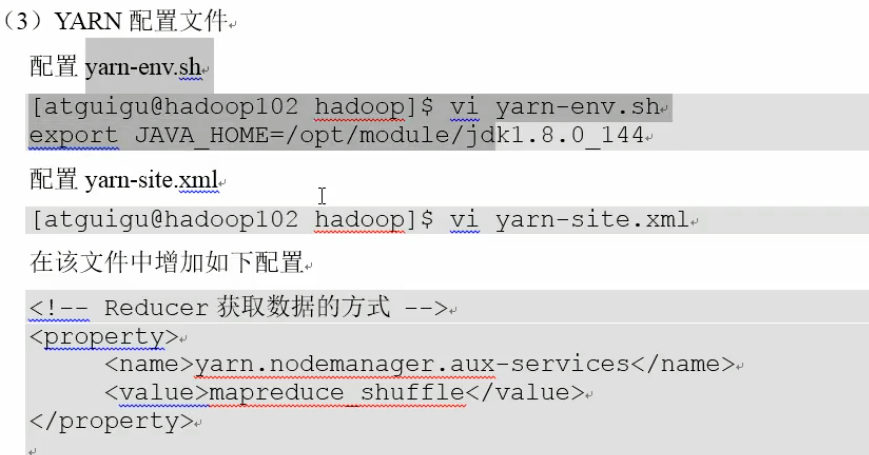

说明:对于yarn-site.xml,还可以增加日志聚集功能(见伪分布式)


说明:对于mapred-site.xml而言,还可以配置历史服务器(见伪分布式)
(

)
我用的是虚拟机新建链接克隆node03,noe04
集群单节点启动:
对node02,03,04都停掉进程,删除目录:

node02上重新格式化:
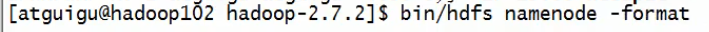
由于node02有namenode,则让node02免密登录到02,03,04
由于node03有resourcemanager,则让node03免密登录到02,03,04
群起集群:
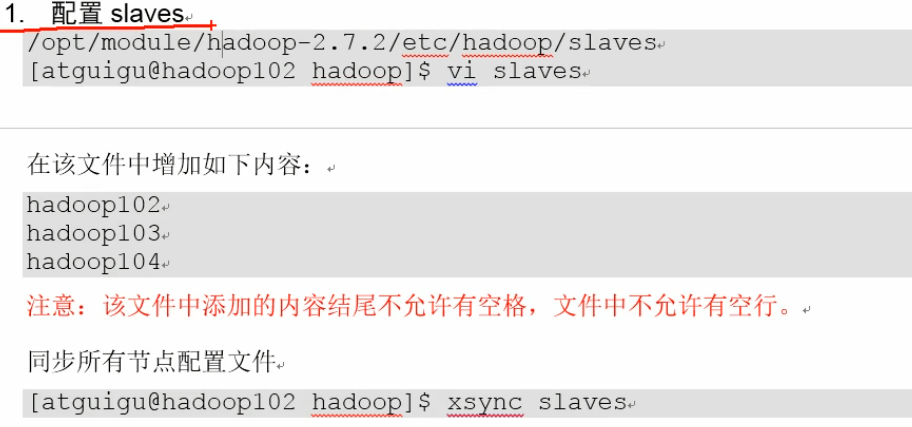
说明:start-dfs.sh启动datanode就是参照slaves的。清空slaves原有的,同时写的时候不要有多余的空格和空行。我同步使用的scp拷过去的
集群停止和启动的方法:


此时启动hdfs上的所有结点,然后必须且只能在配置有resourcemanager上的103上,启动yarn上的所有manager(对于yarn来说,start和stop都必须在node03上做,因为resourcemanager在node03上。)
jps对比是否和集群部署一致。
测试:
再到http://node02:50070,
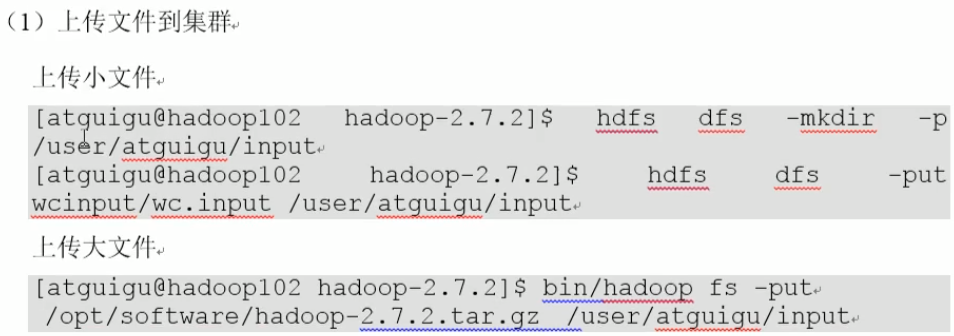
说明:哪种put都可以,都是从本地上传到hdfs
over!
8.集群时间同步

说明:这三个必须得有才行
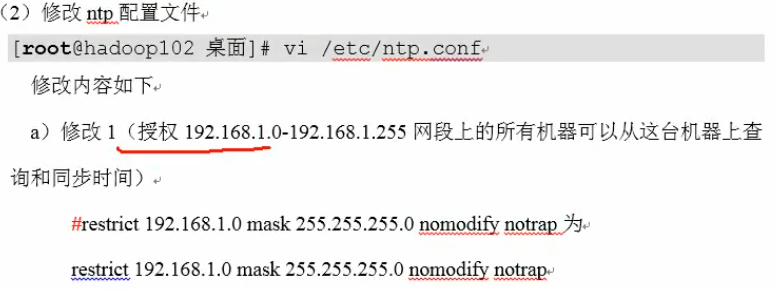
说明:我的是192.168.10.0


说明:都在同一个配置文件里改的


说明:必须用root启动它

说明:这个可选

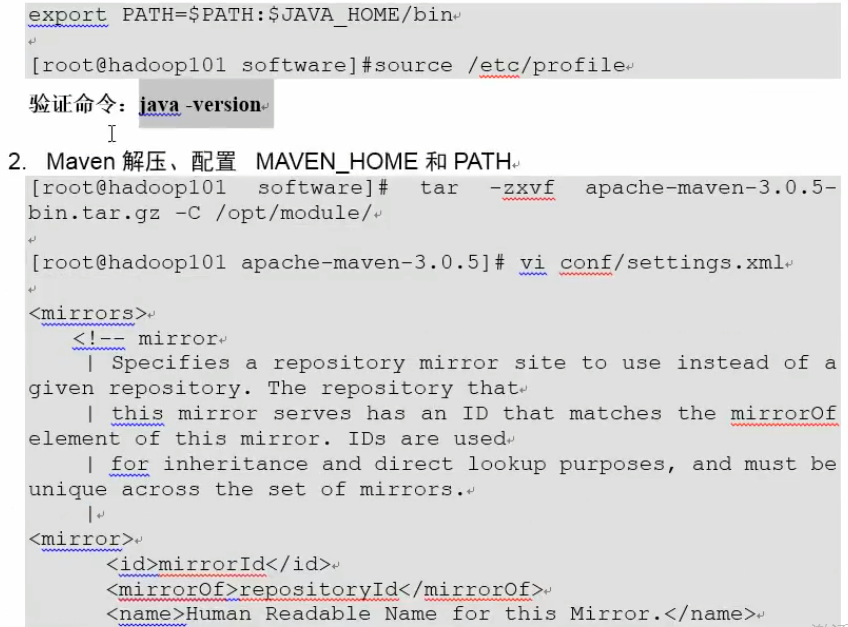
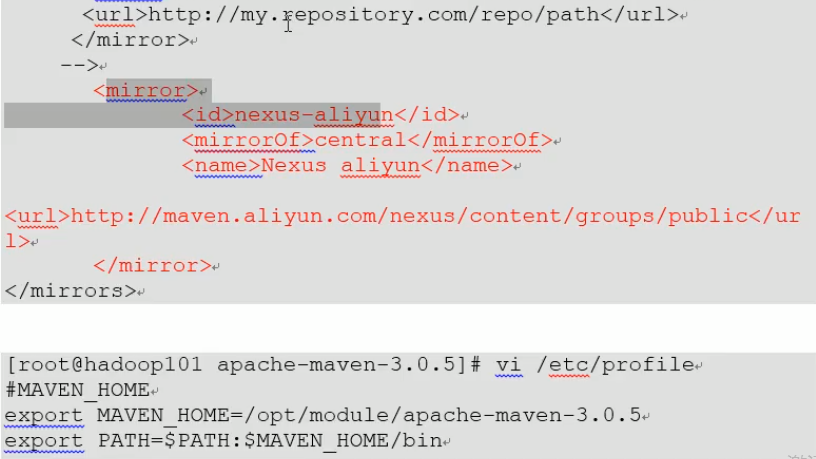
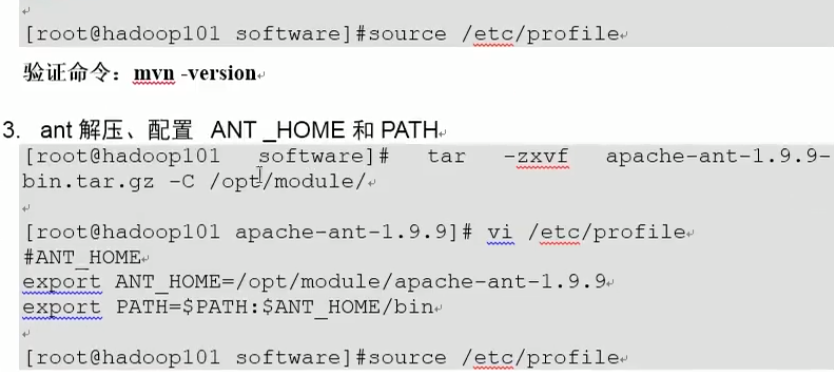
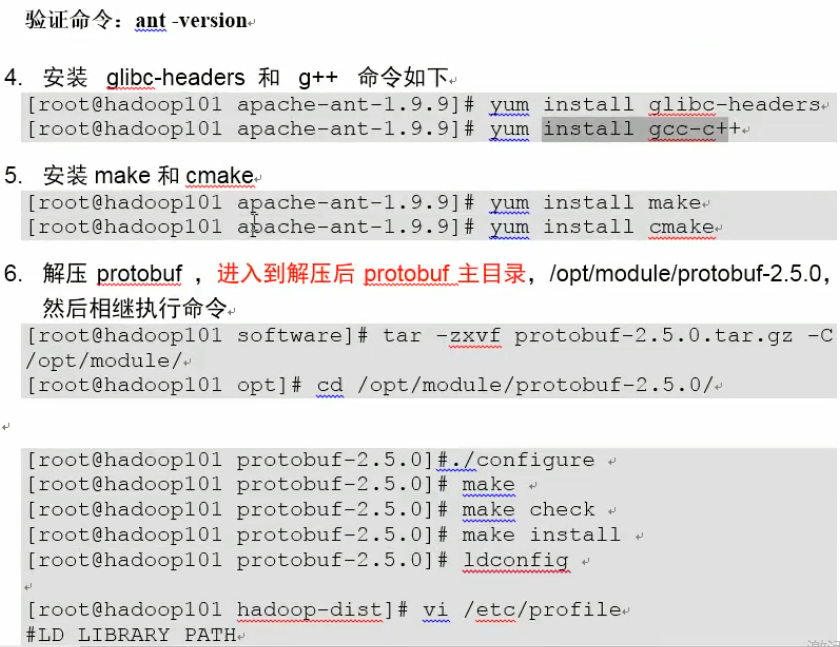
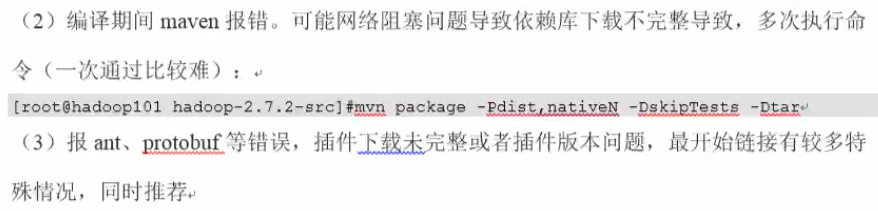
10.Hadoop源码编译