
hdfs
1.性质:
hdfs是一个分布式文件系统,是一个集群,集群里面有很多不同的结点,结点上运行不同的角色(进程)。
伪分布式:在一台机器上启动所有的进程。
存储模型以字节为最小单位。
文件线性切割成块。如果每一块有4个B数据,那么第1块的偏移量是0,第二块的偏移量是4。。。。。
将大文件分割为块后,block分散存储在集群结点中。
同一个文件内block大小一致,不同文件的block可以不同。
block可以设置副本数(备份),各个地位是平等的。副本分散存储在不同结点中。
不能修改文件,但是可以使用append追加数据。
2.架构:


注意:客户端先访问namenode,再去直接访问datanode
3。namenode
namenode基于内存存储,不会和磁盘发生交换。磁盘只负责保存某个时刻的状态(持久化)。

说明:当namenode拍快照不保存文件的位置信息,只有当重新加载快照时,才会根据心跳机制与datanode进行沟通,才会补上位置信息。
4.持久化的名字

5。datanode

说明:DN保存block元数据,NN保存文件元数据。block元数据会包含md5,md5算法可以将一个文件映射成一个字符串,如果外界要取这个块,外界给出一个md5,然后再看看元数据里面的md5是不是一样的,就表明外界拿对了数据了。
6.fsimage和edis搭建过程
edis是放在磁盘上的。刚开始搭建集群时格式化,此时产生一个空的fsimage,namenode启动后加载fsimage到内存,同时执行edis,不过这个edis也是空的。随后根据内存的东西再创建一个空的fsimage写到磁盘,和空的edis。随着运行的继续,edis开始增加内容。当下一次namenode开机时,加载fsimage和edis,这样就能还原开机的时候的状态了。这样就会使得:如果用了十年的机器,十年后突然挂了,此时的fsimage却是十年前的状态,回复起来会很慢,而SNN就可以隔一段时间将两者结合更新一下:

7.block放置策略,下图右边有2个机架,第一个副本放到第一个机架的一台服务器,第二个副本放到另外一个机架的一个点,第三个。。。。。

8.写流程
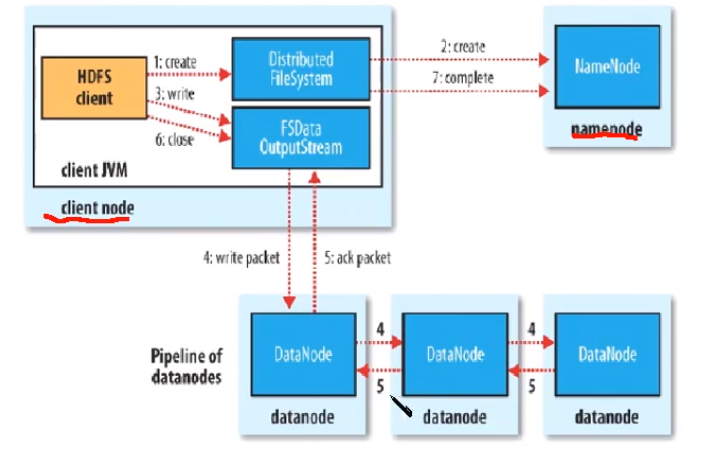
上图中,客户端先和namenode联系,例如客户端上传文件,在namenode进城的虚拟目录树中创建一个文件名,随后namenode返回客户端三个节点顺序。接着客户端和第一个dn建立socket链接,第一个dn和第二个dn建立socket链接,第二个和第三个.....。然后客户端按照分组交换方式,将一个个大文件的小块再细分成很多小组,向第一个dn传大文件中的一个块的一个小分组,再传这个块的第二个分组,同时当第一个dn收到分组时,就会向第二个dn发送出去,如此往复地进行传送。最后dn用心跳机制向nn汇报。
9.读流程
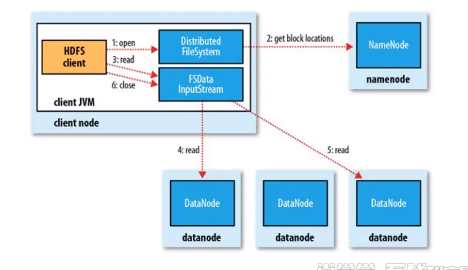
客户端向nn请求文件的各个块的元数据,由于每个块都有相似的副本,nn会根据一个块的众多副本到客户端的距离优先原则进行排序,把副本的序列发给客户端,客户端选第一个就好了。此时客户端可以任意选择大文件中的哪几块进行读取。
10。文件权限

11。安全模式

12.伪分布式环境搭建
①查看映射和hostname是否正确:
cat /etc/hosts;hostname;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号