
知识点
1。 人工智能包括机器学习,机器学习包括深度学习。机器学习一共有三个分支,有监督学习、无监督学习(比如聚类)和强化学习(半监督学习)。强化学习是系统从环境学习以使得奖励最大的机器学习。强化学习和有监督学习的不同在于教师信号。强化学习的教师信号是动作的奖励,有监督学习的教师信号是正确的动作。
2。分类:目标概念为已知类别;回归:目标概念为连续值
3。监督学习:样本有目标概念,样本有标签标定,需要训练集和测试集。无监督学习的样本没有标签。
4。监督学习包括分类(包括:KNN,DT,SVM,NN,NB)和回归(LR,NLR)
非监督学习包括:K-Means
5。前一层神经元的值,权重,加权求和之后,再+自己的偏置值,再通过激励函数,最终为该神经元的结点的值
6。输入层神经元接受的值是:一个样本的特征值。输出层输出的神经元的值:该神经元的目标集
7.Sigmoid函数可以映射到0-1区间
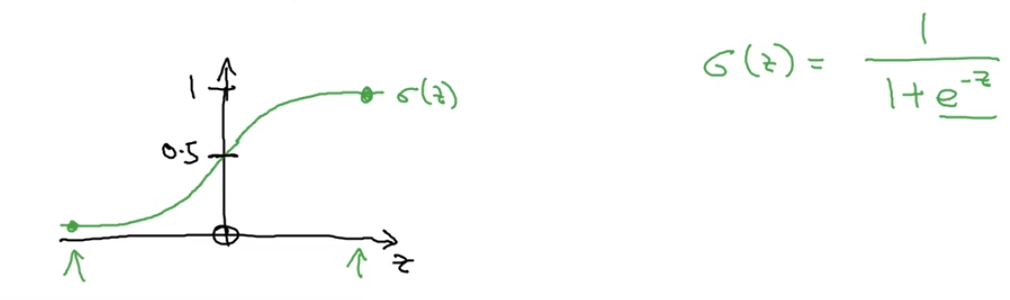
满足公式:
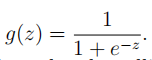
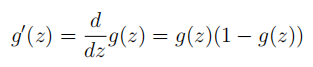
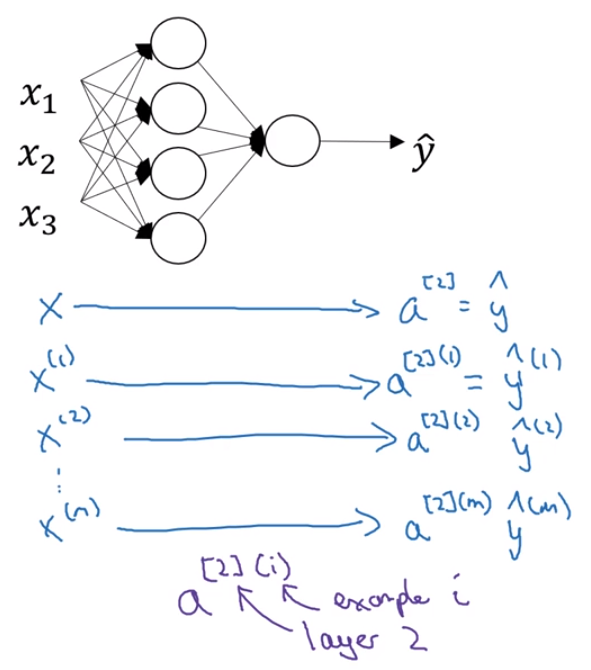
10。神经网络输入层算第0层,见下图的符号标注,右上角表示第几层。
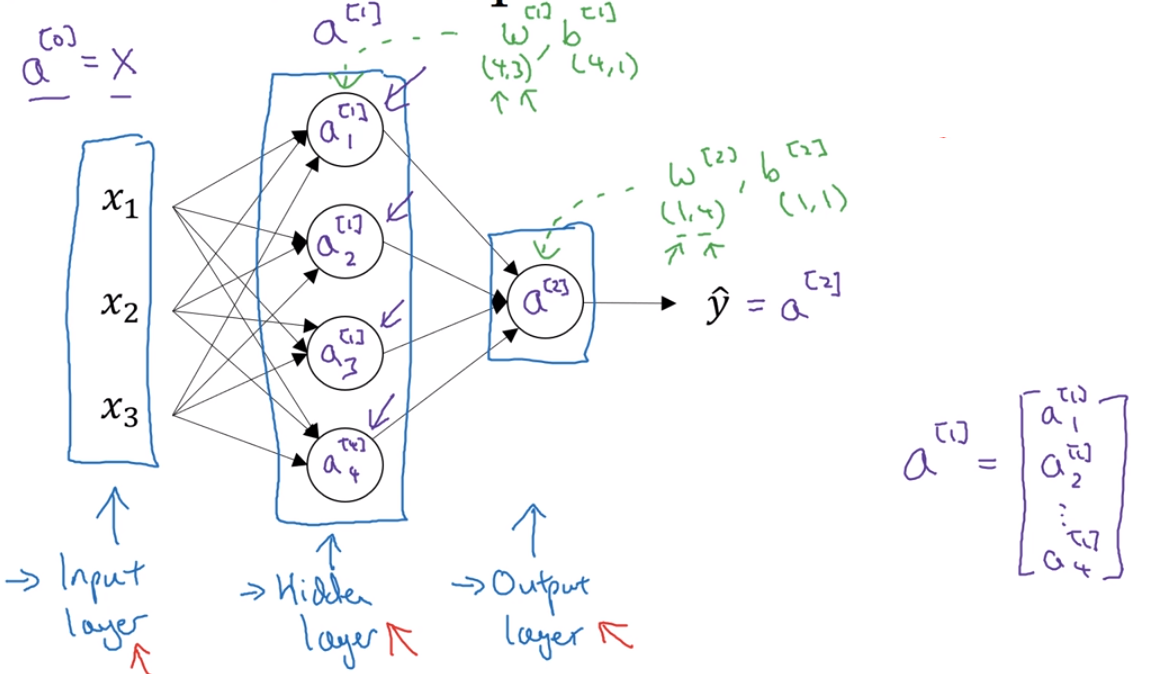
11。下图,右上角的第1个数字表示第几层。右上角的第2个数字表示:在对第几个样本计算。
12。激活函数应该是非线性的,否则就不需要隐藏层了,就成了logistics回归了。这个可以用sigmoid函数(二分分类时,输出层常用),也可以用tanh函数(映射到-1到1之间),也可以reLu函数(<0置0,>=0不变,这是最常用的)
13。BP总体步骤:先前向传播,计算出所有的结点值,再反向传播,计算出所有代价函数对参数的偏导数值,再利用这些导数值更新参数(可以用梯度下降)
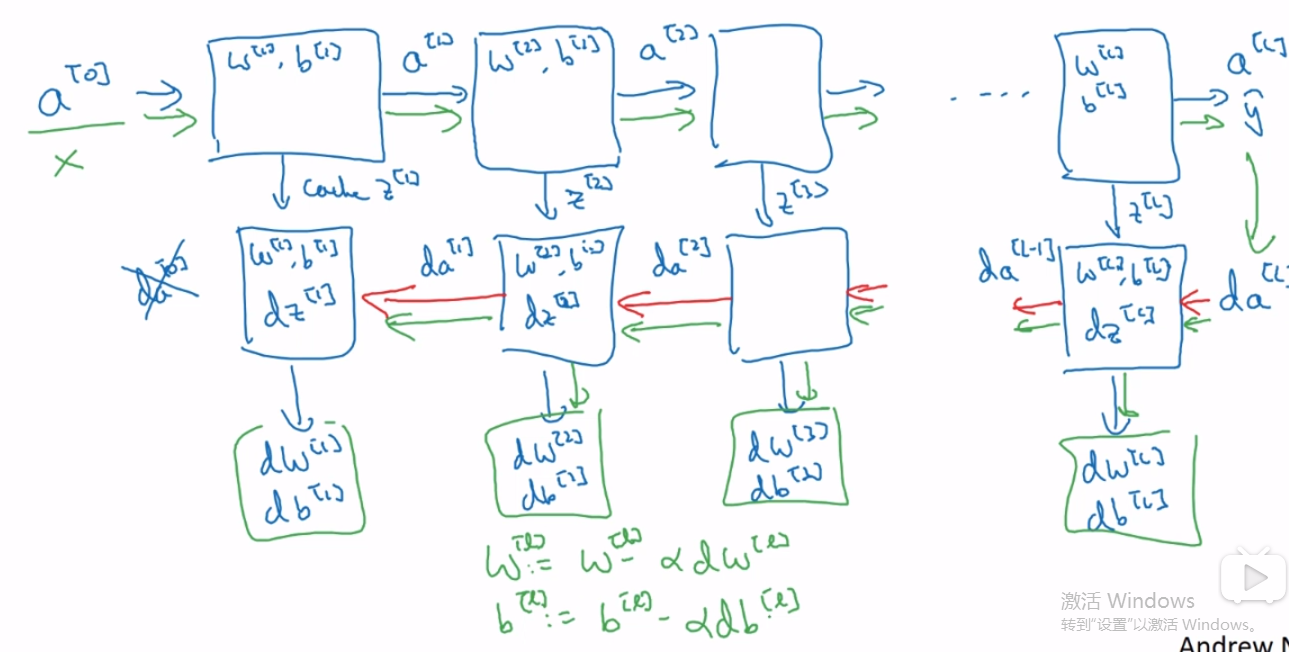
14。W,b是参数。学习率,循环次数,隐藏层数量都是超参数,因为它们控制着W和b。
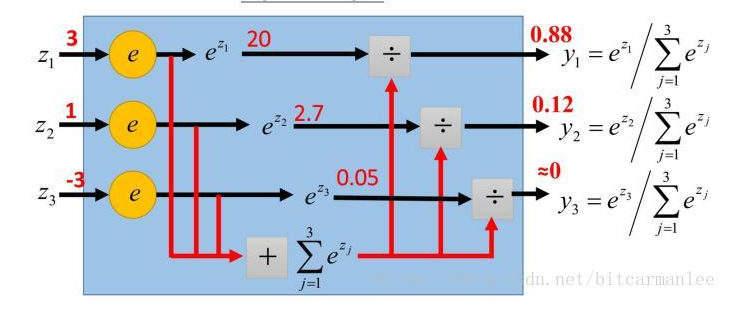
15。softmax函数将一个数映射到0--1之间,下图中每个数都经过了softmax函数:
16.下面原图是一个神经网络,可以改造成残差神经网络(ResNet),此时下图有5个残差块,每个残差块中,最前面的数据可以通过捷径直接传到最后面的
层(即跳远连接),当进行激励的时候,加上前面这个数,在进行激励
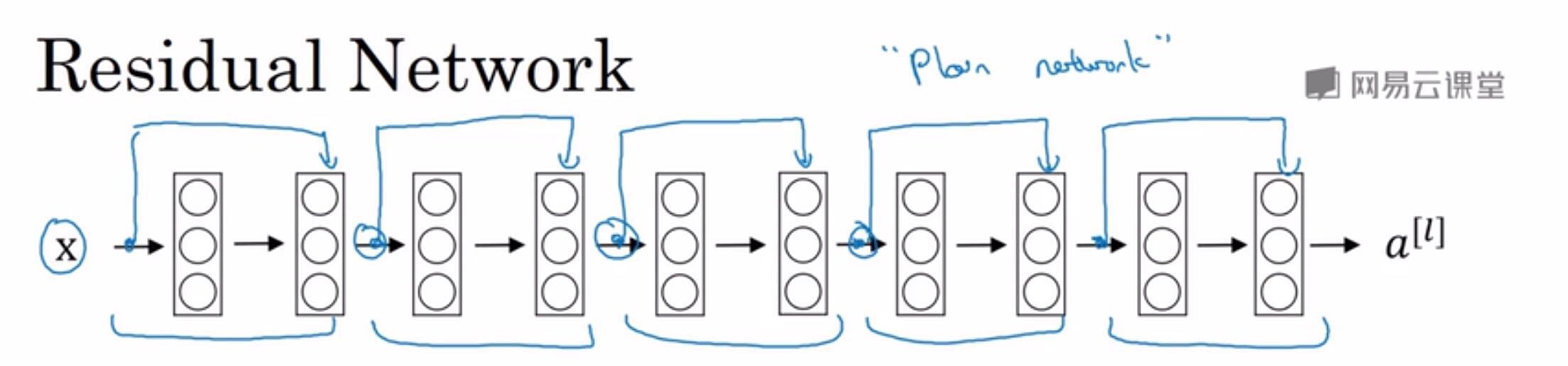
17.残差神经网络效率更高一些,因为它学习恒等函数比普通神经网络更容易。(因为跳远连接的存在,使得a[l+2]=a[l]更快一些)
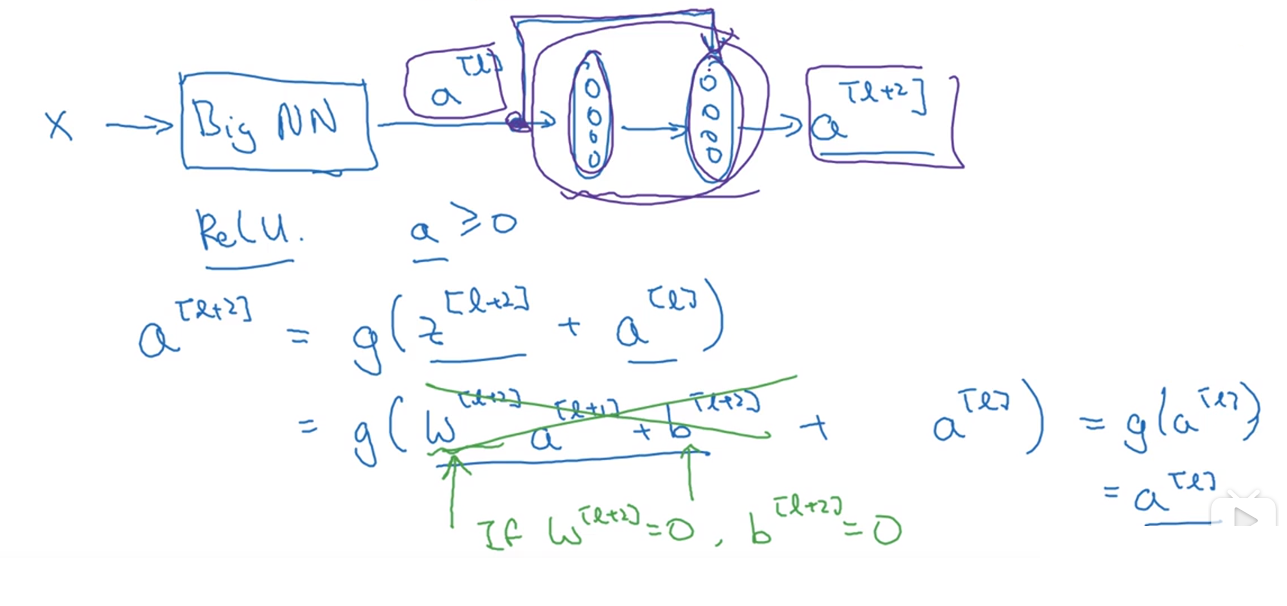
18.
当padding为valid时,即不进行像素填充
当padding为same时,则进行相应的像素填充,使得最后的输出图像和输入图像的长宽一致。
19.
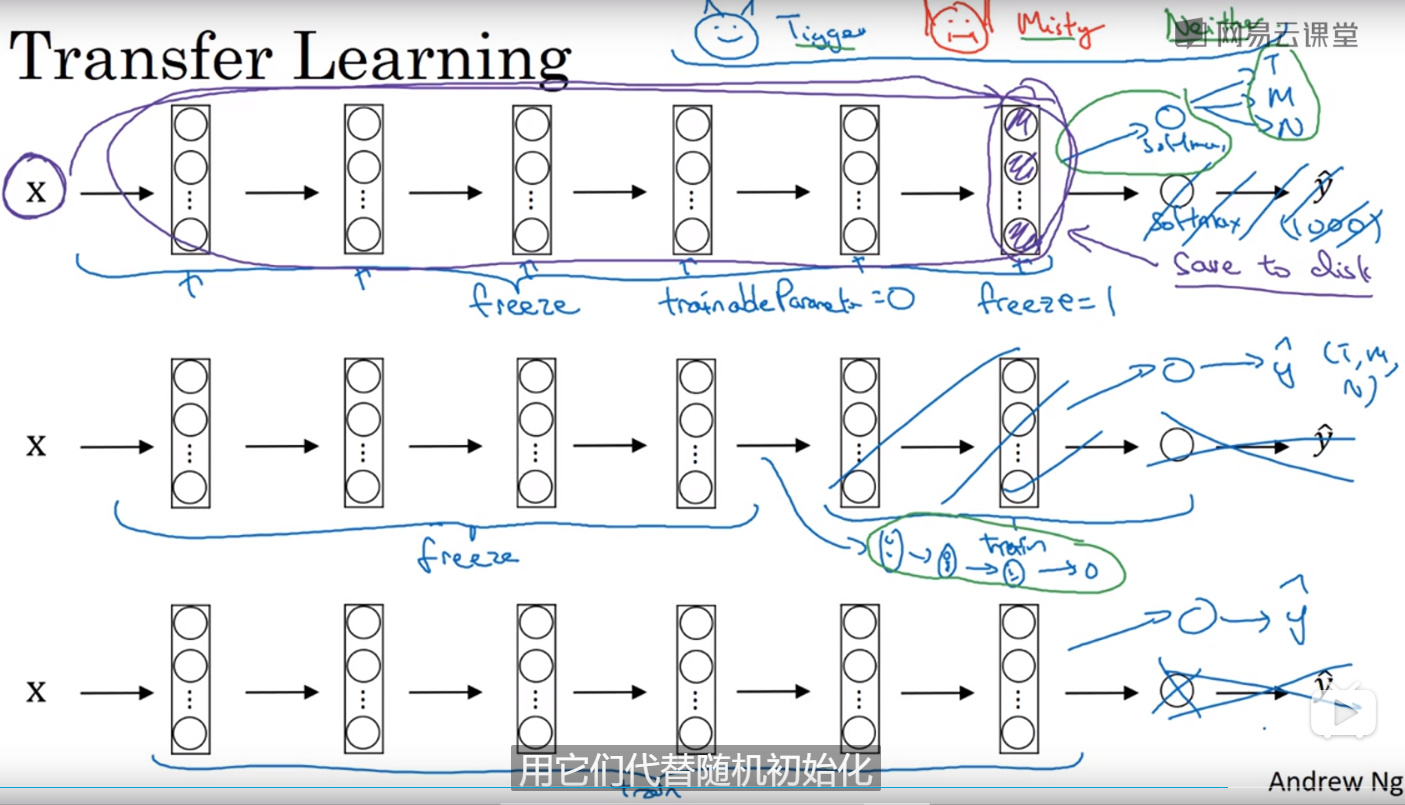
迁移学习:把别人的神经网络的开源代码下载下来,然后可以选择冻结里面几层(通过设置参数,比如freeze=1等等),使得训练的时候不要改变它的权重,就按照原作者的设计的权重值,接着按照需求改变一下softmax层使得这个网络适合自己的分类。或者在初始化时,不用再随机初始化权重了,用原作者的权重作初始化。
20.
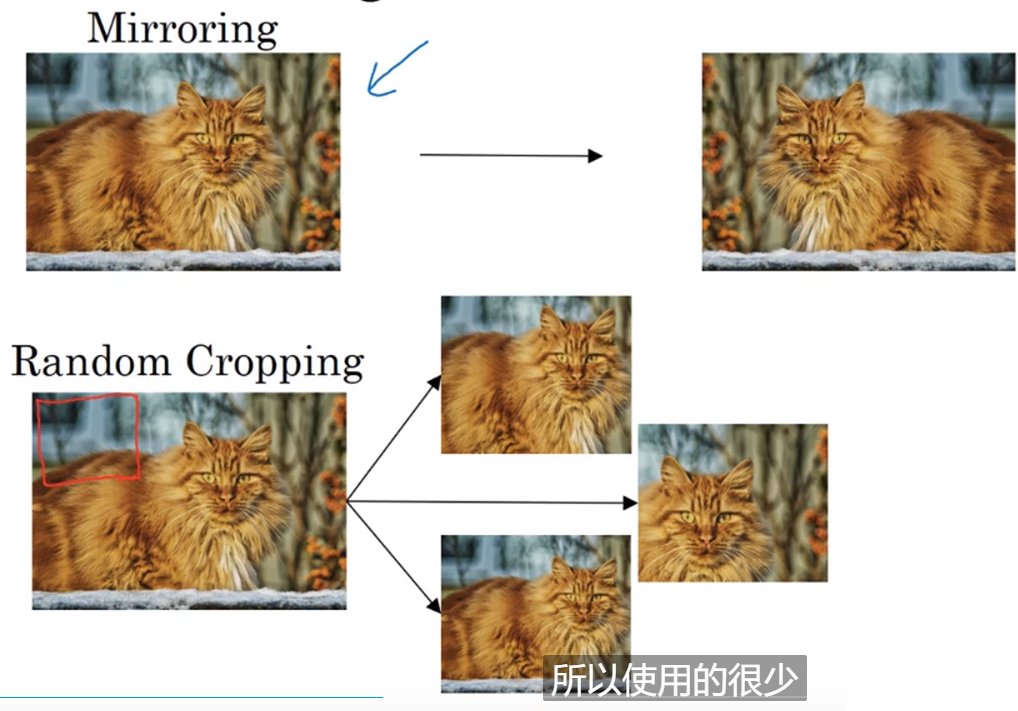
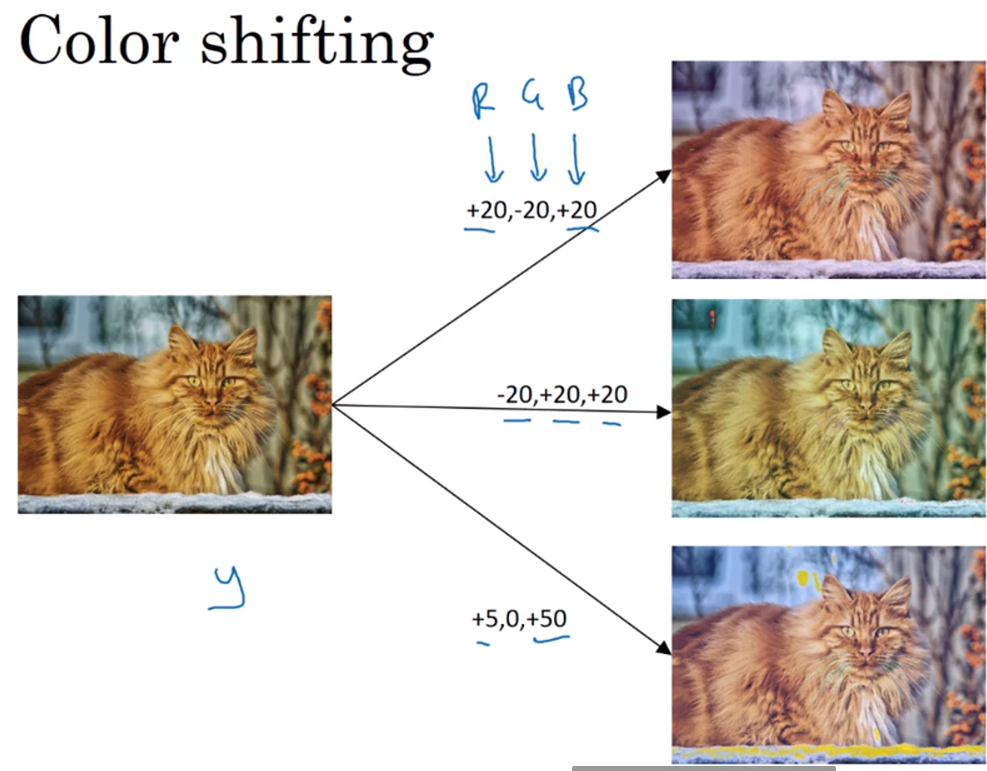
数据扩充技巧:镜像操作,随机裁剪(见下图),色彩转换(给RGB通道分别增加相应的失真值,见下下图)
21.
占位符是一种需要接受输入的结点
22.
tensorflow变量:模型当中的参数都是变量,在训练时值可以变化,而当进行预测时,变量的值此时就不变了。
23.
分类问题与回归问题:
输入变量与输出变量均为连续变量的预测问题是回归问题;
输出变量为有限个离散变量的预测问题成为分类问题;
其实回归问题和分类问题的本质一样,都是针对一个输入做出一个输出预测,其区别在于输出变量的类型。
分类问题是指,给定一个新的模式,根据训练集推断它所对应的类别(如:+1,-1),是一种定性输出,也叫离散变量预测;
回归问题是指,给定一个新的模式,根据训练集推断它所对应的输出值(实数)是多少,是一种定量输出,也叫连续变量预测。
举个例子:预测明天的气温是多少度,这是一个回归任务;预测明天是阴、晴还是雨,就是一个分类任务。
24.
符号说明:


25.
将很多运算打包成矩阵相乘的形式可以简化:

26.
若想利用多项式回归,可以先对样本进行处理,比如先保持x不变,再取x平方,。。。。。,最后利用线性回归来做。
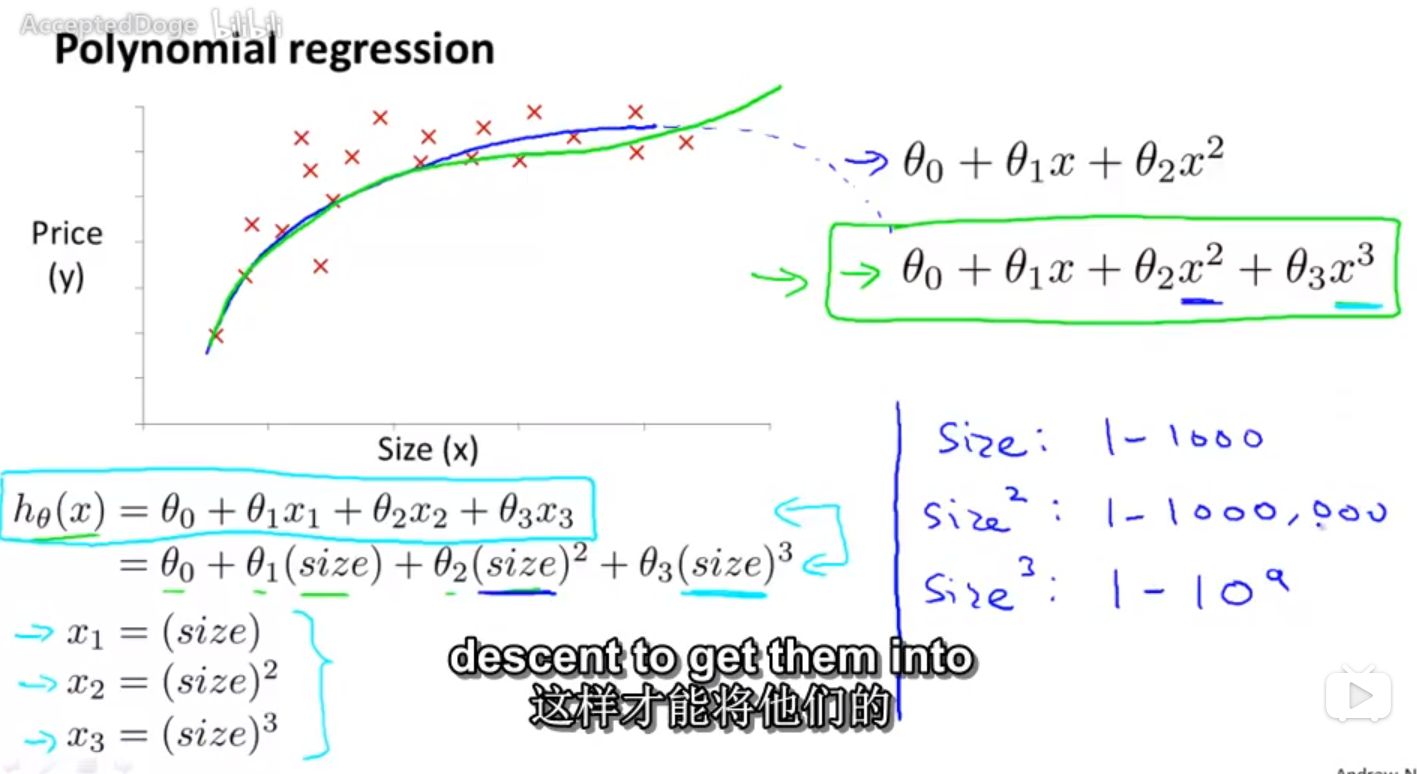
27.
均方误差形式的代价函数,且是多元线性回归问题,代价函数的表现形式:
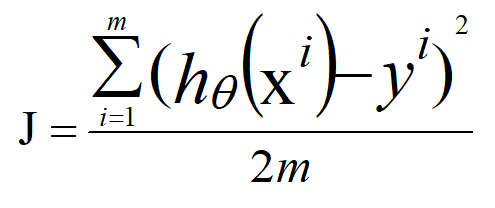
其中:
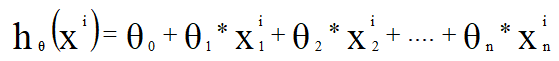
它的矩阵等价形式:
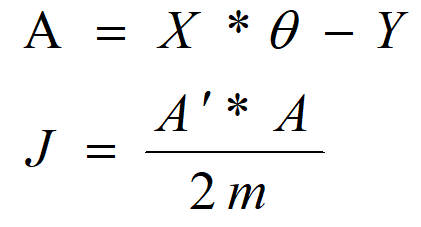
其中:
举例符号说明:
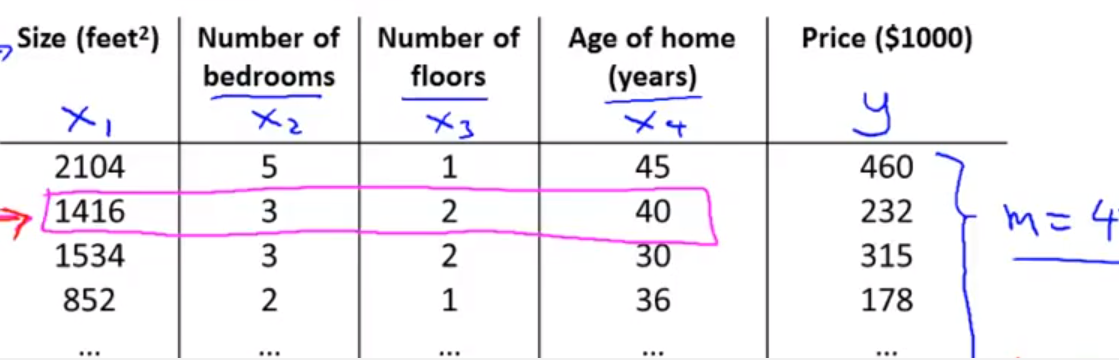
X=[ 1 2104 5 1 45
1 1416 3 2 40
1 1534 3 2 30
1 852 2 1 36]
Y=[ 460
232
315
178]
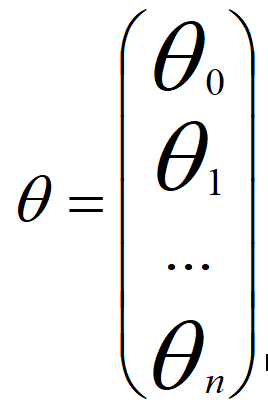
28.
方法与对应的使用情形
 29.
29.
通常采用比较大的神经网络并采用正则化方法要比使用小型的神经网络的效果要好。
30.
运用机器学习取解决问题时的推荐步骤:
①先快速实现一个算法能够解决这个问题,然后采用验证集取验证一下。
②画出学习曲线以决定需不需要更大的数据集或者是特征值。
③在验证集上做误差分析:分析一下哪些东西经常被算法认错,哪些类别这个分类器没有识别出来,那么对着相应的问题从而改进算法,比如修改特征值的个数等等。
32.
多项式回归的本质就是把x1*2,x1*x2,....作为新的特征,并且可以对这些特征进行feature scaling.
31.
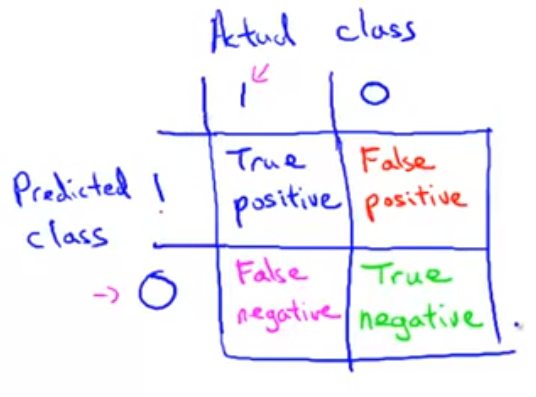
偏斜集(skewed class):正样本(y=1)的数量明显少于负样本
对于偏斜集,precision和recall越高代表这个算法效果越好
癌症例子符号说明如下:
32.
问题转化:
①问题
有大量已经标好的垃圾邮件,此时需要建立一个垃圾邮件分类器。
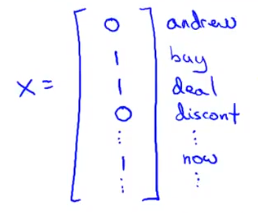
②得到x,y,确定特征时可以咨询相关领域的人类专家。
在所有邮件当中选取1万到5万个出现频率很高的单词,把它作为属性(或者是标题,邮件地址等等),此时查看每个邮件,若该邮件中出现了哪个单词就把对应的属性置为1,否则为0,此时生成了x,每个样本都有了x。
例如:
33。
高斯分布又称正态分布:
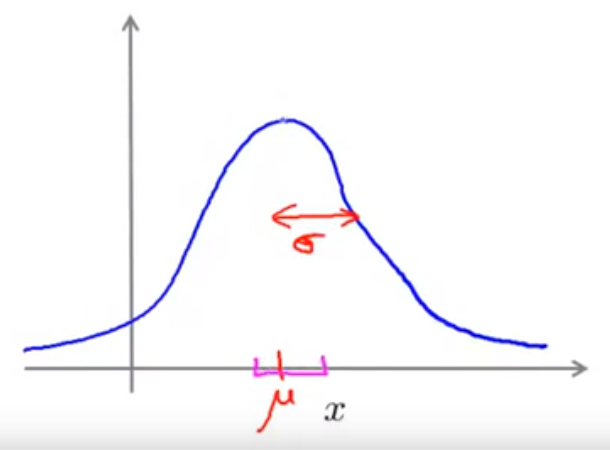
34.
若x1,x2都服从正态分布,则可以从图中估计出正态分布的均值和方差来:
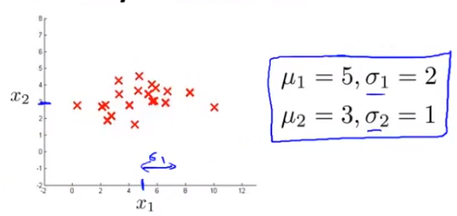
35。
对于不符合高斯分布的样本可以经过函数变换转化为高斯分布:
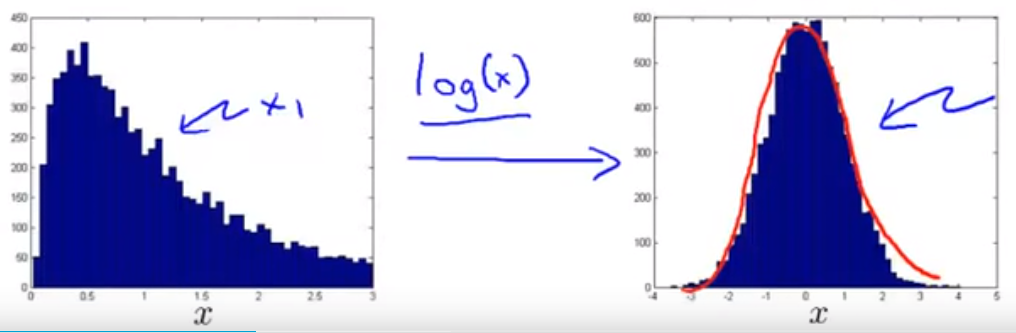
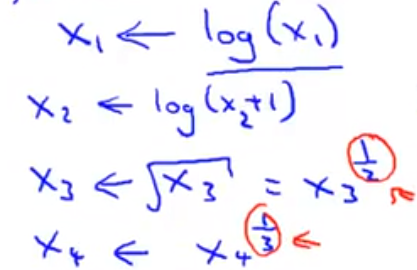
36
MapReduce
思想:比如要计算下面这个式子:
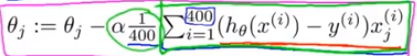
可以把求和分配给4个计算机,每个计算机算100个,最后把各自的结果传给中心服务器,然后中心服务器计算总的式子。这样可以提高4倍的速度。
35.
滑动窗口检测,即将下面的绿色框不断移动,每移动到一个位置,就把框框里面的图片传给分类器,让分类器看看是否有行人。接着换用同比例更大的绿色图块重新扫描。

37.
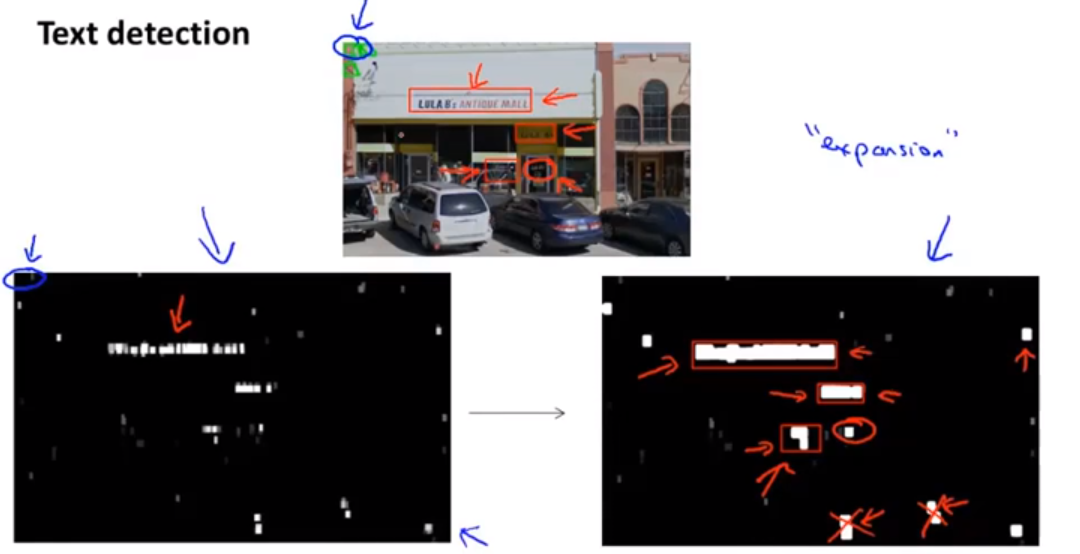
OCR问题:识别图片中的字符
解决流程:
①先检测图片中的文本区域,检测出来的像素标记为白色,再利用放大算子把某个白色像素周围的像素都变为白色,随后再把长宽比不合适的区域去掉:
②再进行字符的分割:

方法:首先训练一个分类器,让它学会什么时候该画一条线分割图片(对应的样本记为正样本),什么时候不用分(对应的样本记为负样本):
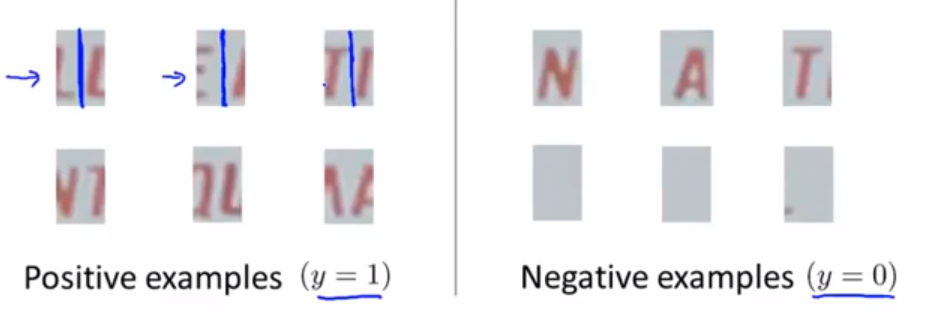
然后利用一个绿色框在图片上以步长进行滑动,每选定一个区域就利用分类器判别要不要分割,如果不用分割就继续滑动,如果要分割就分割出来对应的区域,然后绿色框框继续移动:

③最后进行字符分类识别,这一步可以利用逻辑回归,神经网络等等方法:

38.
上限分析:
假定一整个流程由三部分顺着执行,对每一个部分直接取测试集 ,然后把测试的集的真实标签传给后一部分,即跳过这一部分,看看总的性能会提高多少,接着在看下一个部分,不过保持之前完美的结果,继续对这一个部分做上限分析,直到最后的100%,画出一个表格来,见下图。看看对整个系统有显著提升的部分是什么,就把重点放在这里。下图中,可以看出要把工作重心放到text detection处。


39.
规模较小的数据集可以使用SVM,线性回归,。。。。,当规模大时,神经网络最好了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号