A Little Context to Start
我的hobby引擎使用一个系统,任何类或者结构体可以有metadata,但是这不是严格必须的。
除此之外,每个metadata开启的类型,并不要求去有一个虚函数表。让我们考虑一个简单的类型,
它位于一个名为ChildType.h的头文件中。
//ChildType.h
class childType : public parentType
{
DECLARE_TYPE( childType, parentType );
void RedactedFunction( float secretSauce );
float unsavedValue; /// +NotSaved
double * ptrToDbl;
ValueType_t someValues[3];
};
通过使用DECLARE_TYPE宏的美德,这个类型目的是元数据开启的是清晰的,但是它不能很好地知道这个数据来自于哪里。
我们需要去表示所有的关键信息,关于类的,在这样一个方式,我们可以序列化它或者一般性地检查它。
我的设计的选择的方式和原因不重要,但是我的方案是去定义一个新的cpp文件,看起来像这样:
//ChildTypeClass.cpp
MemberMetadata const childType::TypeMemberInfo[] = {
{“unsavedValue”, eDT_Float, eDT_None, eDF_NotSaved, offsetof(childType, unsavedValue), 1, NULL },
{“ptrToDbl”, eDT_Pointer, eDT_Float64, eDF_None, offsetof(childType, ptrToDbl), 1, NULL },
{“someValues”, eDT_StaticArray, eDT_Struct, eDF_None, offsetof(childType, someValues), 3, ValueStructClass }
};
IMPLEMENT_TYPE( childType, parentType );
这里发生了很多事情,并且这里有一些不重要的管路系统隐藏在这些DECLARE_TYPE和IMPLEMENT_TYPE宏之后。
对于这个讨论,DECLARE_TYPE宏添加了一个MemberMetadata结构体的类静态数组。
那个数组的每个成员描述了一个名字,主要的类型,次要的类型,标识符(比如+NotSaved),offsetof,这些在结构体中的成员,
静态数组长度(通常为1),还有目标metadata数组(或者NULL)。
要正确输入大量数据,并在引擎的整个生命周期中维护这些数据。
Automation Enters the Picture
自动化进入了视野。
这篇文章是关于如何我去创建我自己的元数据的。
Enter Clang
Clang是一个C语言家族前端,对于LLVM。Clang是一个C++对于LLVM编译器。
libClang提供了一个相对简单的C风格的API,到抽象语法树(AST),被语言解析器所创建。
这对于创建元数据来说意义重大。
A Little Glossary Action
一点词汇行动。
libClang API使用一些简单的概念,去建模你的代码,在AST形式下。
Translation Unit
实际上,它是创建一个AST的编译器的一次运行。我们可以思考它作为一个编译的文件+任何它包含的头文件。
在libClang的术语,它是一个基础层次的容器,并且是我们将需要去数据收集工作的起点。
Cursor
一个Cursor表示一个语法构造,在AST中。它们可以表示一个完整的命名空间或者一个简单的变量名。
它们也保留父子/儿子关系,和其它cursors。对于我们的目的,cursors是在AST中我们需要去遍历的节点,
它们也包含了对源文件位置的引用,它们所找到的。
Type
这个是非常简单的。我们查看的cursors将经常引用一个类型。这些就是字面上的语言类型。
记在心里,Clang建模了整个类型系统,那么typedefs是不同于它们所别名的类型。
The Plan
一旦解析完成,整个解决方案就非常轻松了。
1.设置环境
2.对于每个头文件,制作一个Translation Unit。
3.遍历AST,对于感兴趣的类型定义cursors。
4.对于每个类型定义,查找member data cursors,还有其它信息。
5.一旦我们获得了关于一个类型的所有信息,就将文本转储到文件中。
Setup-Compiler Environment
显然地,我们需要一个或者多个头文件去工作,但还有更多-比我天真预期的还要多。即时我们只是硬编码了一系列的头文件,我们也不能够去编译它们,通过它们自己。我们需要复制足够多的普通项目环境,以获得与普通编译器相同的解析结果。
我们需要去使用相同的命令行预处理定义(-D)就行同样的额外包含目录(-I's)。
注意,编译器会搜索额外包含目录,本质上是使用了-I这个命令。
作者的解决方案涉及到解析Visual Studio的工程文件。
Setup-Header Environment
另一个我没有考虑到的事情是头文件所处的环境是什么样的。在包含给定的头文件之前,无法知道需要包含哪些文件。
这里真正地只有两件事情,你可以假设,当解决这个问题的时候-假设任何预定义的头文件被包含,在你的头文件之前,并且假设
任何事物不需要去包含,因为你的头文件可以独立存在。第二个点与我通常如何构造我的头文件相互吻合,但是它已经升级为一个硬性情况。头文件级联可以杀死你的编译时间性能,但是外部的头文件顺序依赖是更糟糕的。显然,在可能的情况下,使用前向声明来减少头文件级联是一个好主意。
Time to Make the Doughnuts
是时候制作甜甜圈了。
当我们收集了所有的头文件路径,和预处理符号,调用clang非常轻松。
我们不可以只传递header到clang_parseTranslationUnit就这么定了。我假设我可以,但是".h"是一个模糊的扩展。Clang不知道如何去执行,当它不知道额外的参数的时候,去揭示语言如何去使用。我也需要去包含PCH文件。
所以,我以创建一个短暂的.cpp文件去一石二鸟。
这里有一个基本步骤,用于构建一个translation unit,对于一个单一的头文件,叫做"MyEngineHeader.h"。
显然,你的环境参数有所不同。
-I表示额外包含目录。
char const * args[] = {"-Wmicrosoft"
, "-Wunknown-pragmas"
, "-I\\MyEngine\\Src"
, "-I\\MyEngine\\Src\\Core"
, "-D_DEBUG=1" };
CXUnsavedFile dummyFile;
dummyFile.Filename = "dummy.cpp";
dummyFile.Contents = "#include \"MyEnginePCH.h\"\n#include \"MyEngineHeader.h\"";
dummyFile.Length = strlen( dummyFile.Contents );
CXIndex CIdx = clang_createIndex(1, 1);
CXTranslationUnit tu = clang_parseTranslationUnit( CIdx, "dummy.cpp"
, args, ARRAY_SIZE(args)
, &dummyFile, 1
, CXTranslationUnit_None );
Build Errors?WTF?!
编译你的代码,使用Clang,将可能输出一些不期望的错误。记住,Clang是一个C++编译器有一些细微差别,相比于其它的,
并且Clang的差异不一定需要匹配你的其它C++编译器的差别。这是一个很好的事情-真的!任何人,做跨平台的工作,
将告诉你,所有额外的平台,长期的错误表现它们自己。拥抱多编译器的情况,将迫使你保持更加清晰、更符合标准的代码。
不幸地是,解决主要问题是不可选的,在这里。我们需要去创建一个有效的AST对于遍历,它不会缺少描述数据的任何属性。
为了获取我们所想要的,parser实际上,不得不去完成它所作的。使用clang_getDiagnostic,clang_getDiagnosticSpelling,等,去获取人类可读的错误信息。
unsigned int numDiagnostics = clang_getNumDiagnostics( tu );
for ( unsigned int iDiagIdx=0; iDiagIdx < numDiagnostics; ++iDiagIdx )
{
CXDiagnostic diagnostic = clang_getDiagnostic( tu, iDiagIdx );
CXString diagCategory = clang_getDiagnosticCategoryText( diag );
CXString diagText = clang_getDiagnosticSpelling( diag );
CXDiagnosticSeverity severity = clang_getDiagnosticSeverity( diag );
printf( "Diagnostic[%d] - %s(%d)- %s\n"
, iDiagIdx
, clang_getCString( diagCategory )
, severity
, clang_getCString( diagText ) );
clang_disposeString( diagText );
clang_disposeString( diagCategory );
clang_disposeDiagnostic( diagnostic );
}
Time to Start Digging!
是时候开始挖了。
编译阶段应当已经提供你一个有效的translation unit。当我们获取了顶层的top-level cursor,使用clang_getTranslationUnitCursor(),我们将translation unit放在一个安全的位置,并且使用cursor作为高层的对象。
C风格的Clang接口使用一个笨拙的回调API,叫做clang_visitChildren。Clang将对它所遇到的每个child cursor调用回调函数。
你的回调,然后,返回一个值表示是否迭代器应当重新递归更深的儿子,持续到它的儿子的兄弟,或者完全退出。
我们在这个阶段只对类型声明感兴趣,但是C++允许新的类型发生,在一些地方。
幸运的是,我们可以很快地削减文件。
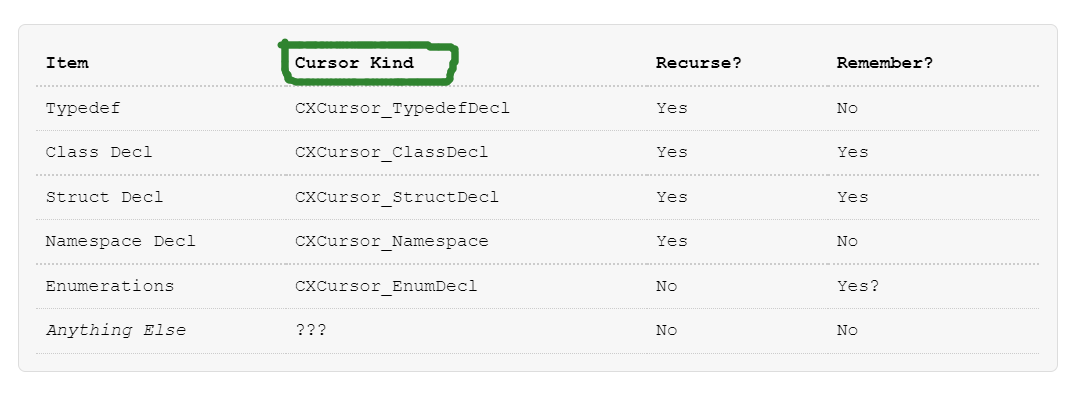
这里有一些其它的情况,没有被覆盖-函数私有类型,还有联合。
Remember表示是否要记录?
Traverse For Types
MyTraversalContext typeTrav;
clang_visitChildren( clang_getTranslationUnitCursor( tu ), GatherTypesCB, &typeTrav );
enum CXChildVisitResult GatherTypesCB( CXCursor cursor, CXCursor parent, CXClientData client_data )
{
MyTraversalContext * typeTrav = reinterpret_cast( client_data );
CXCursorKind kind = clang_getCursorKind( cursor );
CXChildVisitResult result = CXChildVisit_Continue;
switch( kind )
{
case CXCursor_EnumConstantDecl:
typeTrav->AddEnumCursor( cursor );
break;
case CXCursor_StructDecl:
case CXCursor_ClassDecl:
typeTrav->AddNewTypeCursor( cursor );
result = CXChildVisit_Recurse;
break;
case CXCursor_TypedefDecl:
case CXCursor_Namespace:
result = CXChildVisit_Recurse;
break;
}
return result;
}
枚举是混合的,即时它们有点特殊。对于元数据目的,你可能把它们当成整数来处理。
Panning For Gold
我们现在有了一大串类型,我们想去过滤它们。记住,我们可能遇到一大串头文件级联,在编译器阶段。逻辑上地,我们只对在我们直接处理的头文件中声明的类型感兴趣。当我们依次处理头文件的时候,我们将遇到其它的。幸运地是,我们可以迭代感兴趣的cursors的列表在我们上一阶段创建的,并且询问每一个文件来自哪个文件位置。类型来自其它文件将被安全地剔除。
Data Gathering-Internal
在剔除来自其它头文件的类型后,我们应当有一个更少的有趣类型的列表,那么我们可以使用它们的cursors作为起始点,去学习它们。
这里是我们开始收集所有的数据开始的地方,我们之前提到的。我们将以与首先获得类型游标相同的方式迭代这些数据。我可以确认你可以这样做它们在一次扫描,但是,我发现问题领域在两个阶段中更容易考虑。这个时间,相反,开始于translation unit的顶部,我们可以开始迭代在type cursor。我们想去迭代类型声明cursor完整地,并且查找一些不同的事物。

Base types和member variables应当清楚地说明我们为什么需要它们,但是静态类变量可能奇异,对于这个列表。我使用它们,对于另一个过滤的水平。我知道任何人,支持metadata,使用DECLARE_TYPE宏在之前。当然,宏是所有被预处理器解析,那么C语言parser不会使用那个符号,但是其中隐藏着一个静态类变量,我们可以找到它的名称和类型。如果没有,那么这个类就不能支持元数据,我们完全可以跳过它。换个角度看问题,我们需要做的唯一的事情,就是按顺序开启metadat对于一个给定的类,添加DECLARE宏。剩下的自然就好了。
Data Gathering-External
一旦我们有了所有我们将从类的里面获取的数据,我们只需要一些额外的花絮,在我们可以生成metdata文件之前。我们需要去知道目标类型的完整限定符命名空间,以及所有基础类型的命名空间。这也是非常相当简单的,因为你可以简单地询问任何cursor的词法父级是什么。通过迭代,直到你碰到translation unit,你可以捕获一个给定类型的所有包含作用域。
Ambiguity Operator
歧义性运算符
namespace FooNS
{
class Foo
{
int dataFoo;
};
}
using namespace FooNS;
typedef Foo FooAlias;
class Bar : public FooAlias
{
int dataBar;
};
当我们尝试去查找Bar的基类的完整作用域,我们并不知道Foo实际上住在FooNS里面,并且using指示符是一些允许这个去工作的东西。我不是using的粉丝,并且经常涉及它作为歧义性的运算符。
去解决这个情况的方式,是行走一遍词法父级链,像我之前提到的那样,但是在每一个步骤,
我们需要去查看,是否parent scope是一个class-type,struct-type,或者typedef。如果它是这些中的任何一个,那么我们需要去获取parent cursor中的type,然后询问标准类型记录,目的是去消除typedef指示符,并且获取cursor从type record,使用clang_getTypeDeclaration函数。
Data Gathering-Off-World
数据收集-外部世界。
这么多东西,还能收集什么呢?回到第一部分,我说我的数据成员可以有标识,比如"+NotSaved",
我从来没有说这些信息是如何获取的。不幸地是,C++没有真正地提供与解析器机制集成的代码注释方案。有一个小的空间,对于一个#pragma或者一个__attribute__接口,但我无法让这些系统按照我想要的方式去运行。此外,我不喜欢为了给每个成员数据属性赋予粒度,它们必须非常繁琐。相反的,我简单地采用去使用代码注释。
Writing it out
最终,我们应当有所有的数据,我们所需要去书写到我们的metadata。如前所述,我将所有内容写入cpp文件,以便包含到引擎项目中。这是一个非常好,人类可读的方法,但是它有一个隐式的需要,任何metadata生成运行,可能需要一个小的额外的构建步骤。
Details Details...
我认为,我需要给出一些例子,AST是如何构造的,对于通常的情况。
让我们简单地考虑一些普通的成员数据:
class Normal
{
int data1;
float data2;
};
cursor层次看起来如下:
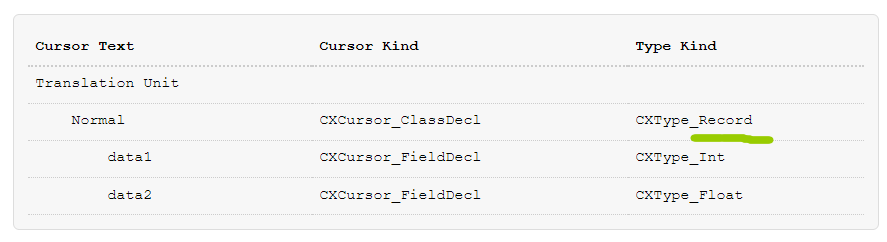
它真正看起来,是相当直观的。Types被分离从语义构造,还有POD类型,被直接地表示,在Clang API。
现在考虑一些更加复杂的情况:
class StillPrettyNormal
{
int * dataPtr1;
struct DataType * dataPtr2;
};
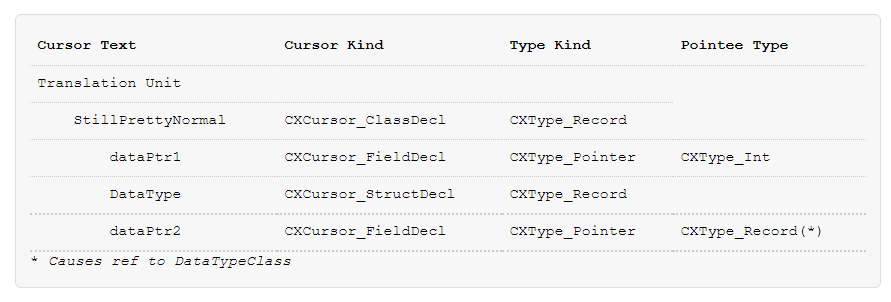
这里有两个奇怪的部分。第一,我们丢失了integer的注解,对于dataPtr1,我们只知道它是一些指针。这不是一个真正的问题,因为Clang提供了clang_getPointeeType函数。你可以调用这个在任何pointer type,去获取下个类型在链条上。指向指针的指针的指针可以被解析,通过多次调用,如果需要的话。
第二,我们有一个意外的结构体声明在我们类声明的中间。好吧,它不是完整的意味的。
'struct'的包含,在dataPtr2的字段声明,是一个类型的前向声明,并且Clang表示这个。幸运地是,它是实际字段声明的兄弟,我们可以安全地忽略它。
这个例子最终的部分是类型的引用,到外部定义的DataType。在C++中的前向声明允许类型被提及,并且不需要完整的定义,直到它们被使用,我不得不去假设DataTypeClass实际上存在于其它地方。
然而,DataType不是一个metadata-enabled的类型,并且引用到DataTypeClass将破坏一些链接时间。
好的,再举一些例子,但是我要提前告诉你,这已经有点超出了我的元数据创建工具的范围。
class WackyTown
{
MyContainer< MyData* > cacheMisser;
MyContainer< MyData*, PoolAllocator<32768> > sendHelp;
};
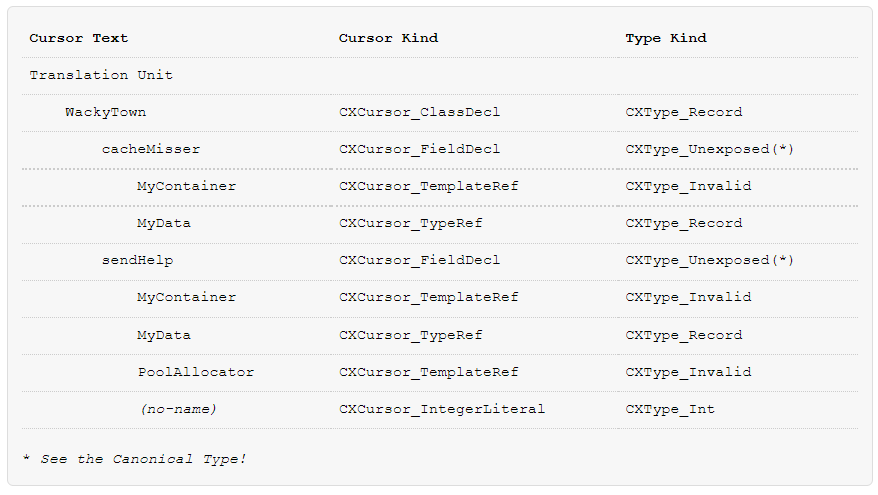
这里有一些丢失的数据在这里!第一,cacheMisser和sendHelp的类型被列出来,作为"Unexposed"的。第二,template-ref类型是无效的,没有清楚的方式,去获取模板定义。
第三,目前,暴露给AST的是,MyType引用其实是指针。第四,这里没有方式去知道整数值是如何被传递给PoolAllocator在其它实例。第五,模板类型推导的隐式层次被变得平坦了。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号