
第1章网络爬虫简介(学习笔记)
1.1网络爬虫有何用
重复性的手工流程,可以用网络爬虫技术实现自动化处理。
在理想状态下,网络爬虫并不是必需品,每个网站都应该提供API,以结构化的格式共享他们的数据,现实情况是,他们限制了抓取的数据,以及访问这些数据的频率。我们不能仅仅依赖API去访问我们所需的在线数据。
1.2网络爬虫是否合法
如果被抓取的数据用于个人用途,并且在合理使用版权法的情况下,通常没有问题。但是,这些数据会被重新发布,并且抓取行为的攻击性过强导致网站宕机,或者其内容受版权保护,抓取行为违反其服务条款的话,有可能违法。
1.3Python3
本书使用python3开发,个人推荐pycharm+anaconda。
1.4背景调研
深入讨论爬取一个网站时,我们首先需要对目标站点的规模和结构进行一定程度的了解。网站自身的robots.txt和sitemap文件可以提供一定的帮助,此外还有一些外部工具,Google搜索和WHOIS。
1.4.1检查robots.txt
大多数网站都会定义robots.txt文件,让爬虫了解爬取这些网站时有哪些限制。爬取之前,检查robots.txt可以让爬虫被封禁的可能性降至最低。
更多信息可以参见http:www.robotstxt.org
实例网站:http://example.python-scraping.com
其中robots.txt内容如下:
# section 1
User-agent: BadCrawler
Disallow: /
# section 2
User-agent: *
Disallow: /trap
Crawl-delay: 5
# section 3
Sitemap: http://example.python-scraping.com/sitemap.xml
注:
1.section1中禁止用户代理为BadCrawler的爬虫爬取该网站,不过这种写法可能起不到什么作用,后面会有离子展示如何让爬虫自动遵守robots.txt的要求。
2.section2中,无论使用那种用户代理,都应该在两次下载请求之间给出5秒的抓取延迟,我们应该遵守该建议以免服务器过载,这里还有一个/trap链接,用于封禁那些爬取了不循序访问链接的恶意爬虫。如果你访问了这个链接,服务器就会封禁你的IP一分钟。
3.section3中定义了一个sitemap文件。
1.4.2检查网站地图
网站提供的sitemap文件可以帮助网络爬虫定位网站最新的内容,无需爬取每一个网页。更多信息参考http://www.sitemap.org/protocol.html
下面是在robots.txt文件中定位到sitemap文件的内容:
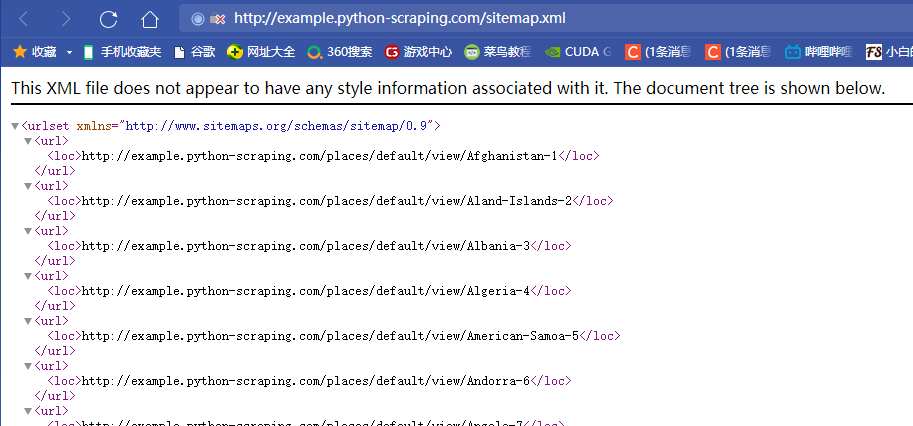
网站地图提供了所有网页的链接,虽然它提供了一种有效的方式,我们仍需谨慎处理,因为文件可能存在丢失过期或者不完整的情况。
1.4.3估算网站大小
目标网站的大小会影响我们如何进行爬取,当站点拥有较多网页时效率变得非常重要。估算网站的一个简便方法就是检查Google爬虫的结果。可以通过Google搜索的site关键字过滤域名结果,从而获取该信息,更多信息参考http://www.google.com/advanced_search
在域名后面添加url路径,可以对结果进行过滤,仅显示网站的某些部分。
1.4.4识别网站所用技术
