
机器学习概述
1、什么是机器学习
机器学习是从数据中自动分析获得规律(模型),并利用规律对未知数据进行预测。
2、为什么需要机器学习
解放生产力、解决专业问题、提供社会便利
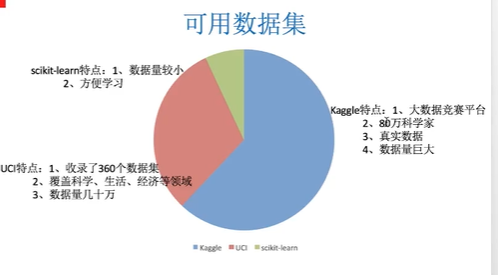
3、可用数据集
数据处理:
pandas:一个数据读取非常方便以及基本的处理格式的工具
sklearn:对于特征的处理提供了非常强大的接口
4、特征提取
1)特征抽取对文本等数据进行特征值化
#API sklearn.feature_extraction
2)字典特征抽取
作用:对字典数据进行特征值化
#类 skelearn.feature_extraction.DictVectorizer
字典数据抽取:把字典中一些类别数据,分别进行转换成特征
dict.get_feature_names()
数组形式,有类别的这些特征,先要转换为字典数据
from sklearn.feature_extraction import DictVectorizer
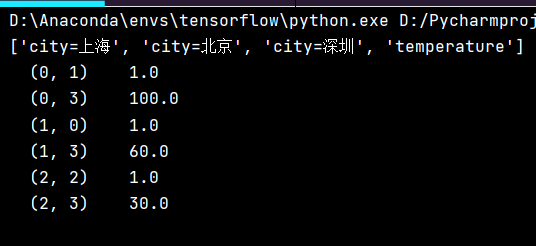
def dictvec(): #实例化 dict = DictVectorizer() #调用fit_transform data = dict.fit_transform([{'city': '北京', 'temperature': 100}, {'city': '上海', 'temperature': 60}, {'city': '深圳', 'temperature': 30}]) #字典数据抽取 print(dict.get_feature_names())
print(data) return None if __name__ =="__main__": dictvec()
3)文本特征抽取
作用:对文本数据进行特征值化
#类 sklearn.featurn_extraction.text.CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer def contvec(): #对文本进行特征值化 cv = CountVectorizer() data = cv.fit_transform(["life is short, i like python", "life is so long, i dislike python"])
#对单个英文字母不统计,没有分类依据 print(cv.get_feature_names()) print(data.toarray()) return None if __name__ =="__main__": contvec()

中文文本特征提取
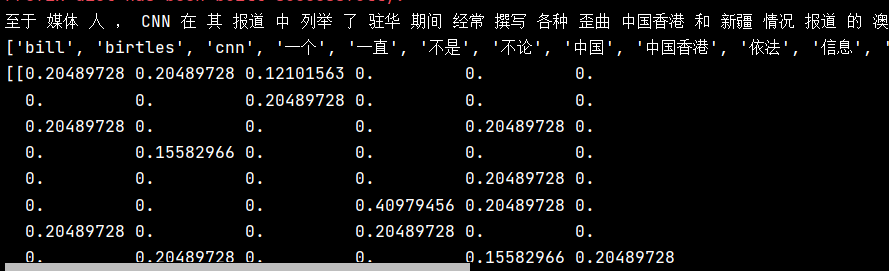
from sklearn.feature_extraction.text import CountVectorizer import jieba def cutword(): con1 = jieba.cut("至于媒体人,CNN在其报道中列举了驻华期间经常撰写各种歪曲中国香港和新疆情况报道的澳大利亚广播公司记者Bill Birtles和《澳大利亚金融评论报》的记者。") con2 = jieba.cut("但CNN还是隐瞒了另一个重要的信息,那就是在过去几年里澳大利亚媒体一直在配合澳大利亚政府打着“抓间谍”的旗号污名化在澳大利亚的华人、中国学生学者、甚至还多次骚扰过中国媒体的驻澳记者。") con3 = jieba.cut("所以,不论他怎么对CNN辩解说是无辜的,还抛出自己的4个孩子正在爱尔兰等信息“博同情”,他都应该在中国的法律框架下依法应对这起案件,而不是跑到CNN上对中国的司法用政治手段给自己开脱。") #转换成列表 content1 = list(con1) content2 = list(con2) content3 = list(con3) #把列表转换成字符串 c1 = ' '.join(content1) c2 = ' '.join(content2) c3 = ' '.join(content3) return c1, c2, c3 def ChineseVec(): c1, c2, c3 = cutword() print(c1, c2, c3) cv = CountVectorizer() data = cv.fit_transform([c1, c2, c3]) print(cv.get_feature_names()) print(data.toarray()) if __name__ =="__main__": #dictvec() #contvec() ChineseVec()

4)tf_df分析问题
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer import jieba def cutword(): con1 = jieba.cut("至于媒体人,CNN在其报道中列举了驻华期间经常撰写各种歪曲中国香港和新疆情况报道的澳大利亚广播公司记者Bill Birtles和《澳大利亚金融评论报》的记者。") con2 = jieba.cut("但CNN还是隐瞒了另一个重要的信息,那就是在过去几年里澳大利亚媒体一直在配合澳大利亚政府打着“抓间谍”的旗号污名化在澳大利亚的华人、中国学生学者、甚至还多次骚扰过中国媒体的驻澳记者。") con3 = jieba.cut("所以,不论他怎么对CNN辩解说是无辜的,还抛出自己的4个孩子正在爱尔兰等信息“博同情”,他都应该在中国的法律框架下依法应对这起案件,而不是跑到CNN上对中国的司法用政治手段给自己开脱。") #转换成列表 content1 = list(con1) content2 = list(con2) content3 = list(con3) #把列表转换成字符串 c1 = ' '.join(content1) c2 = ' '.join(content2) c3 = ' '.join(content3) return c1, c2, c3 def tfidfvec(): c1, c2, c3 = cutword() print(c1, c2, c3) tf = TfidfVectorizer() data = tf.fit_transform([c1, c2, c3]) print(tf.get_feature_names()) print(data.toarray()) return None if __name__ =="__main__": tfidfvec()
5、特征预处理-归一化
1)特征预处理是什么
通过特定的统计方法(数学方法)将数据转换成算法要求的数据
数值型数据:标准缩放:1、归一化2、标准化3、缺失值
类别型数据:one-hot编码
时间数据:时间的切分
2)sklearn特征处理API
sklearn.preprocessing
3)归一化
特点:通过对原始数据进行转换将数据映射到[0,1]之间
公式:![]()
欢迎关注我的CSDN博客心系五道口,有问题请私信2395856915@qq.com
