

GPU workflow浅述
写在前面:
本文章为个人学习笔记,方便以后自己复习,也希望能帮助到他人。
由于本人水平有限难免出现错误,还请评论区指出,多多指教。
部分图元和素材来源于网络,如有侵权请联系本人删除。
参考资料与链接会在文章末尾贴出。
=======================================================================
最近在看GPU硬件架构的相关知识,在这记录一下。
layout:
1.CPU与GPU的区别
2.GPU物理架构
3.GPU工作逻辑
1.CPU和GPU的区别
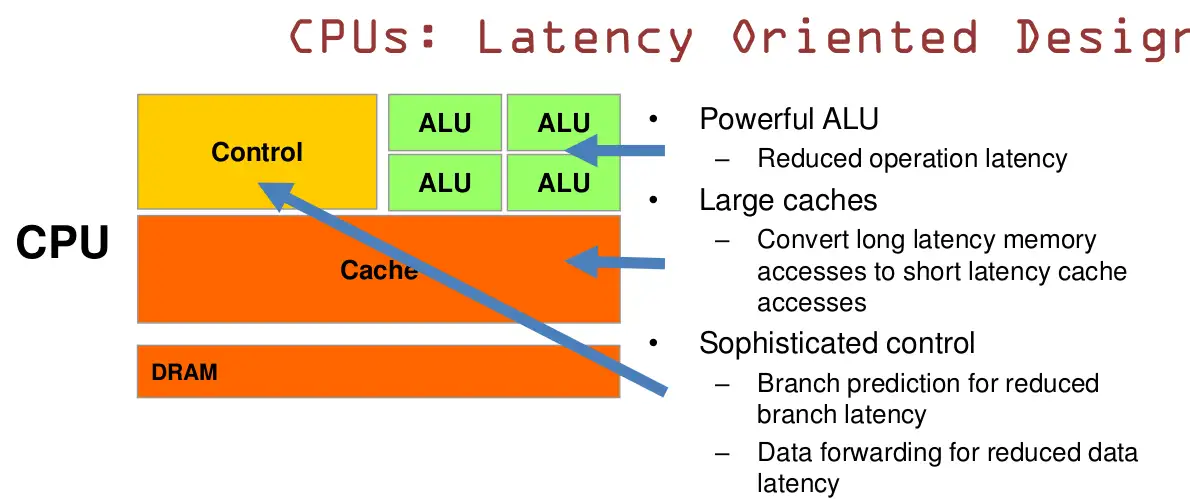
- CPU有强大的算术逻辑单元(ALU,Arithmetic Logic Unit),可以减少操作延迟
- 用大缓存来降低延迟,可以保存某些之前访问过的数据在缓存中,当再次需要访问时就可以在缓存中读取
- 复杂的逻辑控制单元,当程序含有多个分支的时候,它通过提供分支预测的能力来降低延时。数据转发。 当一些指令依赖前面的指令结果时,数据转发的逻辑控制单元决定这些指令在pipeline中的位置并且尽可能快地转发一个指令的结果给后续的指令。
概括的来说CPU基于低延迟设计,确保任务能尽可能快地完成,并能在不同的操作中切换,是串行计算。
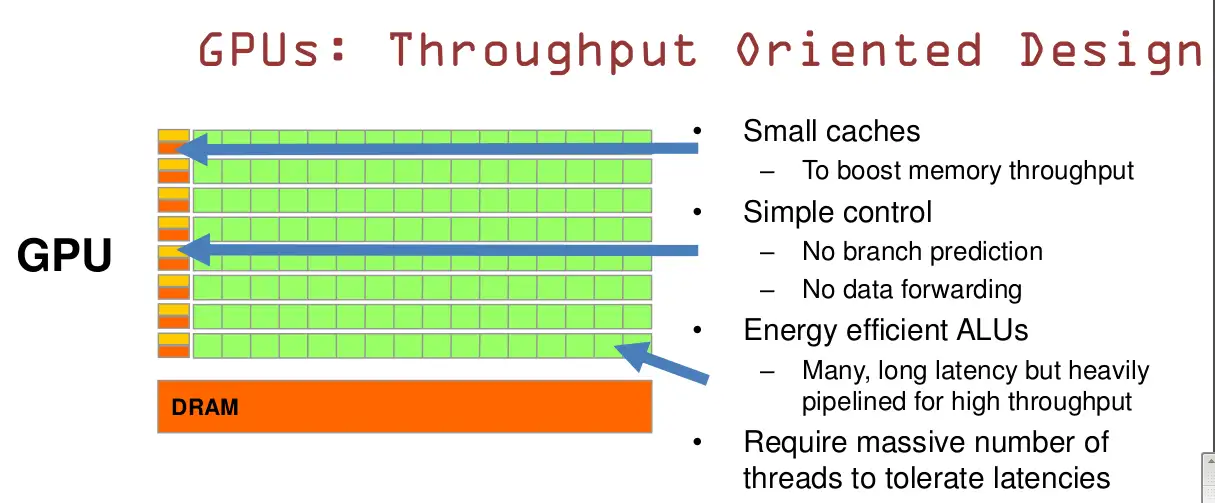
- GPU有许多的ALU和很小的缓存,尽管延迟比CPU高,但是保证了大的数据吞吐量。
- 简单的控制单元,没有分支预测和数据转发。
- GPU的内存访问延迟问题被数量众多的ALU和Thred平衡了。
2.GPU的物理架构
以Nvidia为例,Nvidia历代GPU架构以历史上的著名科学家名字命名,Tesla,Fermi,Kepler,Maxwell,Pascal,Volta,Turing,Ampere,Hopper。自Fermi以来,历代GPU都有着部分类似的结构():
- TPCs(texture/processor clusters,纹理处理簇)
- GPCs(graphics processor clusters)
- SMs(streaming multiprocessors,流多处理器)
- SPs(streaming processors,流处理器)
- SFU(Special Function Unit,特殊函数处理单元如sin,cos等
- Warp Schedular
- Core
- Dispatch Unit
- Thread
- ALU
- ROP(Render output unit)
- FB(Frame Buffer)
- Register File
- Rester Engine
......
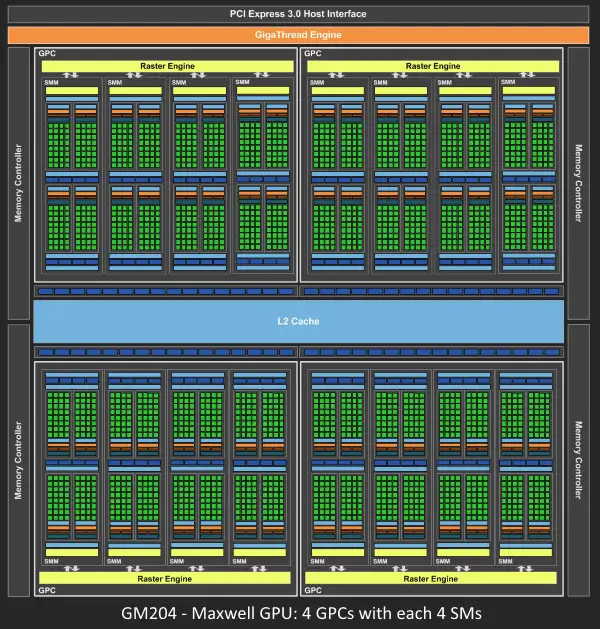
我们先简要记住,SPs是最基本的处理单元,也成为了CUDA core(compute unified device architecture),GPU进行并行计算也就是许多个SP同时进行处理。而多个SP加上其他一些部件(比如Warp Scheduler,register...)就组成了一个SM(每一代具体结构和core数量不一样),几个SM加上其他一些部件比如Raster Engine就组成了一个GPC。比如Pascal架构的Nvidia GTX1080显卡有4组GPC,每组有5个SM(2×64个CUDA),共2560个CUDA(介于980和980Ti之间),ROPs数量为64,TMUs数为160。这是由硬件层面上的分类。

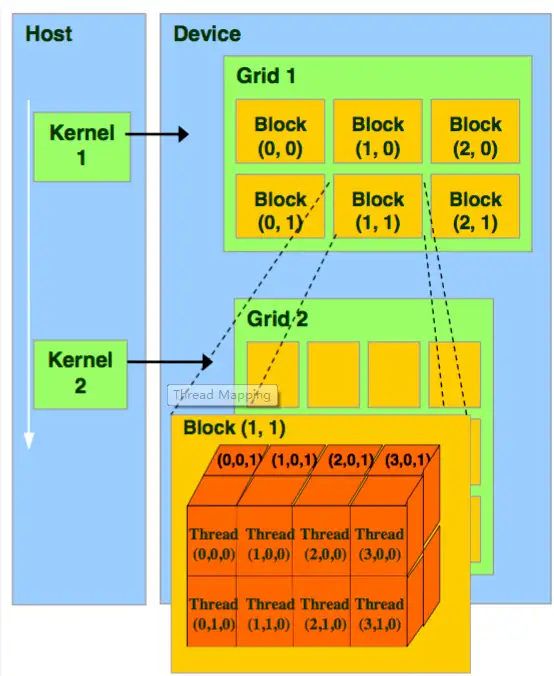
从软件上看,即GPU的线程模型,可以分为Grid,Block(Group),Tread,Warp,在Compute Shader的资源分配中理解这几个名词非常重要。
一个CUDA的并行程序会被分成许多个Thread来执行。许多个Thread会被划分成一个Block(Group),同一个Block(Group)中的Threads可以同步执行,可以通过Shared memory进行通信。多个Blocks再组成一个Grid。Warp是GPU执行程序时的调度单位,同一个Warp里面的Threads执行相同的指令,即SIMT(single instruction, multiple threads)。需要注意的是一般会分组分成三维的
如下图所示,GigaThread Engine管理所有正在进行的工作,GPU划分为若干个GPCs,而每个GPC又由若干个SMs和一个Raster Engine组成。在工作过程中各个部分会互相通信,比如GPCs会通过Crossbar互相传输数据。
而我们程序员所写的shader的执行是在SMs中完成的。SM中包含的许多cores为Threads任务执行数学运算,一个Thread既可以执行Vertex-shader也可以执行Pixel-shader。这些cores和其他单元会由Warp schedulers驱动(一般Nvidia32个Threads一个warp,AMD64个Threads一个warp),并把指令交由Dispatch Units执行,因此程序逻辑实际上是由scheduler掌握而不是core。相比于CPU的core,GPU的core算是很“笨”的。
3.GPU 的工作逻辑流水线(The Logic Pipeline)
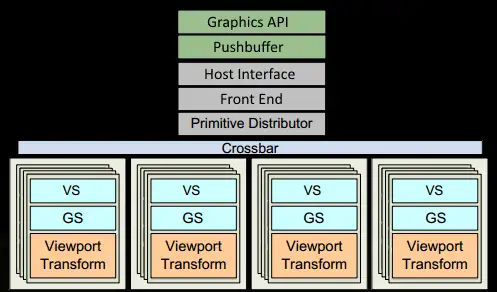
1.程序通过图形api(DX,glsl等)发出drawcall将其推送到驱动程序,在检查指令合法性后就塞入pushbuffer。很多时候性能瓶颈会在此时的CPU端发生,所以知道如何使用好api和利用好GPU强大的性能对于程序员来说是很重要的。
2.经过一段时间或显示地调用“flush”指令后,驱动会把pushbuffer的内容推送给GPU。GPU的The Host Interface接收到这些内容后将会由Front End处理。
3.我们会在Primitive Distributor中进行任务的分配–处理indexbuffer中的顶点索引生成三角形并分成若干批次(batch)发送到各个GPCs中。
接下来我们看看在GPCs中的其中一个SM是如何工作的
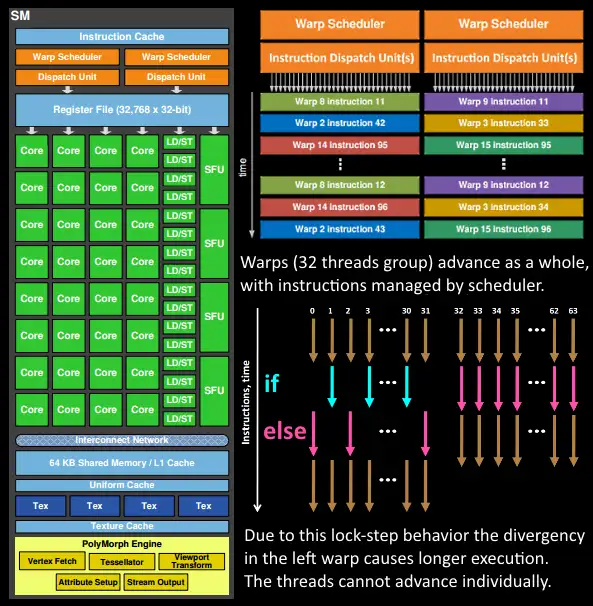
4.在某一GPC中,有许多SMs,在SM内,the poly morph engine会从三角形索引(triange indices)中获取顶点数据(图中Vertex Fetch模块)
5.获取完顶点数据之后,在SM内,以32thread一个warp为单位,来进行顶点处理的工作
6.SM中的warp scheduler将按顺序发送给warp,而warp中的threads会锁步执行各自的程序,如果有的thread因为某些原因不需要被激活将会被遮掩(masked out)。举个例子,在某个指令下有if-else语句,true分支执行,false分支不执行,或者某些thread执行循环的次数不一样,这样会显著拉长了整个warp的执行时间(先完成的等后完成的),因此这也是为什么shader里面不建议执行if-else语句的原因,除非整个warp都走同一个分支,即都是true或都是false。thread是不能独立执行指令的,必须以一个warp为单位。
7.warp的指令可能一次就完成也可能需要经过多次调度。举个例子,在SM中LD/ST(加载存取)单元数量通常少于数学操作单元。
8.由于某些指令需要更长的时间去完成,特别是内存加载,warp scheduler会简单地由一个warp切换到另一个没有在等待内存加载的warp。这就是GPU克服内存读取延迟的关键,只是简单地切换线程组。为了使这种切换非常快,warp scheduler管理的所有warp在寄存器文件(register-file)中都有自己的寄存器(register)。这里就会有个矛盾产生,shader需要越多的寄存器,就会给threads/warps留下越少的空间,就会产生越少的warp,这时候在碰到内存延迟的时候就会只是等待,而没有可以运行的warp可以切换。
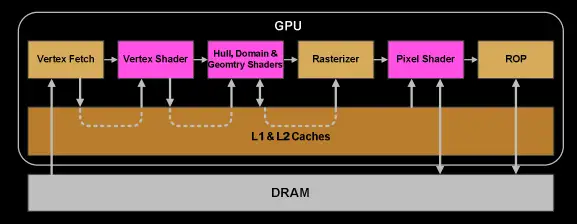
9.一旦warp完成了所有vertex-shader和pixel-shader的指令后,计算结果将会被Viewport Transform模块处理,三角形被剪裁完成后就准备进入光栅化。我们会使用L1和L2缓存让Vertex-shader和pixel-shader之间传输数据。
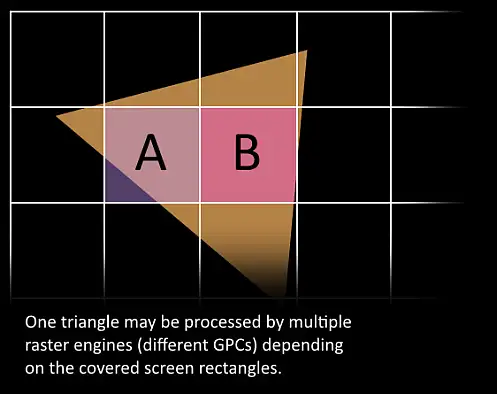
10.接下来,三角形会被分割并通过Work Distribution Crossbar分配给一个或多个GPCs取决于此三角形覆盖的“tile”。屏幕空间被划分为了若干个tile,由不同的raster engine负责,因此三角形可能会因为覆盖了不同的tile而分别被不同的raster engine处理。如此一来,我们将三角形划分成许多的小任务来高效处理。
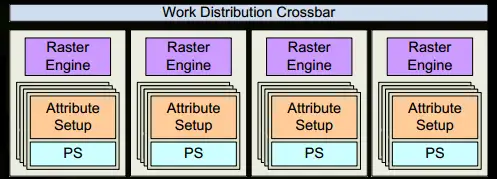
11.Attribute Setup保证了vertex-shader计算结果的插值是pixel-shader可读的格式。
12.GPC上的Raster Engine处理它收到的三角形并生成相关的像素信息,同时也会处理背面剔除,Early-Z剔除。
13.同样地,我们把32个处理像素的线程分成一组(batch up),更准确的说,是8个2x2的像素块,这是我们在pixel-shader中处理的最小单位。因为2x2的像素块方便我们导数计算(derivative),比如纹理的mipmap计算。如果2x2中像素块没有被三角形覆盖那么它们的thread将会被遮掩(masked out),SMs中的warp schedulaer会负责管理任务。
14.接下来pixel-shader中的步骤逻辑与vertex-shader中是一样的。

15.最后一步,pixel-shader已经完成了颜色和深度值得计算,在把数据传送到其中一个ROP子系统(render output units subsystem)一个ROP子系统内部有若干ROP单元之前,我们必须考虑到原来图形api的输入顺序。在ROP中我们会进行深度测试,颜色blending等像素操作,这些操作必须是原子操作(单个像素)来保证我们不会出现在某一像素中是这个三角形的颜色却是另一个三角形的深度值。
至此,GPU就将一些像素“画”在了rendertarget上,这就是GPU大概的workflow。
参考资料:
1.https://developer.nvidia.com/content/life-triangle-nvidias-logical-pipeline
2.https://developer.nvidia.com/blog/maxwell-most-advanced-cuda-gpu-ever-made/
3.http://download.nvidia.com/developer/cuda/seminar/TDCI_Arch.pdf
4.https://www.cnblogs.com/timlly/p/11471507.html#42-gpu%E9%80%BB%E8%BE%91%E7%AE%A1%E7%BA%BF


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?