

Render Path渲染路径
写在前面:
本文章为个人学习笔记,方便以后自己复习,也希望能帮助到他人。
由于本人水平有限难免出现错误,还请评论区指出,多多指教。
部分图元和素材来源于网络,如有侵权请联系本人删除。
参考资料与链接会在文章末尾贴出。
=======================================================================
两个基本的渲染路径为前向渲染(Forward Rendering)和延迟渲染(Deferred Rendering),以unity为例,在shader,camera,graphic setting中均可设置。
1.前向渲染
我们在主相机中设置rendering path为Forward
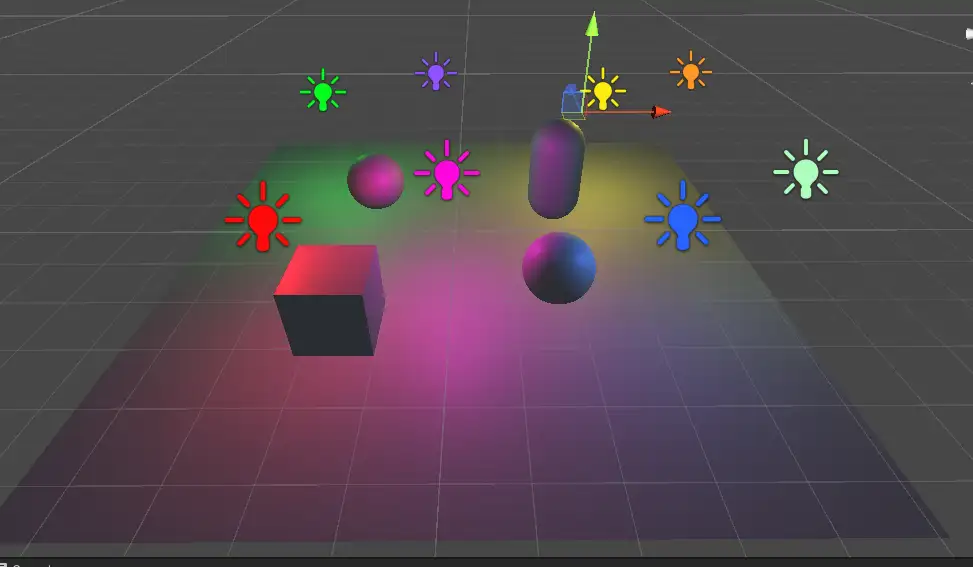
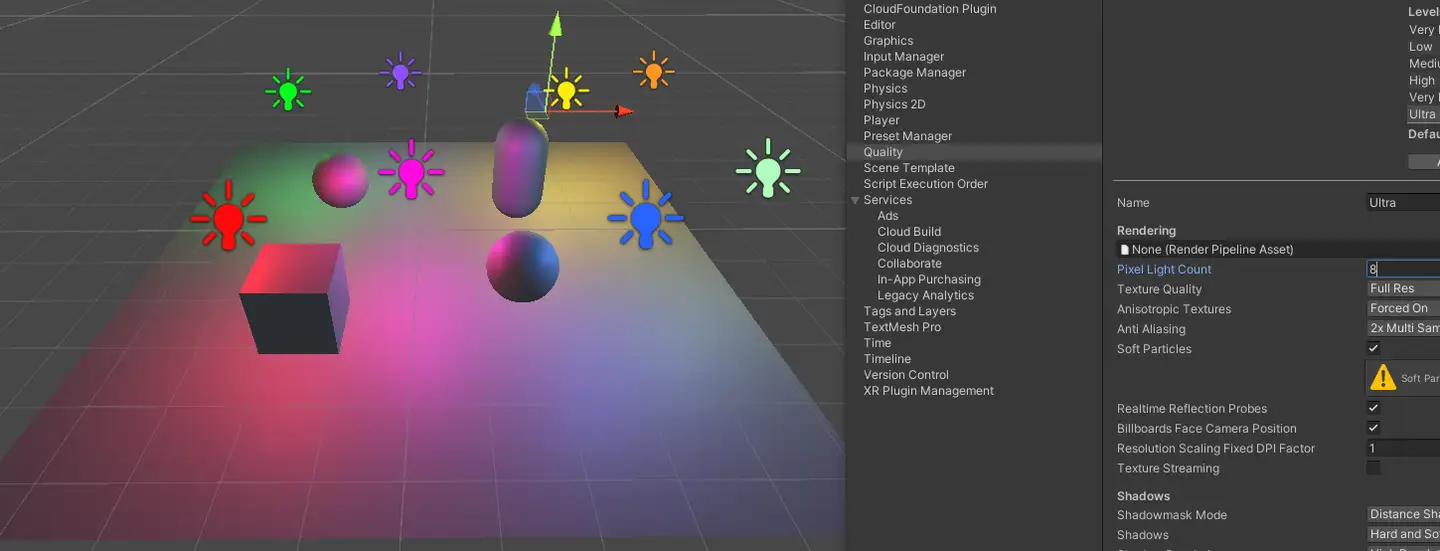
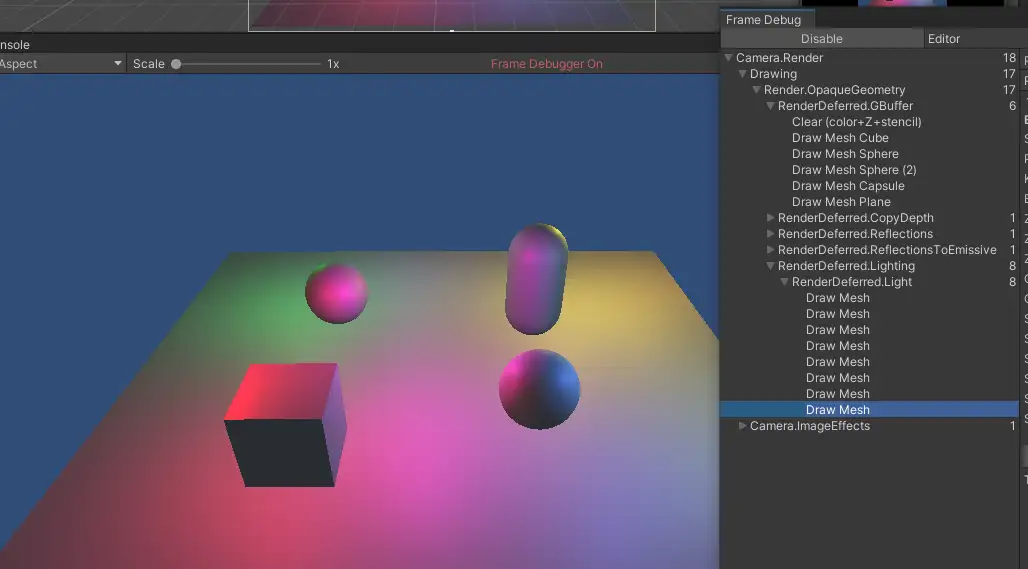
先直接上图看效果,场景中有4个点光源5个unity primitive。可以看到模型都或多或少,或近或远地受到不同颜色的点光源影响

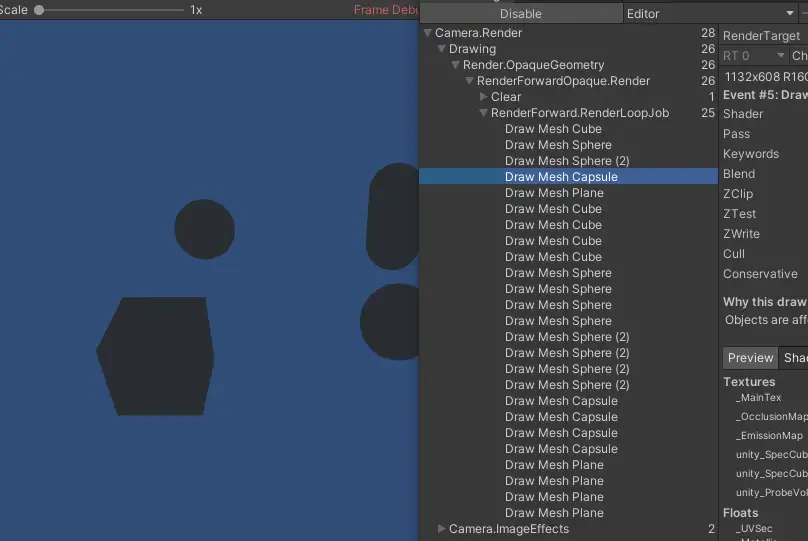
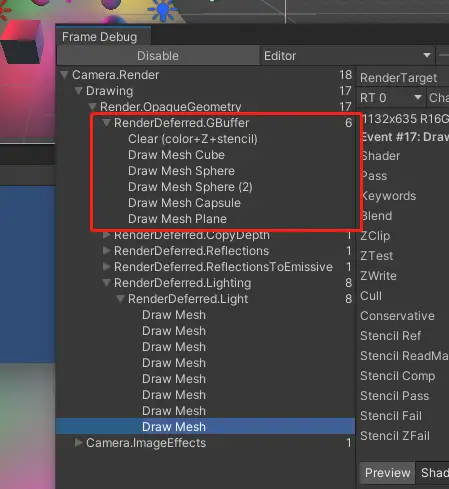
那么这个场景是怎么绘制,以什么样的顺序绘制出来的呢?我们可以在window->analysis→frame debugger中查看,我们重点关注RenderLoopJob中的绘制工作。以左下角的cube为例,我们发现一个cube居然被绘制了5遍,开头每个primitive被绘制了一遍,然后cube被连续绘制了4遍,这是怎么回事呢?我们点击这几个cube绘制发现这几次绘制就像是给cube“上色”,如果一个点光源代表了一种颜色,那么这个绘制过程就简单理解为,先画一个没有颜色的cube然后第一个点光的颜色,然后是再画第二个点光的颜色......
由此我们可以发现一个规律,有多少个光源就是给物体上几次颜色,而且第二个物体还得再重复一遍.......如果m代表场景中的物体数量,n代表光源数量,那么我们可以得出在前向渲染中我们绘制一个场景需要绘制(m x n)遍。
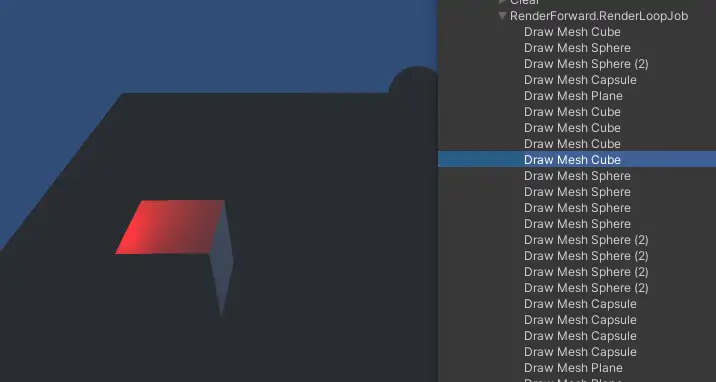
那么物体来了,当我们的场景有非常多的光源,非常多的物体时,GPU绘制的任务是很重的,尤其是有一些距离物体较远的点光源,可能对物体的影响微乎其微,如果把这一丢丢点光源对物体的贡献也加进去(玩家几乎不会注意到),这无疑是一种性能浪费。
我们继续试验一下,这次我们点光源数量翻倍,有八个。
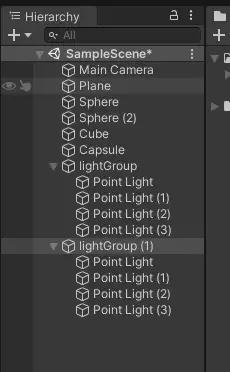
场景颜色明显有了变化,但却貌似没有变得“更亮了”,理论上来说灯光数量越多应该越亮。我们到frame deugger中查看发现,对某一模型的绘制次数依然是5遍而不是m x n=5 x 8=40遍,这与我们上面的结论不符。
原因是为了节省性能,unity将Pixel Light count的数量默认设置为4。简单记住unity中这三种光照计算,pixel light,vertex light ,SH光照(shperical harmonics,球谐光照),在一般模型顶点数不够高的情况下,光照质量依次降低。光照质量越高意味着计算消耗越大,因为unity对这三种光照的默认设定是:
在built-in管线中
1.场景中最亮的光照为pixel light
2.对某一光源light mode设置为important的为pixel light
3.在不超过pixel light count设置的情况下,按照对物体的光照贡献(比如intensity ,distance等)设置贡献最大的几个光源为pixel light
4.之后的光源为vertex light,最多四个
5.之后的光源为SH光照
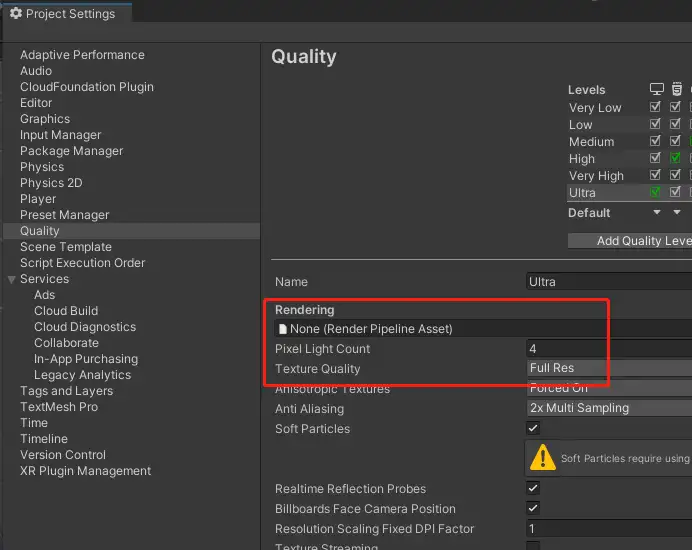
因此,当我们把pixel light count设置为8后,就能在frame debugger里面看到意料之中的绘制。
但是,更多光源更多消耗消耗这个问题我们应该怎么办呢?
2.延迟渲染
我们把主相机设置成Deferrd在frame debugger中发现,在8个pixel light的情况下,unity的RenderDefferdLighting只绘制了8次就完成了,且效果与forward一样。
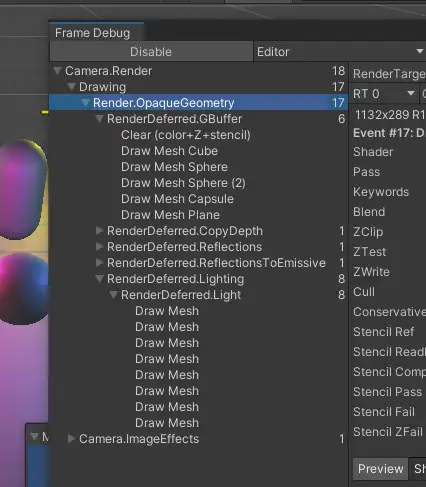
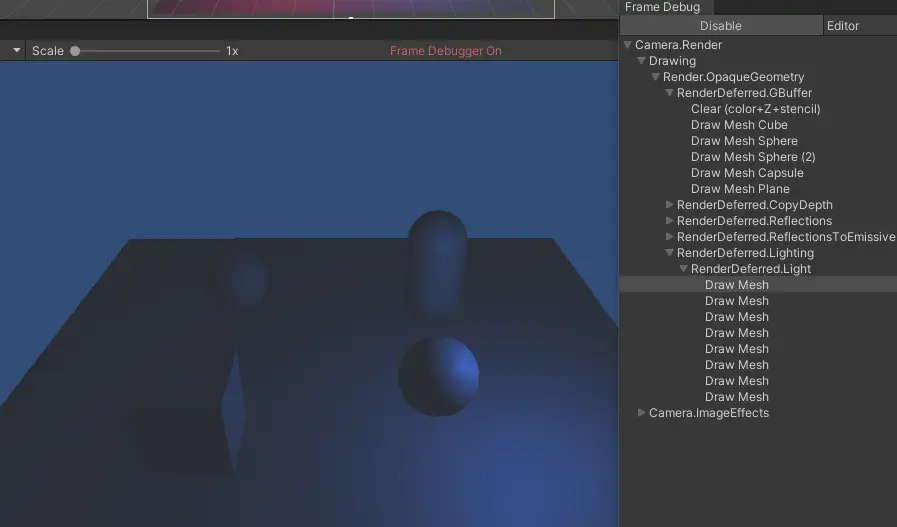
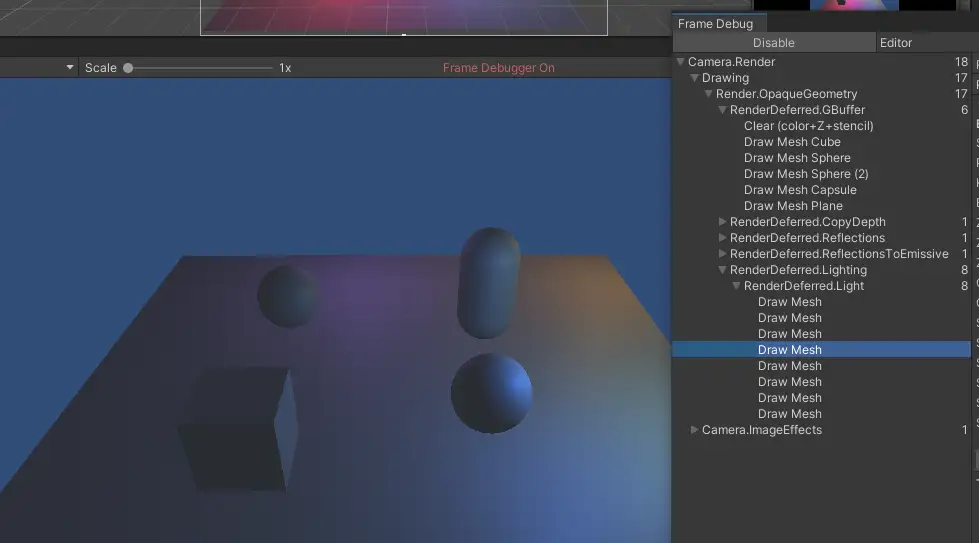
我们需要认识一下前向渲染与延迟渲染的原理和区别:
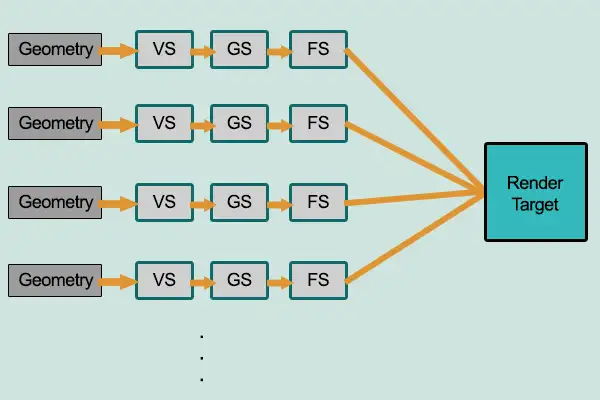
传统正向渲染的思路是先进行着色,再进行深度计算,而着色是先计算场景中所有光源对某一物体的贡献,再计算下一物体。假如场景中有1000个物体每个物体有100个三角面,场景中有100个光源,计算量是十分巨大的,况且有相当一部分物体是会被其他物体遮挡掉的(对于玩家不可见),这对性能又是一种浪费,计算复杂度前面提到过为O(m * n)。
而延迟渲染则会先把所有物体都先绘制到屏幕空间的缓冲(即G-buffer,Geometric Buffer,几何缓冲区)中,再逐光源对该缓冲进行着色,从而避免了因计算被深度测试丢弃的⽚元的着色而产⽣的不必要的开销。也就是说延迟渲染基本思想是,先执行深度测试,再进行着色计算,将本来在物空 间(三维空间)进行光照计算放到了像空间(二维空间)进行处理。由此一来,无论场景中有多少物体和光源,我们计算复杂度都变成了O(m + n)。
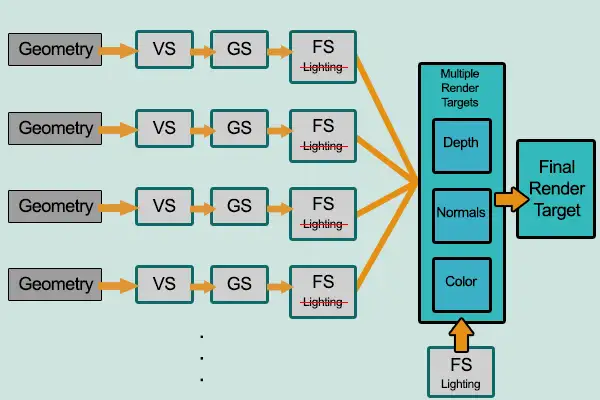
在Gbuffer里面我们可以保存世界空间坐标,法线,diffuse颜色,specular颜色等等,因此也需要硬件支持MRT(multi render target,一些旧硬件特别是移动端是不支持的)。此外,移动端游戏也比较少会有如此多灯光的场景,因此延迟渲染用的也。

此外,由于Gbuffer中包含了上述信息(还能塞其他信息进去),我们在做后处理(基于图像处理)的时候可以直接拿来用不用再算一遍,这也是一大优点。
当然,延迟渲染也是有它的缺点的:
1.对MSAA支持不友好,因为MSAA是硬件AA,在光栅化阶段计算某个像素的被覆盖率(而不是简单地1或0),比如50%,然后在pixel-shader里面计算着色结果*0.5。而在延迟渲染中,场景都先被光栅化到GBuffer上去了,不直接做shading。
2.渲染透明物体存在问题。因为延迟渲染根据场景可见性将信息渲染到Gbuffer中,而渲染不透明物体往往是关闭了深度写入。因此一般是延迟渲染不透明物体后,再用前向渲染的方法渲染透明物体。
3.Gbuffer占用带宽问题。如上面提到Gbuffer即记录了当前场景一系列信息,虽然可以根据具体情况自行设计buffer内容,但是带宽占用依旧不小。简单算术题1920*1080(渲染分辨率) * 4(RGBA通道)* 8(bits) * 4(MRT,包括position,normals,albedo,specular)* 60(FPS)≈1.8GB/s。
4.只能用同一个光照pass。当场景可见性信息都渲染到Gbuffer后已经不知道哪一个像素点是哪一个mesh,只能套用同一个光照模型计算,而前向渲染中则可以不同物体用不同的光照计算,不过基本上在同一场景也不会有不一样的光照,反而是要求场景内光照统一。
