
实验室每日一题wp
题目length3
打开压缩包发现是CRC碰撞题目
4位以内的自动化脚本,直接上~
1 # 自动读取爆破加密zip所有1-4字节文件CRC,输出文件名(密码段顺序)和结果 2 # 如果个别文件爆破失败,修改multiCrack中dic字典变量即可 3 from zipfile import ZipFile 4 import itertools, binascii 5 6 def permutations_with_replacement(szDic, k): 7 result = [] 8 for i in itertools.product(szDic, repeat = k): 9 result.append(''.join(i)) 10 return result 11 12 def multiCrack(iSize,lCrcs): 13 #dic = '''abcdefghijklmnopqrstuvwxyz0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ!-@_{}''' 14 dic = '''abcdefghijklmnopqrstuvwxyz0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~ ''' 15 dResult = {} 16 mydic = permutations_with_replacement(dic,iSize) 17 for i in mydic: 18 txt = "".join(i) 19 crc = binascii.crc32(txt.encode()) 20 if str(crc) in lCrcs: 21 print(hex(crc)+" "+txt) 22 dResult[str(crc)] = txt 23 return dResult 24 25 def crack(lFilesCRC): 26 lResult = [] 27 iSizes = set([int(i.split('|')[1]) for i in lFilesCRC]) 28 for iSize in iSizes: 29 lCrcs = [i.split('|')[2] for i in lFilesCRC if i.split('|')[1]==str(iSize)] 30 dTMP = multiCrack(iSize,lCrcs) 31 for k,v in dTMP.items(): 32 for i in lFilesCRC: 33 if i.find(k)>0: 34 lResult.append(i+" "+v) 35 return lResult 36 37 if __name__ == "__main__": 38 myzip = ZipFile(r"length3.zip") 39 fInfos = myzip.filelist 40 lFilesCRC = [] 41 for i in range(len(fInfos)): 42 fInfo = fInfos[i] 43 if fInfo.file_size < 5: 44 # 格式“文件名|原始大小|CRC”——如“1.txt|4|3463500836” 45 lFilesCRC.append(fInfo.filename + '|' + str(fInfo.file_size) + '|' + str(fInfo.CRC)) 46 print(sorted(crack(lFilesCRC)))
获得1-6txt 明文为:50 51 67 95 99 114
直接转acill可得:23C_cr
坑人啊,解压不对,折磨死我这个萌萌哒的脑袋瓜儿~
最后问出题人得知是:Crc_32
哎呀妈耶,激动的心,颤抖的手,终于解压成功了,啊这,他还开了个玩笑
对二维码图片使用lsb分析,我使用了 StegSolve.jar
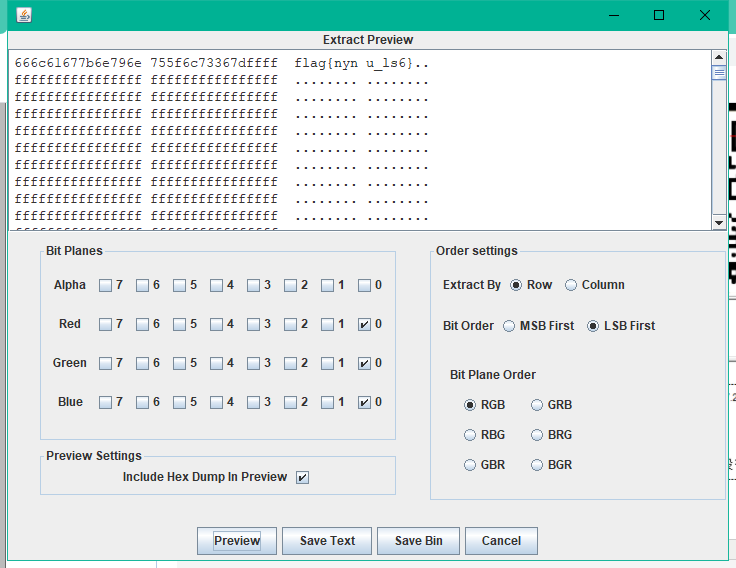
得到flag。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号