
推荐系统(二)
2024.12.18 update,百度推荐中台三面后六天挂了
排序详解
用户-笔记的交互:点击率、点赞率、收藏率、转发率
排序的依据:预估点击率、点赞率、收藏率、转发率 + 融合这些预估分数 + 根据融合的分数做排序和阶段
-
多目标模型(工业界普遍使用的模型)
-
模型结构:把用户特征、物品特征、统计特征、场景特征作为输入,输出对各个指标的预估(即前文所说的点击率,点赞率,收藏率,转发率)以此反应出用户对物品的兴趣
-
用户特征:用户ID,用户画像
-
物品特征:物品ID,物品画像,作者信息等
-
场景特征:用户所在地点,点击的时间等
-
-
负样本降采样
-
解决问题:类别不平衡,比如每100次曝光,有10次点击,90次无点击
-
解决方案:保留一部分负样本,让正样本数量平衡,节约计算
-
-
-
融合预估分数
-
简单的加权和
-
点击率 x 其他项的加权和
-
-
图文排序 vs 视频排序
-
图文排序的一句:点击、点赞、收藏、转发、评论
-
视频排序:播放时长和完播率
-
-
排序模型所用特征
-
用户画像:用户ID,人口统计学属性(性别、年龄),账号信息(新老用户与活跃度),用户感兴趣的话题
-
物品画像:物品ID,发布时间,所在城市(GeoHash),标题,类目,关键词,品牌,字数,图片数,标签数,图片美学等
-
用户统计特征:用户最近30天、7天的曝光数,点击数,点赞数,收藏数;按照笔记图文和笔记视频分桶来判断用户对图文还是对视频更感兴趣
-
笔记统计特征:笔记最近30天、7天、1天的曝光数,点击数,点赞数,收藏数;按照用户性别分桶,按照用户年龄分桶等;作者特征:发布笔记数,粉丝数,消费指标等
-
场景特征:用户定位地点,当前时刻,是否是周末,是否是节假日,手机品牌,手机型号,操作系统(安卓用户和苹果用户的兴趣差异很显著)
-
-
数据服务
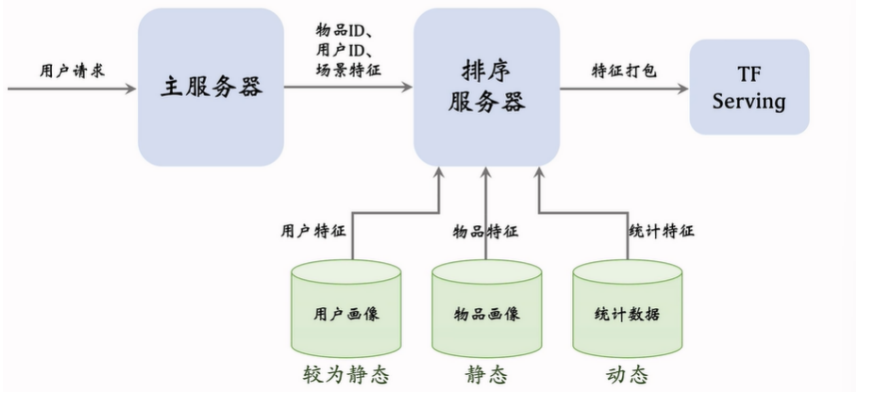
-
线上服务中大概的系统架构如上图所示
-
排序服务器需要从三个数据源中获取到数据,用户画像数据源压力比较小,而物品画像数据源压力比较大,因为需要召回、排序取到几千篇笔记(所以一般不建议在物品画像数据源中存过大的向量)
-
对于用户画像和物品画像来说,时效性不大,最关键的是读取的速度,因此有时候甚至可以将它们缓存在内存中来进行读取的加快
-
物品冷启动
什么是物品冷启动?
:如何对新发布的物品做分发,比如b站用户新上传的视频,微信公众号新发布的文章等等;其中以UGC的物品冷启最为困难,即用户发布的物品的分发
之所以要特殊对待新笔记原因如下:
-
新笔记缺少与用户的交互,导致推荐的难度大,效果差
-
扶持新发布、低曝光的笔记,可以增强作者发布意愿
想要达到的目标有:精准推荐;激励发布;挖掘高潜
UGC 平台的物品冷启动主要考察三种指标:
-
作者侧指标
-
包括发布渗透率(当日发布人数/日活人数)、人均发布量(当日发布笔记数/日活人数)
-
反应作者的发布积极性,经验上发现,新笔记获得的曝光越多,首次曝光和交互出现得越早,作者的发布积极性就越高
-
-
用户侧指标
-
包括大盘消费指标(大盘的消费时长、日活、月活,避免冷启动损害大盘消费指标,因为冷启动会大力扶持低曝光笔记,带来不好的用户体验)和新物品消费指标(新物品的点击率、交互率)——》分别考察高曝光和低曝光的新笔记,并在其中尤其注重低曝光笔记的冷启动优化
-
-
内容侧指标,比如高热物品占比
冷启动的召回通道:
-
冷启动召回的难点:缺少用户交互,还没有学好笔记ID embedding,导致双塔模型效果不佳,且缺少用户交互会导致ItemCF不适用
-
双塔模型改造:
-
改进方案1:让新笔记做default embedding,让物品塔做ID embedding时,让所有新笔记共享一个ID,直到下一次模型训练时才使用笔记自己的ID
-
改进方案2:查找topk内容最相似的高曝光笔记,把k个高曝笔记的embedding向量取平均,作为新笔记的embedding
-
-
类目召回
-
兴趣平台都会记录一些用户画像中感兴趣的类目和标签,可以基于类目来做召回
-
系统会维护一个类目->笔记列表(按照时间倒排)的索引;用类目索引做召回时,取回笔记列表的前topk篇笔记
-
同理还有关键词召回等等
-
缺点在于:只对刚刚发布的新笔记有效;弱个性化,不够精准
-
-
聚类召回
-
基于物品内容的召回通道
-
它假设如果用户喜欢一个物品,那么用户会喜欢内容相似的其他物品。
-
事先训练一个多模态神经网络,将笔记图文表征为向量,并对向量做聚类,然后建索引
-
-
look-Alike召回
-
look-Alike起源于互联网广告,比如说 统计发现购买特斯拉的用户基本都是 25-30岁+大学本科以上+对科技数码感兴趣+喜欢电子产品,那么在投递广告时会把特斯拉的广告投递到满足这些特征的人群,这些人群就叫做种子用户
-
种子用户的数量可能不是很多,通过look-Alike做人群扩散,找到与种子用户相似的用户,对他们一起做广告投放
-
-
找到对新笔记感兴趣的用户,这些作为种子用户,然后取回他们的用户向量取到一个均值,来作为这篇新笔记的特征向量,每当由用户交互时,随时更新这个特征向量;线上召回时,当有用户刷新时,就用这个用户的用户向量在向量数据库中做最近邻查找,找到最邻近它的新笔记
-
本文作者:pinoky
本文链接:https://www.cnblogs.com/pinoky/p/18615852
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步