IO多路复用源码分析
IO多路复用源码分析
select源码分析
select函数可以同时监听多个文件描述符,当某个文件描述符就绪时,select函数返回,程序可以通过遍历文件描述符集合来确定哪些文件描述符已经就绪,随后可进行相应的操作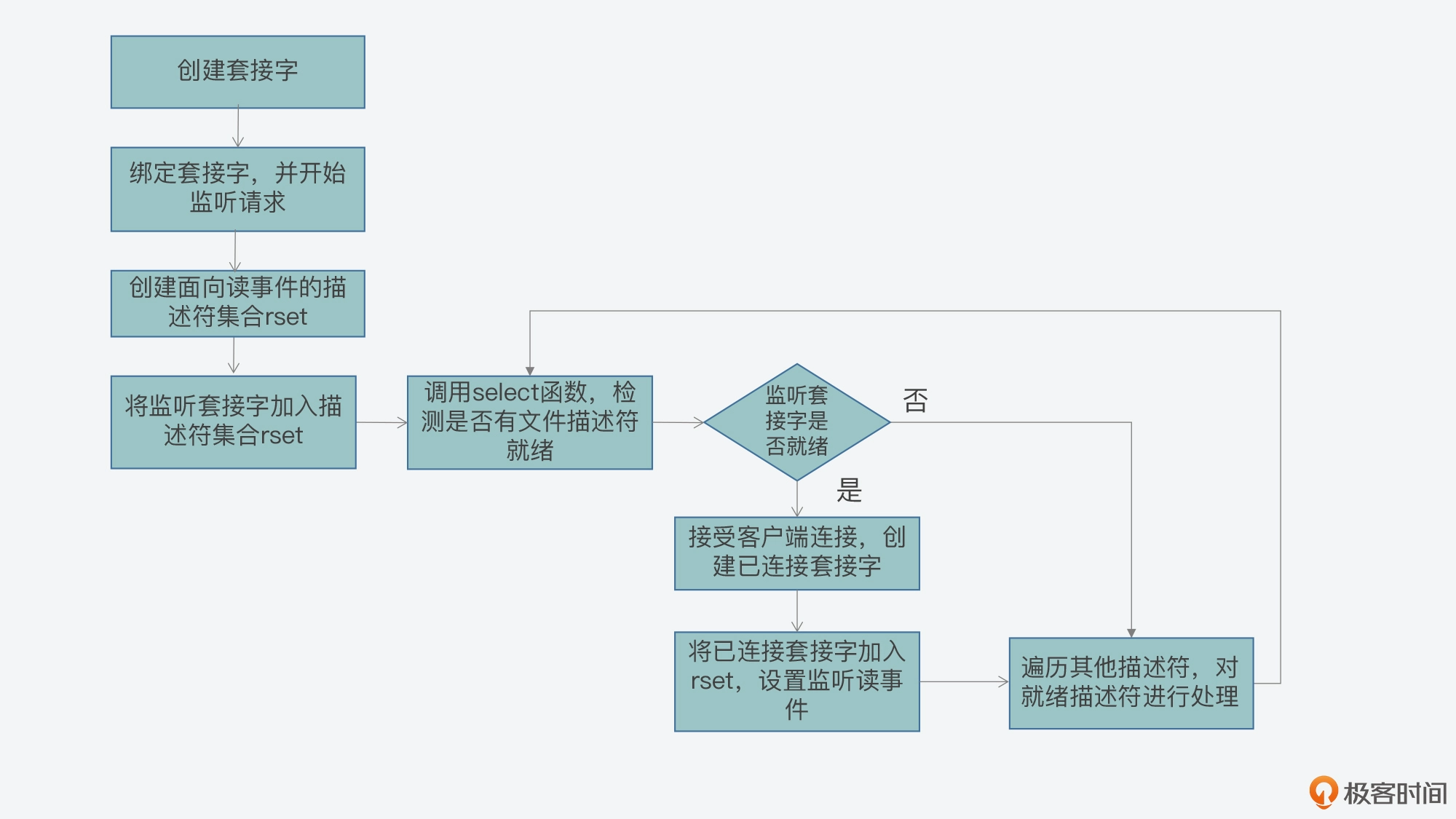

fd_set rfds;
FD_ZERO(&rfds_storage); //清空位图
FD_SET(sock_fd, &rfds_storage); //设置位图
struct timeval tv = {.tv_sec = 5, .tv_usec = 0}; //设置超时时间
ret = select(max_fd + 1, &rfds, NULL, NULL, &tv);
//成功则返回检测到的文件描述符数量,失败返回-1,超时返回0
select的关键是位图
从用户的视角来看:用户首先调用FD_SET,将文件描述符注册到读、写、异常位图上(即将特定位置设置为1),然后通过select函数轮询位图中的读、写、异常事件
select底层轮询获取读写异常位图中注册的socket文件事件,若有就绪状态的socket文件,则将其对应的事件设置到输出位图,直到所有socket轮询完,会统一将输出位图通过copy_to_user复制到输入位图并覆盖输入位图的信息(所以每次执行select之前都要重新FD_ZERO,FD_SET),同时超时时间的剩余时间也覆盖原来的超时时间(所以每次执行select之前都要重新设置超时时间)

select的位图定义如下:
typedef __kernel_fd_set fd_set;
typedef struct {
unsigned long fds_bits [__FDSET_LONGS]; //定义一个数组
} __kernel_fd_set;

位图最多有1024位,这也就是为什么select最多只能监听1024个文件描述符的原因
select底层主要依赖的函数有两个:core_sys_select和do_select
- core_sys_select:设置好位图对应的内存空间,把应用层的监听集合拷贝到内核中,然后调用do_select阻塞,直到满足条件时返回后,将结果拷贝回应用层
- do_select:遍历所有文件描述符,第一遍遍历调用
(*f_op->poll)(file, wait)是为了为每一个文件描述符申请一个等待队列元素,将其添加到对应驱动程序的等待队列中,然后会睡眠等待,当有条件满足时,对应的驱动会通过等待队列唤醒该进程,然后进行第二次遍历,此时对于有事件发生的文件描述符会得到一个掩码,然后设置好每一个文件描述符状态,退出
- 为什么要传入最大文件描述符:select使用1024比特位图监测最多1024个文件描述符,然而实际的情况很少会到达1024文件描述符上限,使用maxfd可以避免每次都轮询1024个文件描述符,从而提高轮询效率。maxfd通常设置为已打开最大文件描述符+1,目的是为了保证位图中每个文件描述符都被轮询到
- select优点:支持多种文件描述符,跨平台
- select缺点
- 每次调用select都要将所有位图从用户态拷贝到内核态,返回后还要遍历所有文件描述符找到就绪的文件,都比较耗时
- 最大的文件描述符数量为1024,无法满足高并发应用场景,假设我们的服务器需要支持100万的并发连接,则在__FD_SETSIZE 为1024的情况 下,则我们至少需要开辟1k个进程才能实现100万的并发连接。除了进程间上下文切换的时间消耗外, 从内核/用户空间大量的句柄结构内存拷贝、数组轮询等,是系统难以承受的。因此,基于select模型的 服务器程序,要达到100万级别的并发访问,是一个很难完成的任务。
- select采用轮询的方式获取读,写,异常事件,轮询的方式效率低,不管文件事件是否就绪,都需要去做检测
- select的触发方式是水平触发,应用程序如果没有完成对一个已经就绪的文件描述符进行IO操作, 那么之后每次select调用还是会将这些文件描述符通知进程
poll源码分析
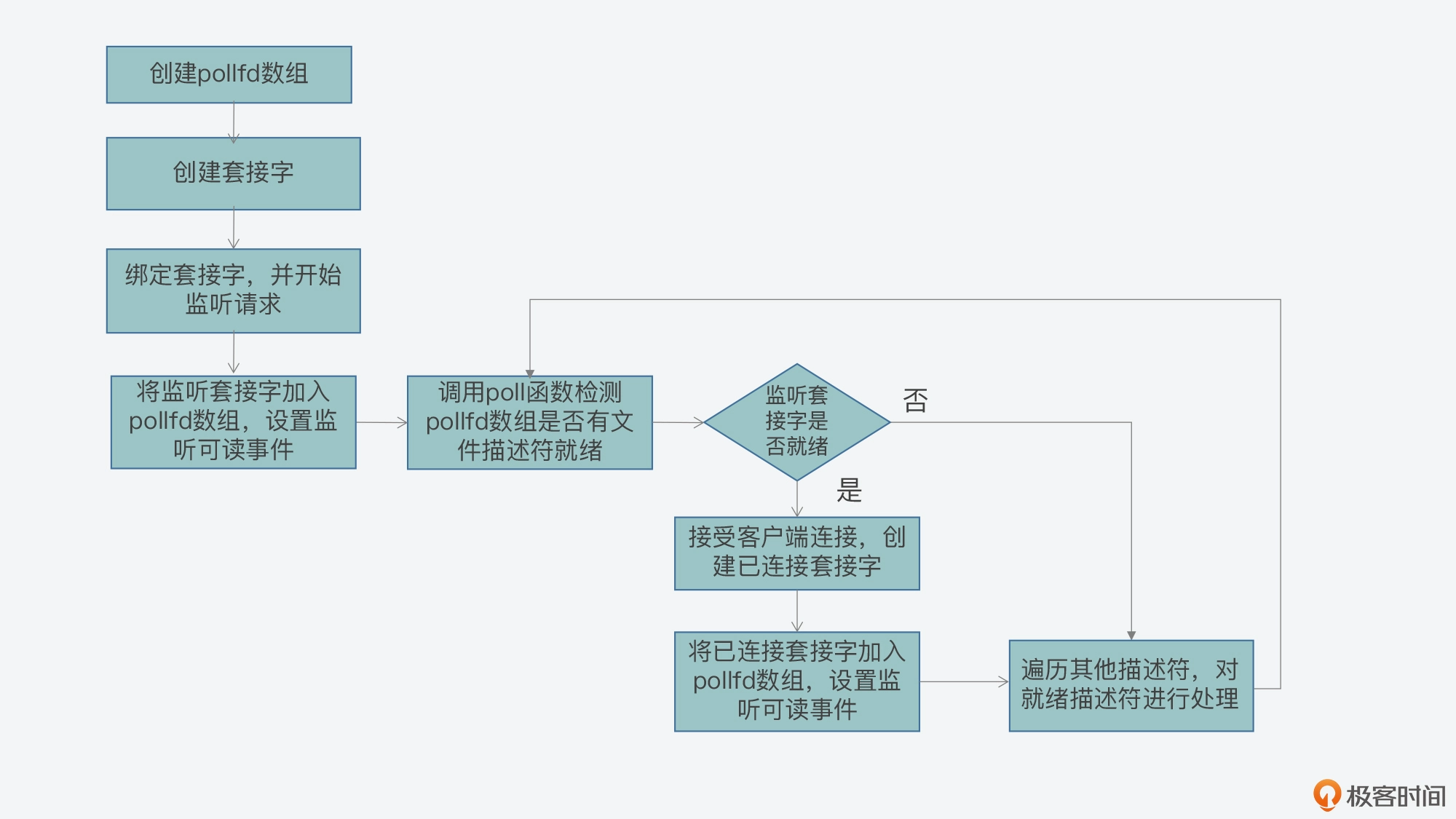
int poll(struct pollfd *fds, nfds_t nfds, int timeout); //poll函数原型
//传递pollfd数组,数组数量和超时时间
struct pollfd fds[MAX_FD];
memset(fds, 0, sizeof(fds));
fds[0].fd = 0;
fds[0].events = POLLIN;
int nfds = poll(fds, MAX_FD, -1);
//包含要监听的描述符,和该描述符上要监听的事件类型
struct pollfd {
int fd; //进行监听的文件描述符
short int events; //要监听的事件类型
short int revents; //实际发生的事件类型
};
poll可以监听多个文件描述符,直到条件满足或超时时,就会返回
poll底层依赖的函数主要有:do_sys_poll 和 do_poll
-
do_sys_poll:在栈上定义一段内存用来存放用户层传递过来的pollfd数组的数据,然后定义一个poll_list指针指向上述内存(如果在栈空间上分配的内存不够会重新分配内存到堆上),之后执行do_poll,然后阻塞等待,直到条件满足后将得到的结果拷贝回应用层
与select的区别:select使用位图来维护文件描述符数据,所以有1024的限制;而poll使用链表来管理,内存不够了还能继续分配,故没有了最大文件描述符数量的限制

-
do_poll:所做的事情与select中的do_select所做的事情相同,第一次遍历为每个文件描述符申请一个等待队列项并加入到驱动程序的等待队列头中(此时poll处于睡眠状态)
直到驱动程序唤醒等待队列时,poll唤醒并第二次遍历所有的文件描述符,调用驱动程序的poll函数获得一个掩码,掩码值不为0则代表着有一个就绪事件,count++
poll优点:相比select没有了监视文件数量的限制,但其他三个缺点仍然存在
epoll源码分析
首先epoll机制是使用epoll_event结构体用来记录待监听的文件描述符以及监听的事件类型的
typedef union epoll_data
{
...
int fd; //记录文件描述符
...
} epoll_data_t;
struct epoll_event
{
uint32_t events; //epoll监听的事件类型
//常见的事件类型有:EPOLLIN读事件表明文件描述符有数据要读,EPOLLOUT写事件,EPOLLERR错误事件
epoll_data_t data; //应用程序数据
};
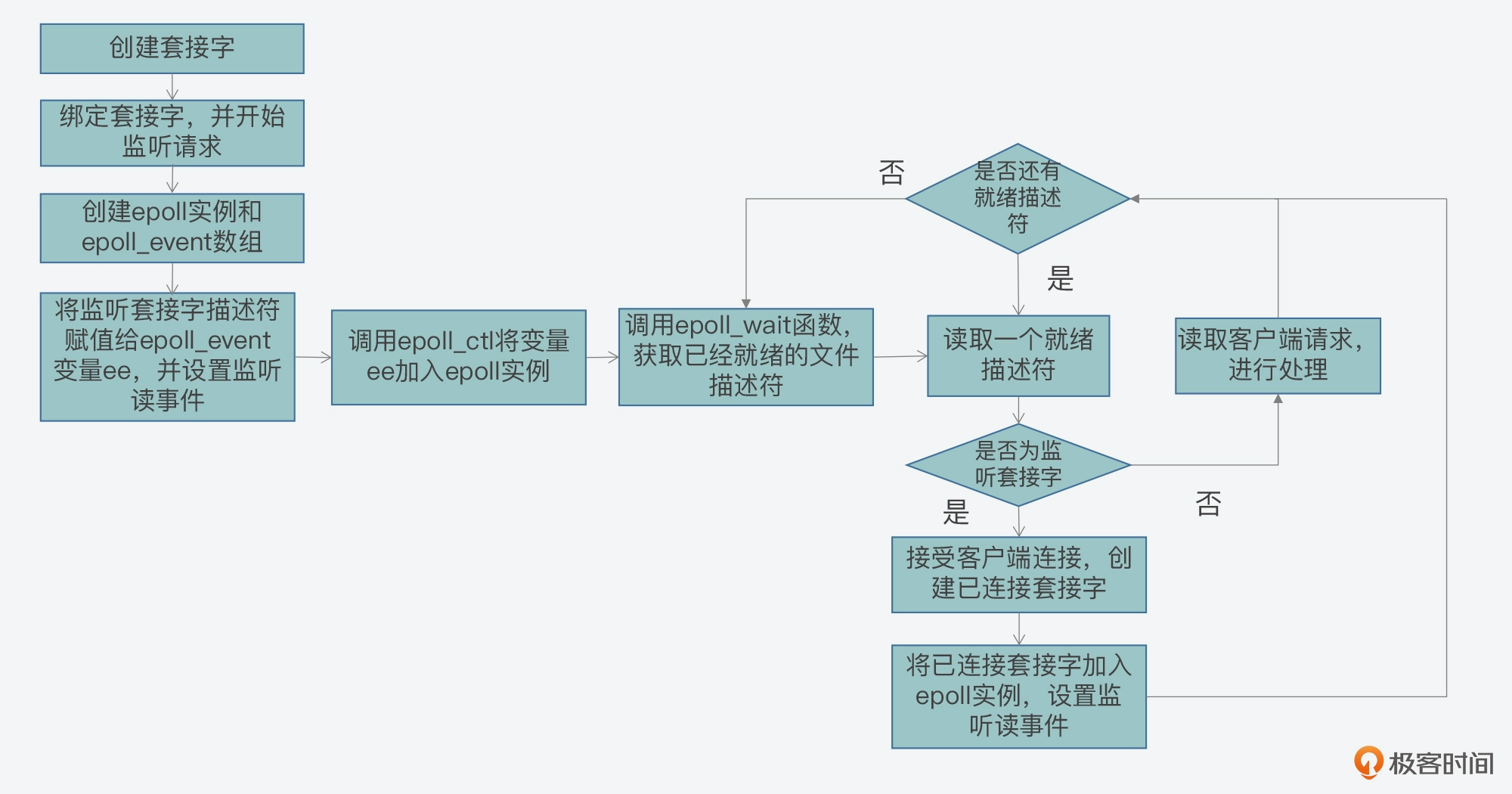

epoll的实现机制是通过内核与用户空间共享一个事件表,这个事件表中存放着所有需要监控的文件描述符以及它们的状态,当文件描述符的状态发生变化时,内核会将这个事件通知给用户空间,用户空间再根据事件类型进行相应的处理
int epoll_create(int size); //创建epoll文件描述符

它用于申请一个epoll文件描述符放回到用户空间,同时申请一个eventpoll结构体,用来管理epoll事件
- 等待队列和就绪队列:存放等待事件和就绪事件的fd
- 红黑树:存放被监视的文件描述符以及与之相关的事件信息,用于快速定位和管理这些文件描述符
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
/* 增加、删除、修改epoll事件
epfd是用create产生的fd
op是操作码(EPOLL_CTL_ADD, 、EPOLL_CTL_DEL, EPOLL_CTL_MOD)
event是epoll_event结构体,存放epoll事件与文件描述符 */

主要分析一下插入事件时发生了什么:
- 调用ep_insert,首先它会添加等待队列元素到驱动的socket等待队列中,并且初始化驱动唤醒eventpoll中等待队列所用的回调函数ep_poll_callback
- 将epoll事件添加到红黑树当中
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
/* 用于监听epoll事件
epfd:epoll文件描述符,
events:epoll事件数组,
maxevents:epoll事件数组长度
timeout:超时时间 */

- sys_epoll_wait调用ep_poll
- ep_poll定义等待队列元素,并添加到eventpoll的等待队列中,等待唤醒
- 然后ep_poll通过schedule_hrtimeout_range进入睡眠等待模式
- 当IO准备就绪时,即驱动程序判断到socket收到数据后,会唤醒socket等待队列项,然后执行回调函数ep_poll_callback
- ep_poll_callback在回调函数中将就绪epoll事件节点添加到epoll就绪队列中,然后唤醒epoll等待队列项进程(即ep_poll函数)
- epoll随后判断就绪队列若不为空则退出睡眠循环,然后调用ep_send_events获取就绪链表中epoll项的状态,并将事件状态拷贝到应用层
整个epoll机制流程总结如下:

LT模式水平触发和ET模式边缘触发的区别:
LT在epoll_wait获取完就绪队列epoll事件后,会再次将epoll事件添加到就绪队列,这样会让它一调用epoll_wait一直检测到epoll事件,直到socket缓冲区数据清空为止(用户层上看就是socket上有可读事件发生时,服务端会不断苏醒直到取走所有数据)
ET只会在缓冲区满足特定情况下才会触发epoll_wait获取epoll事件(用户层上看就是socket有可读事件发生时,服务端只会从epoll_wait苏醒一次,只有在第一次触发条件的时候传递信息,所以需要尽可能地将数据读完(否则不会再苏醒了)一般搭配非阻塞I/O使用,循环地从socket里读取数据,直到系统调用返回错误)
两者优缺点如下:
为什么epoll高效:
- eventpoll等待队列机制,当就绪队列没有epoll事件时主动让出CPU,阻塞进程,提高CPU利用率(epoll机制本身是阻塞的,通过出让CPU提高CPU资源利用率)
- socket等待队列机制,只有接收到数据时才会将epoll事件插入就绪队列,唤醒进程获取epoll事件
- 红黑树提高epoll事件增加,删除,修改效率
- 任务越多,进程出让CPU概率越小,进程工作效率越高,所以epoll非常适合高并发场景
- epoll_wait的效率也非常高,因为调用epoll_wait时,并没有 向操作系统复制这100万个连接的句柄数据,内核也不需要去遍历全部的连接
epoll机制下socket采用阻塞还是非阻塞:
epoll机制属于IO多路复用,特点是一个进程处理多个IO请求
采用非阻塞方式,如果采用阻塞方式进程同一时间只能处理一个socket数据,如果该socket阻塞会导致无法处理其他socket影响性能;且频繁的阻塞会导致CPU一直进行上下文切换,降低效率


 浙公网安备 33010602011771号
浙公网安备 33010602011771号