
日志系统
日志系统
redo log重做日志
redo log为InnoDB引擎特有的物理日志,记录了:“在某个数据页上做了什么修改” 的操作,循环写入,具备着占用空间小、顺序写磁盘的优点
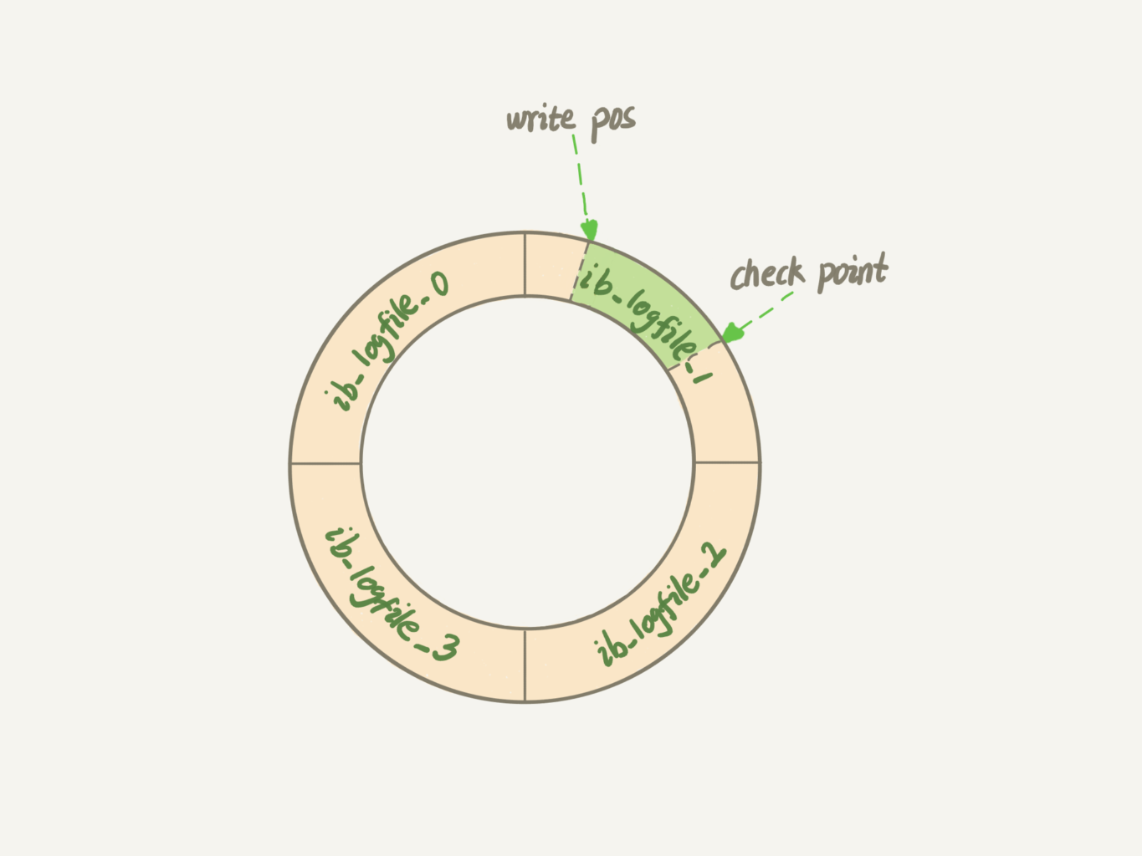
write pos作为当前记录的位置,一边写一边顺时针移动;checkpoint作为当前要擦除的位置,一边擦出一边顺时针移动,在擦除记录前要把数据落盘
write pos和checkpoint之间的空白 就可以用来记录新的操作,如果write pos追上了checkpoint,就需要停止更新,将记录落盘以推进checkpoint
通过redo log就能保证数据库异常重启后,之前提交的记录不丢失,即crash-safe
redolog的写入机制
在事务执行过程中,生成的日志会写入到redo log buffer,直到最终真正执行commit 的时候才会将redo log buffer中的日志写入到redo log文件中
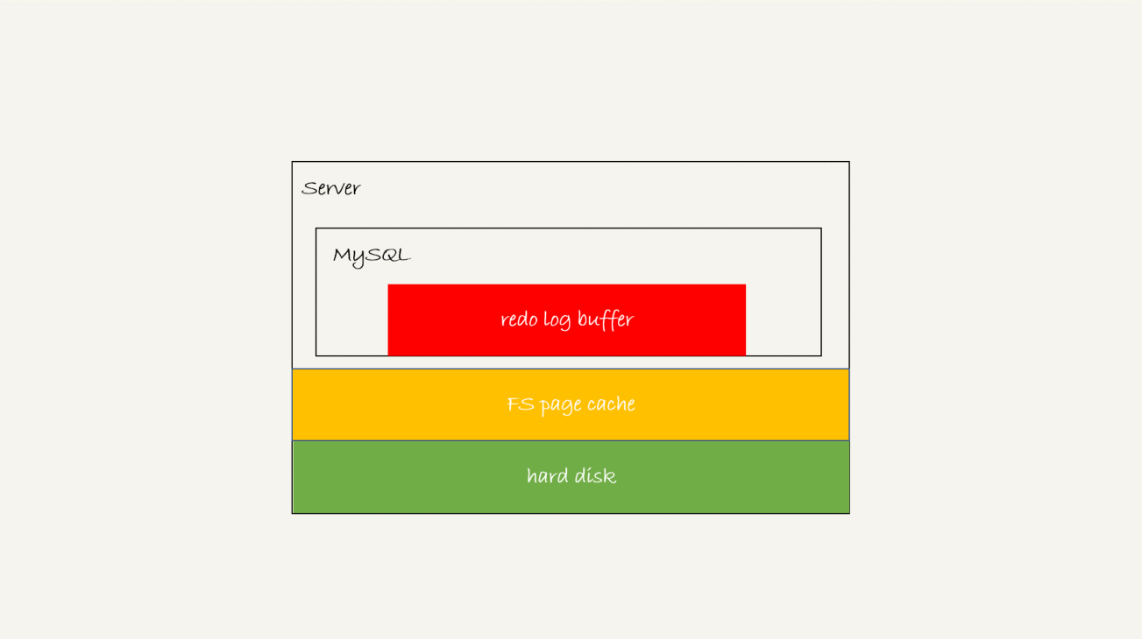
redo log可能有的三种状态:存在buffer中(内存);write到磁盘但没有fsync持久化(page cache);持久化(磁盘)
redo log写入到redo log buffer
在实际的过程中,redolog是以组的形式写入到redo log buffer中的,即是以一个mtr里所有的redo日志为基本单位整体写入的
每组redo日志都对应着一个LSN值,即日志逻辑序列号,表示当前系统写入buffer中 的redo log量(LSN = 当前所占用的所有redo log buffer的空间总和),每次写入长度为length的redo log,LSN的值就会再加上length,它也会被写入到InnoDB数据页中,用来确保数据页不会多次执行重复的redo log
如果有多个并发事务,当trx1开始写盘时,此时组里已有trx2和trx3(LSN=160),那么trx1写盘时带的值就是LSN=160(此时的redo log buffer里面已经包含到LSN=160的redo log了);因此等trx1返回时,所有LSN<160的redo log已经被持久化了,这时候的trx2和trx3可以直接返回
在这种组提交机制下,组员越多,节约磁盘IOPS的效果越好,
redo log buffer刷盘到磁盘
事务执行期间如果MySQL发生异常重启,则redo log buffer会丢失其中的redo log,但由于事务没有提交,所以丢失redo log并没有影响
InnoDB有一个后台线程,每隔1秒就会把redo log buffer中的日志,调用write写入到文件系统的page cache,然后调用fsync持久化到磁盘
由于事务执行过程中的redo log也会直接写在redo log buffer中,这些redo log也会被后台线程一起持久化到磁盘,所以一个没有提交事务的redo log也有可能已经持久化了
同时,redo log buffer 占用的空间即将达到 innodb_log_buffer_size 一半的时候,后台线程会主动写盘,且并行的事务提交的时候,顺带将这个事务的 redo log buffer 持久化到磁盘
可以通过参数innodb_flush_log_at_trx_commit控制redo log写入策略
- = 0:每次事务提交只是把redo log 留在 redo log buffer
- = 1:每次事务提交都将redo log 持久化(在两阶段提交中的prepare阶段 即 fsync,commit阶段只write)
- = 2:每次事务提交都只把redo log写到page cache
binlog归档日志
binlog是MySQL的Server层实现的逻辑日志,记录语句的原始逻辑,比如:”给ID=2这一行的c字段+1“,作为追加写的日志,binlog写到一定大小后会切换到下一个,不会覆盖之前的日志
binlog的格式
statement格式的binlog最后有COMMIT,row格式的binlog最后有XID event,同时引入binlog-checksum参数,通过这三个方面可以让MySQL验证binlog的完整性
statement格式下的binlog日志就是存储着执行的语句原文,如:
但在这种格式下,因为delete带着limit,可能会因为删除选取的索引不同,而导致用于主备时导致主备数据不一致
row格式下的binlog日志记录了server id,table_map(在哪个库上面做的操作)以及真正操作的行主键id,如: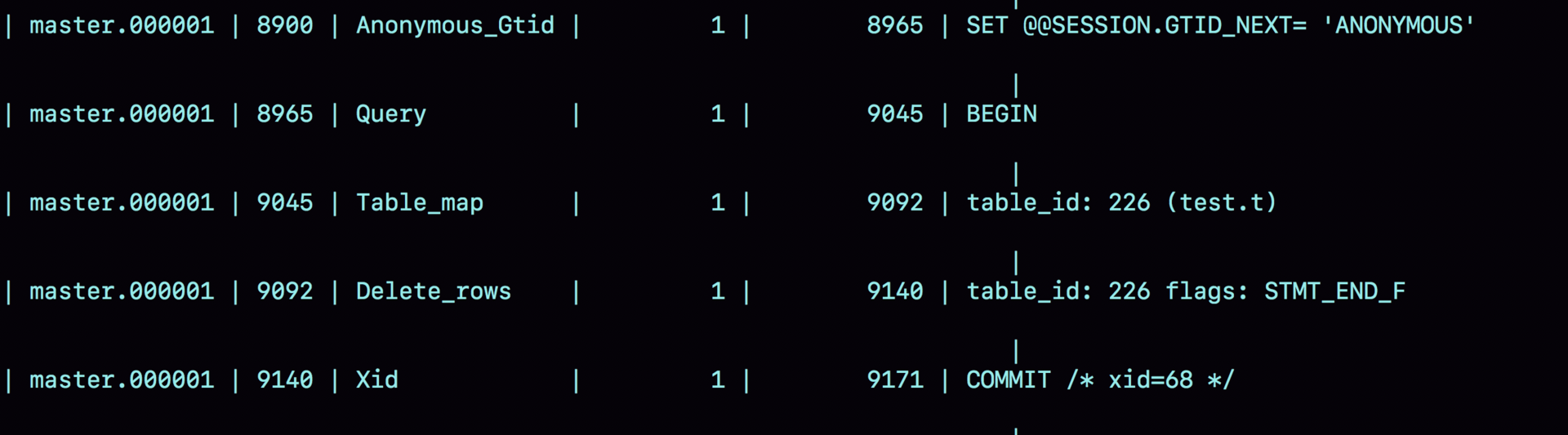
这就避免了statement格式下可能导致的主备数据不一致的问题,在越来越多的场景下使用row都更方便数据恢复
但row格式下的binlog日志耗费空间严重,同时耗费传输binlog时的IO资源影响执行速度,所以出现了兼备statement格式和row格式的mixed格式
单纯的binlog是 不具备 crash-safe 的,原因是:binlog没有能力恢复数据页,由于WAL技术,执行事务写完内存和日志,事务就算完成了,如果发生崩溃需要依赖日志来恢复数据页,因为binlog并没有记录数据页的更新细节,系统很难判断需要从哪个事务的binlog开始重放
相比redo log,binlog用处主要有2个:
- 归档:相比redolog的循环写,binlog是追加写,可以保留历史日志
- 复制:作为实现主从复制一部分的binlog二进制日志,可以支持从库做增量复制
利用binlog做数据恢复:系统定期做整库备份,需要数据恢复时找到最近一次全量备份,然后从备份的时间点开始以此取出binlog,重放到想要的时刻
binlog的写入机制
事务执行过程中,先把日志写到binlog cache,提交时再把binlog cache写入到binlog文件中,一个事务的binlog不能拆开,需要确保一次性写入
每个线程都有自己的binlog cache,但共用一份binlog files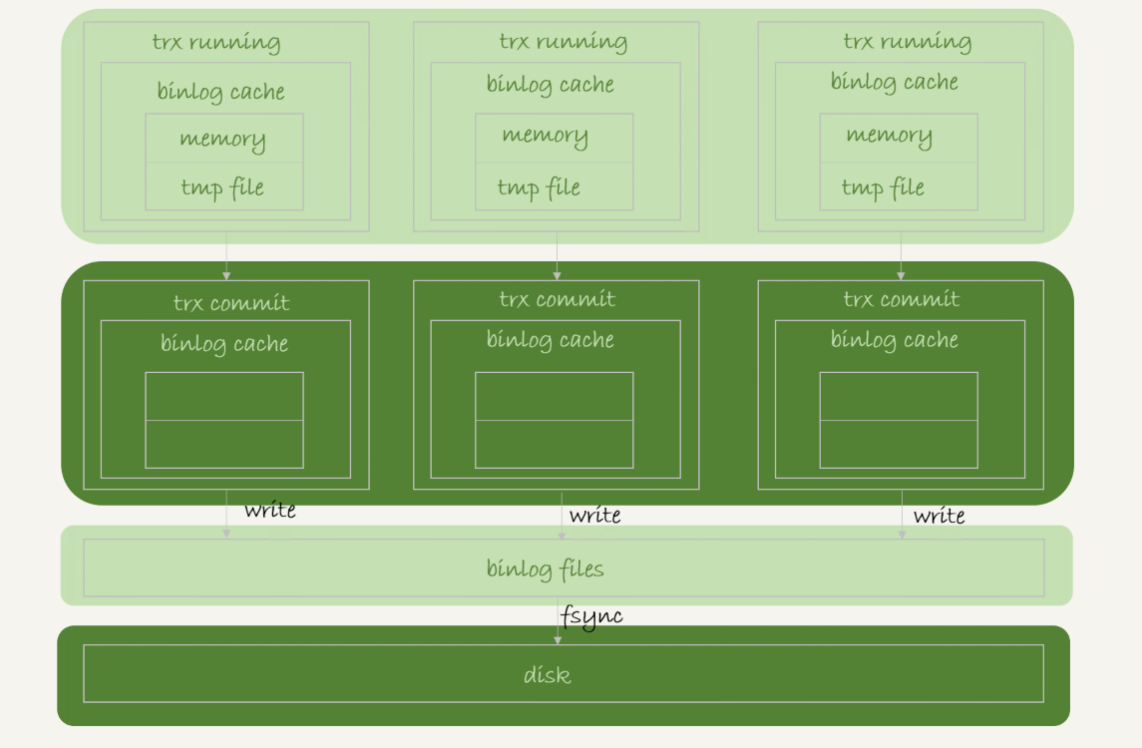
每个线程通过write将日志写到文件系统的page cache;随后再通过fsync将binlog files持久化到磁盘(此时才占磁盘的IOPS)
可以通过参数sync_binlog控制write和fsync的时机
- = 0 每次commit 事务只write,不fsync;
- = 1每次都会fsync;
- =N,累计N个事务后才fsync
在出现IO瓶颈时,会将它设置为一个比较大的值提升性能,但会有丢失最近N个事务的binlog日志的风险
WAL 与 两阶段提交
update T set c=c+1 where ID=2;的执行过程如下
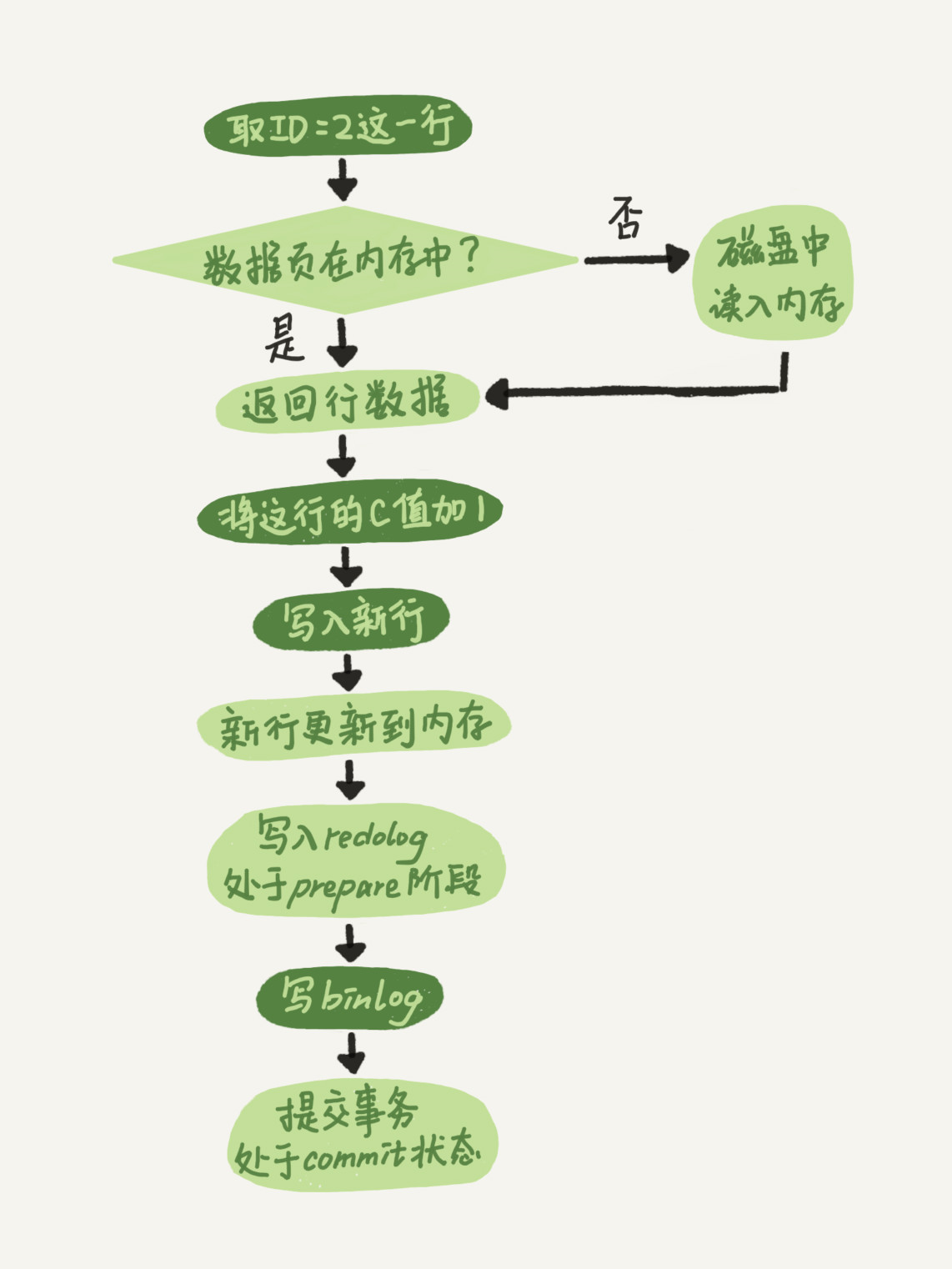
引擎将新数据更新到内存中,会先把更新操作记录到redo log,令其处于prepare状态,然后告知执行器执行完成,可提交事务;执行器生成该操作的binlog并写入磁盘;执行器提交事务,引擎将刚才的redo log改成commit状态
两阶段提交:将redo log的写入拆成了两个步骤 prepare 和 commit,由于redolog 和 binlog 都可以用于表示事务的提交状态,所以两阶段提交的目的就是保证两个日志之间的逻辑一致
如果没有两阶段提交,就要么先写入redolog再写binlog,或先写binlog再写redolog,如果在写完一个日志后系统崩溃,就会导致主从数据库不一致、恢复后数据与原数据不一致的情况发生
binlog和redolog都有一个数据字段:XID,基于两阶段提交进行崩溃恢复:
- 顺序扫描redo log,碰到既有prepare又有commit的redo log,说明该事务已经顺利commit,则直接提交事务
- 如果碰到只有prepare没有commit的redo log,就用XID去找到该事务对应的binlog,如果binlog是完整的,则提交事务,否则回滚事务
组提交机制优化:实际上会将redo log的fsync 以及 binlog 的fsync 放在一起,让一次fsync所带的组员更多,从而实现binlog的组提交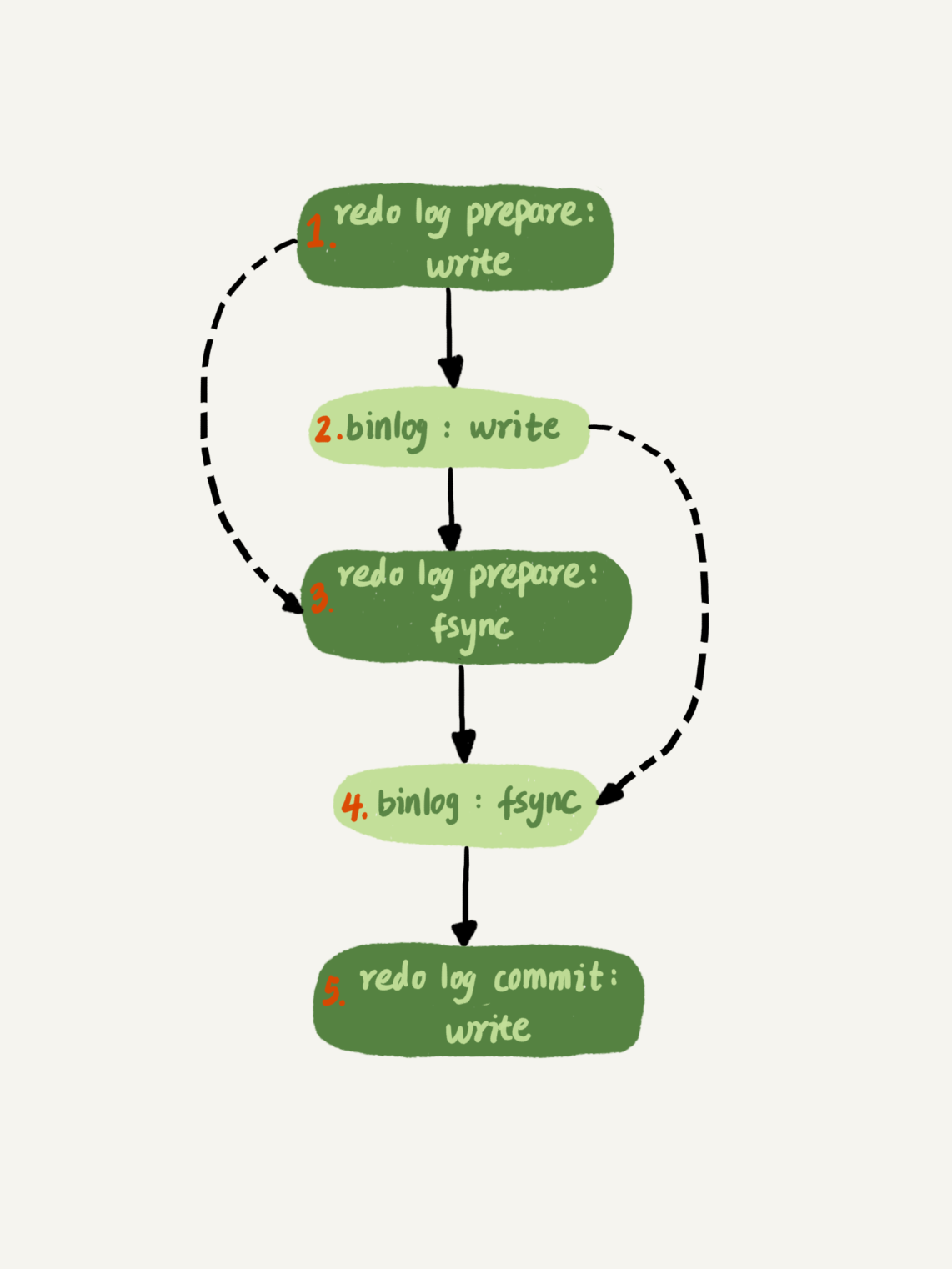
WAL:write-ahead-logging,关键点在于先写日志,再写磁盘,当一条记录需要更新的时候,InnoDB会先把记录写到日志中并更新内存,此时视为更新完成,直至系统空闲时将这个操作记录写入磁盘,提高磁盘IO效率的原因来自:
- redo log和binlog都是顺序写,磁盘的顺序写比随机写速度要快
- 组提交机制,可以大幅度降低磁盘的IOPS消耗
本文作者:pinoky
本文链接:https://www.cnblogs.com/pinoky/p/18414844
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步